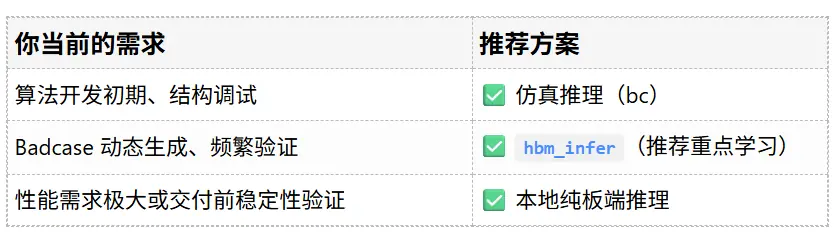
在模型结构优化与部署量化过程中,开发者往往会遇到一个关键任务:基于历史 Badcase 数据验证模型精度变化,确保模型修改不会引入明显性能退化。 这类验证常见于感知、预测、行为识别等任务,尤其在客户交付或精度回归过程中十分关键。
但实际场景中,Badcase 的来源和管理非常复杂:
- 数据常常分散在客户服务器;
- 有些数据是动态生成、无法导出;
- 板端资源有限,难以长期驻留模型或数据。
为此,地平线工具链围绕量化后的模型,提供了三种可选的精度验证方案,分别适配不同类型的项目需求。
一、三种 Badcase 精度验证方案
1.1 方案一:仿真推理(Simulate Inference)
使用量化过程生成的与 hbm 等效的 .bc 模型,在服务端模拟 BPU 行为进行推理,无需依赖硬件设备。
- 优点 :
- 无需开发板,部署轻量;
- 适合多模型结构快速迭代验证;
- 缺点 :
- 本地仿真推理因为缺少了专用板端硬件参与,速度相对较差。
适用场景:早期算法开发、模型结构调整的初步验证。
1.2 方案二:本地数据,远程推理(hbm_infer 协同执行)
基于 hbm_infer 模块,服务端将输入数据通过 RPC 接口发送至板端,调用 HBM 模型进行真实硬件推理,结果再返回服务端进行分析。
- 优点 :
- 数据留在服务端,可动态调度;
- 使用板端 硬件推理,速度较快,且度评估基于真实 BPU,结果可靠;
- 缺点 :
- 网络带宽影响推理效率;
- 需依赖板端资源;
适用场景:Badcase 动态生成、服务端数据不便迁移、对验证速度存在较大需求 、真实精度验证。
1.3 方案三:板端本地验证(纯离线推理)
通过 NFS 或本地挂载方式将全部数据传输到板端,在板端离线完成所有推理与验证工作。
- 优点 :
- 推理速度最快,完全无网络瓶颈;
- 精度结果与部署完全一致;
- 缺点 :
- 需预先准备所有测试数据;
- 动态输入或在线调试能力较弱
- 重度需依赖板端资源;
适用场景:静态 Badcase 精度评估、大规模离线验证、交付测试。
二、三方案对比一览
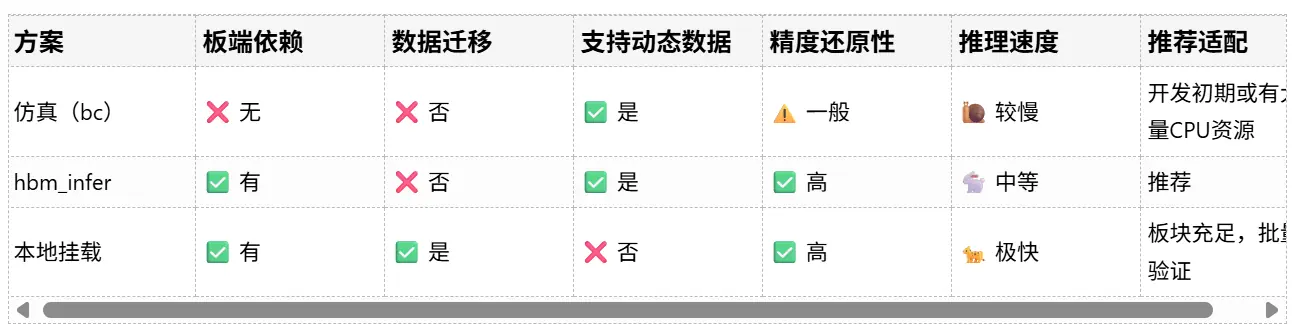
三、为什么重点介绍方案二?
尽管三种方案各有应用空间, 在目前发布的 OE 包与官方示例中,对方案一/三已有说明与案例 ,而方案二虽然支持面广、功能强大,却缺少系统化教程 ,另外方案二 hbm_infer 是目前唯一能同时满足以下需求的解决方案:
- 数据无需迁移:Badcase 可在服务器本地组织;
- 推理结果真实可信:完全基于硬件板端执行;
- 部署过程存在一定复杂度:但可高度自动化,适合通用集成;
本文将聚焦方案二的 hbm_infer 使用流程,提供完整、可运行的代码模板,帮助你快速构建服务端 + 板端协同验证框架。
四、 hbm_infer 使用指南(方案二)
4.1 安装依赖
Bash
# 安装核心组件
1. hbm_infer的使用依赖算法工具发布的docker环境,因此在使用hbm_infer前需要先构建后DOCKER环境,然后在容器中安装hbm_infer组件
2. 在NDA支持下获取hbm_infer python安装包,进入docker环境后使用pip install 安装后使用4.2 常规模式示例:开发调试推荐
Python
import torch
import time
from hbm_infer.hbm_rpc_session import HbmRpcSession
def test_hbm_infer():
hbm_model = HbmRpcSession(
host="192.168.1.100", # 板端 IP
local_hbm_path="./model.hbm"
)
hbm_model.show_input_output_info()
data = {
"input_0_y": torch.randint(0, 256, (1, 512, 960, 1), dtype=torch.uint8),
"input_0_uv": torch.randint(0, 256, (1, 256, 480, 2), dtype=torch.uint8),
}
begin = time.time()
for _ in range(10):
outputs = hbm_model(data)
print({k: v.shape for k, v in outputs.items()})
print(f"Avg time: {round((time.time()-begin)*1000 / 10, 2)} ms")
hbm_model.close_server()
if __name__ == "__main__":
test_hbm_infer()4.3 Flexible 模式示例:多线程/多模型推荐
Python
from hbm_infer.hbm_rpc_session_flexible import (
HbmRpcSession, init_server, deinit_server, init_hbm, deinit_hbm
)
import torch, time
def test_flexible():
server = init_server(host="192.168.1.100")
handle = init_hbm(hbm_rpc_server=server, local_hbm_path="./model.hbm")
hbm_model = HbmRpcSession(hbm_rpc_server=server, hbm_handle=handle)
data = {
"input_0_y": torch.randint(0, 256, (1, 512, 960, 1), dtype=torch.uint8),
"input_0_uv": torch.randint(0, 256, (1, 256, 480, 2), dtype=torch.uint8),
}
begin = time.time()
for _ in range(10):
outputs = hbm_model(data)
print({k: v.shape for k, v in outputs.items()})
print(f"Avg time: {round((time.time()-begin)*1000 / 10, 2)} ms")
hbm_model.close_server()
deinit_hbm(handle)
deinit_server(server)
if __name__ == "__main__":
test_flexible()五、小贴士:提高推理效率的建议
- 板端与服务端建议处于同网段或直连,降低传输延迟;
- 对于批量推理任务,可提前批量加载数据并串行发送;
- 支持
with_profile=True打开性能日志分析;
六、总结建议