RabbitMQ-基础
文章目录
- RabbitMQ-基础
RabbitMQ是一个高性能的异步通讯组件,假如当们我实现一个登录的业务时,使用同步通讯来实现,那么效率会降低很多,如下图基于OpenFegin实现的就是同步通讯,发起的请求需要实时等待返回信息,登录的效率比较低,影响用户体验。
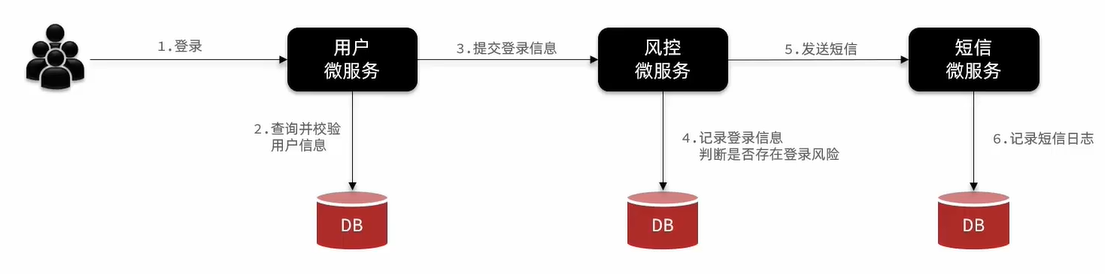
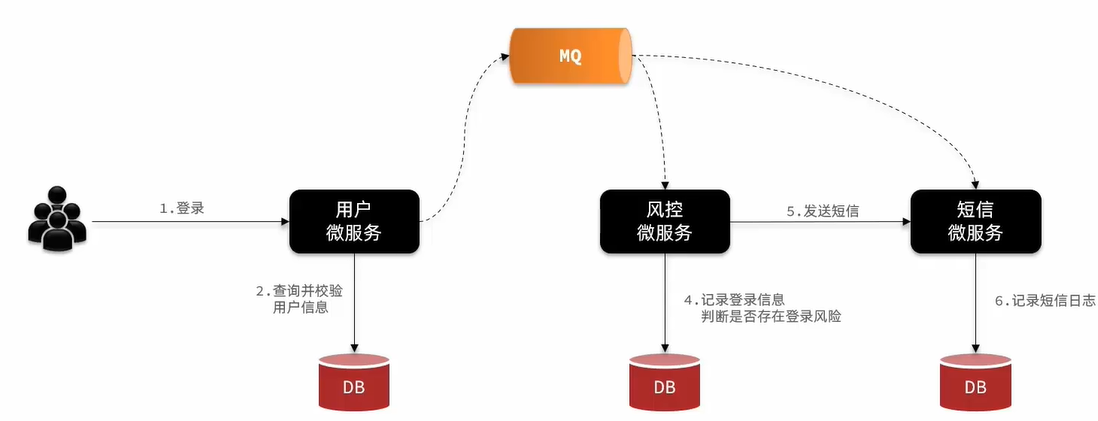
此时我们使用RabbitMQ即刻解决这个问题,用户完成登录校验后直接登录,并将相关信息提交至MQ,再由其他服务从MQ中获取信息完成业务,可以大大增加并发量,提升业务效率!
注意:并不是异步通讯就比同步通讯好,要根据业务情况分析选择合适的技术。
1.同步调用
这里我们举一个简单的同步调用的例子:
在支付业务当中,我们调起支付,需要实时的知道用户余额是否足够才能之下之后的逻辑。
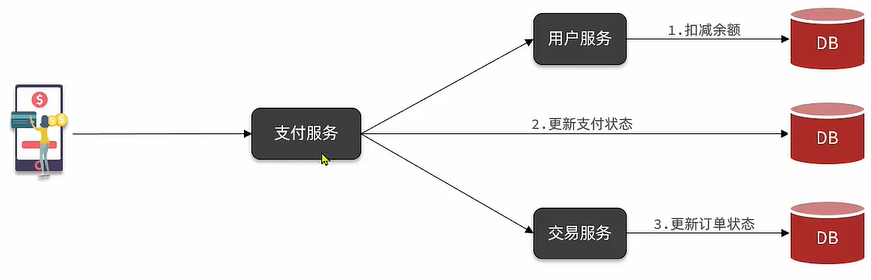
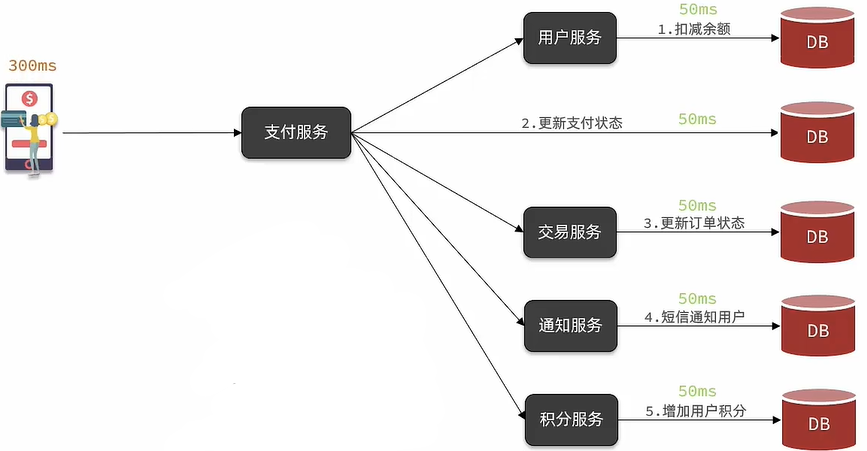
同步调用存在哪些问题呢?
- 当我们需要在支付业务中添加新的需求,每一个新的需求都需要向支付服务返回处理结果,当需求越多阻塞等待时间越长,用户的满意度也就会极大地减少,性能下降。
- 我们会发现代码的扩展性很差,我们的核心业务时实现支付,为了新的需求要多次的修改支付服务的代码。
- 假设交易服务出现故障抛出异常,长时间得不到解决,也会导致支付服务出现问题,也就是级联失败问题。
2.异步调用
异步调用方式其实就是基于消息通知的方式,一般包含三个角色:
- 消息发送者:投递消息的人,可以理解为快递员。
- 消息代理:管理、暂存、转发消息,可以理解为菜鸟驿站。
- 消息接收者:接收和处理消息的人,可以理解为取快递的人。
这样支付服务不再同步调用关联度低的服务,而是发送消息到Broker(中间人)。
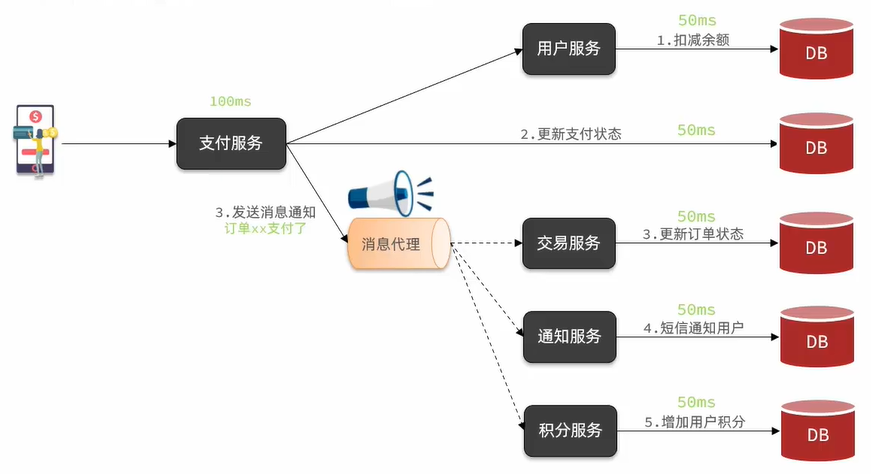
优势:
-
解除耦合,拓展性更强,支付服务只关心用户余额的扣减问题。
-
无需等待与支付服务关联度低的服务,性能提升。
-
故障隔离,假设交易服务故障,不会影响到支付服务,并且可以从消息代理中拿到消息进行业务重试。
-
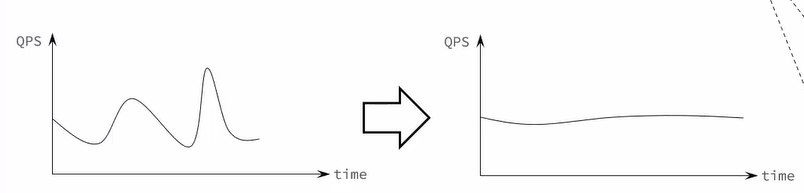
缓存消息,流量削峰填谷。
当有大量消息通知进入消息代理(消息代理的容量很大),后边的服务可以根据自己的处理速度来一个一个处理。
缺点:
- 不能立即得到调用结果,时效性差。
- 不确定下游业务是否执行成功。
- 业务安全依赖于Broker的可靠性。
3.技术选型
MQ (M essageQ ueue),中文是消息队列 ,字面来看就是存放消息的队列。也就是异步调用中的Broker。
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMOP, XMPP, SMTP, STOMP | OpenMire, STOMP, REST, XMPP, AMOP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
- 追求可用性:Kafka、 RocketMQ 、RabbitMQ
- 追求可靠性:RabbitMQ、RocketMQ
- 追求吞吐能力:RocketMQ、Kafka
- 追求消息低延迟:RabbitMQ、Kafka
据统计,目前国内消息队列使用最多的还是RabbitMQ,再加上其各方面都比较均衡,稳定性也好,所以学习RabbitMQ也是个不错的选择。
4.安装RabbitMQ(官方网址)https://www.rabbitmq.com/
这里安装使用的docker,拉取RabbitMQ镜像并执行以下语句:
shell
docker run \
-e RABBITMQ_DEFAULT_USER=(你的用户名) \
-e RABBITMQ_DEFAULT_PASS=(你的密码) \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
--network hmall \
-d \
rabbitmq:3.8-management(这里用你拉取的镜像版本)- 15672:RabbitMQ提供的管理控制台的端口
- 5672:RabbitMQ的消息发送处理接口
安装完成后,我们访问 http://你的虚拟机地址:15672即可看到管理控制台。首次访问需要登录,默认的用户名和密码在配置文件中已经指定了。
登录后即可看到管理控制台总览页面:
RabbitMQ架构:
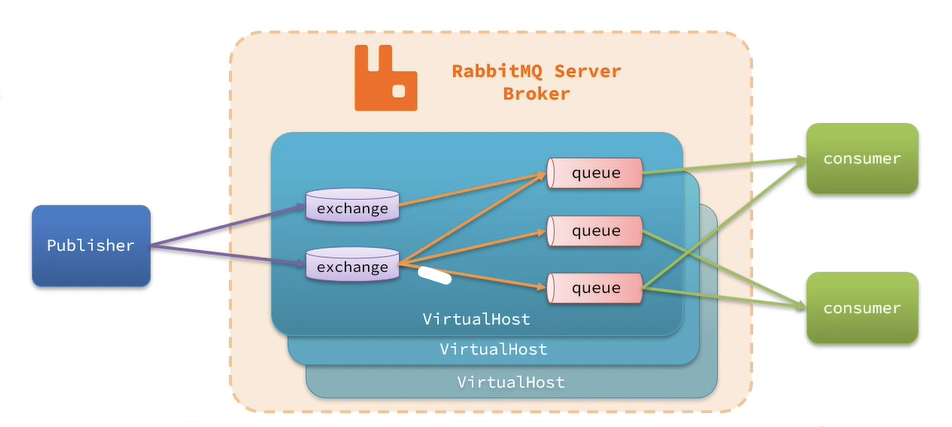
其中包含几个概念:
publisher:生产者,也就是发送消息的一方。consumer:消费者,也就是消费消息的一方。queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理。exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue。可以理解为一个公司里做多套项目,每个项目使用一个虚拟主机实现项目隔离,但只使用一个MQ集群。
5.快速入门
5.1收发消息
5.1.1交换机
我们点击Exchanges选项,可以看到存在许多交换机:
我们点击任意交换机进入交换机详情页面。利用控制台中的publish message 发送一条消息:
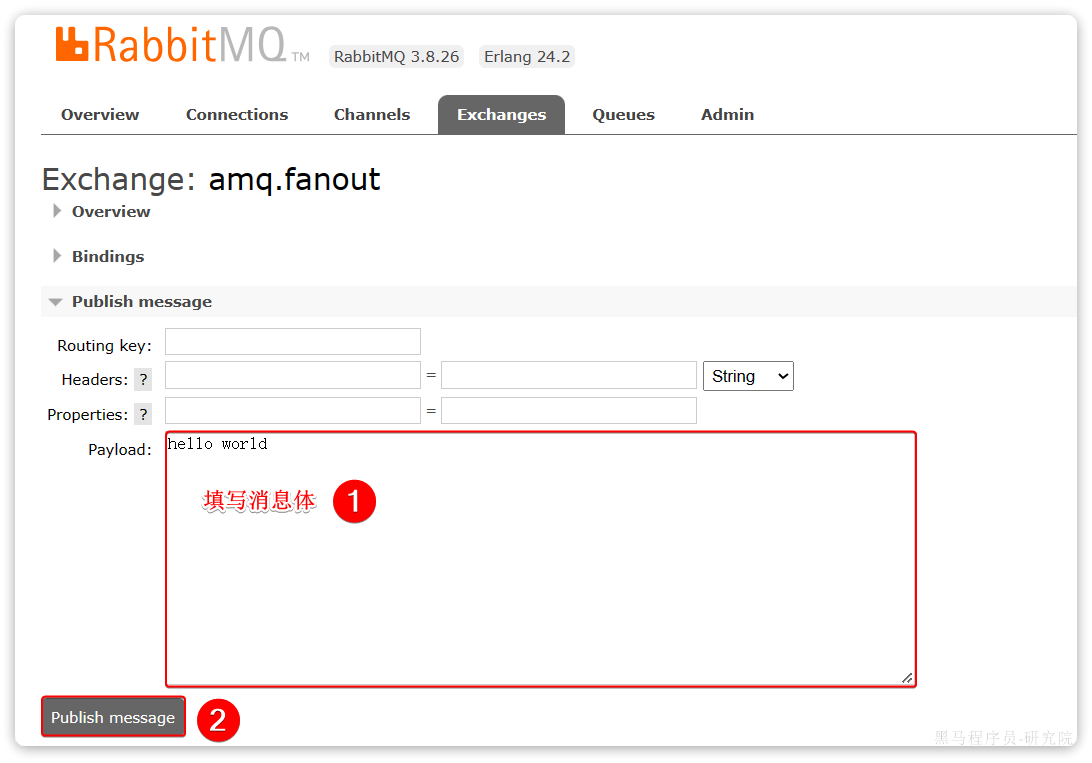
这里是由控制台模拟了生产者发送的消息。由于没有消费者存在,最终消息丢失了,这样也说明交换机没有存储消息的能力。
5.1.2队列
我们点击Queues选项,并新建一个队列:
命名为hello.queue:
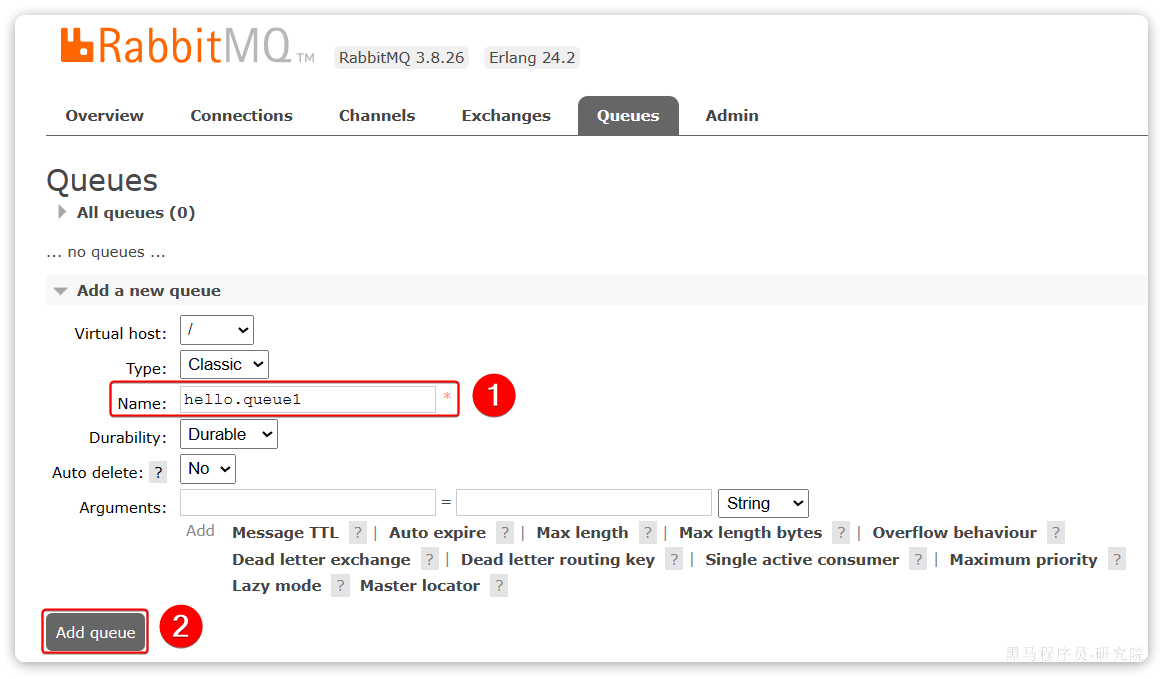
再也同样的方式创建队列hello.queue2,最终列表队列如下:
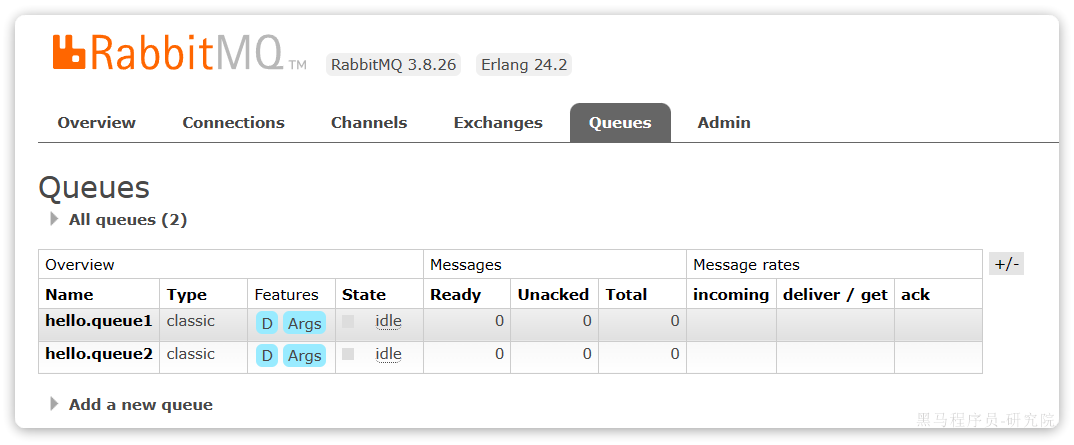
此时我们返回amq.fanout交换机发送一条消息,会发现消息并没有到达队列:
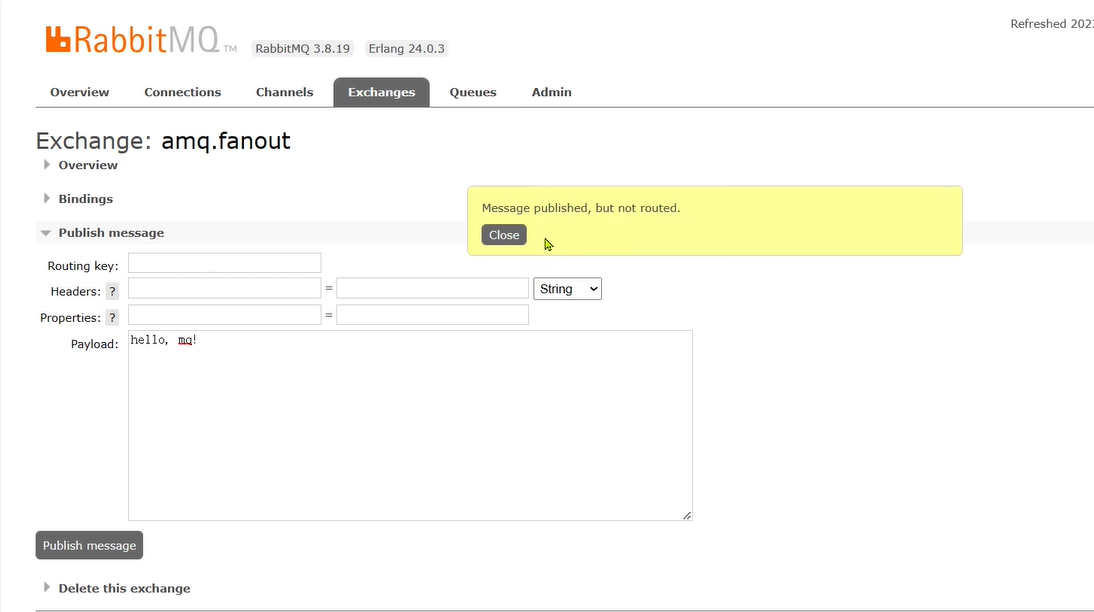
这是因为我们还需要将交换机和队列进行绑定!
5.1.3绑定关系
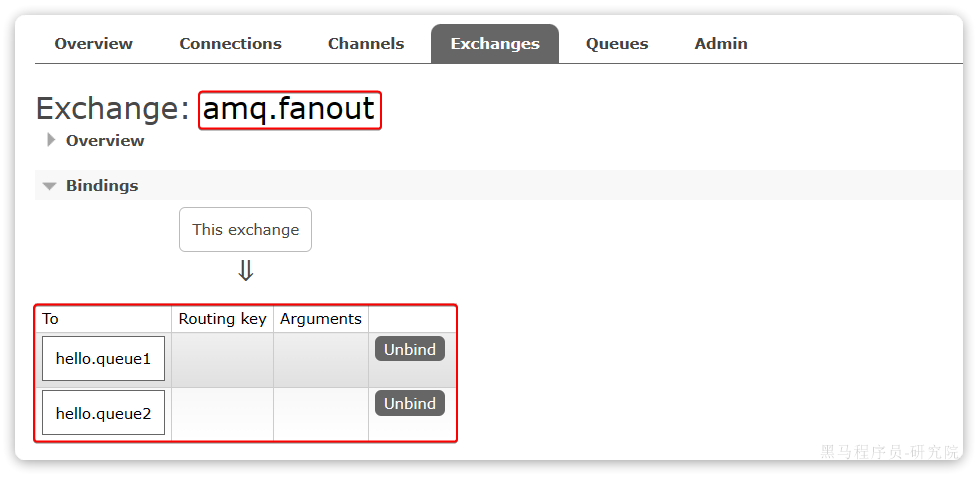
点击Exchanges选项卡,点击amq.fanout交换机,进入交换机详情页,然后点击Bindings菜单,绑定hello.queue1和hello.queue2:
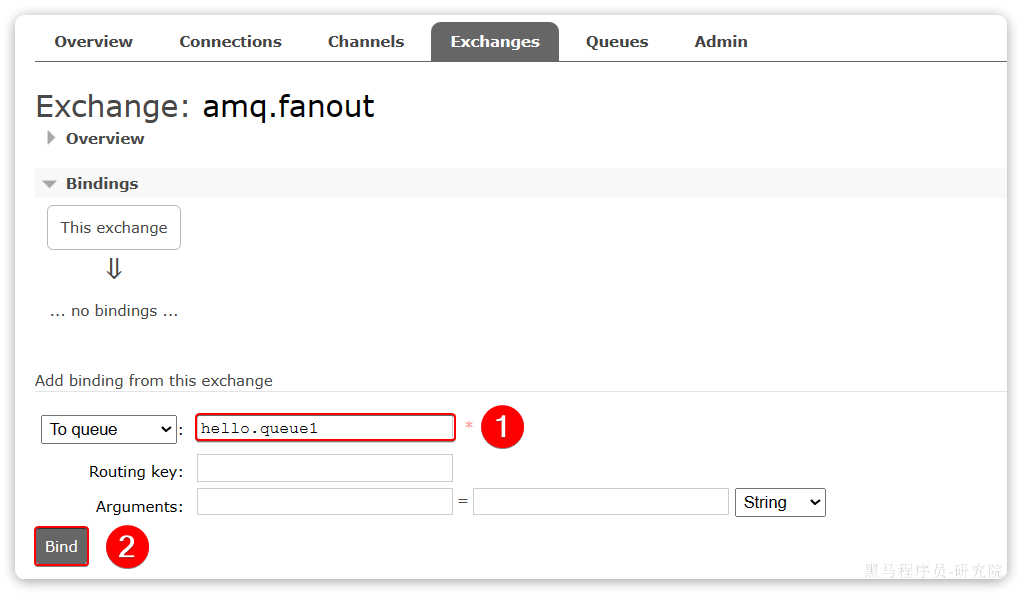
结果如下:
5.1.4发送消息
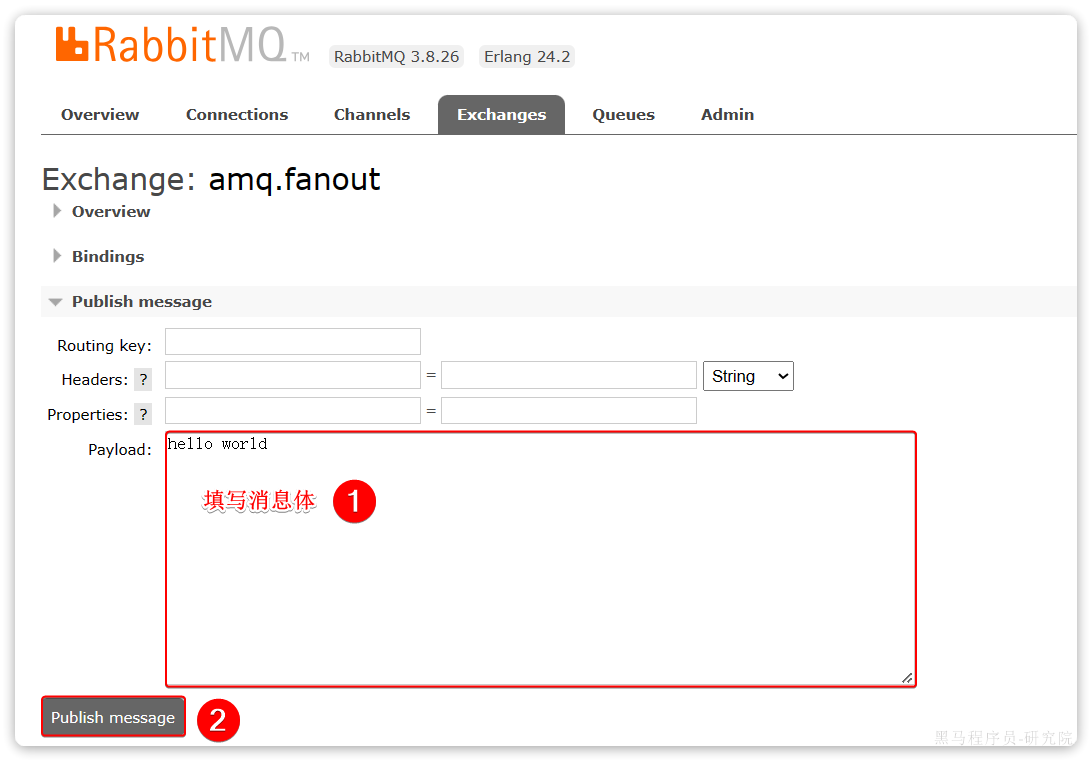
再次回到exchange页面,找到刚刚绑定的amq.fanout,点击进入详情页,再次发送一条消息:
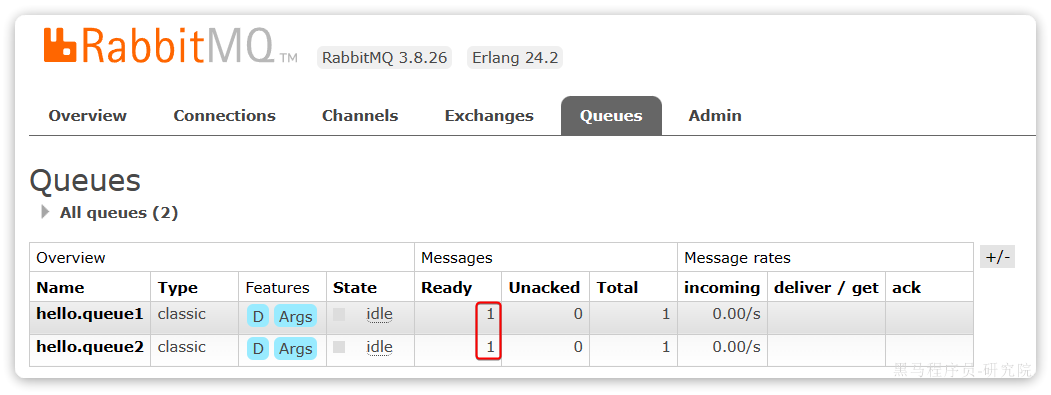
回到Queues页面,可以发现hello.queue中已经有一条消息了:
点击队列名称,进入详情页,查看队列详情,这次点击get message:
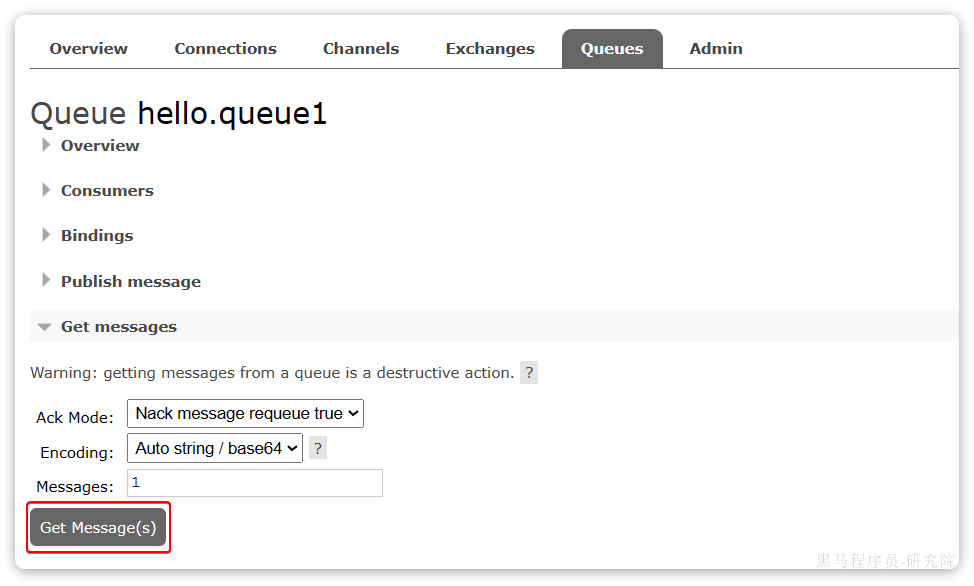
可以看到消息到达队列了:
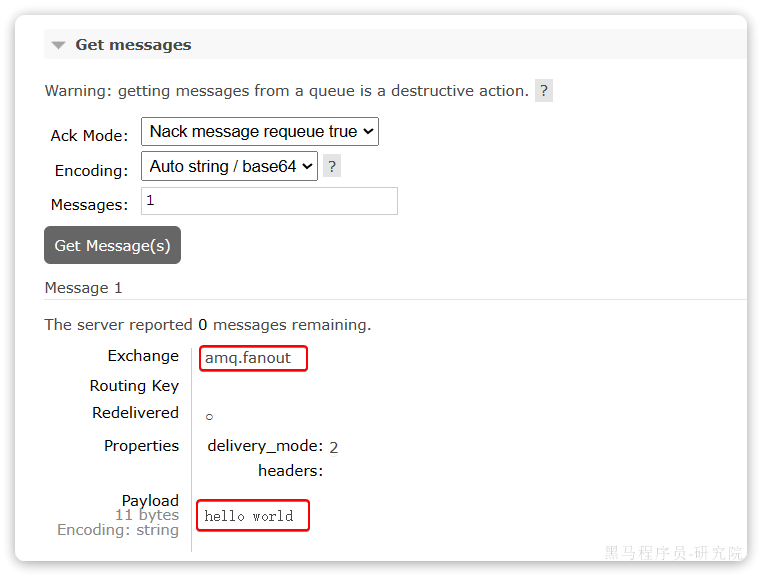
此时如果有消费者监听了MQ的hello.queue1或hello.queue2队列,就能接收到消息了。
5.2数据隔离
5.2.1用户管理
点击Admin选项,会看到RabbitMQ控制台的用户管理界面:
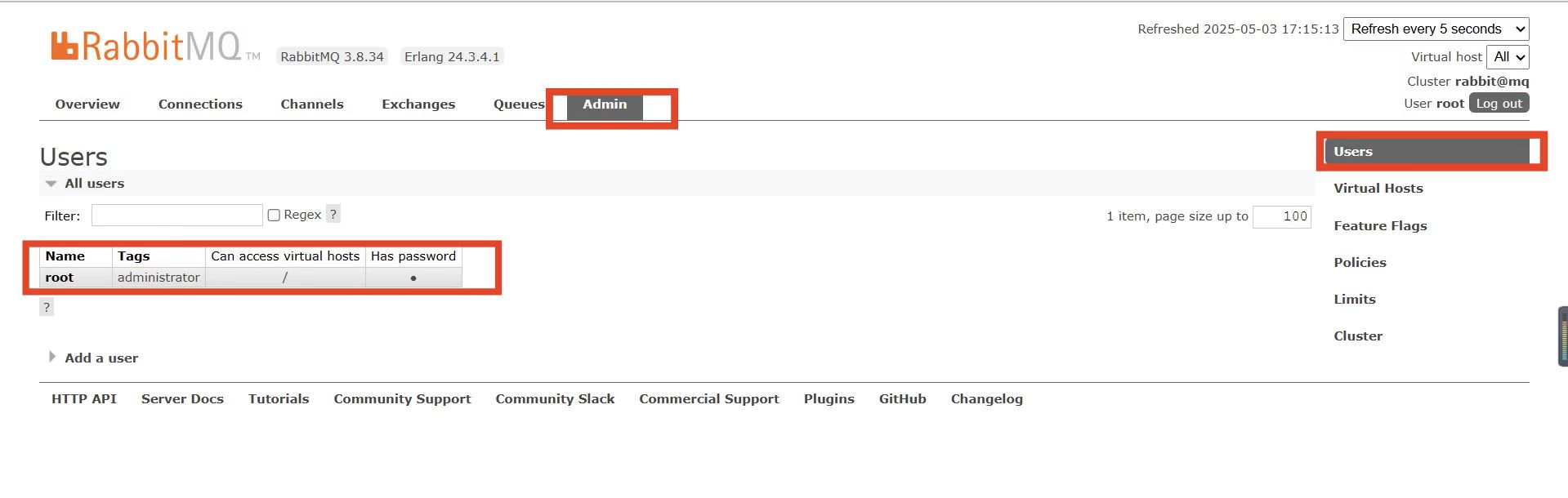
这里的用户都是RabbitMQ的管理或运维人员。目前只有安装RabbitMQ时添加的root这个用户。仔细观察用户表格中的字段,如下:
Name:root,也就是用户名Tags:administrator,说明root用户是超级管理员,拥有所有权限Can access virtual host:/,可以访问的virtual host,这里的/是默认的virtual host
对于小型企业而言,通常只会搭建一套MQ集群,公司内的多个不同项目同时使用。为了避免互相干扰, 会利用virtual host的隔离特性,将不同项目隔离。一般会做两件事情:
- 给每个项目创建独立的运维账号,将管理权限分离。
- 给每个项目创建不同的
virtual host,将每个项目的数据隔离。
比如,我们创建一个新的用户,命名为Study:
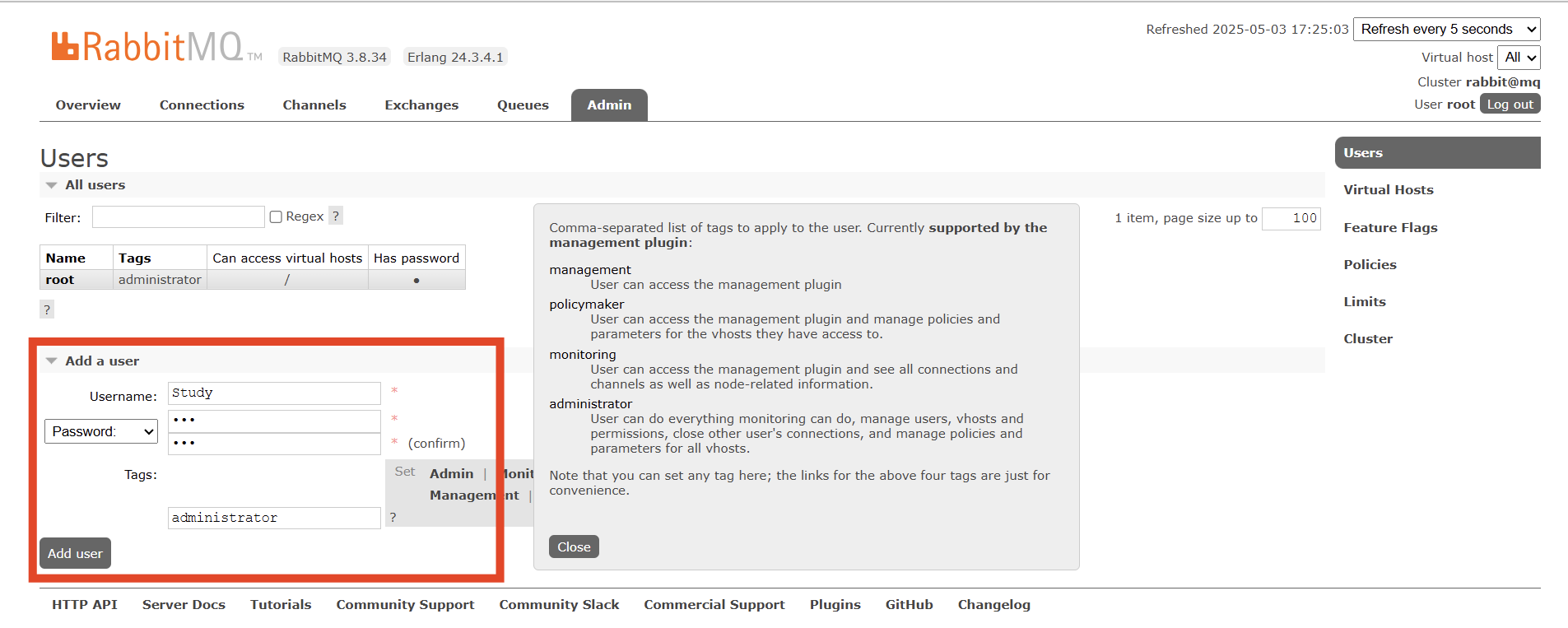
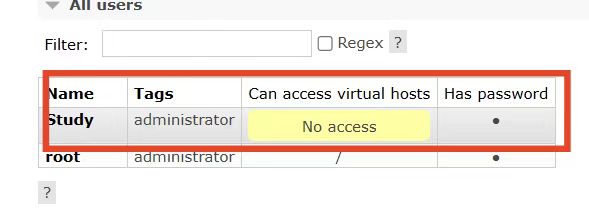
你会发现此时Study用户没有任何virtual host的访问权限:
5.2.2virtual host
我们退出登录,并切换到创建的Study用户登录,然后点击Virtual Hosts菜单,进入virtual host管理页:
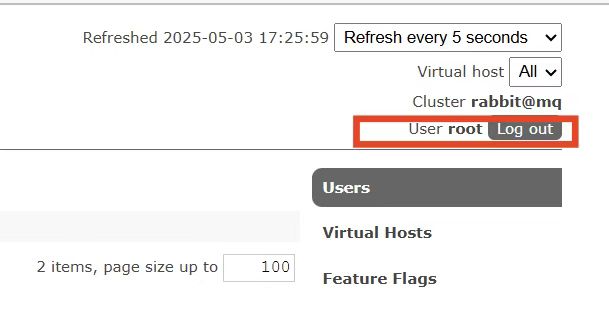
此时可以创建一个单独的virtual host,而不是使用默认的/:
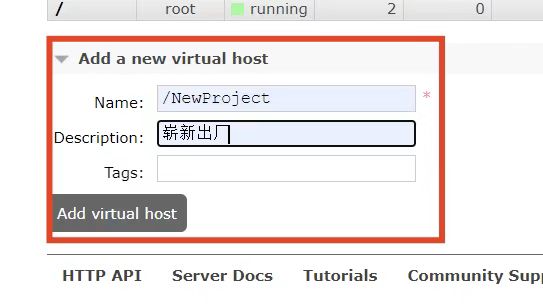
创建后如下图:
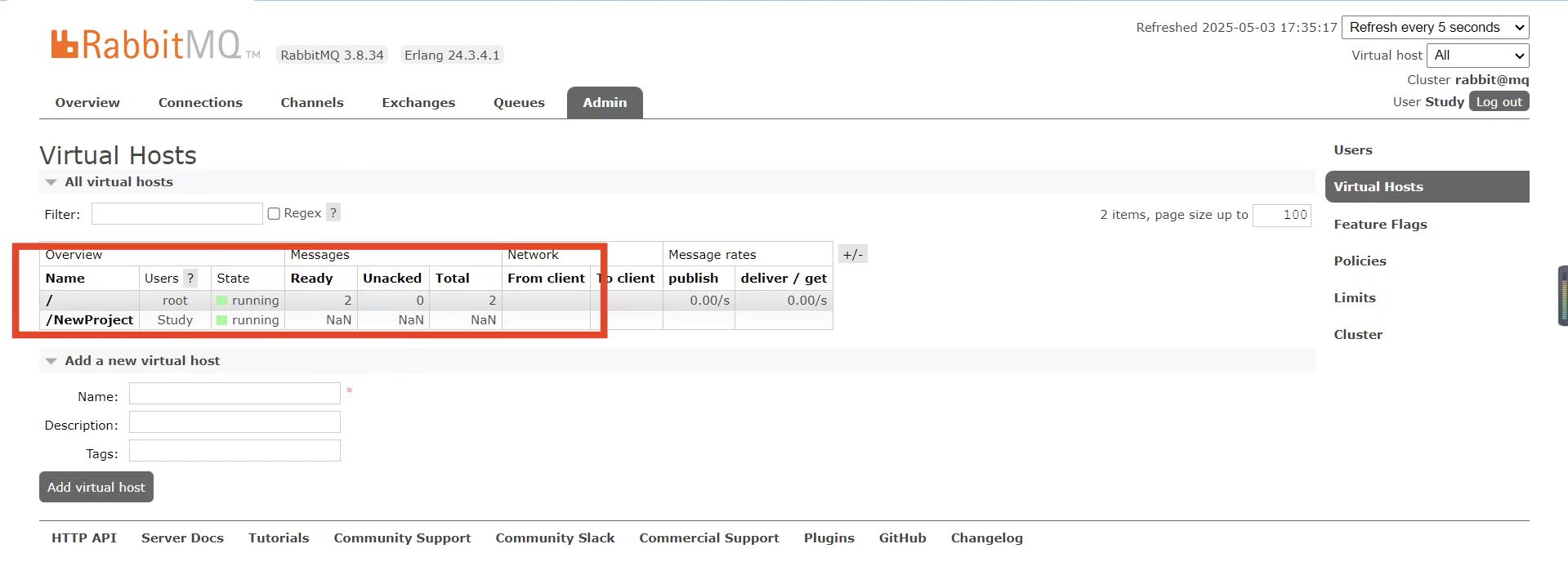
由于我们是登录Study账户后创建的virtual host,因此回到users菜单,你会发现当前用户已经具备了对/NewProject这个virtual host的访问权限了:
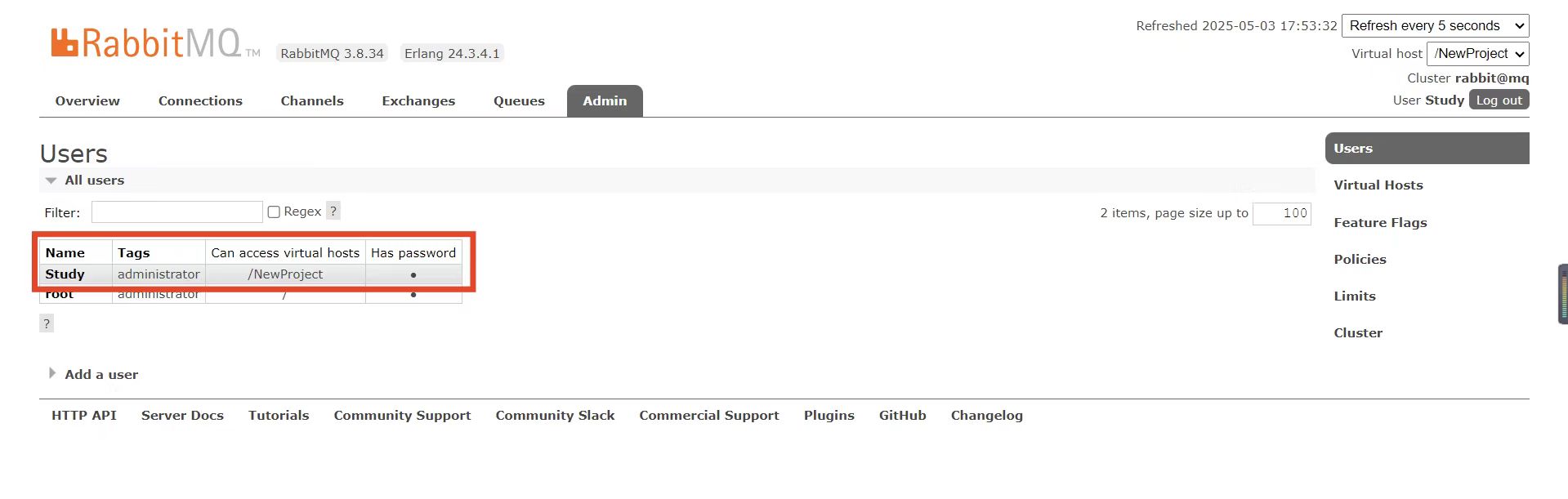
此时,点击页面右上角的virtual host下拉菜单,切换virtual host为 /NewProject,然后再次查看queues选项卡,会发现之前的队列已经看不到了:
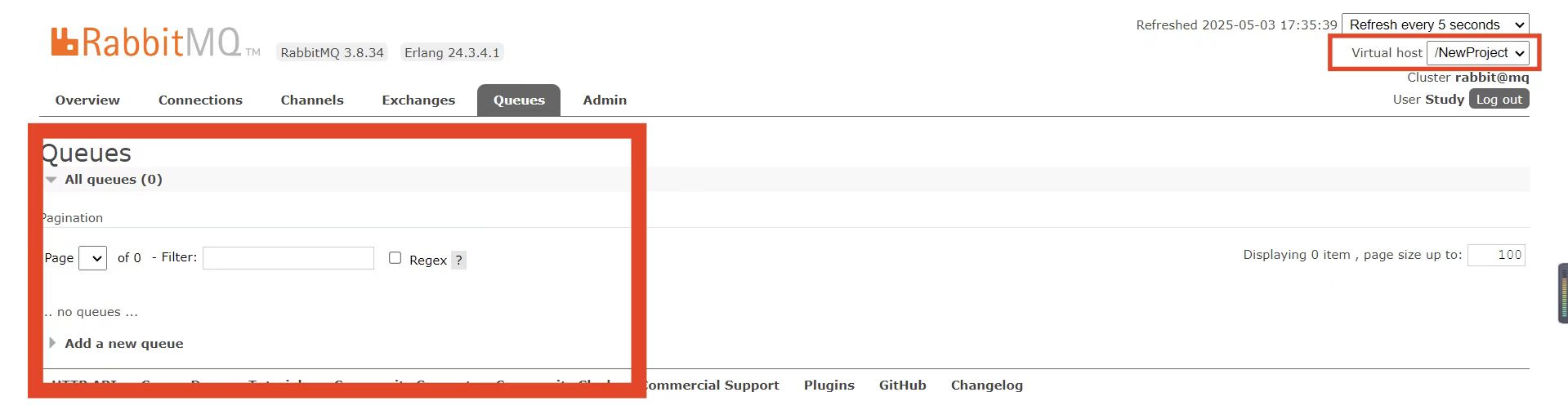
这就是基于virtual host 的隔离效果。
6.Java客户端操作RabbitMQ
这里我提供了一个简单的基础项目,大家可以使用项目一起进行之后的内容学习:https://pan.baidu.com/s/1w66gVO1xc6PaF2uWFEEW0g?pwd=6666
6.1快速入门
这里我们实现以下需求(创建队列这里不再演示):
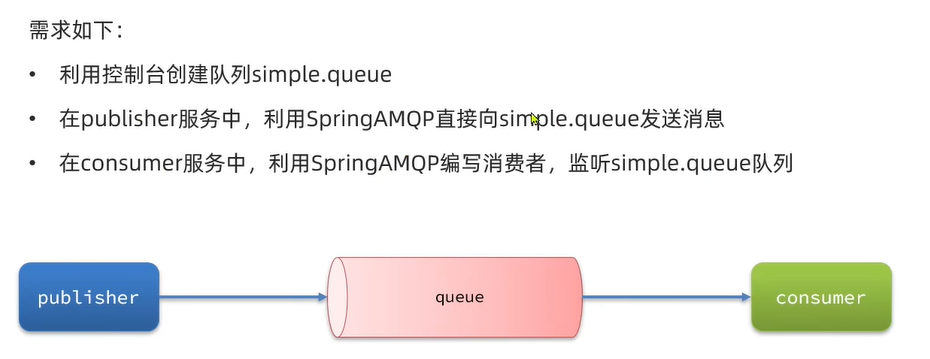
-
引入依赖(提供的demo中已经引入过了)
java<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> -
在发消息的yml文件配置mq
javaspring: rabbitmq: host: 你的虚拟机地址 port: 5672 virtual-host: /NewProject(刚刚创建的) username: Study(刚刚创建的用户名) password: 123(刚刚创建的密码) -
发送消息
java@SpringBootTest public class SpringAmpqTest { @Resource private RabbitTemplate rabbitTemplate; @Test void testSendMessage2Queue(){ String queueName="simple.queue"; String msg="Hello,world!"; rabbitTemplate.convertAndSend(queueName,msg); } }发送结果:

-
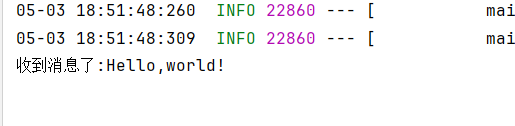
接收消息
java@Slf4j @Component public class MqListener { @RabbitListener(queues = "simple.queue") public void listenSimpleQueue(String msg){ System.out.println("收到消息了:"+msg); } }输出结果:
6.2work模型
我们创建一个新的work.queue队列并让两个消费者来监听(我们希望处理快的多处理一些):
java
//Consumer
//这使用sleep来模拟每个消费者不同的处理能力
@RabbitListener(queues = "work.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1收到消息了_:"+msg);
Thread.sleep(20);
}
@RabbitListener(queues = "work.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2收到消息了_:"+msg);
Thread.sleep(200);
}
java
//publisher
@Test
void testSendMessageToWorkQueue(){
String queueName="work.queue";
String msg="Hello_";
for(int i=1;i<=50;i++){
rabbitTemplate.convertAndSend(queueName,msg+i);
}
}结果:50个消息被平均分配,不符合预期。
默认情况下,RabbitMQ的会将消息依次轮询投递给绑定在队列上的每一个消费者 。但这并没有考虑到消费者是否已经处理完消息,可能出现消息堆积。
java
#因此我们需要修改application.yml,设置preFetch值为1,确保同一时刻最多投递给消费者1条消息:
spring:
rabbitmq:
host: 你的虚拟机地址
port: 5672
virtual-host: /NewProject
username:用户名
password: 密码
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息这时重新运行会发现两个消费者处理的消息数量不同了。
总结一下:Work模型的使用
- 多个消费者绑定到一个队列,可以加快消息处理速度 。
- 同一条消息只会被一个消费者处理 。
- 通过设置prefetch来控制消费者预取的消息数量,处理完一条再处理下一条,实现能者多劳。
6.3交换机
真正生产环境 都会经过exchange来发送消息,而不是直接发送到队列,交换机的类型有以下三种:
- Fanout:广播
- Direct:定向
- Topic:话题
6.3.1Fanout交换机
Fanout Exchange会将接收到的消息广播到每一个跟其绑定的queue,所以也叫广播模式。
这里使用其我们实现如下内容:
-
在RabbitMQ控制台中,声明队列fanout.queue1和fanout.queue2
-
在RabbitMQ控制台中,声明交换机study.fanout,将两个队列与其绑定
-
在consumer服务中,编写两个消费者方法,分别监听fanout.queue1和fanout.queue2
-
在publisher中编写测试方法,向study.fanout发送消息
java
//Consumer
@RabbitListener(queues = "fanout.queue1")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1收到消息了_:"+msg);
}
@RabbitListener(queues = "fanout.queue2")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.out.println("消费者2收到消息了_:"+msg);
}
java
//Publisher
@Test
void testSendMessageToFanoutQueue(){
String ExchangeName="study.fanout";
String msg="Hello,EveryBody!";
rabbitTemplate.convertAndSend(ExchangeName,null,msg);
}运行结果:
总结一下:交换机的作用是什么?
- 接受publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- FanoutExchange的会将消息路由到每个绑定的队列
6.3.2Direct交换机
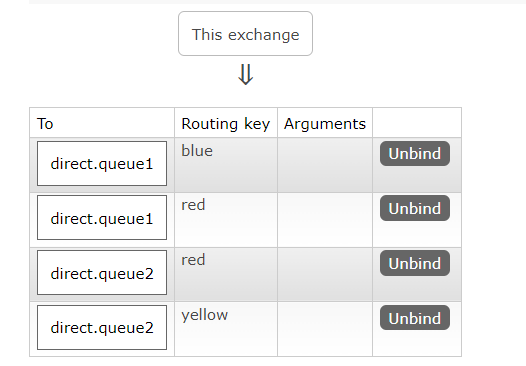
Direct Exchange 会将接收到的消息根据规则路由到指定的Queue ,因此称为定向路由。
- 每一个Queue都与Exchange设置一个BindingKey
- 发布者发送消息时,指定消息的RoutingKey
- Exchange将消息路由到BindingKey与消息RoutingKey一致的队列
java
//Consumer
@RabbitListener(queues = "direct.queue1")
public void listenDirectQueue1(String msg) throws InterruptedException {
System.out.println("消费者1收到消息了_:"+msg);
}
@RabbitListener(queues = "direct.queue2")
public void listenDirectQueue2(String msg) throws InterruptedException {
System.out.println("消费者2收到消息了_:"+msg);
}
java
//Publisher
@Test
void testDirect(){
String ExchangeName="study.direct";
String msg="红色警告!";
rabbitTemplate.convertAndSend(ExchangeName,"red",msg);
}运行结果: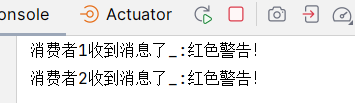
6.3.3Topic交换机
TopicExchange与DirectExchange类似,区别在于routingKey可以是多个单词的列表,并以.分割。
例如:
- china.news 代表有中国的新闻消息;
- china.weather 代表中国的天气消息;
Queue与Exchange指定BindingKey时可以使用通配符:
- # :指代0个 或多个单词
- *****:代指一个单词
我们来实现以下需求:
-
在RabbitMQ控制台中,声明队列topic.queue1和topic.queue2
-
在RabbitMQ控制台中,声明交换机study.topic,将两个队列与其绑定
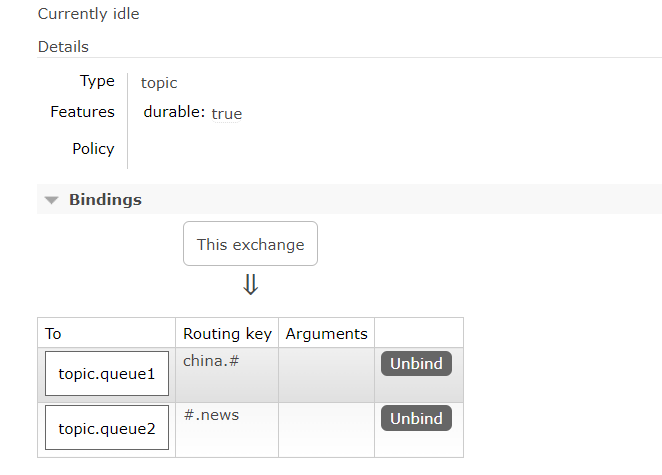
-
在consumer中,编写两个消费者方法,分别监听topic.queue1和topic.queue2
java//Consumer @RabbitListener(queues = "topic.queue1") public void listenTopicQueue1(String msg) throws InterruptedException { System.out.println("消费者1收到消息了_:"+msg); } @RabbitListener(queues = "topic.queue2") public void listenTopicQueue2(String msg) throws InterruptedException { System.out.println("消费者2收到消息了_:"+msg); } -
在publisher中编写测试方法,利用不同的RoutingKey向hmall.topic发送消息
java//Publisher @Test void testTopic(){ String ExchangeName="study.topic"; String msg="小日子,我们中国是Numer One!!"; rabbitTemplate.convertAndSend(ExchangeName,"Japan.news",msg); }此时根据通配符匹配结果,应当只有消费者2收到消息:

6.4声明队列和交换机的方式一
SpringAMQP 提供了几个类,用来声明队列 、交换机 及其绑定关系:
-
Queue :用于声明队列,可以用工厂类QueueBuilder构建
-
Exchange :用于声明交换机,可以用工厂类ExchangeBuilder构建 ,由于Exchange有多种类型,所以他有多种实现。
-
Binding :用于声明队列和交换机的绑定关系,可以用工厂类BindingBuilder构建
我们在Consumer中编写代码:
java
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FanoutConfiguration {
//声明fanout交换机
@Bean
public FanoutExchange fanoutExchange() {
//return ExchangeBuilder.fanoutExchange("study.fanout2").build();
return new FanoutExchange("study.fanout2");
}
//声明队列
@Bean
public Queue fanoutQueue() {
//return QueueBuilder.durable().build();
return new Queue("fanout.queue3");
}
//绑定队列和交换机
@Bean
public Binding fanoutBinding3() {
return BindingBuilder.bind(fanoutQueue()).to(fanoutExchange());
}
/* @Bean
public Binding fanoutBinding3(Queue fanoutQueue,FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue()).to(fanoutExchange());
}*/
}运行后可以看到已经成功绑定:
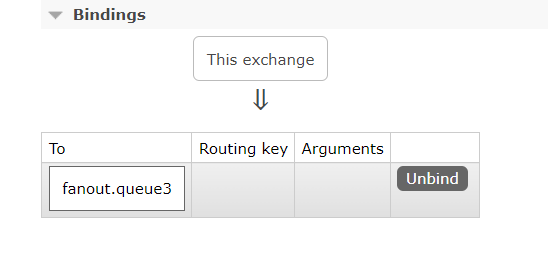
不过这里提一点这种方式的缺点 ,当我们需要Direct交换机并进行绑定时,由于需要多个routingKey,而bind()只能绑定一个key,此时就需要创建多个Bean,非常的麻烦,这里不演示,自行敲一遍感受一下。
6.5声明队列和交换机的方式二
SpringAMQP还提供了基于**@RabbitListener注解**来声明队列和交换机的方式。
java
//Consumer
@RabbitListener(bindings=@QueueBinding(
value=@Queue(name = "direct.queue1",durable="true"),
exchange=@Exchange(name="study.direct",type= ExchangeTypes.DIRECT),
key={"red","blue"}
))
public void listener1(String msg){
log.info("收到消息:{}",msg);
}
@RabbitListener(bindings=@QueueBinding(
value=@Queue(name = "direct.queue2",durable="true"),
exchange=@Exchange(name="study.direct",type= ExchangeTypes.DIRECT),
key={"red","yellow"}
))
public void listener2(String msg){
log.info("收到消息:{}",msg);
}运行后会发现创建成功:
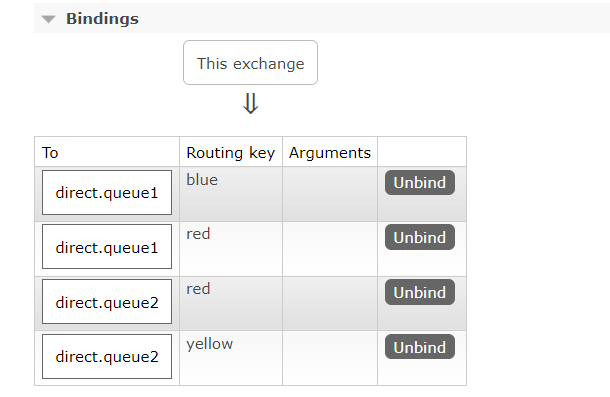
6.6消息转换器
我们创建一个新的队列并向其中发送Map类型的消息:
java
@Test
void testMessageConvert(){
String queueName="object.queue";
Map<String,String> msg=new HashMap<>(2);
msg.put("name","张三");
msg.put("age","20");
rabbitTemplate.convertAndSend(queueName,msg);
}运行结果查看发送的消息如下:
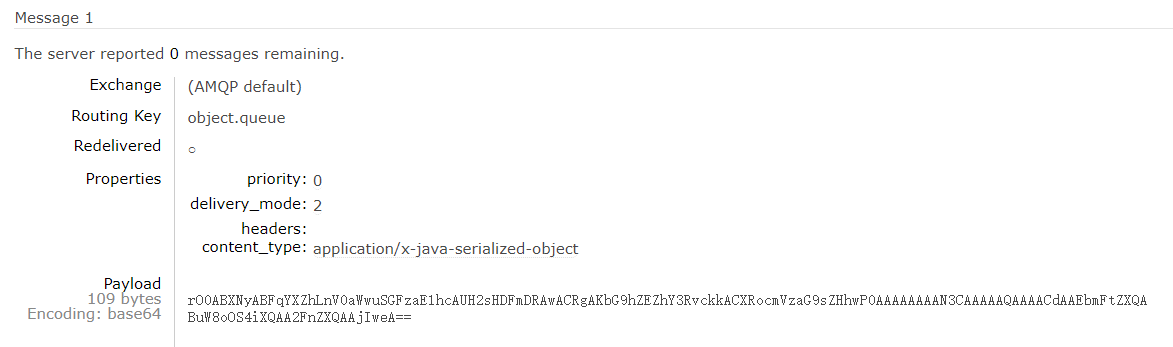
Spring的对消息对象的处理是由org.springframework.amqp.support.converter.MessageConverter 来处理的。而默认实现是SimpleMessageConverter ,基于JDK的ObjectOutputStream完成序列化,感兴趣的可以去看源码。
不过存在下列问题:
- JDK的序列化有安全风险
- JDK序列化的消息太大
- JDK序列化的消息可读性差
建议采用JSON序列化代替默认的JDK序列化:
-
在Publisher和Consumer中引入jackson依赖
java<!--Jsckson--> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency> -
在Publisher和Consumer中都要配置MessageConverter
java@Bean public MessageConverter jackaonMessageConvert(){ return new Jackson2JsonMessageConverter(); }
此时查看会发现消息正常:
