文章目录
- 磁盘级文件系统
-
- 磁盘的物理存储结构
- 物理存储结构转换成逻辑存储结构
- Ext磁盘文件系统
-
- 磁盘分区
- 如何管理组(组的框架)
-
- [Boot Block:](#Boot Block:)
- [inode Table:](#inode Table:)
- [Data Blocks](#Data Blocks)
- inodeBitmap
- BlockBitMap
- GDT(GroupDescriptorTable)
- [Super Block](#Super Block)
- 详解Ext文件系统
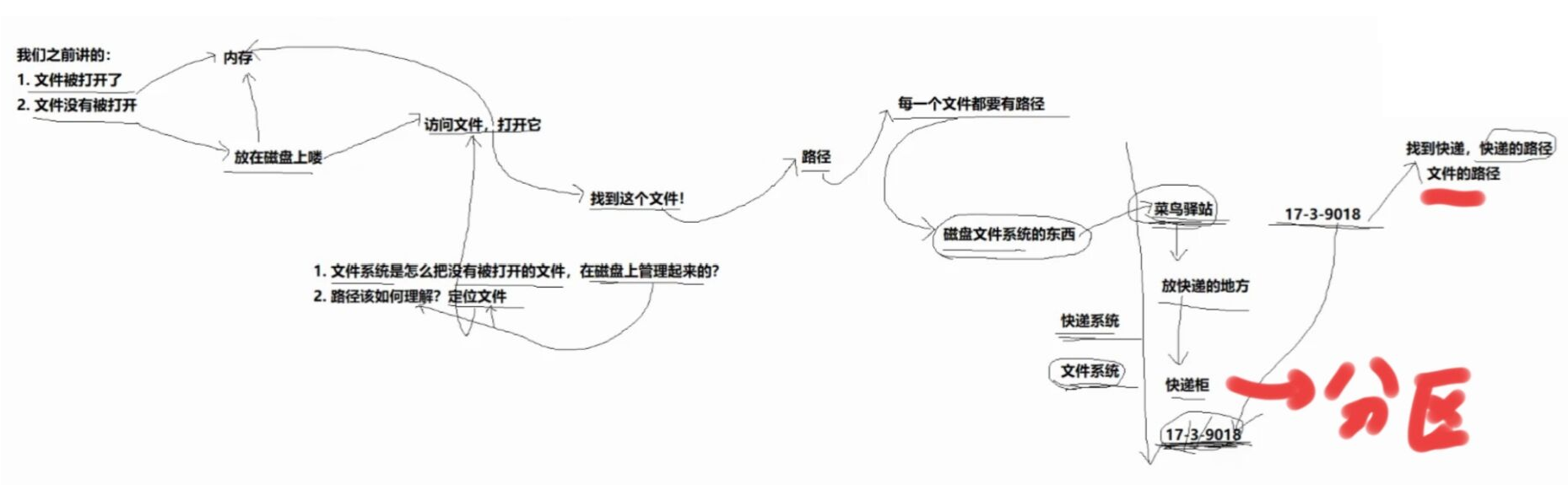
- 操作系统如何管理磁盘文件?
- 文件名和inode的关系
- 查找一个文件
-
- [struct dentry的详细说明](#struct dentry的详细说明)
- 文件描述符及进程与文件系统的关系
- 如何确定自己使用的文件在哪一个分区中
磁盘级文件系统
我们打开文件的前提是找到文件
而且为了效率还要快速地找到文件,所以必须对文件的存放进行规划
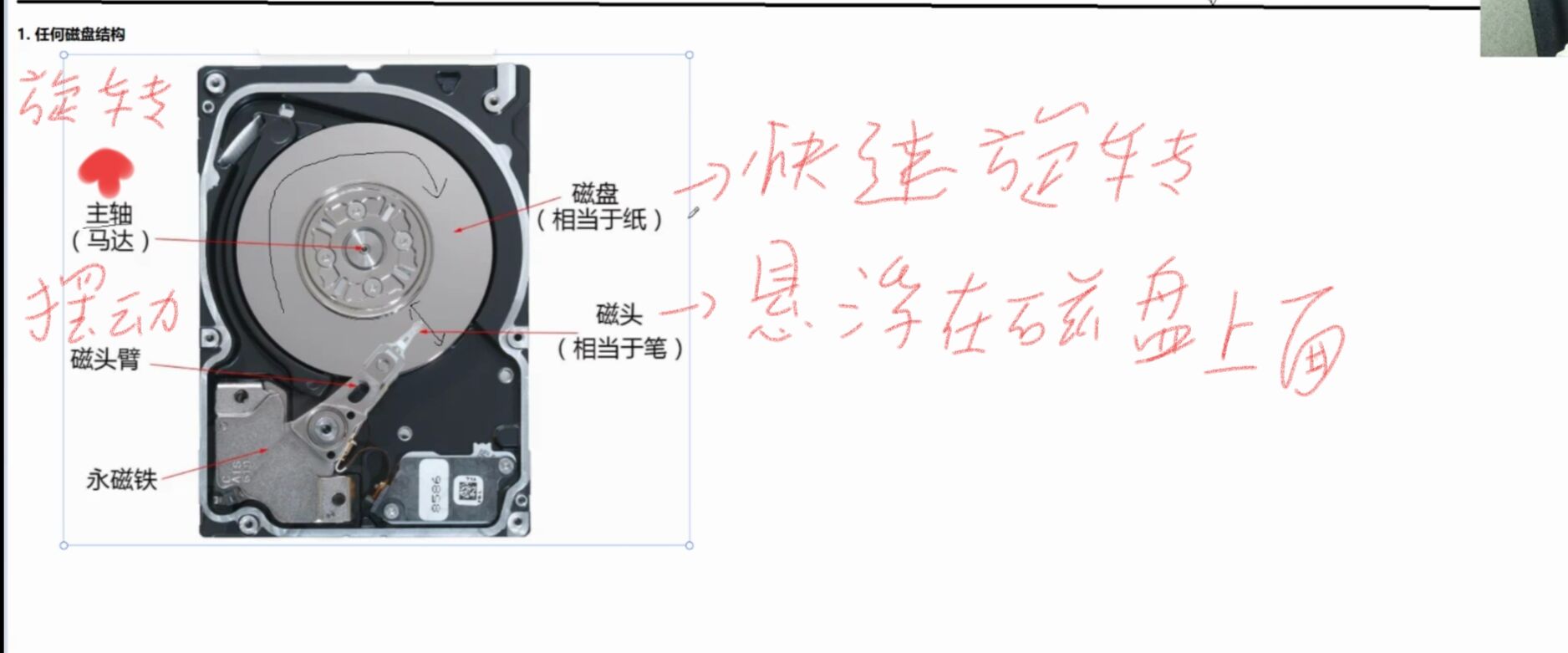
磁盘的物理存储结构
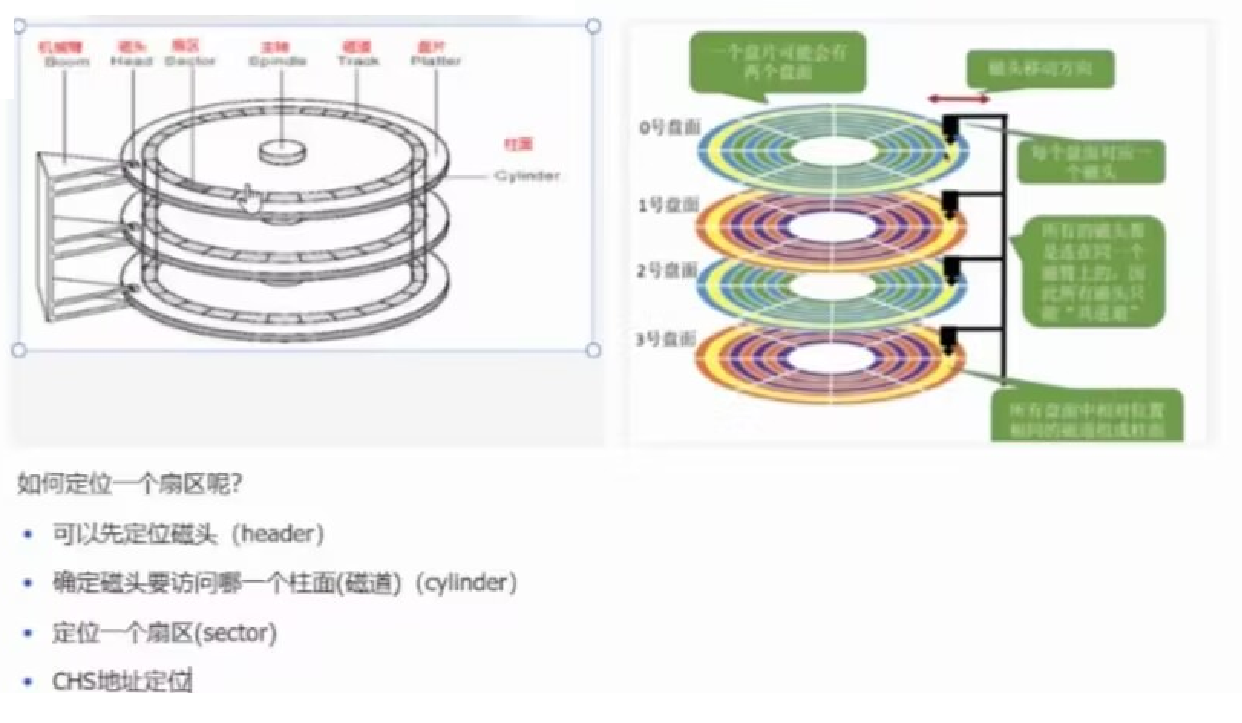
磁盘的物理结构(俯视图)
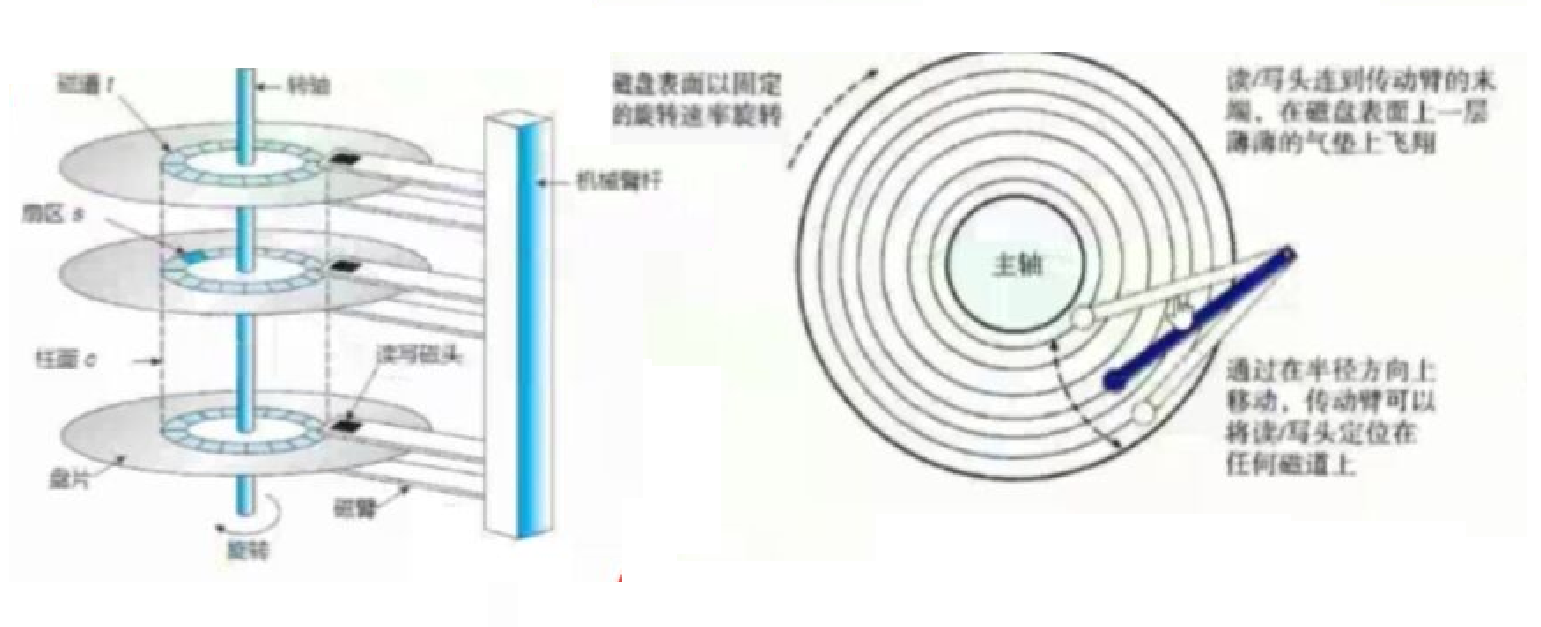
磁盘的盘面由很多个同心圆的磁道构成
每个磁道并不是完整的圆,而是由一段段圆弧构成的,圆弧之间不连续有间隔
这个圆弧被称为扇区
一摞磁盘一个同心圆中的所有磁道构成柱面
所以:
磁头摆动的本质:为了定位不同的磁道(柱面)
磁盘盘片旋转的本质:为了定位磁道上不同的扇区
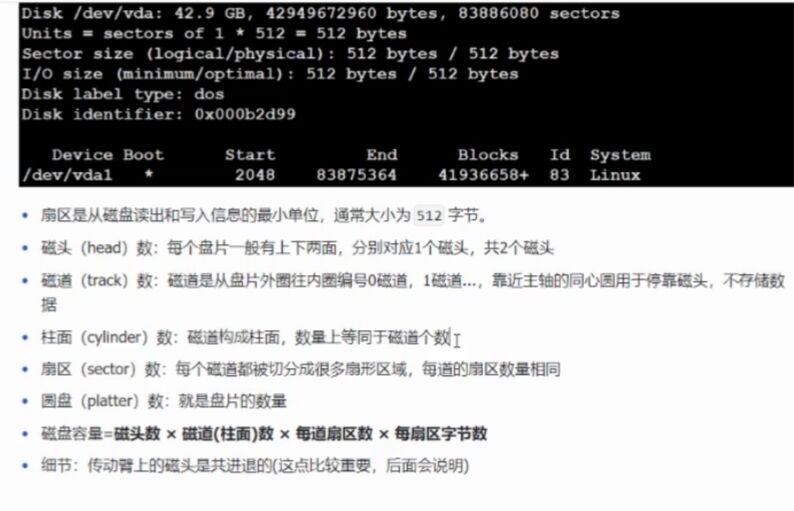
扇区是磁盘最基本的存储单位,一个扇区一般存储512字节
如何找到一个扇区
物理存储结构转换成逻辑存储结构
因为每一个面的磁头都连接在一个磁臂上,所以所有的磁头是同步移动的
也就是它们同时所在的磁道是一样的,那么这些磁道就构成了一个逻辑上的柱面:
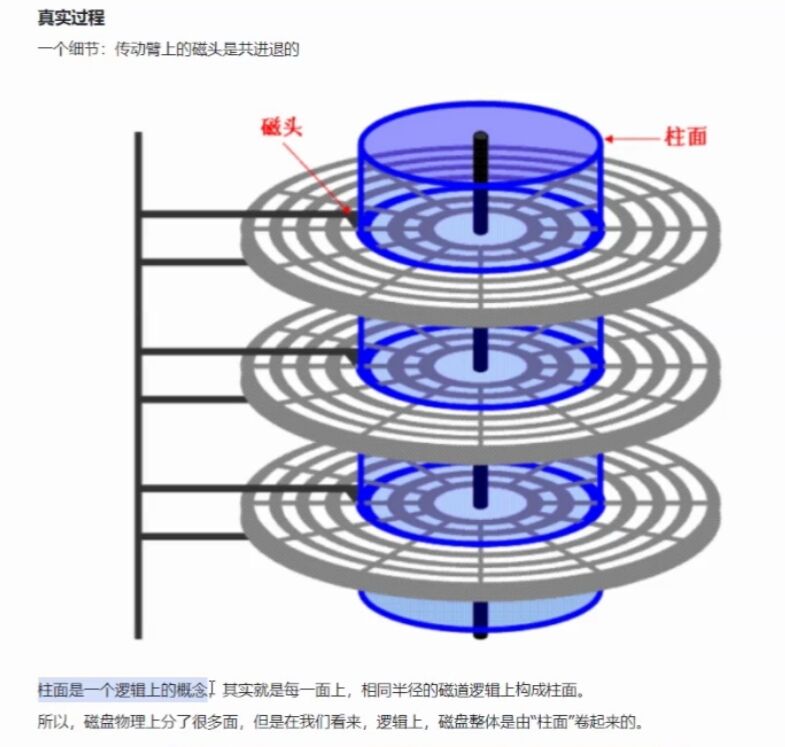
所以再次抽象一下
磁道就是元素是扇区的一维数组
柱面就是元素是扇区的二维数组
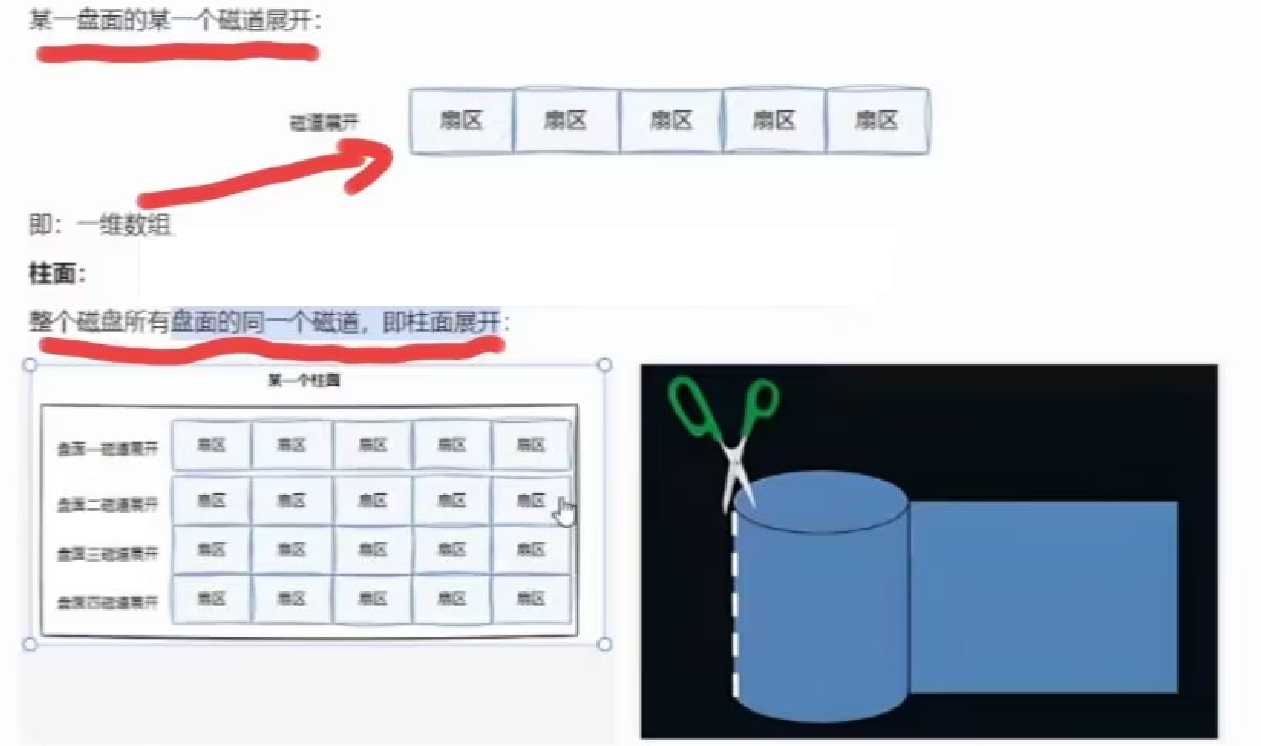
所以整个磁盘就可以看做是:
元素是扇区的三维数组
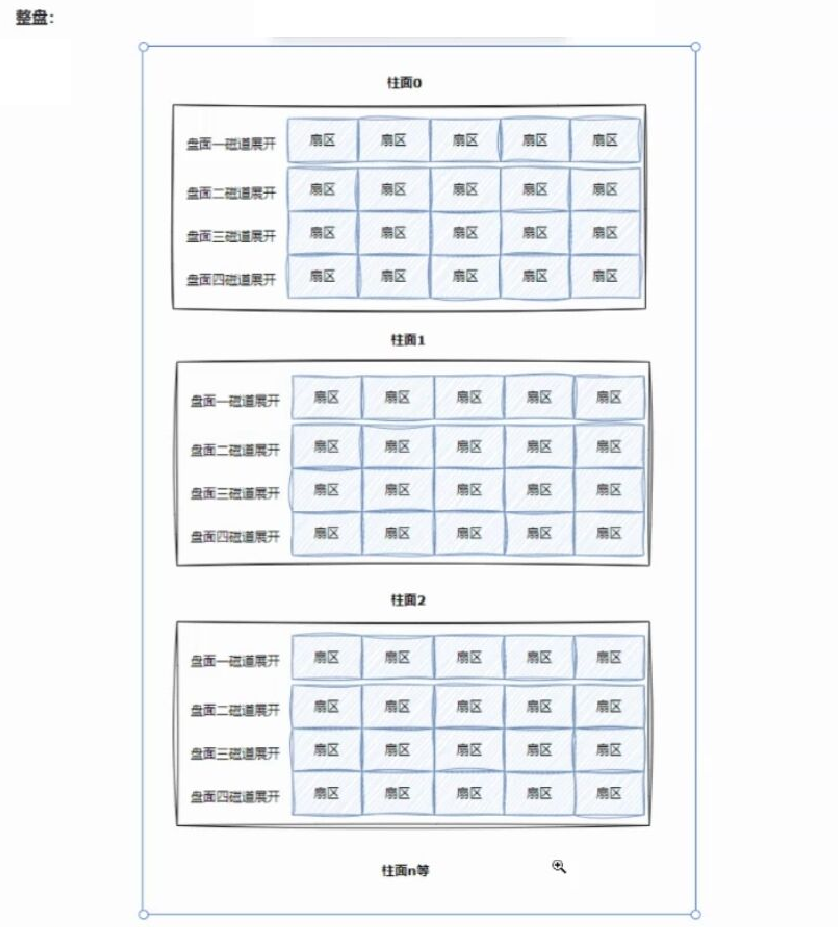
CHS地址就是磁盘物理存储结构上,用于找到一个扇区
最后:
磁盘自己进行LBA地址与CHS地址之间的互相转换,操作系统不需要管
LBA地址就是:磁盘对应的一维数组的下标
Ext磁盘文件系统
数据块:
如果以扇区为单位进行IO,单次IO的数据量还是有点少了
所以就出现了数据块
不同平台对数据块定义的大小不固定,有1kb,8kb,4mb的
但是使用最多的是4kb的数据块,即由8个扇区组成
所以还可以把磁盘的逻辑存储结构看做是以块为单位的一维数组
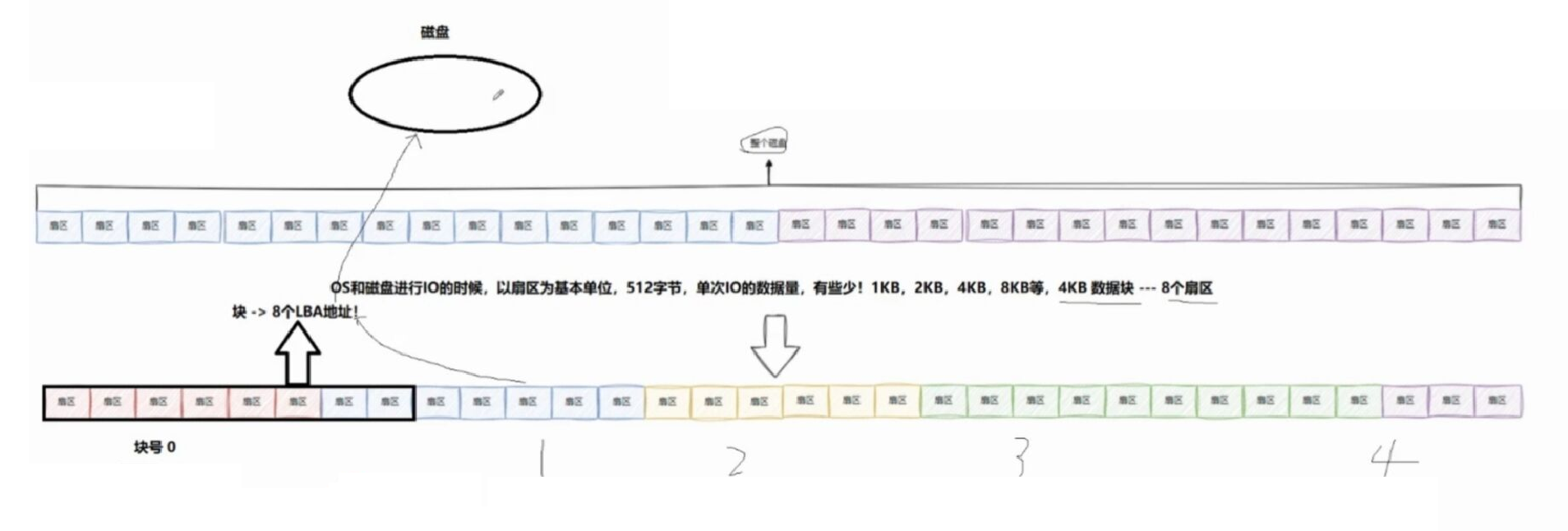
所以对磁盘进行读写的本质是:
读取:就是以数据块为单位,把数据读入内存(即哪怕用户只需要看一个数据块的一个比特位,都必须把整个数据块的数据读入内存)
写入:把数据写入到一个/多个数据块,进行存储
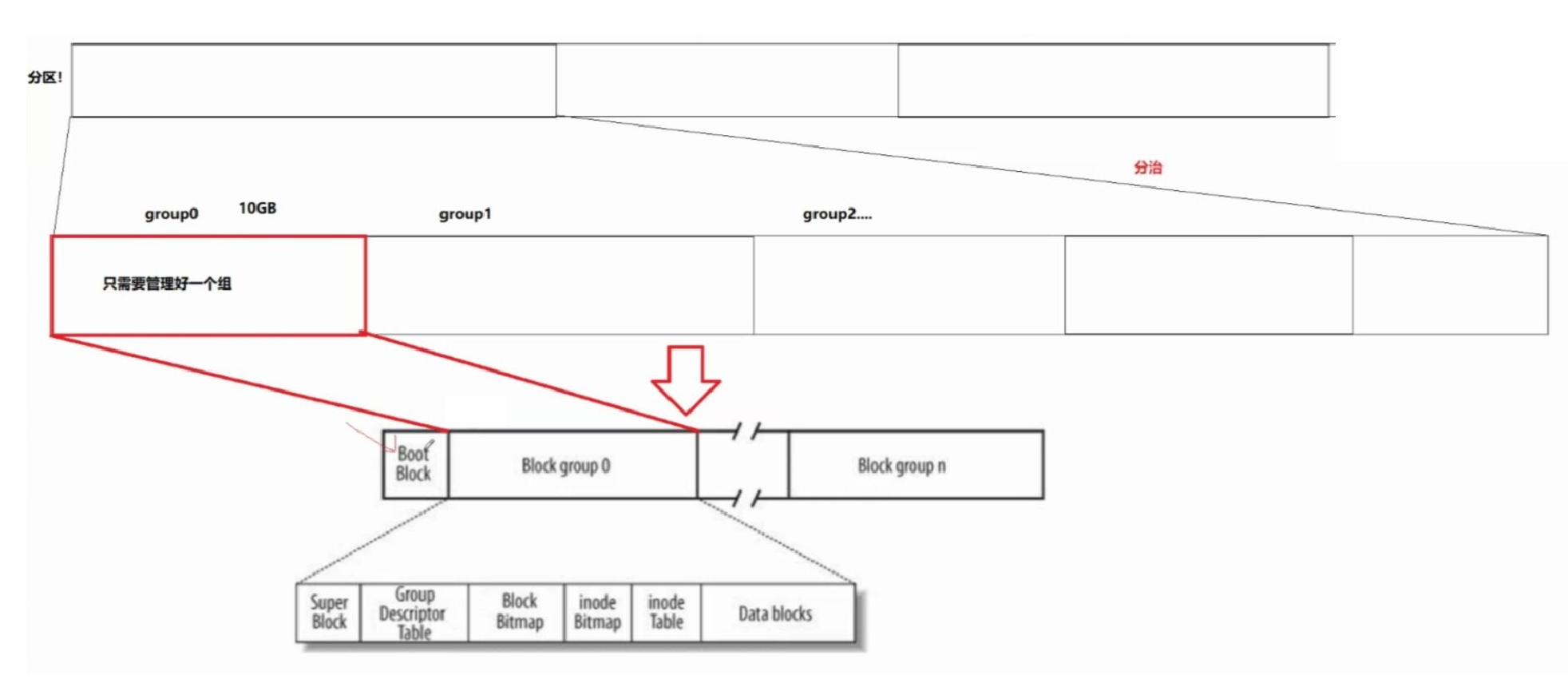
磁盘分区
因为直接管理一整个磁盘不好管,所以就像对进程地址空间一样(栈,堆区)对整个磁盘也进行了分区
(就比如我们国家也分成了省,省里面又分成了市,这其实就是分治的管理
这样只需要对一个市制定管理方案,让所有市都执行这个方案,就管理好了整个国家)
体现在Windows中就是整个磁盘被分成了C盘和D盘等不同的盘
不同的分区之间是独立的,它们使用的文件系统可以不同
分区了还不够,每一个分区还会被分成若干个组
所以我们只需要管理好一个组,其他的组也用类似的管理方法,就可以管理好整个分区了
如何管理组(组的框架)
具体的:
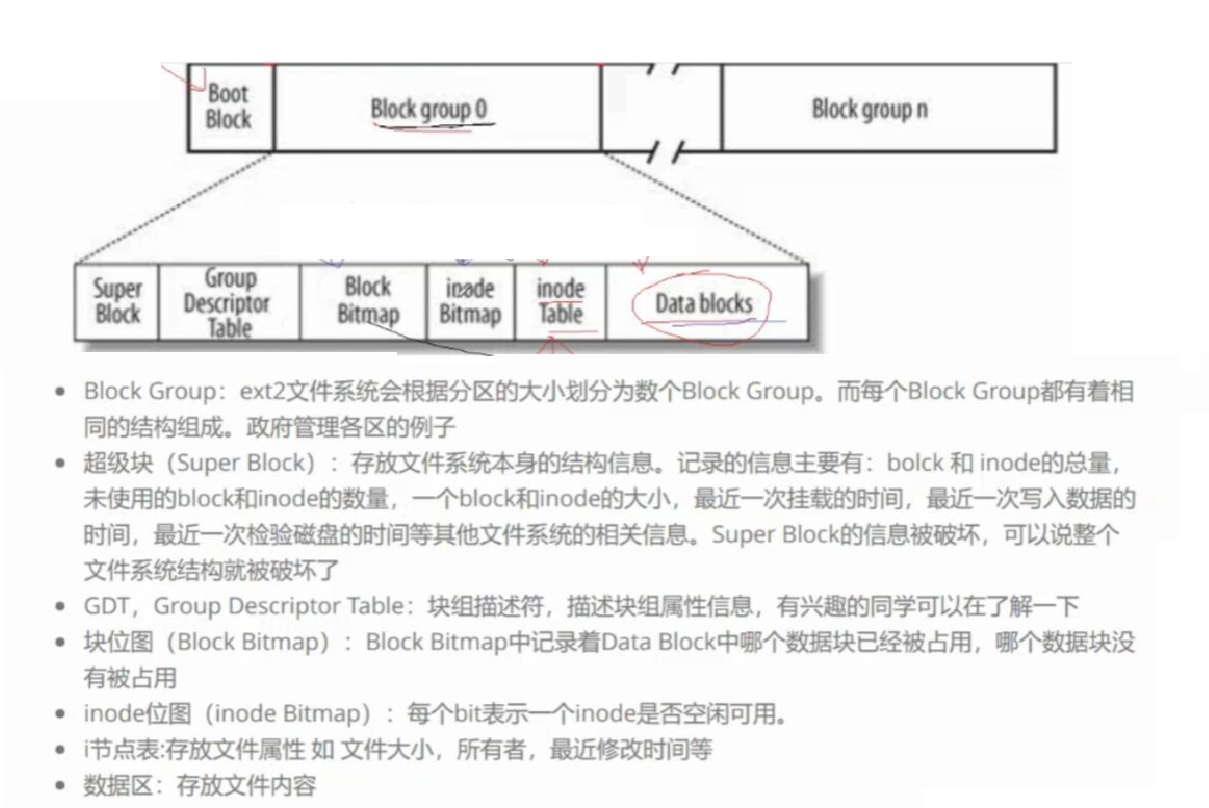
Boot Block:
是单独的组,存储了与开机有关的信息和磁盘自身的信息
inode Table:
磁盘中一个文件的属性集合以inode进行表示和存储
一个文件只有一个inode
一个inode的大小一般为128字节
inode中的具体内容
1.文件属性:
①这个inode的编号
②文件的权限
③文件的拥有者,所属组的UID
④文件的时间属性
⑤文件的大小
⑥引用计数,记录有多少个文件名与这个inod建立了映射关系
等文件属性
2.数据块映射
int blocksN:数组里面存储了,保存文件内容的数据块的块号N=15
其中:
(假设一个数据块4kb)
①前12个块号,指向的数据块都是存储的就是文件内容
②第13个块号,指向的数据块是一级索引块
一级索引块里面存储的是:0~1024个存储文件内容的数据块的块号
此时文件最多存储1024x4kb=4MB
②第14个块号,指向的数据块是2级索引块
2级索引块里面存储的是:0~1024个一级索引块的块号
此时文件最多存储1024x1024x4kb=4GB
③第15个块号,指向的数据块是3级索引块
3级索引块里面存储的是:0~1024个2级索引块的块号
此时文件最多存1024x1024x1024x4kb=4TB
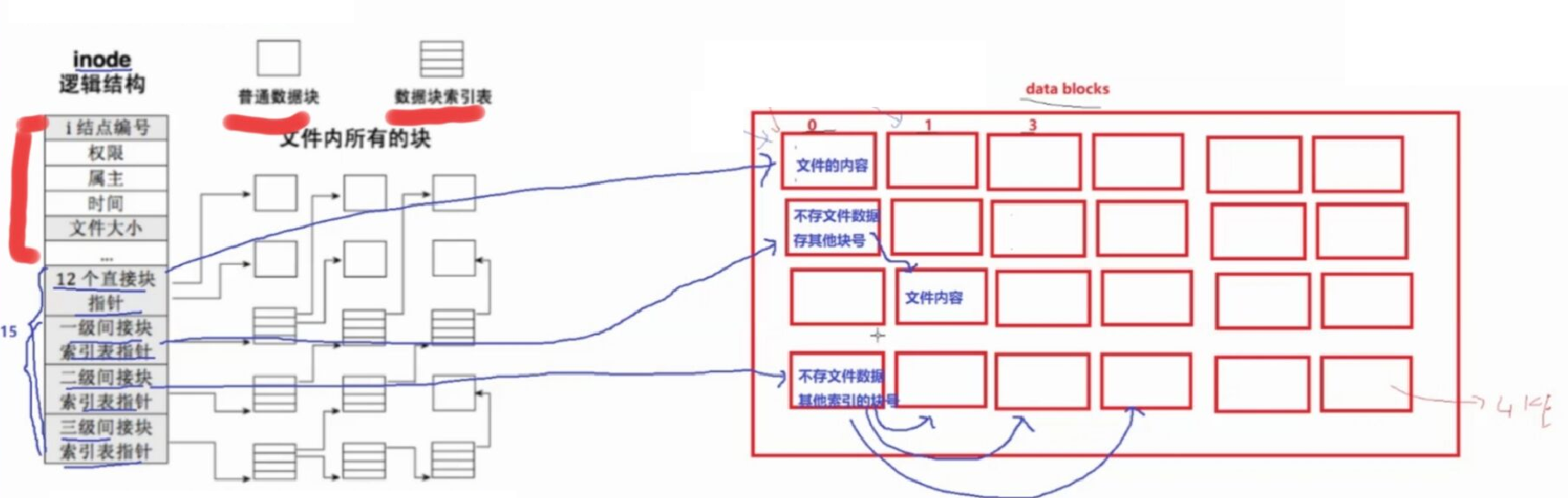
为什么这么存块号?
-
让inode的大小固定,这样才能把inodeTable当做数组使用,不然就无法随机存取了
进而让组的大小固定,这样方便对文件属性整体加载,也更好管理
-
我们经常查看的是文件属性,而且很多时候都是查一堆文件的属性(比如ls命令)
因为inode要经常被加载到内存,所以inode不能太大,至少不能因为映射的原因变大
整个组的所有inode都存储在inode Table中
为了方便管理,给每个inode进行了编号
inode编号一般情况下不会重复
注意:
inodeTable初始化时就会为整个组的所有inode开辟空间
即使没有被使用的inode也占了空间,只是对应的inodeBitMap下标中为0
Data Blocks
Data Blocks是由n个数据块组成的,专门用来存储这个组的所有文件的内容的地方
所以磁盘文件的内容和属性是分开存储的
inodeBitmap
即inodeTable的位图
作用
①标识inodeTable中对应下标的数据是否有效`是不是删除/空状态,因为制空(改)128字节和改一个bit位,谁更赚?`
②快速查找,int类型的位图一次就可以看32个比特位是否为空,为空就可以直接跳过,不为空再查找这32个比特位
BlockBitMap
即Data Blocks对应的的位图
作用和inodeBitmap的作用一样
所以删除一个文件就是把它对应的inodeBitmap和blockBitmap相关位置置成0就行
那么也可以通过这个恢复一部分删除的文件或者恢复文件的一部分(不是再回收站,是真删除了)只需要再把它对应的inodeBitmap和blockBitmap相关位置置成1就行,如果还没被覆盖就能恢复
GDT(GroupDescriptorTable)
描述对应组的属性信息
里面存储了
组里面一共多少个inode,被使用了多少个
DataBlock里面一共有几个数据块,被使用了多少个等信息
通过这些信息,就能了解组里面的inodeTable和Data Blocks的使用情况
Super Block
存储整个分区的文件系统的结构信息
即Super Block就是描述文件系统的"结构体"
一般一个分区会有几个内容相同的Super Block结构变量,分散存储在一些组里面
因为Super Block对于一个分区来说非常重要,如果误删了,整个分区的文件系统就几乎挂掉了
所以在几个组里都存一份,误删的时候就可以互相恢复
详解Ext文件系统
Ext文件系统规定每个分区的inode编号的总个数和DataBlock中的数据块的个数是固定的
每个组的inode编号的个数也是固定的 ,每个组的数据块个数也是固定的
这个是操作系统能够根据inode号高效查找文件的inode和data block的核心原因
即:
一个分区一套inode编号
所以
①相同分区不会出现相同的inode编号
②不同分区的inode的编号可能相同
数据块的块号也是一个分区一套
因为是固定的,所以:
每个组只需要在GDT里面记录自己这个组的起始inode编号和起始数据块块号
知道起始块号之后,就知道每个组的
①inode个数和数据块个数
②也就知道inodeTable和DataBlocks有多少元素,对应位图要多少个比特位
③GDT和SB又是大小固定的结构体变量
这样就可以把整个分区看做是一个一维数组了,元素就是分组
所以一个分组给一个ionde/数据块分配编号就是:
①遍历inodebitmap查找空位,得到组内编号
②组内编号再去DGT中加上该组的起始inode编号
这样就可以确保整个分区的inode号和块号一定具有唯一性
综上:
每个组的组成部分都是固定大小,也就是组也是固定大小每个组的大小都一样
这样设计有什么好处?
可以使用inode号高效查找!
因为每个组的inode个数固定,所以GDT记录了其起始inode号之后,也就知道自己的inode号的范围了
假设每个分组都有n个inode号的话
此时,操作系统只需要根据起始inode序号排序gdt,然后直接拿着inode号/n就知道是在那一组了
(注意:这里说的gdt是操作系统自己在内核构建的结构体,不是磁盘里那个)
然后,每个组的inode又是在数组中连续存放的(注意,inodeTable初始化时就会为整个组的inode开辟空间,即使没有被使用的inode也占了空间,只是对应的inodeBitMap下标中为0)
所以inode号-组起始inode号=inodeTable的下标(偏移量)
每个分组的inode个数和data block的个数是固定的,那如果不够用怎么办?
首先明确一点:
在创建一个文件保存数据的时候,文件系统本身会计算文件的大小,再根据算法把该文件放进合适的分组中
所以本身就很难出现不够用的情况,并且至少能保证inode不可能不够用
就算文件后面进行修改,内容变大了很多
data block不够用了,就可以用其他组的呀反正inode里面存储了数据块的块号
操作系统如何管理磁盘文件?
综上:
磁盘文件的管理由文件系统(SB+GDT)进行管理
所以操作系统要对磁盘文件进行管理,只需要管理好文件系统(SB+GDT)就可以了
操作系统如何管理文件系统?
先描述再组织!
创建struct sb和struct gdt,再把磁盘中的SB和GDT加载到内存进行初始化
并让sb于自己分区里面的gdt进行关联
所以对文件系统的管理就变成了对数据结构的增删查改
操作系统其实不用管磁盘的文件系统是什么
因为不管是什么文件系统,操作系统对他们的功能要求是一样的
只要能删除,增加,修改文件等操作就可以了
所以所有文件文件系统,也像外设的一切皆文件一样,使用函数指针对自己的函数接口进行了统一的封装
文件名和inode的关系
用户在内存中操作文件都是通过文件名进行操作的,但是文件系统都是通过inode号操作的
而Linux中,文件名不存储在inode中
那文件名存储在哪里呢?
目录对于文件系统来说也是文件
所以目录=内容+属性=inode+数据块
所以
①目录的inode里面存储了目录的属性
②目录的数据块里面存储了:目录下的文件的文件名与它的inode号的映射
所以我们查找一个文件:
①找到文件所处的目录,先使用目录的上级目录中存储的该目录自己的inode号,找到该目录的inode
再使用目录的inode找到目录的数据块
②遍历目录的数据块,根据自己的文件名找到自己的inode号
③用文件自己的inode号去文件系统里找内容+属性
所以目录的rwx权限本质是
r:能不能遍历目录的内容,找到文件名与inode号的映射
w:能不能修改目录的内容,添加/删除文件名与inode号的映射
x:能不能打开目录
为什么查找要用inode号,操作又用文件名呢?
①查找是操作系统来查的,整型比字符串查找/比较效率更高,对于计算机来说更有辨识度
②文件名是给人使用的,字符串对于人来说,比整型更有辨识度
③用字符串作为key查找/比较效率低,而且文件名是用户自定义的,重复度太高
既然文件名和inode都要有,那么它们之间就必须要有映射关系
而且为了方便使用,还得保存它们的映射关系
所以就设计了目录,保存映射关系
查找一个文件
/home/xyz/a.txt
要查找a.txt的inode号,就要找到它所处的目录的inode号,也就是目录xyz的inode号
但是xyz的inode号也存储在上级目录的数据块里,所以还要查找home的inode号
而home的inode又存储在/的数据块中
根目录就是固定的了
根目录的inode号等相关信息,电脑安装磁盘并且分区之后,就已经被写入了分区的SuperBlock中了
所以查找一个文件,就必须根据绝对路径从根目录开始,沿着路径一直查找
这也就是为什么使用一个文件时,操作系统必须要知道它的绝对路径的原因,没有路径操作系统根本找不到它
所以:进程的cwd的一个重要作用,也是把它操作文件的相对路径拼接成绝对路径
我们通过上述的方法找到了文件a.txt
(/home/xyz/a.txt)
如果我们又要使用和a.txt处于同一目录的文件b.txt时,难道还要这样查找一遍吗?
不需要,因为每次都这样太慢了
因为每次都要到外设(磁盘)中读取/写入数据块,也就是进行IO,效率很低
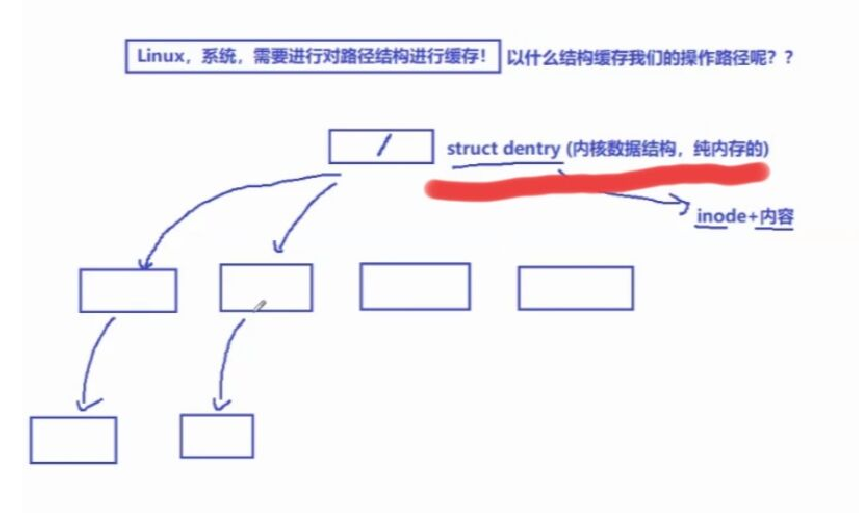
其实Linux在用户每次查找/使用文件时,都会进行路径结构缓存
磁盘里面不需要保存/维护文件路径
但是
操作系统为了在内存中,使用文件更加方便快速,就会对路径结构进行缓存
会在内存中根据用户的文件操作缓存/维护一颗多叉树`struct dentry`
用户第一次进入一个目录时,操作系统就会再悄悄把整个目录的文件添加到缓存的多叉路径树中
这样下次用户再查找这个目录下的文件时,就直接查找内存中缓存的多叉路径树,不需要再去磁盘中进行查找了
注意:
①缓存的多叉路径树,是存储在内存中的,也就是关闭内存(关机)就没有了
②缓存的多叉路径树不会一直变大,一些路径如果长时间不使用,就会被删除
③缓存的多叉路径树struct dentry
没有把节点信息分离成一个结构体,而是也存储在了struct dentry中
所以它的节点的类型也是struct dentry
struct dentry的详细说明
在Linux运行时,并不是磁盘中所有的文件都有对应的struct dentry实例。struct dentry实例是在文件被访问或被文件系统操作(如列出目录内容、打开文件等)时动态创建的。以下是更详细的解释:
-
当一个目录被访问时,文件系统的名称查找机制会为该目录下的每个文件和子目录创建一个
struct dentry实例也就是把它们作为节点链接到多叉树中这些dentry实例通常存储在文件系统的dentry缓存中,这样可以加快后续的文件查找操作。 -
用户访问过的目录中的文件通常会有对应的
struct dentry实例,因为访问操作会触发名称查找并创建相应的dentry。 -
然而,对于那些从未被访问过的文件,尤其是在大型的文件系统中,可能不会有对应的
dentry实例。文件系统不会为每个文件预先创建一个dentry,因为这样会消耗大量的内存,并且大多数文件可能永远不会被访问。 -
当文件或目录不再需要时,其对应的
dentry实例会被标记为无效并最终从系统中移除。例如,当文件被删除或者文件系统被卸载时,相关的dentry实例会被释放。
因此,只有当文件或目录被访问,或者在其生命周期中需要进行文件系统操作时,它们才会对应一个struct dentry实例。一旦这个实例不再需要,它就会被回收。
所以,不是磁盘中所有的文件在任意时刻都有一个对应的struct dentry,而是只有那些在特定时刻被文件系统操作涉及到的文件才会有。
文件描述符及进程与文件系统的关系
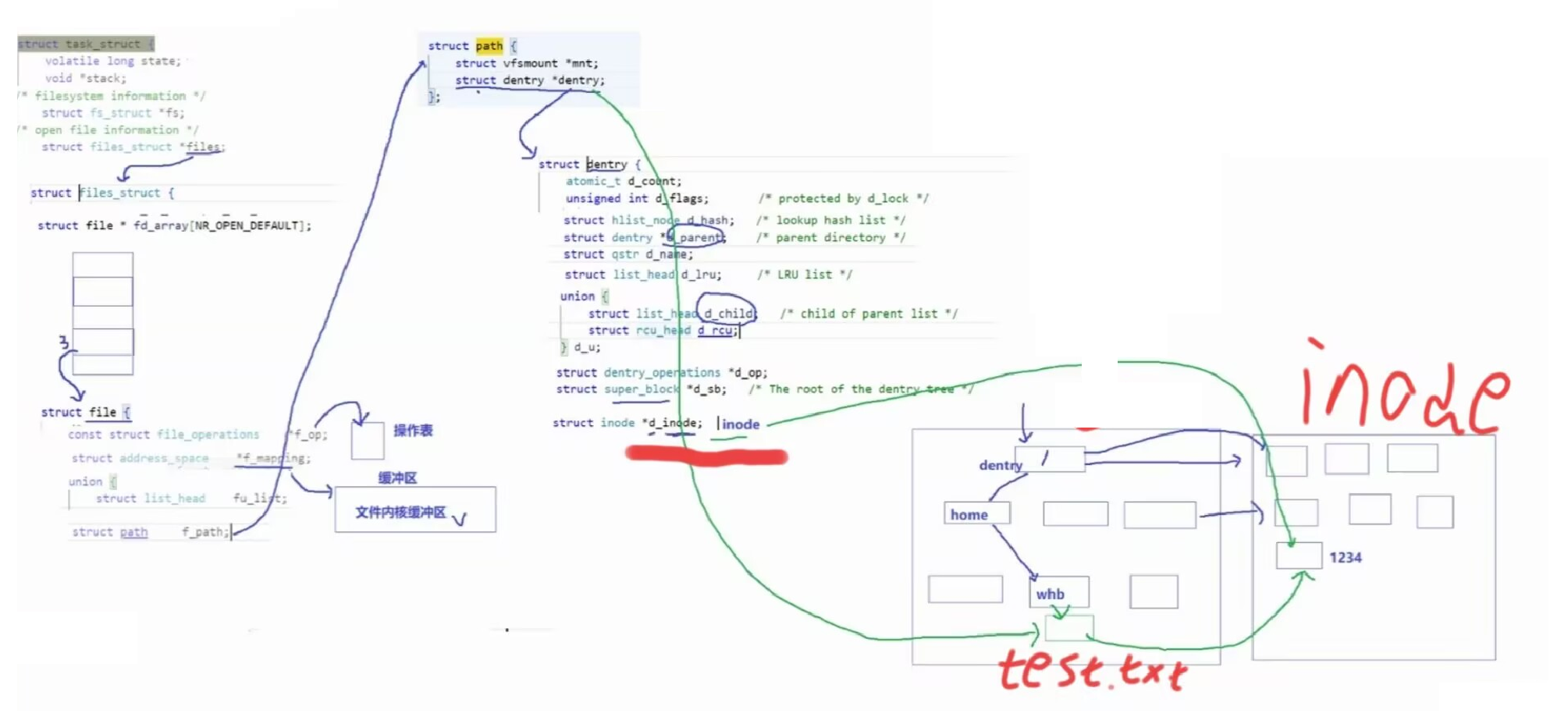
打开的文件的struct file中有一个struct path
它里面存储了两个指针
其中dentry指针指向了这个文件在缓存多叉路径树(struct dentry)中对应的节点`struct dentry的节点类型也是struct dentry`
这个文件对应的struct dentry类型的节点里面就存储了这个文件的inode
因为打开文件的时候,把文件加载到内存时,就把它的inode也加载进来了
如何确定自己使用的文件在哪一个分区中
Linux中如果磁盘有多个分区,那么其中有且仅有一个分区能包含(挂载)根目录
这个分区通常在Linux启动时被自动挂载
这个根分区包含了启动Linux系统所需的所有基本文件和目录,包括/bin、/etc、/lib、/sbin、/var等
其他分区可以挂载到根目录下的任何普通目录上
挂载的作用
Linux中,任何分区创建之后都是不能直接使用的,它们必须挂载在目录上之后,才能通过路径使用分区
因为分区挂载在一个目录下面,那这个分区自己就有路径了,所以这个分区中的所有文件的起始路径就是被挂载的目录
例
一个分区的名字叫做adv3
它挂载到了目录/adv/xyc上
那么,这个分区中的所有文件的路径最开头就是/adv/xyc
所以我们就可以通过从根目录开始的分区自己的路径,找到这个分区中的所有文件,并对它们进行操作了
分区被挂载到一个目录之后,我们cd进入这个目录
之后在这个目录下的文件操作(新建,删除文件)就是在挂载到这个目录的分区中进行的了
所以我们如何确定自己使用的文件在哪一个分区中呢?
只需要看路径的前缀就可以了