Anaconda中配置Pyspark的Spark开发环境
目录
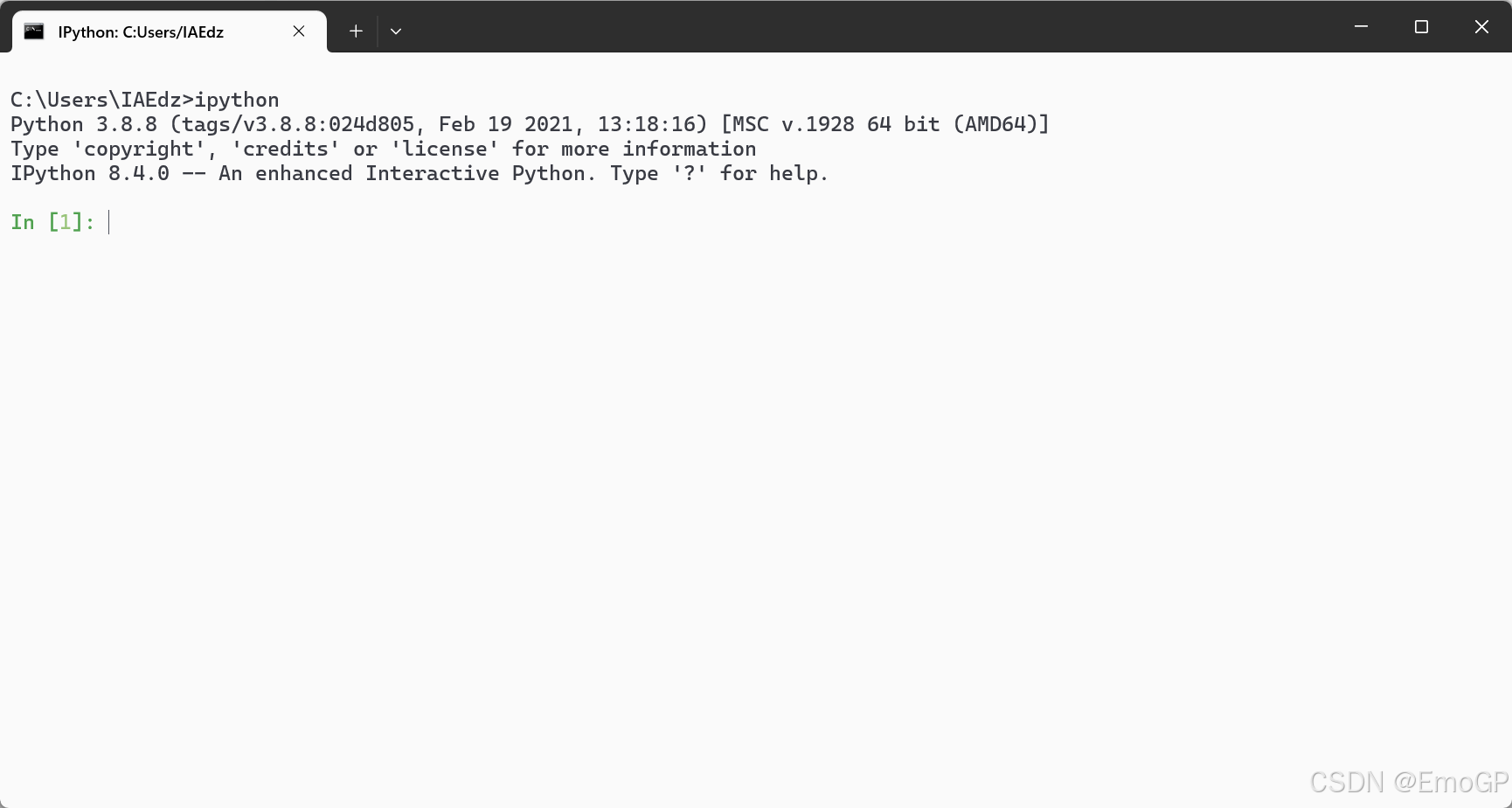
1.在控制台中测试ipython是否启动正常
anaconda正常安装
这里先检查ipython是否正常,cmd命令窗口,输入,ipython,如下就证明可用。
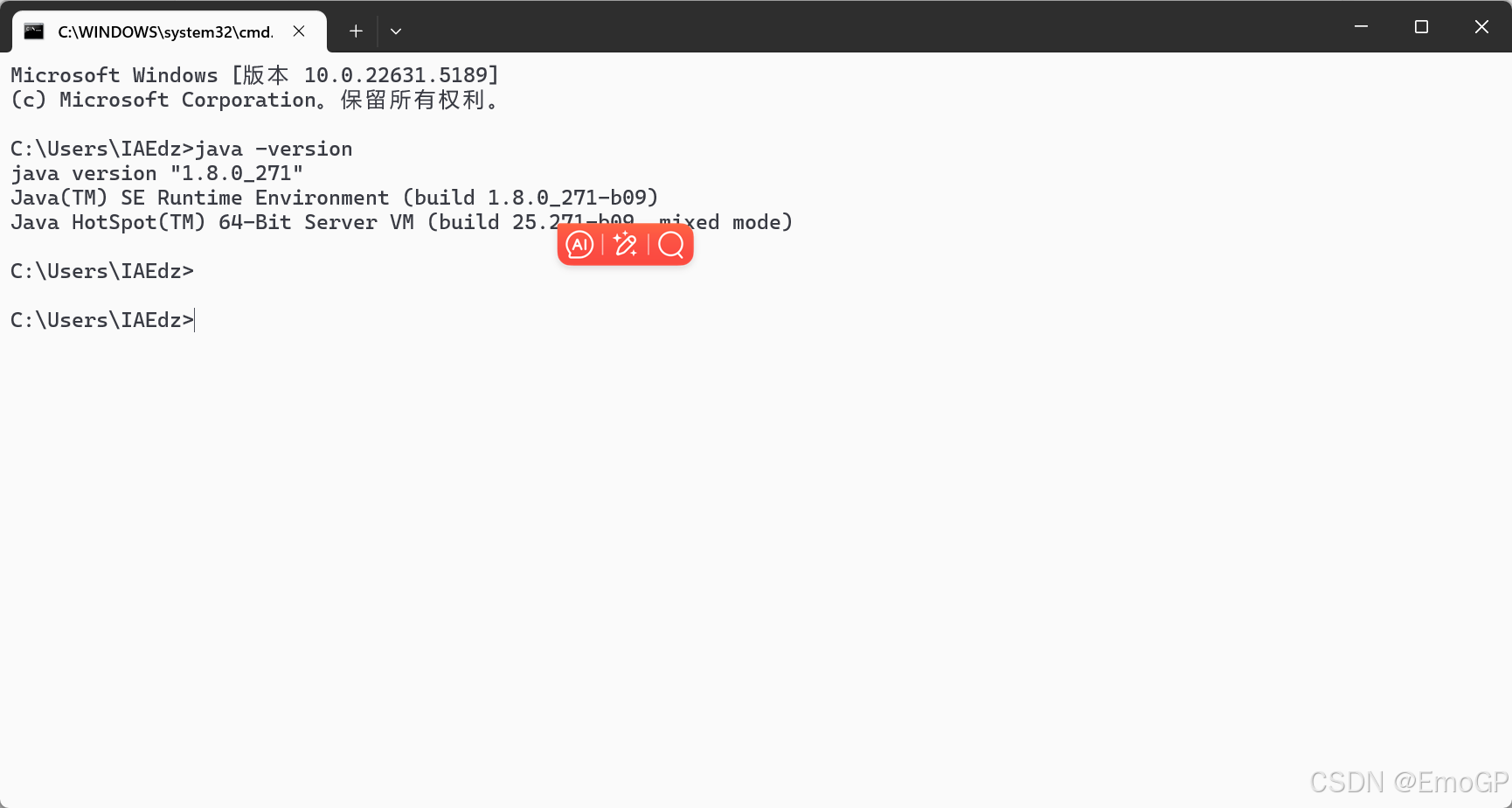
2.安装好Java
测试
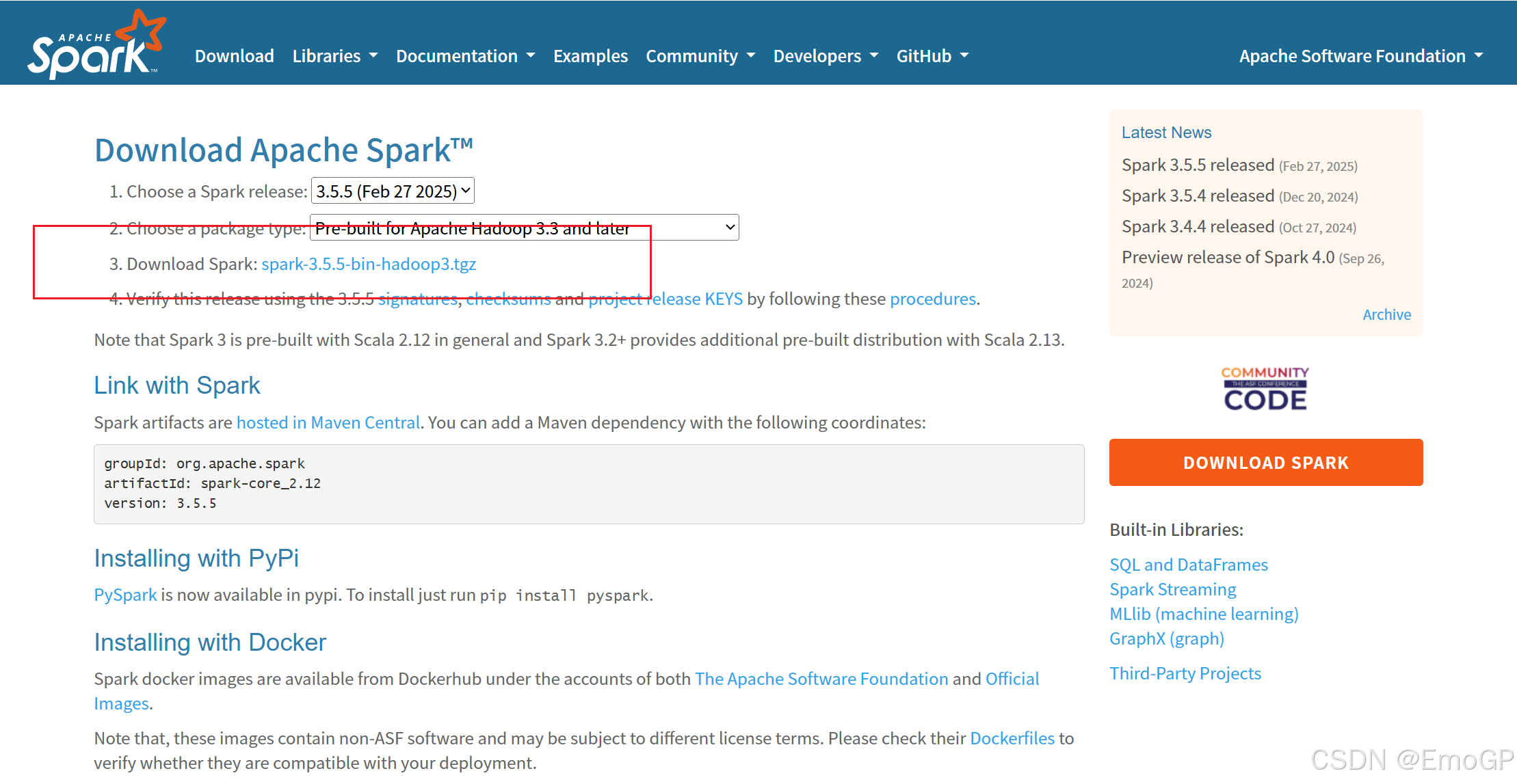
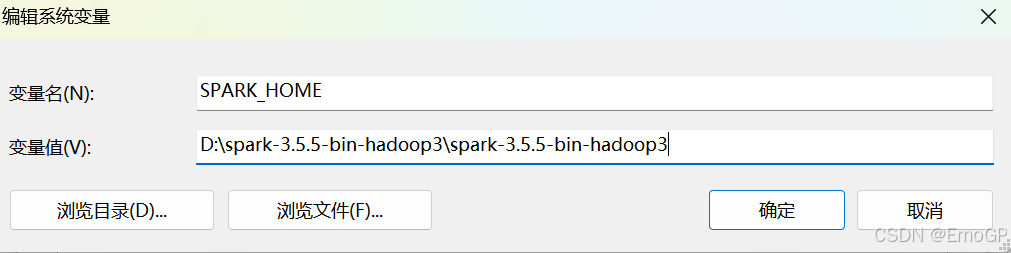
3.安装Spark并配置环境变量
spark 官网地址:https://spark.apache.org/downloads.html
选择需要的版本后安装
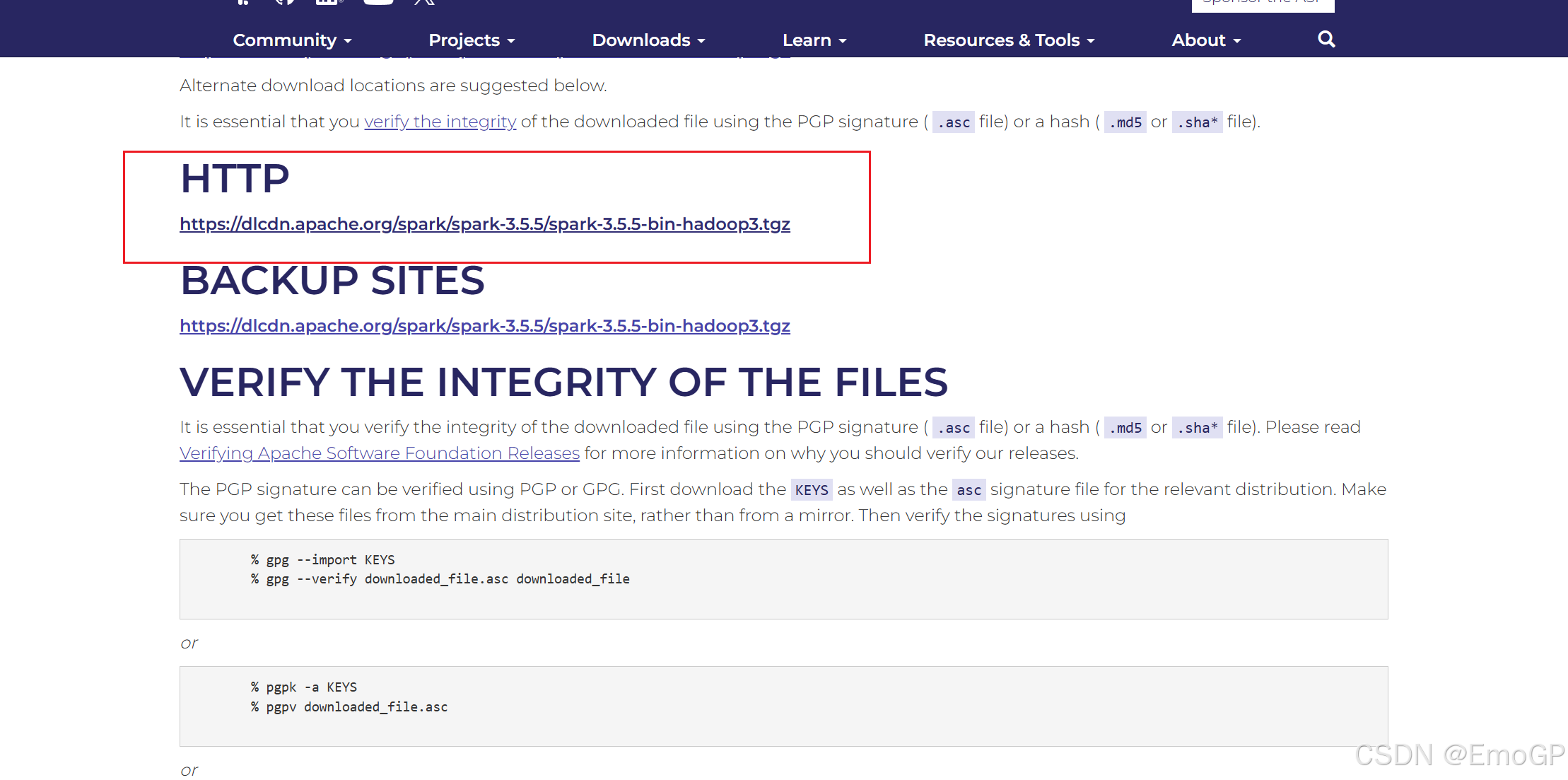
解压:
配置环境变量
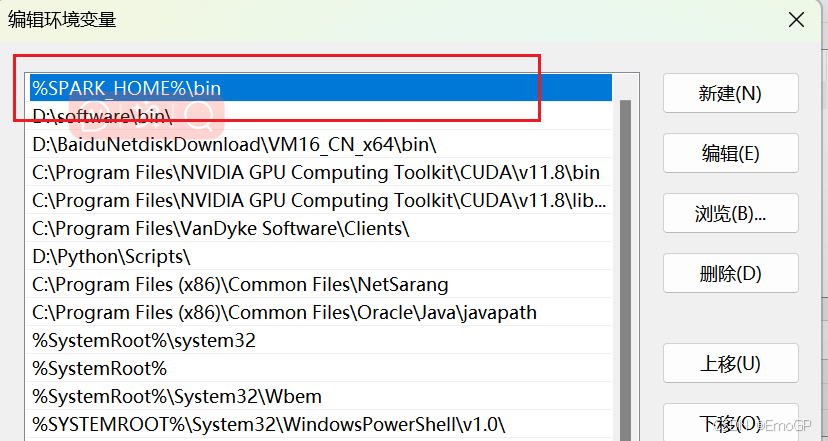
添加到Path:
4.PySpark配置
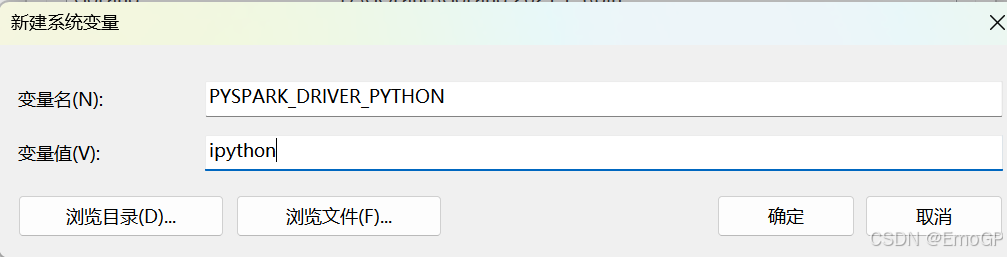
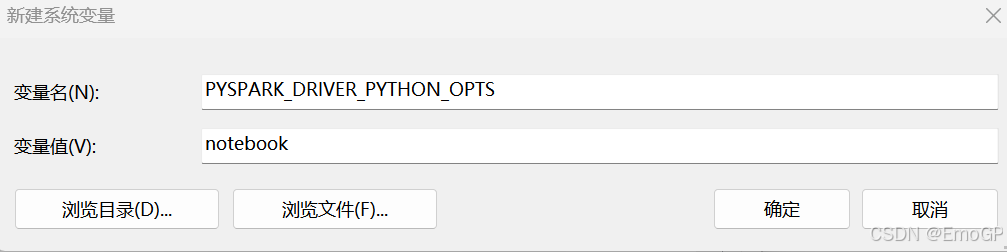
增加:
python
%SPARK_HOME%\python\lib\py4j;%SPARK_HOME%\python\lib\pyspark; 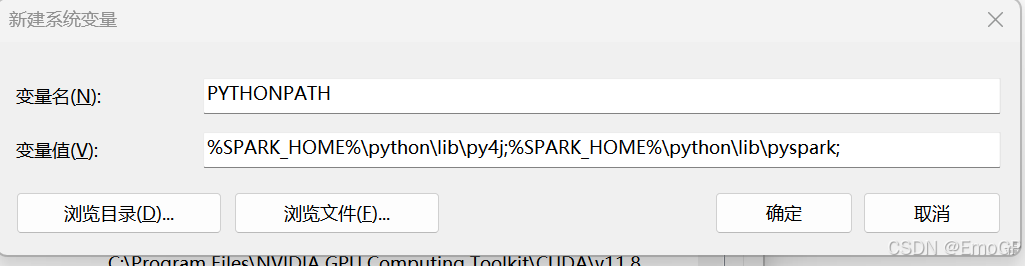
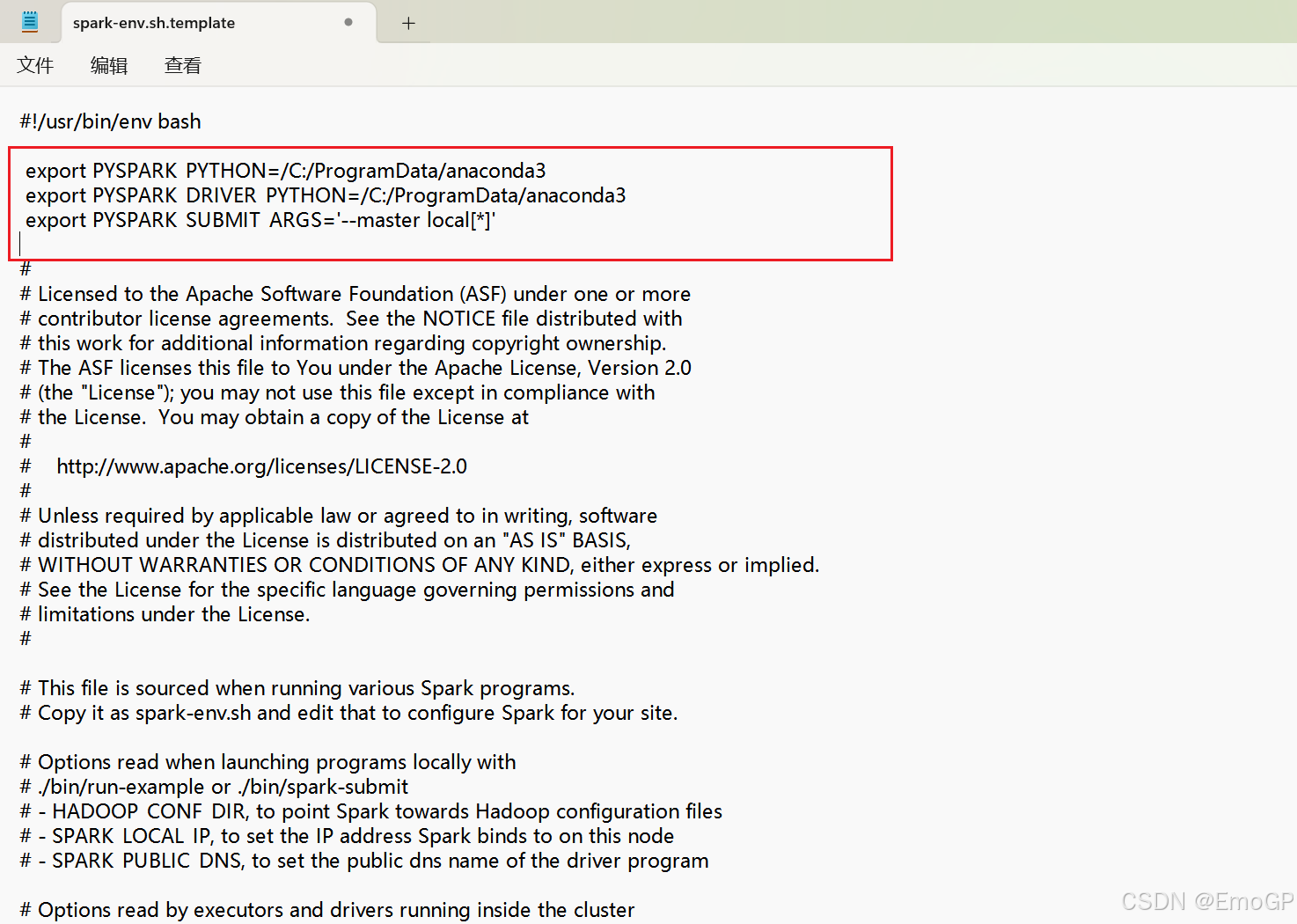
5.修改spark\conf下的spark-env文件
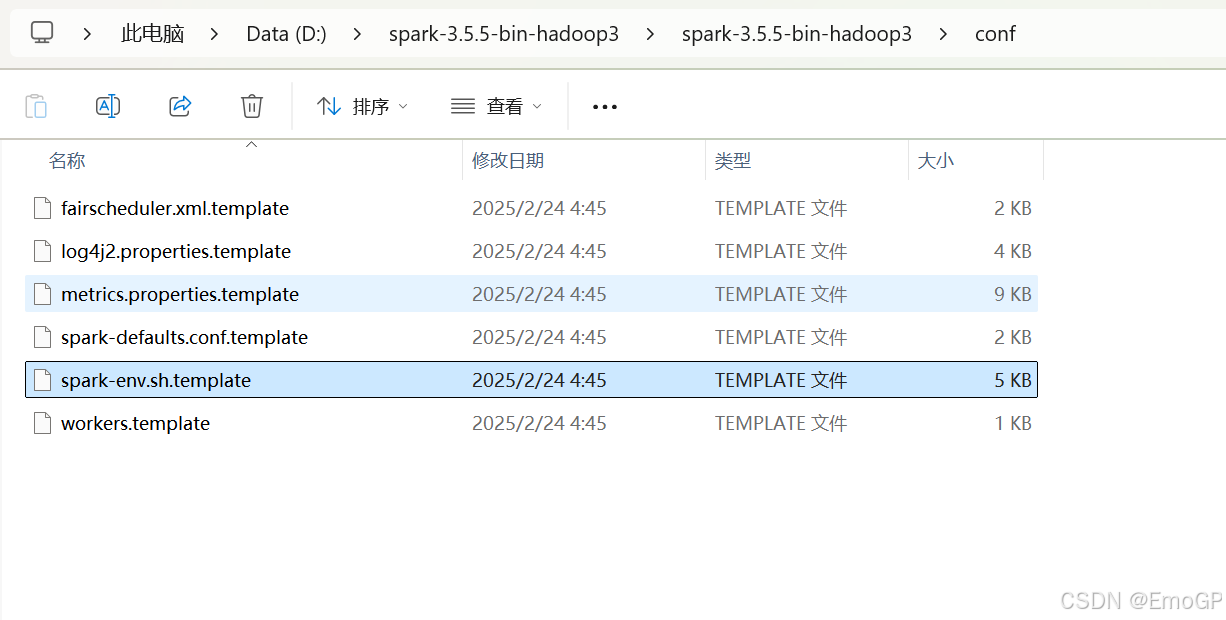
这里路径,写自己的anaconda路径
export PYSPARK_PYTHON=/C:/ProgramData/anaconda3
export PYSPARK_DRIVER_PYTHON=/C:/ProgramData/anaconda3
export PYSPARK_SUBMIT_ARGS='--master local\*'
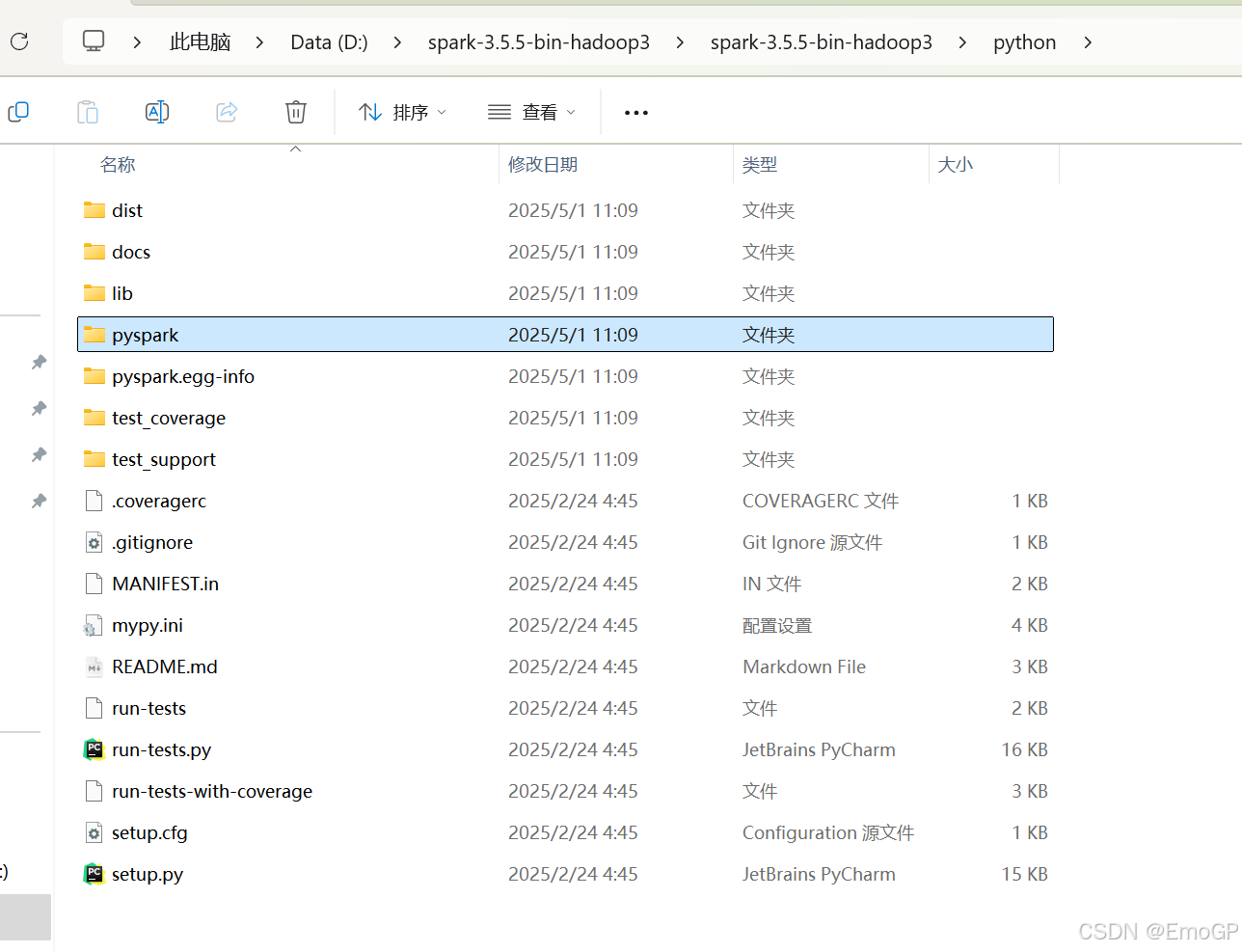
拷贝pyspark到site-packages文件夹下
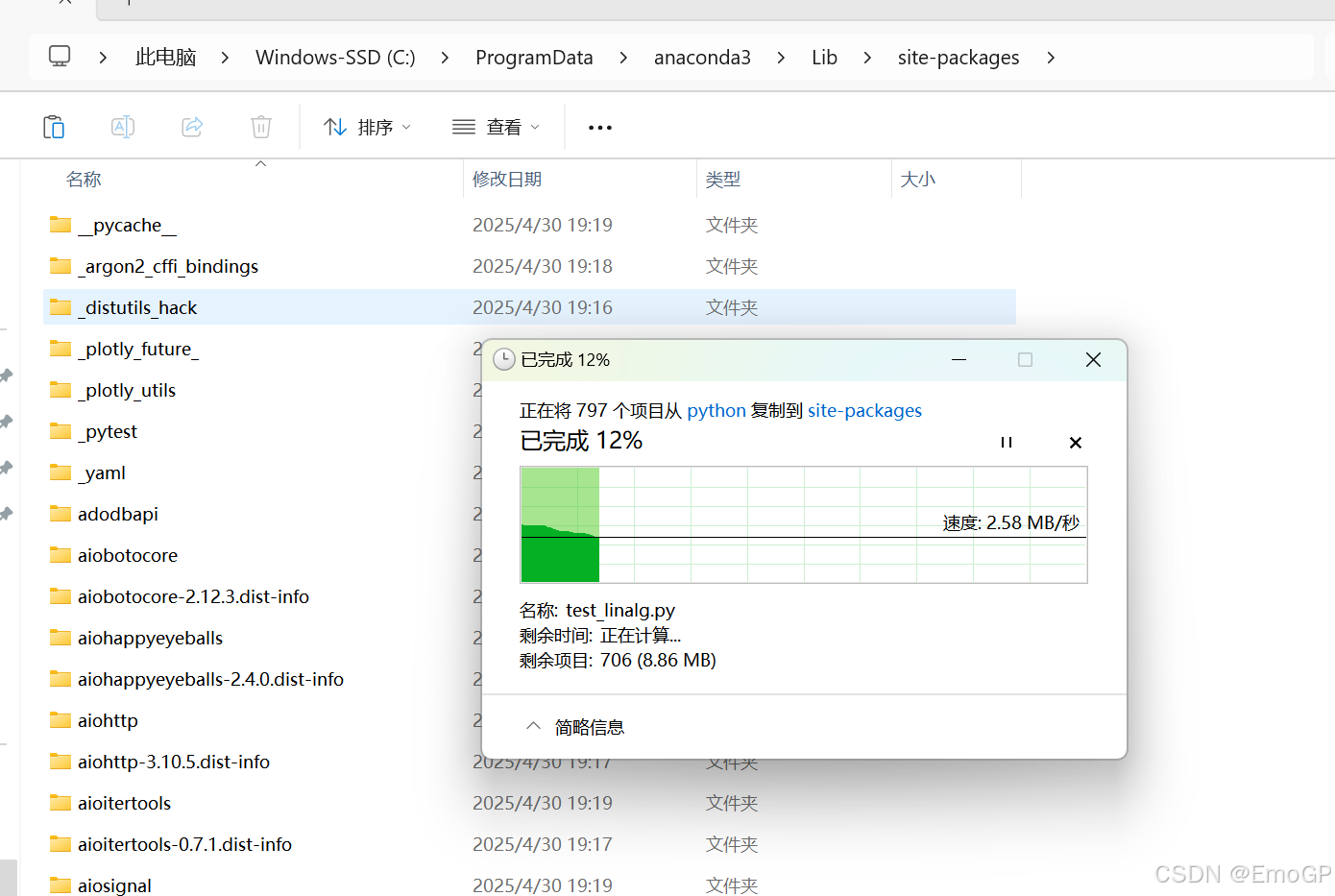
拷贝到自己的anaconda文件下:
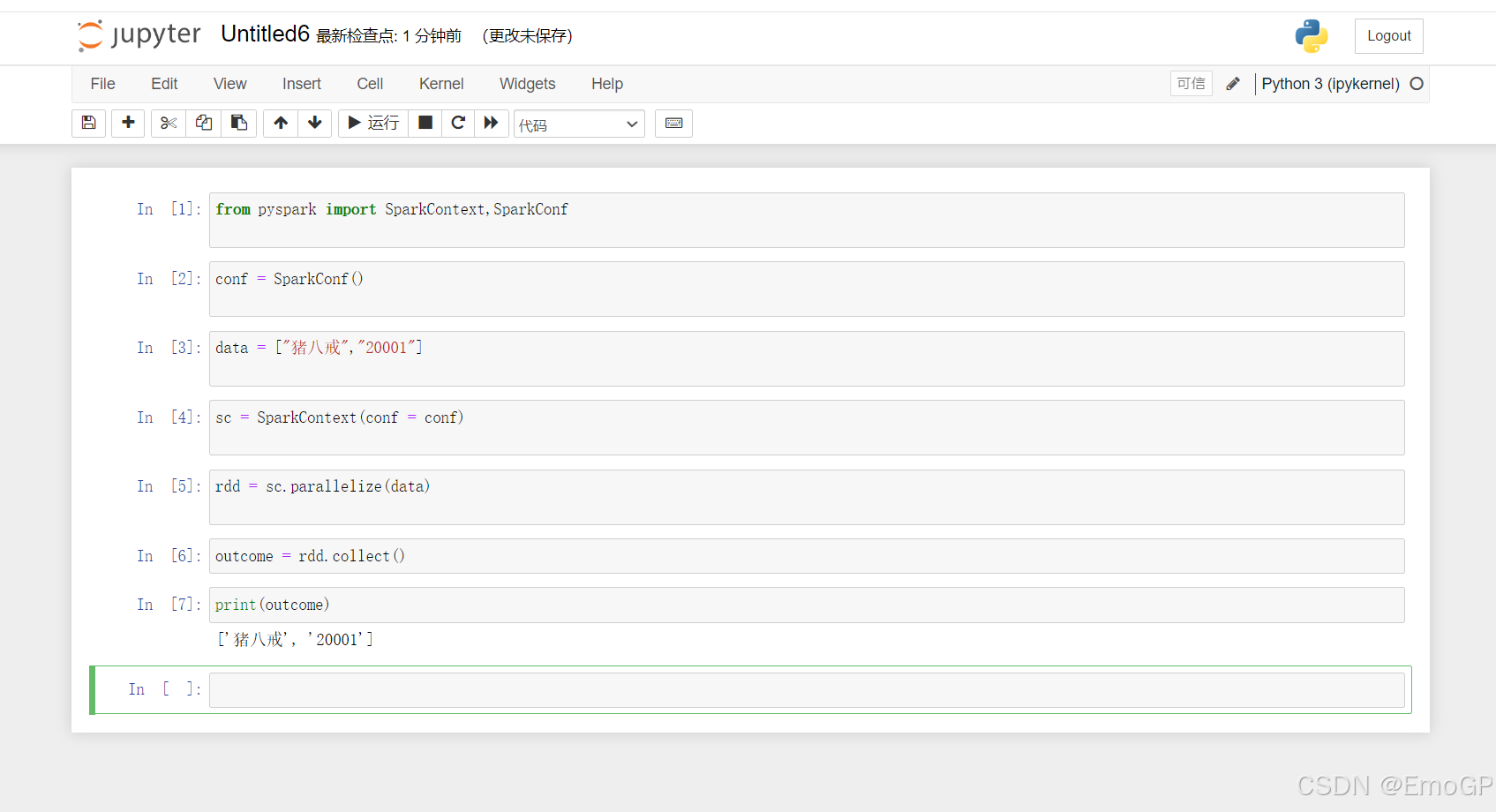
6.测试Pyspark是否安装成功
输入
python
jupyter notebook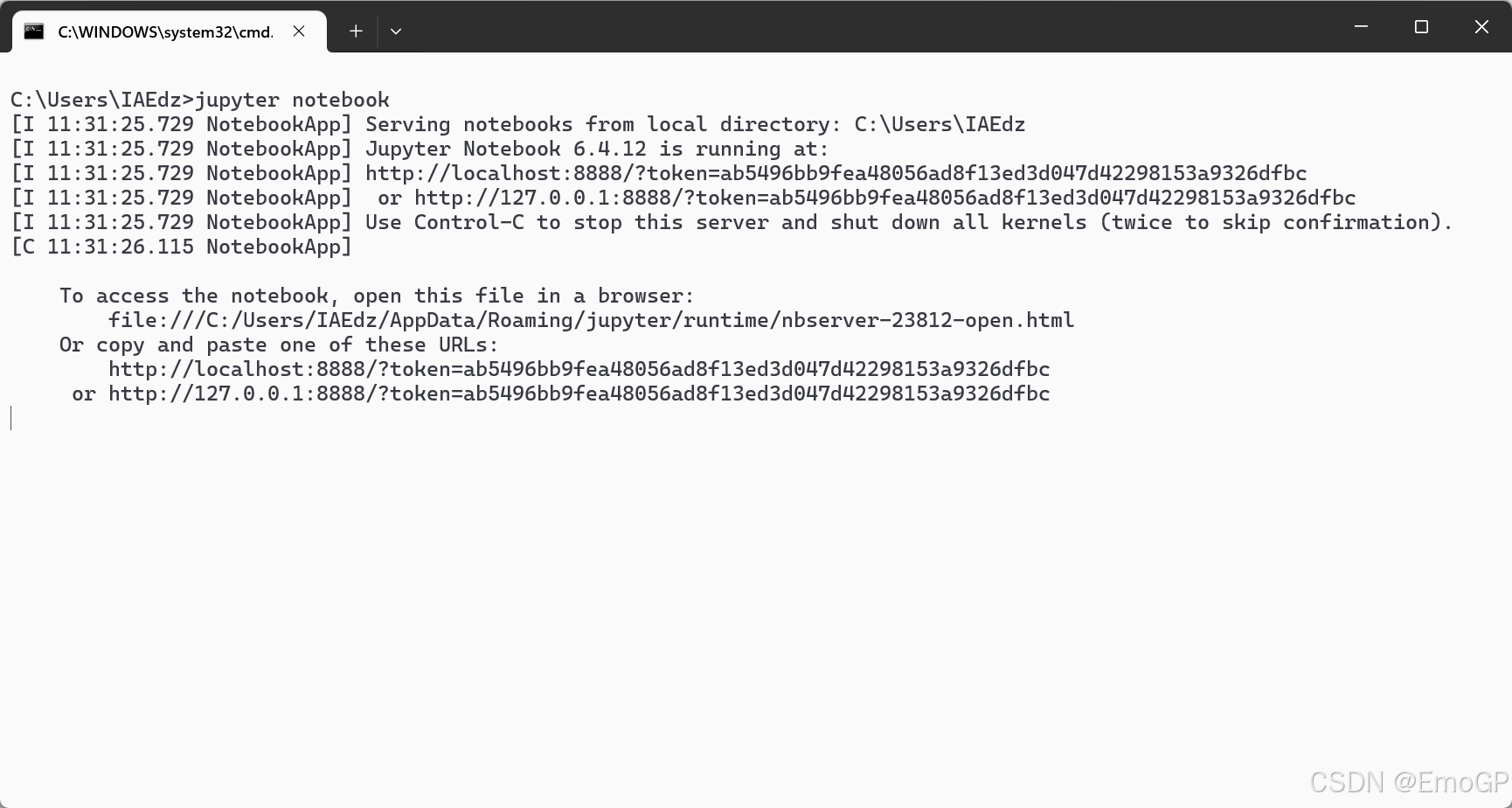
python
from pyspark import SparkContext,SparkConf
conf = SparkConf()
data = ["猪八戒","20001"]
sc = SparkContext(conf = conf)
rdd = sc.parallelize(data)
print(rdd.collect())