程序地址空间回顾
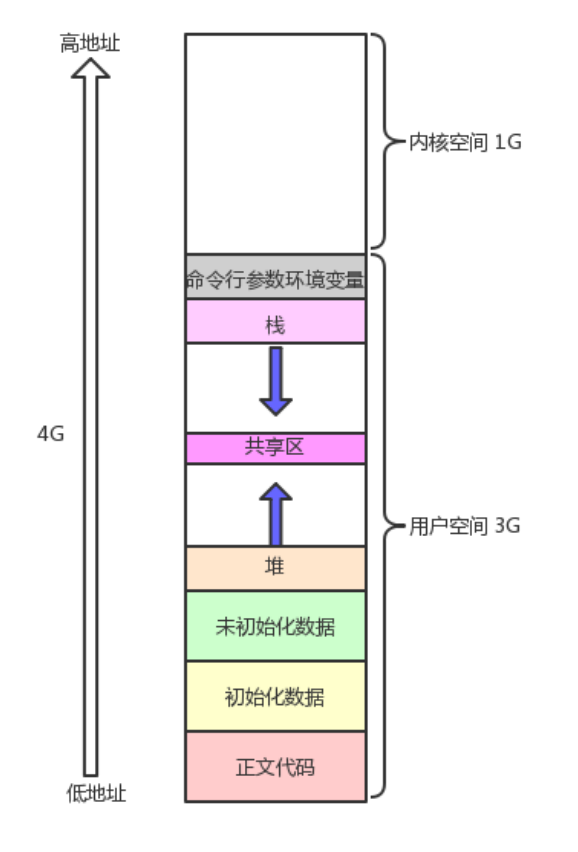
这种形式的程序地址空间根本不可能在内存中存在,这是因为在cpu中需要同时运行很多个进程。无法将每个进程都按照这个形式排列,这样进程将会没有空间运行。
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
const char *str = "helloworld";
printf("code addr: %p\n", main);
printf("init global addr: %p\n", &g_val);
printf("uninit global addr: %p\n", &g_unval);
static int test = 10;
char *heap_mem = (char*)malloc(10);
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
char *heap_mem3 = (char*)malloc(10);
printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)
printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)
printf("read only string addr: %p\n", str);
return 0;
}
可以通过这段代码来帮助我们了解地址结构,运行结果如图所示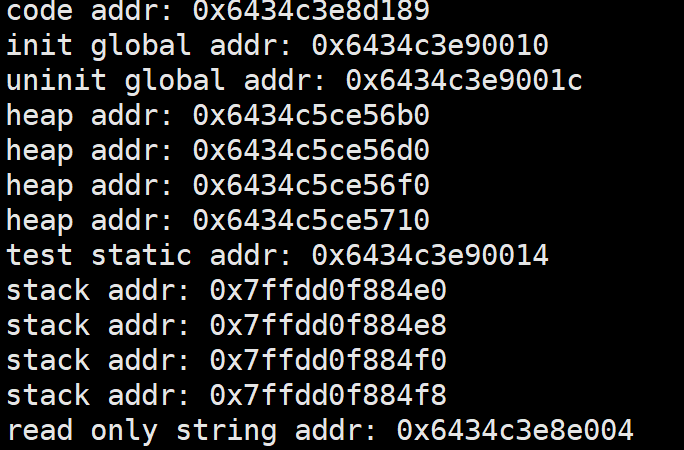
我们可以发现全局变量的地址与static变量的地址相邻,说明static变量也是全局变量的一种
虚拟地址
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if(id < 0){
perror("fork");
return 0;
}
else if(id == 0){ //child
g_val++;
printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);
}else{ //parent
printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}我们可以通过这个代码来了解虚拟地址

• 变量内容不⼀样,所以父子进程输出的变量绝对不是同⼀个变量
• 但地址值是⼀样的,说明,该地址绝对不是物理地址!
• 在Linux地址下,这种地址叫做虚拟地址
• 我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户⼀概看不到,由OS统一管理
进程地址空间
所以之前说'程序的地址空间'是不准确的,准确的应该说成进程地址空间 ,那该如何理解呢?看 图: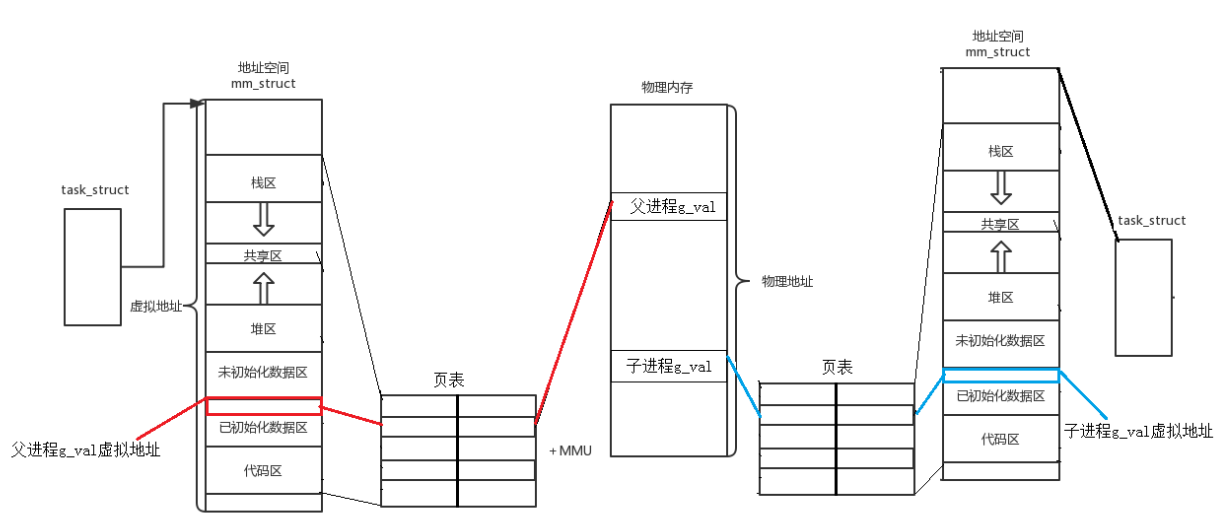
首先我们要知道一个概念:一个进程,一个虚拟地址空间,一个进程,一套页表。
我们代码中的变量有两个地址:一个虚拟内存地址,一个物理内存地址。
页表会对我们的虚拟内存地址与物理内存地址进行转换,页表的左边存放着虚拟内存地址,右边存放着物理内存地址,在运行代码时,操作系统可将物理地址转换成虚拟地址,虚拟地址的数据便是物理地址上的数据。形成映射关系
但是我们也需要对虚拟内存地址进行管理,管理的原则是先描述,再组织,将虚拟地址空间转换成一个结构体,对结构体进行管理。
当我们查看Linux源码时可发现在task_struct中存在一个结构体指针struct mm_struct*,这就是存放虚拟内存空间的结构体
可以说,mm_struct结构是对整个用户空间的描述。每⼀个进程都会有自己独立的mm_struct,这样每⼀个进程都会有自己独立的地址空间才能互不干扰,这样才能实现进程的独立性。先来看看由task_struct到mm_struct,进程的地址空间的分布情况: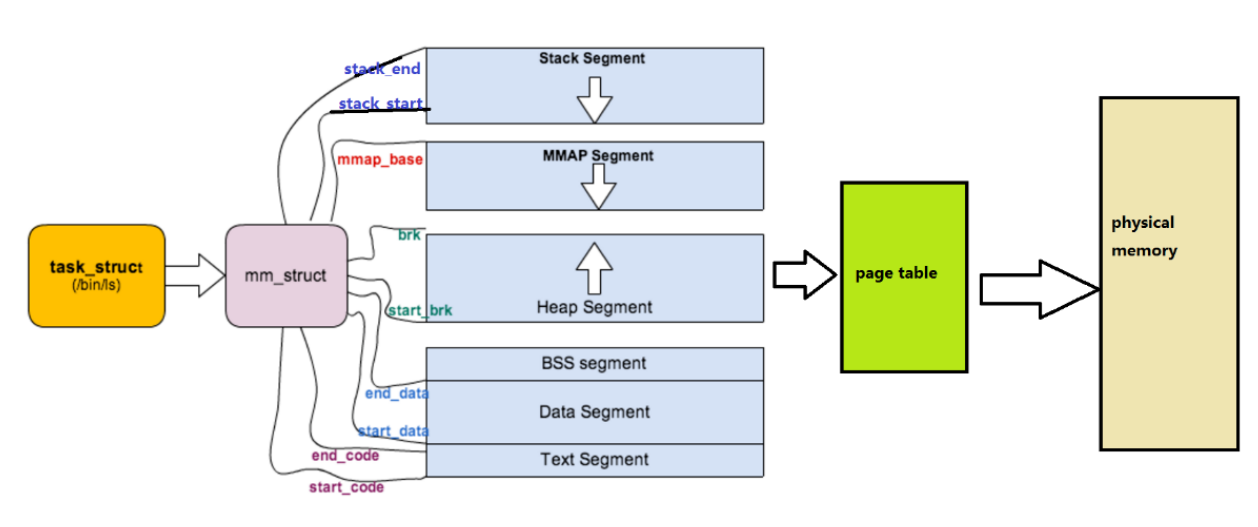
mm_struct只需要进行区域划xing分即可,只需要记录区域的起点和终点即可,所以在mm_struct中存放着数个变量,他们分别记录着堆区,栈区,代码区等等分区的起始地址和结束地址
那既然每⼀个进程都会有自己独立的mm_struct,操作系统肯定是要将这么多进程的mm_struct组织起来的!虚拟空间的组织方式有两种:
-
当虚拟区较少时采取单链表,由mmap指针指向这个链表;
-
当虚拟区间多时采取红黑树进⾏管理,由mm_rb指向这棵树。
因为有地址空间的存在,所以我们在C、C++语言上new,malloc空间的时候,其实是在地址空间上申请的,物理内存可以甚至⼀个字节都不给你。而当你真正进行对物理地址空间访问的时候,才执行内存的相关管理算法,帮你申请内存
父子进程的映射关系
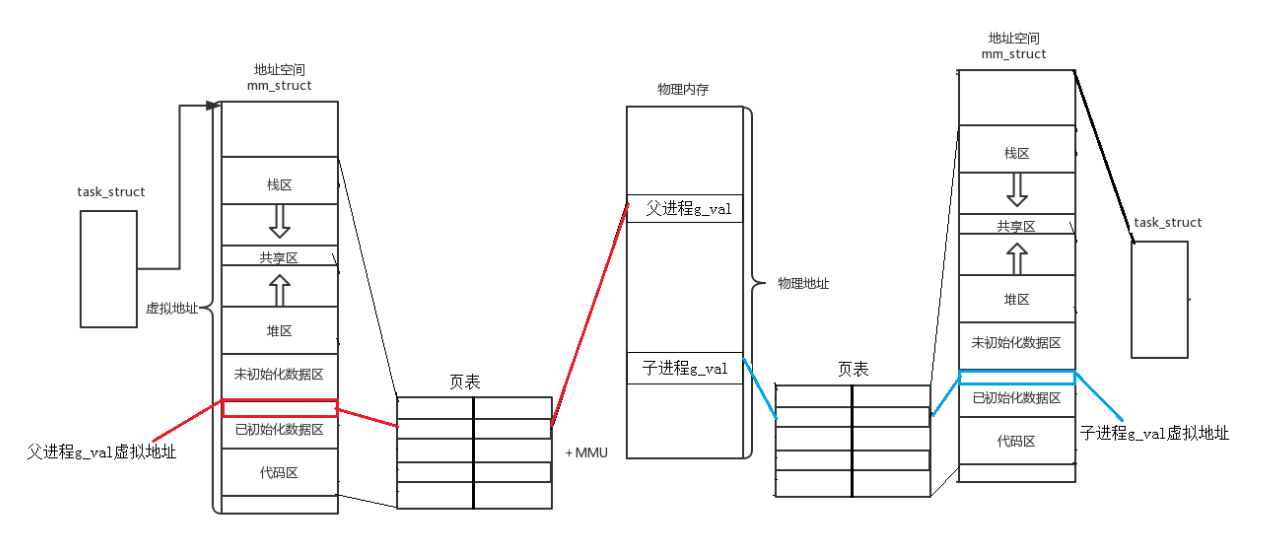
当我们创建子进程的时候,子进程也有属于自己的虚拟地址空间和页表。
但是子进程的数据是向父进程进行浅拷贝形成的,所以子进程中页表和虚拟地址空间的值与父进程完全相同。
当子进程在修改数据的时候,操作系统会发现子进程在修改数据,于是会在物理内存中重新开辟一段空间用于存放修改后的值,然后修改页表中的映射关系,将旧物理地址修改成新的物理地址
所以在上面的代码中,g_val的值不一样但是地址一样,这就是因为父子进程运行代码时g_val的物理地址不同 ,但是其虚拟地址相同导致的。
为什么要有虚拟地址空间
这个问题其实可以转化为:如果程序直接可以操作物理内存会造成什么问题?
在早期的计算机中,要运行⼀个程序,会把这些程序全都装入内存,程序都是直接运行在内存上的, 也就是说程序中访问的内存地址都是实际的物理内存地址。当计算机同时运行多个程序时,必须保证这些程序用到的内存总量要小于计算机实际物理内存的大小。
那当程序同时运行多个程序时,操作系统是如何为这些程序分配内存的呢?例如某台计算机总的内存大小是128M,现在同时运行两个程序A和B,A需占用内存10M,B需占用内存110。计算机在给程序分配内存时会采取这样的方法:先将内存中的前10M分配给程序A,接着再从内存中剩余的118M中划分出110M分配给程序B。
这种分配方法可以保证程序A和程序B都能运行,但是这种简单的内存分配策略问题很多。
• 安全风险 ◦ 每个进程都可以访问任意的内存空间,这也就意味着任意⼀个进程都能够去读写系统相关内存区域,如果是⼀个木马病毒,那么他就能随意的修改内存空间,让设备直接瘫痪。
• 地址不确定 ◦ 众所周知,编译完成后的程序是存放在硬盘上的,当运行的时候,需要将程序搬到内存当中去运行,如果直接使用物理地址的话,我们无法确定内存现在使用到哪里了,也就是说拷贝的实际内存地址每⼀次运行都是不确定的,比如:第⼀次执行a.out时候,内存当中⼀个进程都没有运行,所以搬移到内存地址是0x00000000,但是第⼆次的时候,内存已经有10个进程在运行了,那执行a.out的时候,内存地址就不⼀定了
• 效率低下 ◦ 如果直接使用物理内存的话,⼀个进程就是作为⼀个整体(内存块)操作的,如果出现物理内存不够用的时候,我们⼀般的办法是将不常用的进程拷贝到磁盘的交换分区中,好腾出内 存,但是如果是物理地址的话,就需要将整个进程⼀起拷走,这样,在内存和磁盘之间拷贝时间太长,效率较低。
虚拟地址的优点
1.虚拟地址能够将地址从无序变成有序,方便用户进行资源的管理
2.在地址转换的过程中,可以对地址和操作进行合法性判断,进而保护物理内存,在页表中其实还存在着权限分区->rwx
当我们向字符串常量进行写入的时候,编译器就会报错,崩溃,因为在页表中,字符串常量的权限只有r,但我们想要向其进行w操作,系统就会拦截操作。
3.让我们的进程管理和内存管理,进行一定程度的解耦合,让其彼此之间的操作互不影响,能够相对独立地进行设计、开发、维护和运行