通过本次实验,成功搭建了 Hadoop 单机环境并运行了基础 MapReduce 程序,为后续分布式计算学习奠定了基础。
-
掌握 Hadoop 单机模式的安装与配置方法。
-
熟悉 Hadoop 环境变量的配置及 Java 依赖管理。
-
使用 Hadoop 自带的 WordCount 示例程序进行简单的 MapReduce 计算,验证安装是否成功。
环境准备
操作系统:推荐 Linux(如 Ubuntu/CentOS)或 macOS(Windows 需通过 WSL 或虚拟机)
Java 环境:
安装 JDK 1.8+(Hadoop 3.x 需 Java 8 或 11)
如果安装过,需要卸载以前的包,并且删掉环境变量,然后干掉目录
如果未安装过可以直接进行下一步操作
# 查询已安装的 JDK 包
rpm -qa | grep 'java\|jdk\|gcj\|jre'
# 卸载指定包(替换为实际查询结果)
yum -y remove java*
# 修改环境变量,删掉环境那两行
vi /etc/profile
#使其生效
source /etc/profile
# 清空opt目录下面的东西
cd /opt/
rm -rf *安装jdk
1.上传jdk压缩包jdk-8u181-linux-x64.tar.gz
没有的可以前往飞书直接下载我的
2.解压缩后目录如下,删除压缩包节省空间,并改名方便操作
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /opt/
rm -rf jdk-8u181-linux-x64.tar.gz
mv "jdk1.8.0_181" "jdk1.8"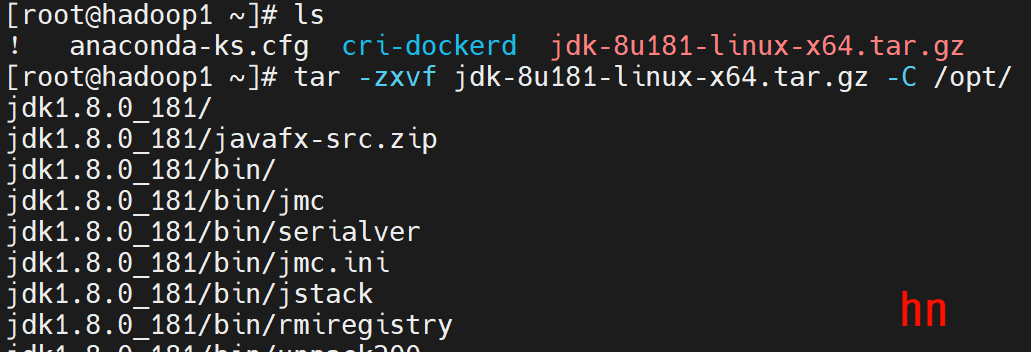
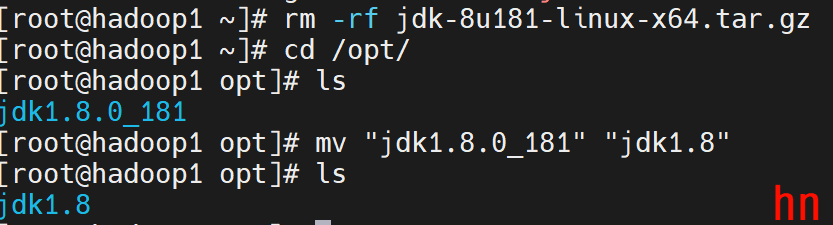
3.配置环境变量
sudo vi /etc/profile
export JAVA_HOME=/opt/jdk1.8 #填写自己的jdk路径
export PATH=$JAVA_HOME/bin:$PATH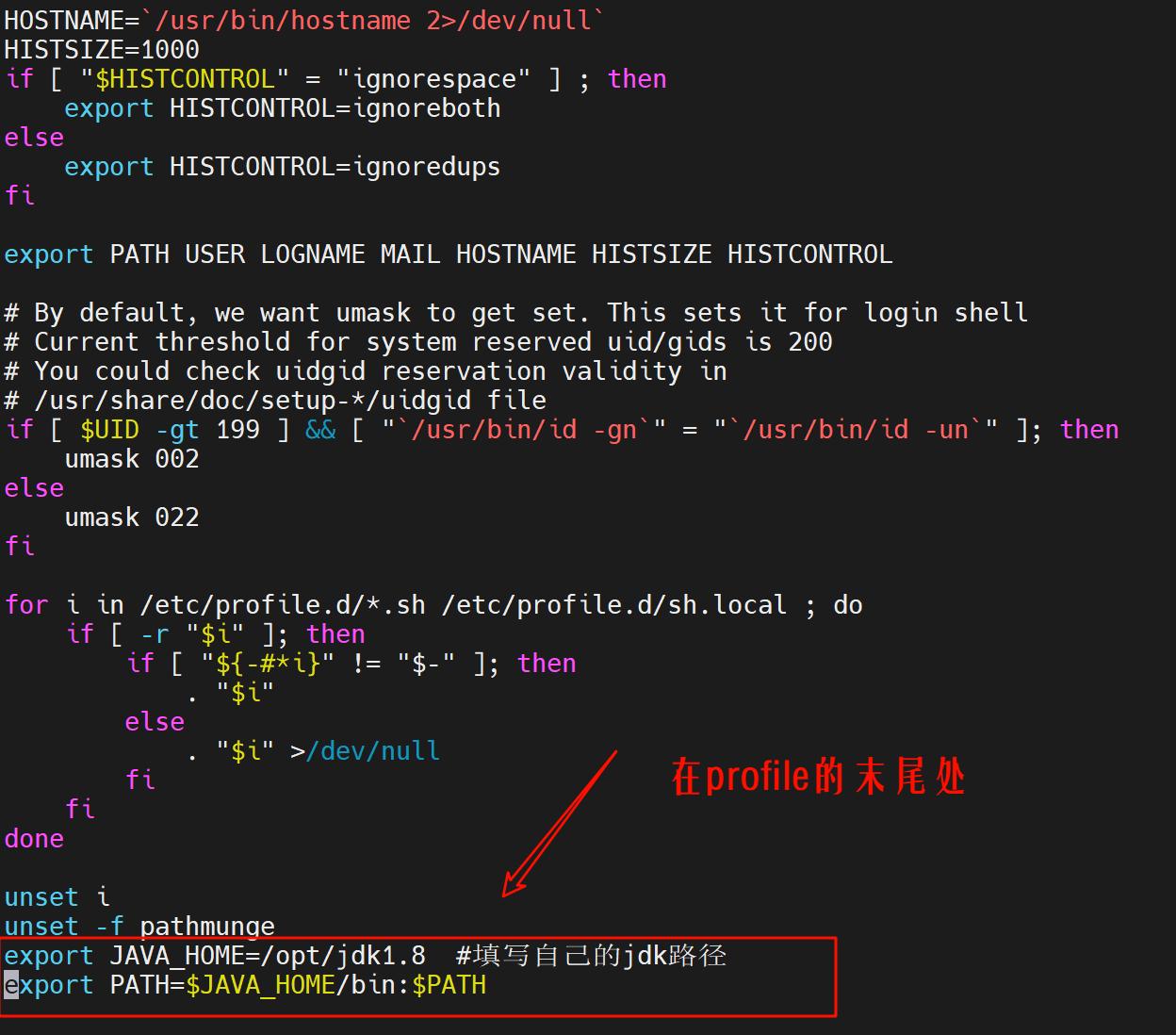
4.环境生效
source /etc/profile5.查看版本确认安装
java -version
安装hadoop
1.没有wegt命令的自行下载
yum -y install wget2.回到opt目录(和jdk一个目录),下载hadoop
cd /opt
wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz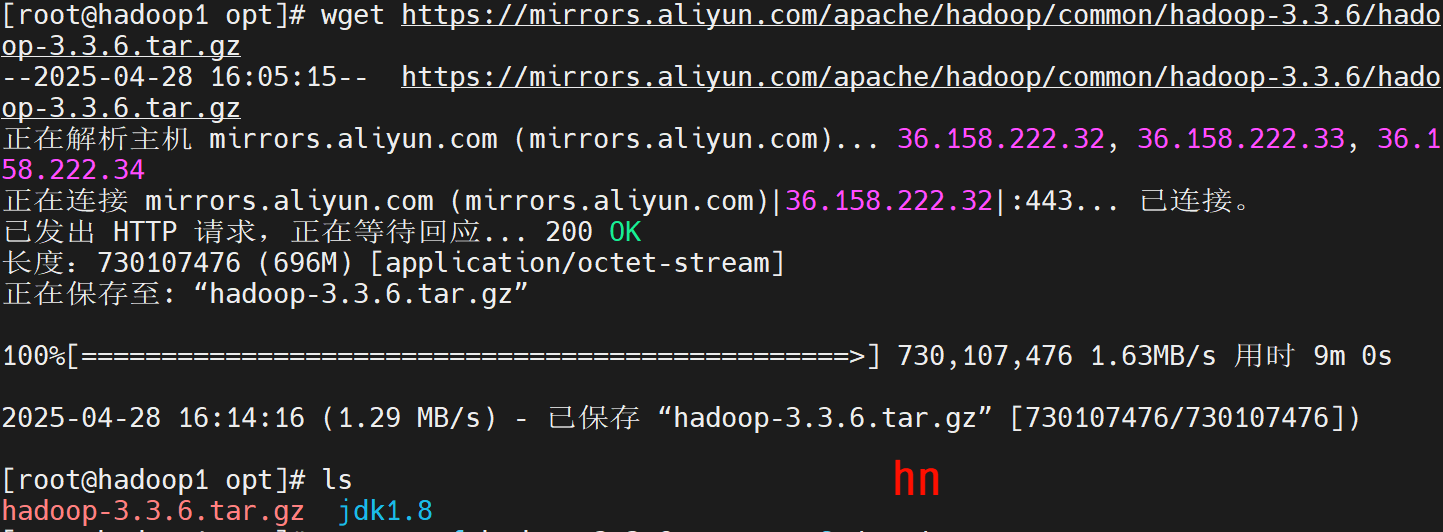
3.检查下载再解压,解压后可以删掉压缩包节省空间,进行改名
# 检查是否wget成功
ls
# 解压缩
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/
# 删除压缩包节省空间
rm -rf hadoop-3.3.6.tar.gz
#修改名字
mv /opt/hadoop-3.3.6 /opt/hadoop
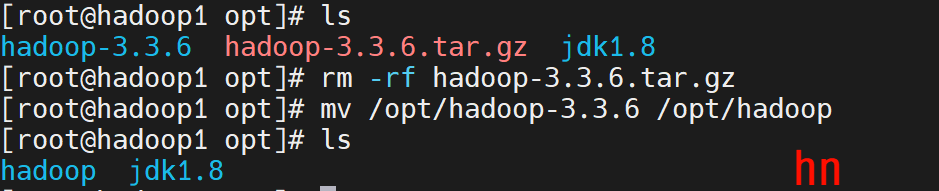
4.配置环境变量,使其生效
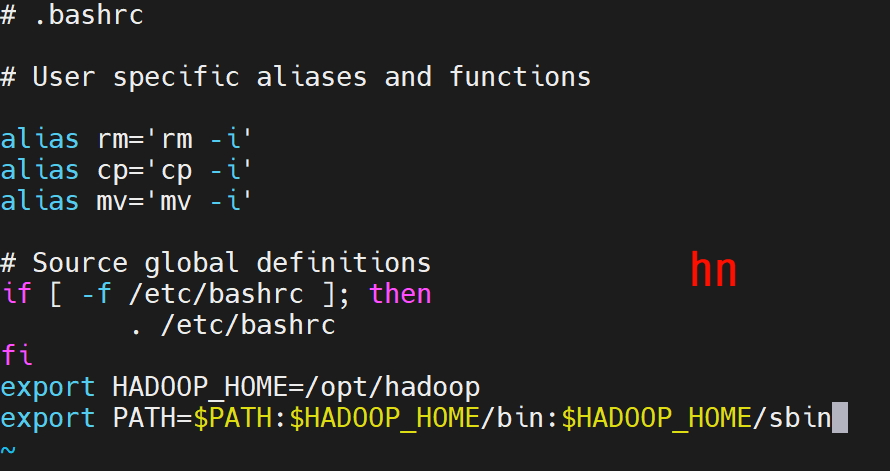
# 配置环境变量(编辑 ~/.bashrc 或 ~/.zshrc)
vim ~/.bashrc
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 使配置生效
source ~/.bashrc
5.检查hadoop版本,验证是否安装成功
hadoop version
进行测试
计算test.txt(计算就是统计文本单词重复出现多少次)
1.创建测试脚本
# 创建输入目录(注意是创建在在root目录下)
mkdir -p ~/hadoop-input
# 写入测试文本
echo "Hello World Hello Hadoop" > ~/hadoop-input/test.txt
# 检查是否写入
cd ~
ls
cd hadoop-input
ls
cat test.txt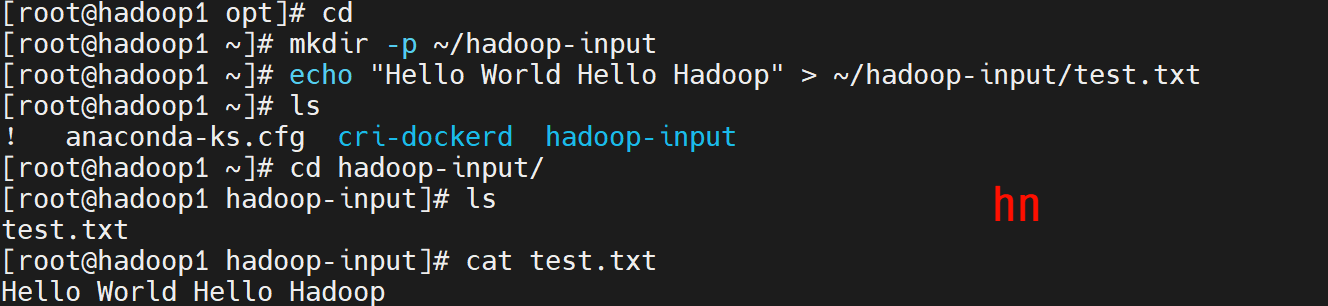
2.查看hadoop提供的案例(只是告诉你hadoop案例放在哪里而已,可以不操作)
cd /opt/hadoop
#查看目录,里面有个share,存放这hadoop的默认案例
cd share/hadoop/mapreduce
ls
-
执行 WordCount,出现successfully字样,此时统计完成
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar
wordcount ~/hadoop-input ~/hadoop-output
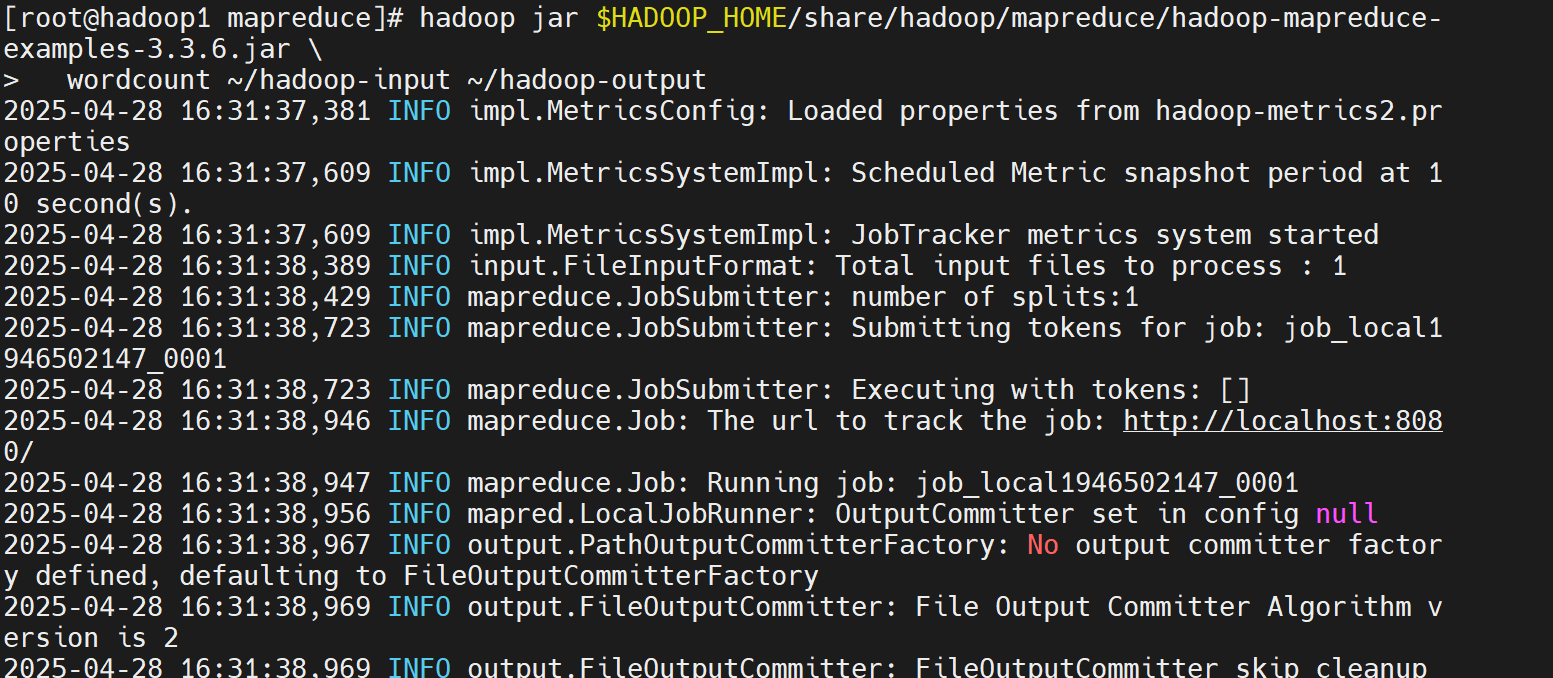
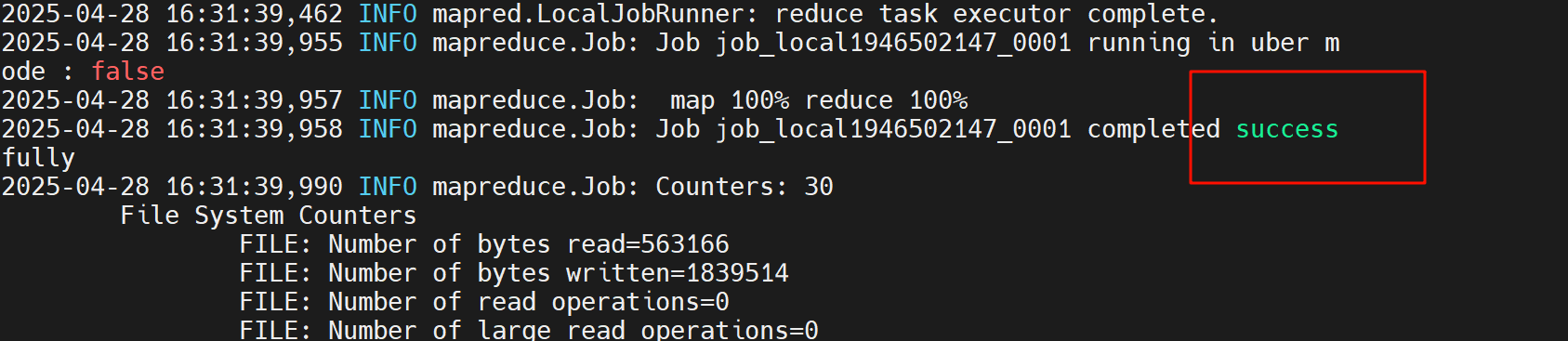
4.查看统计结果
cd ~
cd hadoop-output
ls
cat part-r-00000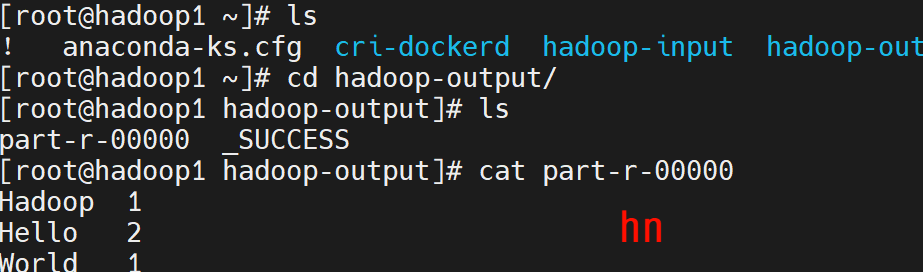
单机部署完成
实验总结
-
成功点:
-
完成 JDK 和 Hadoop 的安装与配置。
-
验证了 Hadoop 单机模式的基本功能(MapReduce 计算)。
-
-
注意事项:
-
需确保环境变量配置正确(如
JAVA_HOME、HADOOP_HOME)。 -
输入/输出目录需提前创建,避免权限问题。
-
-
后续扩展:
-
尝试伪分布式模式(Pseudo-Distributed Mode)部署。
-
使用其他 Hadoop 示例(如
grep、pi)进行测试。
-