目录
[1 Hive Join操作基础](#1 Hive Join操作基础)
[1.1 Join操作的类型与挑战](#1.1 Join操作的类型与挑战)
[1.2 Hive Join执行机制](#1.2 Hive Join执行机制)
[2 MapJoin优化策略](#2 MapJoin优化策略)
[2.1 MapJoin原理](#2.1 MapJoin原理)
[2.2 MapJoin适用场景](#2.2 MapJoin适用场景)
[2.3 MapJoin关键参数](#2.3 MapJoin关键参数)
[3 Sort-Merge Join优化策略](#3 Sort-Merge Join优化策略)
[3.1 Sort-Merge Join原理](#3.1 Sort-Merge Join原理)
[3.2 Sort-Merge Join优势](#3.2 Sort-Merge Join优势)
[3.3 关键配置参数](#3.3 关键配置参数)
[3.4 分桶表优化](#3.4 分桶表优化)
[4 Join优化进阶技巧](#4 Join优化进阶技巧)
[4.1 数据倾斜处理](#4.1 数据倾斜处理)
[4.2 Join顺序优化](#4.2 Join顺序优化)
[4.3 多表Join优化](#4.3 多表Join优化)
[5 监控与调优验证](#5 监控与调优验证)
[5.1 执行计划分析](#5.1 执行计划分析)
[5.2 性能指标监控](#5.2 性能指标监控)
[6 总结](#6 总结)
前言
在Hive查询中,Join操作是最消耗资源的操作之一,尤其是在处理大数据量时。合理的Join策略选择能显著提升查询性能,减少资源消耗。本文将深入探讨Hive中两种核心Join优化策略:MapJoin(小表驱动大表)和Sort-Merge Join,通过原理分析、配置参数以了解Hive Join性能调优的精髓。
1 Hive Join操作基础
1.1 Join操作的类型与挑战
Hive支持多种Join类型,包括:
- Inner Join
- Left Outer Join
- Right Outer Join
- Full Outer Join
- Cross Join

大数据Join面临的挑战:
- 数据倾斜:某些Key的数据量远大于其他Key
- 网络传输:节点间数据Shuffle消耗大
- 内存压力:大表Join时内存容易溢出
- 计算复杂度:笛卡尔积导致计算量爆炸
1.2 Hive Join执行机制
- Hive执行Join的基本流程:

Join策略选择是查询优化的重要环节,直接影响执行效率。
2 MapJoin优化策略
2.1 MapJoin原理
MapJoin又称Broadcast Join,其核心思想是将小表完全加载到内存中,在Map阶段完成Join操作,避免Reduce阶段的Shuffle。
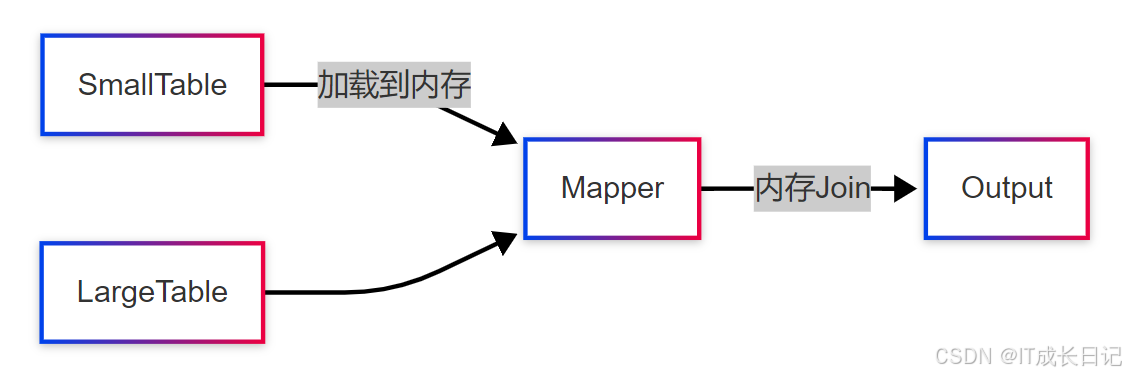
工作流程:
- 本地任务读取小表数据到内存哈希表
- 分布式读取大表数据
- 在Map阶段直接完成Join
- 输出结果
2.2 MapJoin适用场景
2.3 MapJoin关键参数
|-----------------------------------------------|----------|----------------|
| 参数 | 默认值 | 说明 |
| hive.auto.convert.join | true | 是否自动转换MapJoin |
| hive.mapjoin.smalltable.filesize | 25000000 | 小表阈值(25MB) |
| hive.auto.convert.join.noconditionaltask | true | 是否启用多表MapJoin |
| hive.auto.convert.join.noconditionaltask.size | 10000000 | 多表MapJoin总大小阈值 |
-
示例:
-- 设置MapJoin阈值100MB
SET hive.mapjoin.smalltable.filesize=104857600;
-- 强制启用MapJoin
SET hive.auto.convert.join=true;
3 Sort-Merge Join优化策略
3.1 Sort-Merge Join原理
Sort-Merge Join是一种基于排序的分布式Join算法,适合大表间Join的场景。
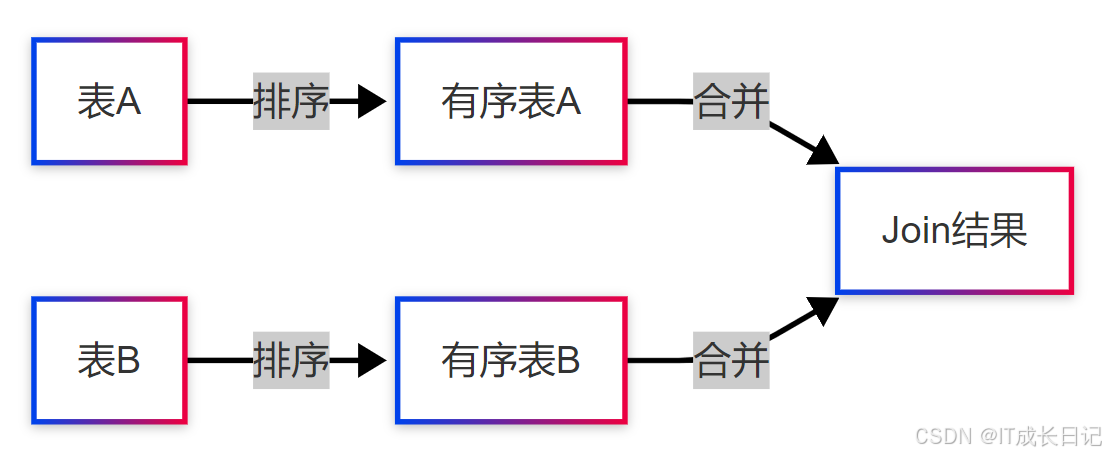
- 排序阶段:对两表按Join Key排序
- 合并阶段:并行扫描已排序的表,匹配相同Key的记录
3.2 Sort-Merge Join优势
- 适合大表间Join
- 内存消耗可控
- 减少网络传输(预排序后只需单次Shuffle)
- 天然解决数据倾斜问题
3.3 关键配置参数
|-----------------------------------------|-------|-----------------------|
| 参数 | 默认值 | 说明 |
| hive.auto.convert.sortmerge.join | true | 是否自动转换Sort-Merge Join |
| hive.optimize.bucketmapjoin.sortedmerge | false | 是否对分桶表使用优化 |
| hive.enforce.sortmergebucketmapjoin | false | 是否强制使用分桶排序Join |
| hive.sortmerge.join.tasks | -1 | 合并阶段任务数 |
-
示例:
-- 启用Sort-Merge Join
SET hive.auto.convert.sortmerge.join=true;
-- 设置合并任务数
SET hive.sortmerge.join.tasks=100;
3.4 分桶表优化
对于分桶表,可以进一步优化Sort-Merge Join:
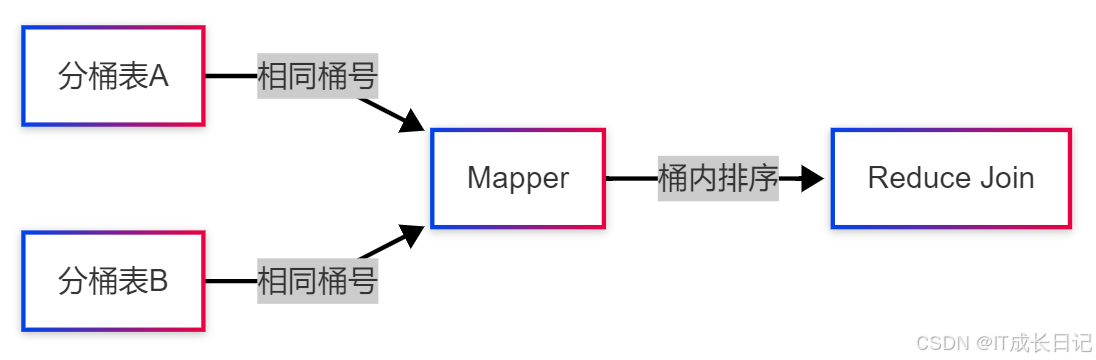
优化条件:
- 两表都是分桶表
- 分桶数量相同
- Join Key是分桶列
- 分桶已排序
4 Join优化进阶技巧
4.1 数据倾斜处理
-
倾斜识别:
-- 检查Key分布
SELECT key, COUNT()
FROM table
GROUP BY key
ORDER BY COUNT() DESC
LIMIT 10;
解决方案:
- MapJoin:将倾斜Key单独处理
-
随机前缀:分散倾斜Key
-- 对倾斜Key添加随机前缀
SELECT * FROM A a JOIN (
SELECT
CASE WHEN id = 'skew_key' THEN concat(id, '', floor(rand()*10))
ELSE id END AS id,
value
FROM B
) b ON a.id = b.id OR a.id = split(b.id, '')[0];
4.2 Join顺序优化
Hive默认按照FROM子句中表的顺序执行Join,可通过以下方式优化:

-
配置参数:
SET hive.auto.convert.join=true;
SET hive.auto.convert.join.noconditionaltask=true;
SET hive.auto.convert.join.noconditionaltask.size=100000000;
4.3 多表Join优化
对于多表Join,Hive提供星型转换优化:
-- 启用星型Join优化
SET hive.optimize.ppd.star=true;
SET hive.optimize.ppd=true;5 监控与调优验证
5.1 执行计划分析
EXPLAIN FORMATTED
SELECT a.id, b.value
FROM table_a a JOIN table_b b ON a.id = b.id;关注执行计划中的:
- Join Operator
- Map Join Operator
- condition mapjoin
5.2 性能指标监控
|------------|----------|--------|
| 指标 | 说明 | 优化目标 |
| Join时间 | Join阶段耗时 | 减少50%+ |
| Shuffle数据量 | 网络传输量 | 最小化 |
| 内存使用 | 峰值内存 | 避免OOM |
6 总结
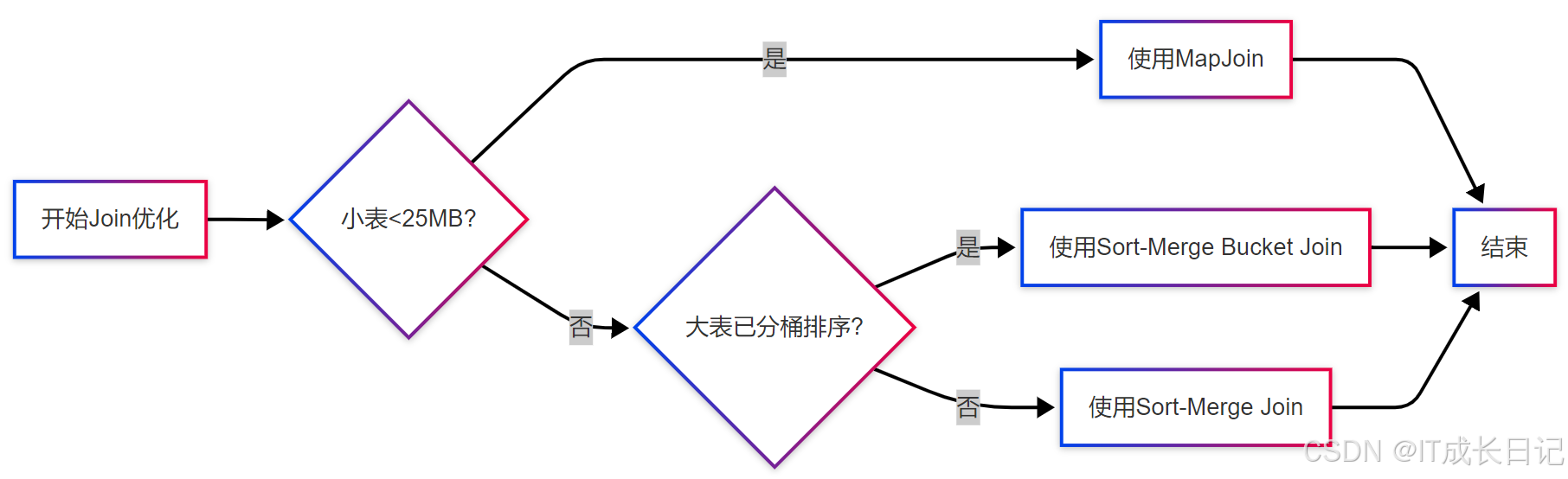
-
小表Join:优先使用MapJoin
SET hive.auto.convert.join=true;
SET hive.mapjoin.smalltable.filesize=256000000; -- 256MB -
大表Join:使用Sort-Merge Join
SET hive.auto.convert.sortmerge.join=true;
SET hive.optimize.bucketmapjoin.sortedmerge=true; -
分桶表:预先分桶排序
CREATE TABLE ... CLUSTERED BY (key) SORTED BY (key) INTO 64 BUCKETS;
-
数据倾斜:单独处理倾斜Key
SET hive.optimize.skewjoin=true;
SET hive.skewjoin.key=100000; -
监控验证:定期检查执行计划
EXPLAIN FORMATTED SELECT ...;
通过合理运用MapJoin和Sort-Merge Join策略,结合本文提供的配置参数和优化技巧,可以显著提升Hive查询性能,特别是在大数据量Join场景下。实际应用中应根据数据特征和集群资源灵活调整参数,持续监控优化效果。