文章目录
- 引言:从二分类到多分类
- 一、多分类问题无处不在
- 二、One-vs-All策略揭秘
-
- [1. 核心思想](#1. 核心思想)
- [2. 数学表达](#2. 数学表达)
- 三、鸢尾花分类完整实现
-
- [1. 环境准备](#1. 环境准备)
- [2. 数据加载与探索](#2. 数据加载与探索)
- [3. 数据预处理](#3. 数据预处理)
- [4. 模型训练与评估](#4. 模型训练与评估)
- [5. 决策边界可视化](#5. 决策边界可视化)
- 四、关键参数解析
- 五、总结
引言:从二分类到多分类
- 逻辑回归是机器学习中最基础也最重要的算法之一,但初学者常常困惑:逻辑回归明明是二分类算法,如何能处理多分类问题呢?本文将带你深入了解逻辑回归的多分类策略,并通过完整的鸢尾花分类代码实现。
一、多分类问题无处不在
- 在我们的日常生活和工作中,多分类问题比比皆是:
- 邮件分类:工作(y=1)、朋友(y=2)、家庭(y=3)、爱好(y=4)
- 天气预测:晴天(y=1)、多云(y=2)、雨天(y=3)、雪天(y=4)
- 医疗诊断:健康(y=1)、感冒(y=2)、流感(y=3)
这些场景都需要算法能够区分多个类别,而逻辑回归通过巧妙的扩展就能胜任这些任务。
二、One-vs-All策略揭秘
1. 核心思想
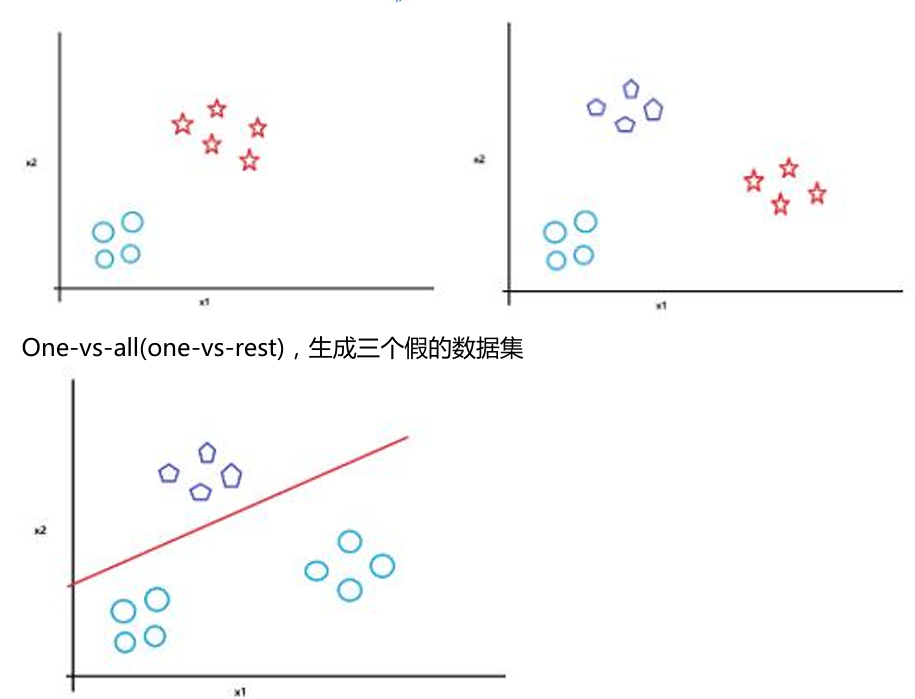
- One-vs-All(一对多,也称为One-vs-Rest)策略将多分类问题转化为多个二分类问题:
- 对于N个类别,训练N个独立的二分类器
- 第i个分类器将第i类作为正类,其余所有类别作为负类
- 预测时,选择所有分类器中预测概率最高的类别
2. 数学表达
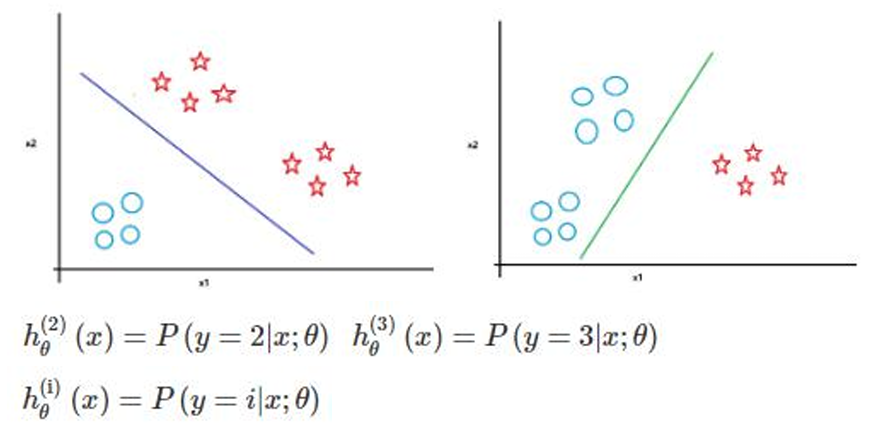
对于第i类,我们的假设函数为:
h θ ( i ) ( x ) = P ( y = i ∣ x ; θ ) h_\theta^{(i)}(x) = P(y = i|x;\theta) hθ(i)(x)=P(y=i∣x;θ)
预测时选择:
max i h θ ( i ) ( x ) \max_i h_\theta^{(i)}(x) imaxhθ(i)(x)
三、鸢尾花分类完整实现
- 使用Python和scikit-learn库完整实现鸢尾花的多分类任务。
1. 环境准备
python
# 导入必要的库
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import (accuracy_score,
confusion_matrix,
classification_report)
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import StandardScaler2. 数据加载与探索
python
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 或 'Microsoft YaHei'
plt.rcParams['axes.unicode_minus'] = False
# 加载鸢尾花数据集
iris = load_iris()
# 特征名称: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# sepal length:花萼长度 sepal width:花萼宽度 petal length: 花瓣长度 petal width: 花瓣宽度
X = iris.data # 特征矩阵 (150, 4)
# 目标类别: ['setosa' 'versicolor' 'virginica']
# setosa 山鸢尾 versicolor 变色鸢尾 virginica 维吉尼亚鸢尾
y = iris.target # 标签 (150,)
# 查看特征名称和目标类别
print("特征名称:", iris.feature_names)
print("目标类别:", iris.target_names)
# 将数据转换为DataFrame便于可视化
iris_df = pd.DataFrame(X, columns=iris.feature_names)
iris_df['species'] = y
iris_df['species'] = iris_df['species'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})
# 绘制特征分布图
sns.pairplot(iris_df, hue='species', palette='husl')
plt.suptitle("鸢尾花特征分布", y=1.02)
plt.show()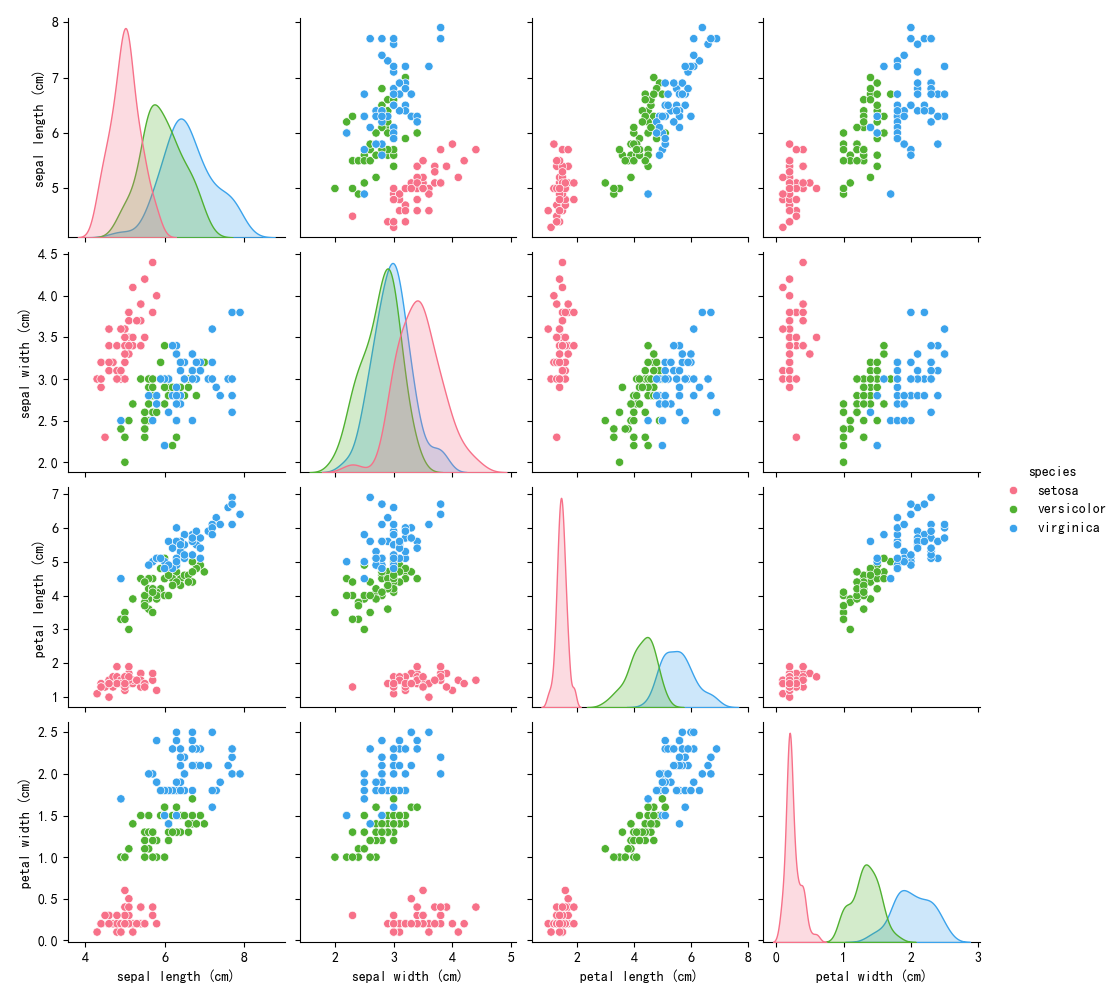
bash
特征名称: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
目标类别: ['setosa' 'versicolor' 'virginica']3. 数据预处理
python
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
print(f"训练集样本数: {len(X_train)}")
print(f"测试集样本数: {len(X_test)}")
# 特征标准化(逻辑回归通常需要)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
bash
训练集样本数: 120
测试集样本数: 304. 模型训练与评估
python
# 构建逻辑回归模型
log_reg = LogisticRegression(
C=1000, # 正则化强度的倒数
solver='sag', # 随机平均梯度下降
max_iter=1000, # 最大迭代次数
random_state=42
)
# 使用 OneVsRestClassifier 包装
ovr_classifier = OneVsRestClassifier(log_reg)
# 训练模型
ovr_classifier.fit(X_train, y_train)
# 在训练集和测试集上评估
train_acc = ovr_classifier.score(X_train, y_train)
test_acc = ovr_classifier.score(X_test, y_test)
print(f"训练集准确率: {train_acc:.2%}")
print(f"测试集准确率: {test_acc:.2%}")
# 更详细的评估报告
y_pred = ovr_classifier.predict(X_test)
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(6,6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=iris.target_names,
yticklabels=iris.target_names)
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('混淆矩阵')
plt.show()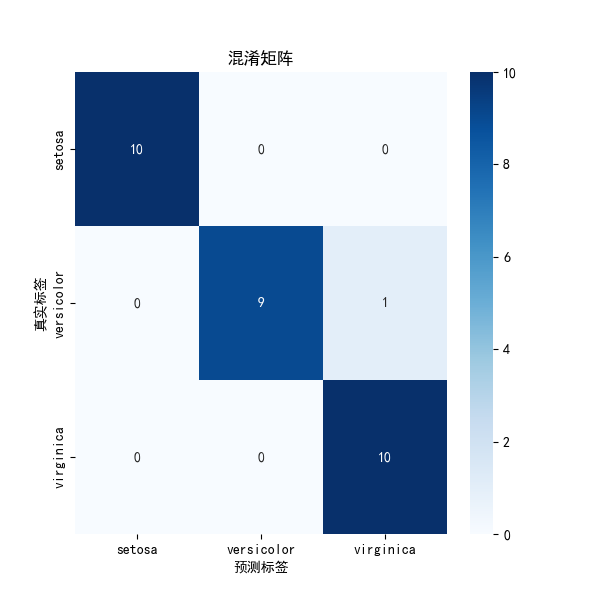
bash
训练集准确率: 96.67%
测试集准确率: 96.67%
分类报告:
precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 1.00 0.90 0.95 10
virginica 0.91 1.00 0.95 10
accuracy 0.97 30
macro avg 0.97 0.97 0.97 30
weighted avg 0.97 0.97 0.97 305. 决策边界可视化
python
# 为可视化,只使用两个主要特征
X_train_2d = X_train[:, :2]
X_test_2d = X_test[:, :2]
# 重新训练一个2D模型
log_reg_2d = LogisticRegression(
C=1000,
solver='sag',
max_iter=2000,
random_state=42
)
ovr_classifier_2d = OneVsRestClassifier(log_reg_2d)
ovr_classifier_2d.fit(X_train_2d, y_train) # 必须先训练模型
# 创建网格点
x_min, x_max = X_train_2d[:, 0].min() - 1, X_train_2d[:, 0].max() + 1
y_min, y_max = X_train_2d[:, 1].min() - 1, X_train_2d[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
# 预测每个网格点的类别
Z = ovr_classifier_2d.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 预测每个网格点的类别
Z = ovr_classifier_2d.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界
plt.figure(figsize=(10, 6))
plt.contourf(xx, yy, Z, alpha=0.4, cmap='Pastel2')
scatter = plt.scatter(X_train_2d[:, 0], X_train_2d[:, 1], c=y_train,
cmap='Dark2', edgecolor='black')
# 添加图例和标签
legend_elements = scatter.legend_elements()[0]
plt.legend(legend_elements,iris.target_names,title="鸢尾花种类")
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.title("逻辑回归多分类决策边界")
plt.show()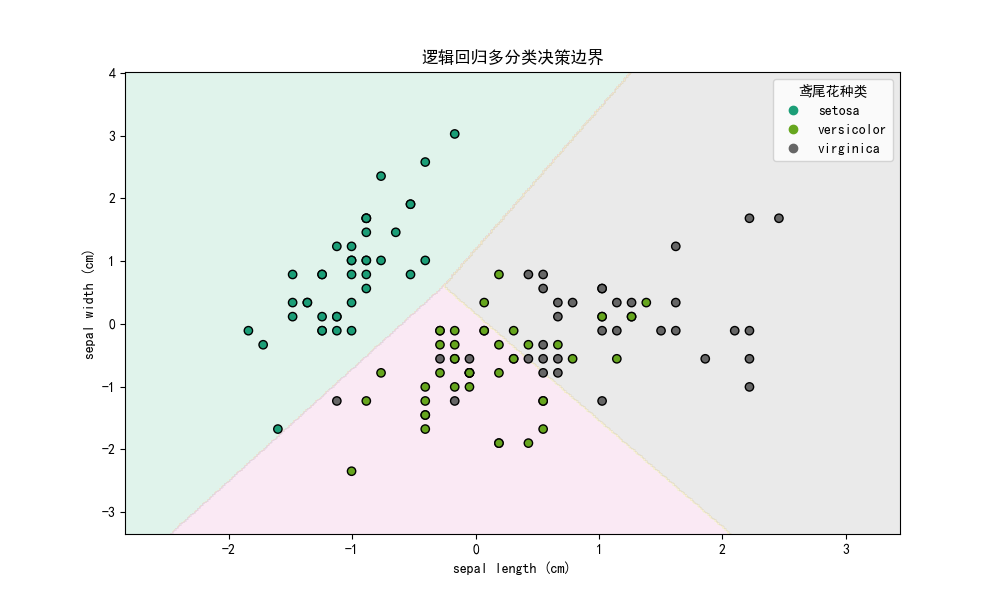
四、关键参数解析
在构建逻辑回归模型时的重要参数:
- C=1000:正则化强度的倒数,较小的值表示更强的正则化。这里设为较大的值,相当于减少正则化。
- multi_class='ovr':指定使用One-vs-Rest策略处理多分类问题。scikit-learn还支持'multinomial'选项,使用softmax函数直接进行多分类。
- solver='sag':优化算法选择随机平均梯度下降(Stochastic Average Gradient),适合大数据集。其他可选算法包括:'liblinear':适合小数据集;'newton-cg':牛顿法;'lbfgs':拟牛顿法。
- max_iter=1000:最大迭代次数,确保模型能够收敛。
五、总结
- 逻辑回归如何通过One-vs-All策略处理多分类问题
- 完整的鸢尾花分类实现流程
- 模型评估与可视化方法