目录
[(2)union all](#(2)union all)
在上一篇文章中我们引入了范式,而在数据设计时由于范式的要求,我们的数据被拆分到多个表中,而此时我们要查询一条完整的数据信息,就要从多个表中获取数据。
例如我们将下面这张原本的表进行了拆分:
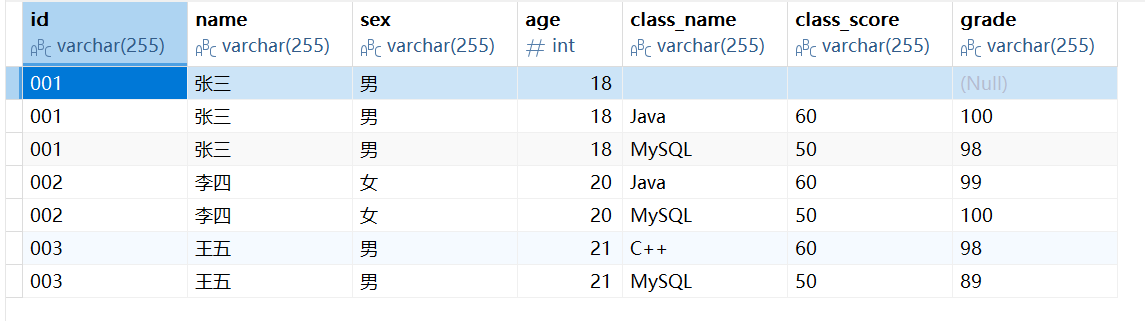
拆分成学生表,课程表,成绩表:
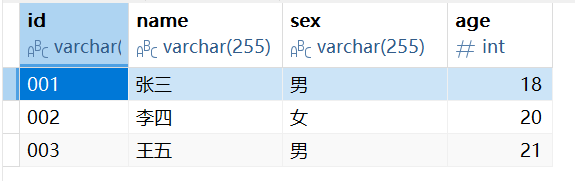
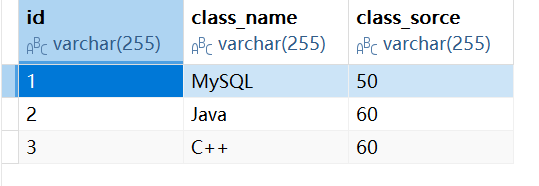
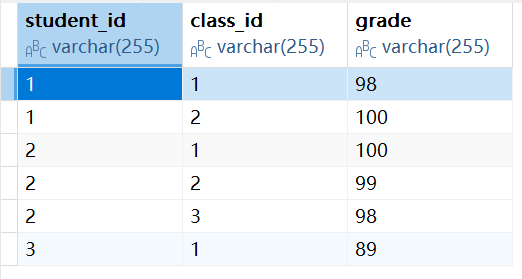
而当这样拆分后,我们我们无法按照之前的方式进行查询了,因为了能够进行跨表查询,我们就引入了联合查询。
**一、**笛卡尔积
在我们进行多表查询的时候我们需要用到一个方式:取笛卡尔积。
select * from 表1 别名,表2 别名;
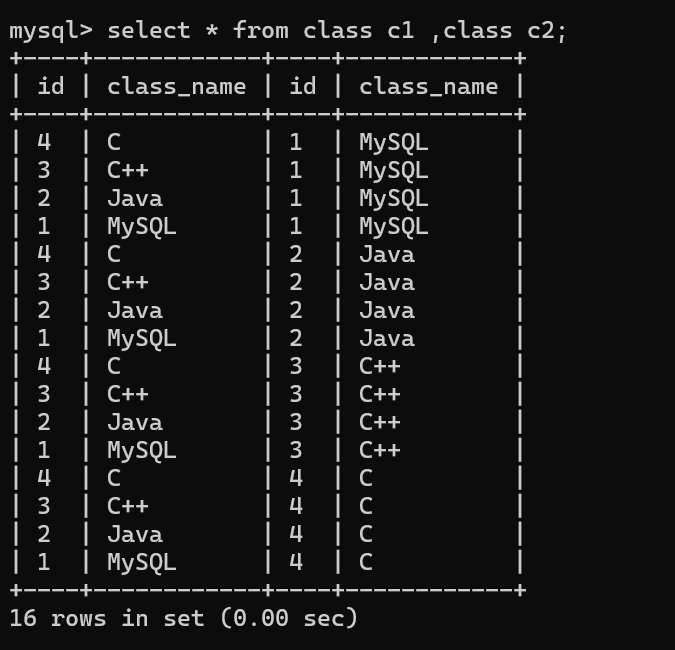
那么我们接下来就对我们的学生表和班级表取笛卡尔积
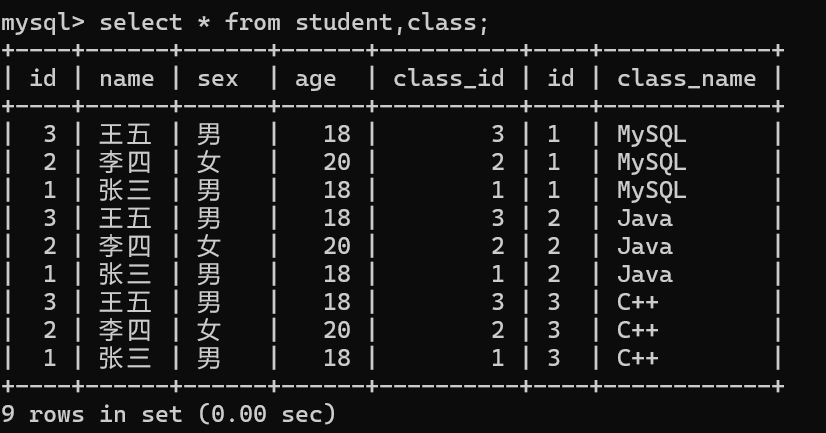
我们发现取笛卡尔积后其实是有很多的无效数据的,因为我们的学生表中的课程id是要和课程表中的id相同才是有效的,因此我们要进行筛选。
这样我们就得到了我们想要的信息了
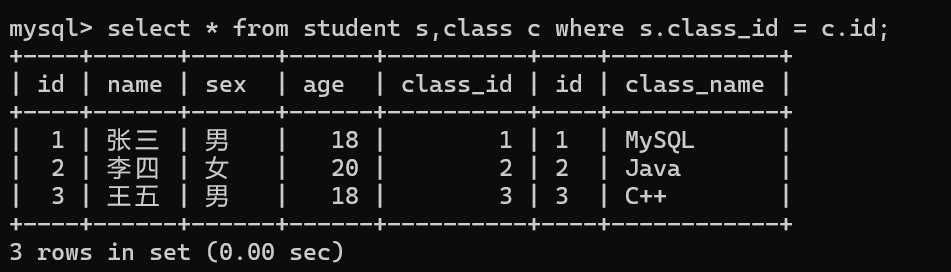
当然如果我们还要进一步的筛选,我们只需要加上and 和我们的筛选条件即可

二、内连接
语法:
select 字段 from 表 1 别名 1, 表 2 别名 2 where 连接条件 and 其他条件 ;
select 字段 from 表 1 别名 1 inner join 表 2 别名 2 on 连接条件 where 其他条件 ;
我们的内连接是有两种写法的,那么我们接下来就用两种方式去得到我们所有学生的信息和他们的成绩
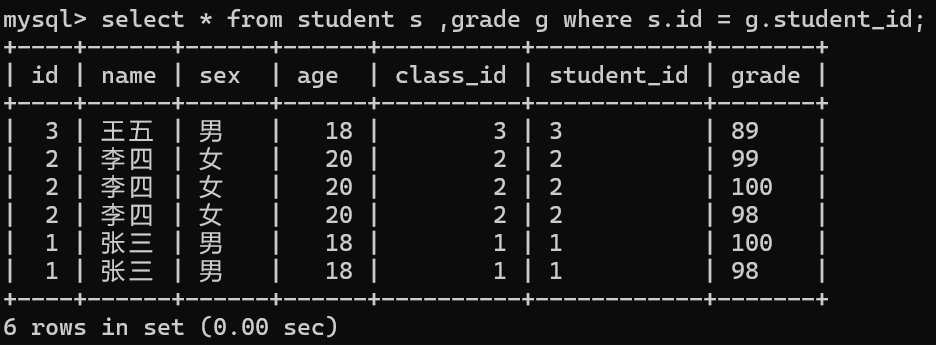
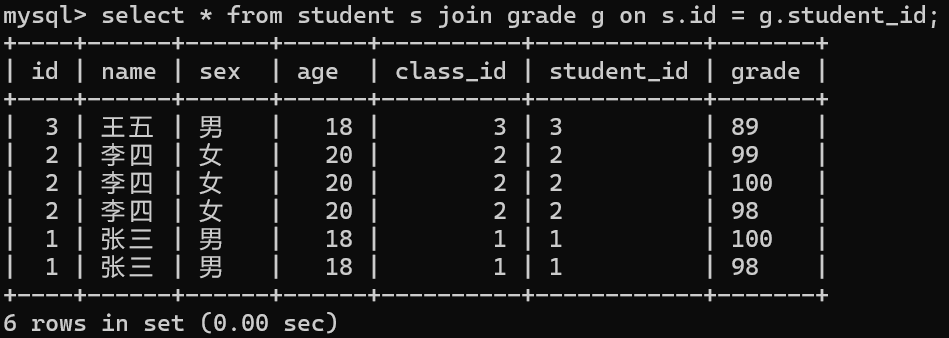
接下来我们也来做个练习利用内连接,查询名字为张三的总成绩

三、外连接
我们的外连接分为左外连接、右外连接和全外连接三种类型。
注意:MySQL不支持全外连接。
(1)左外连接
语法:
select 字段名 from 表名 1 left join 表名 2 on 连接条件 ;
注意: 左外连接会返回左表的所有记录和右表中匹配的记录。如果右表中没有匹配的记录,则结果集中对应字段会显示为NULL。
那么接下来我们利用左外连接去查询学生表和成绩表的有效信息
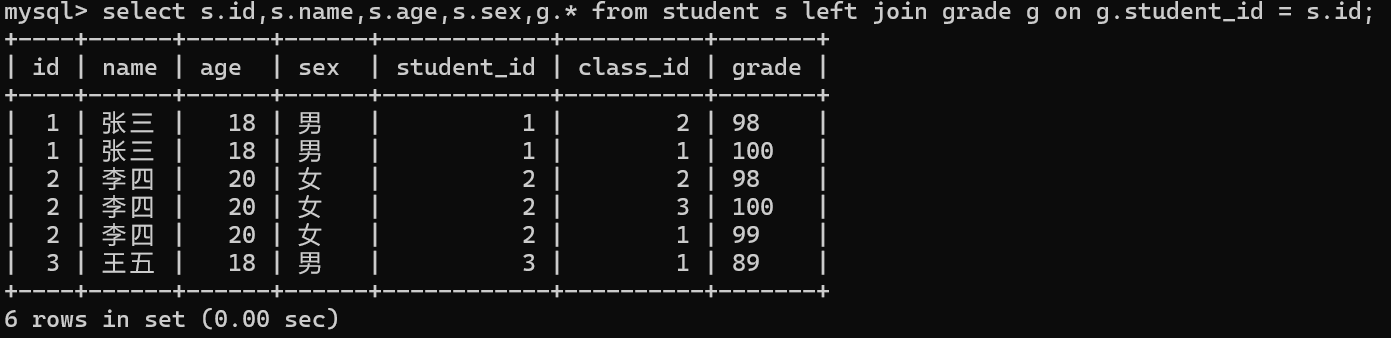 如果此时我们在学生表中添加一位没有参加考试的学生信息,在进行查询将会怎样呢?
如果此时我们在学生表中添加一位没有参加考试的学生信息,在进行查询将会怎样呢?
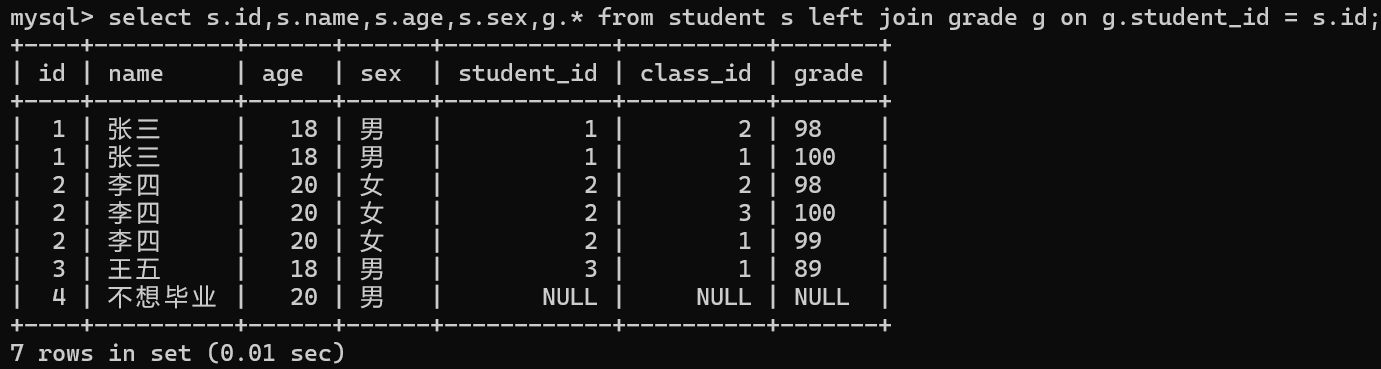
我们发现如果我们使用左外连接进行查询如果我们有没参加考试,他会将我们的表1的信息全部显示,而表2的信息后全部显示为null.
(2)右外连接
语法:
select 字段名 from 表名 1 right join 表名 2 on 连接条件 ;
注意:右外连接是与左外连接相反,返回右表的所有记录和左表中匹配的记录。如果左表中没有匹配的记 录,则结果集中对应字段会显示为NULL。
接下来我们利用右外连接来查询学生表和班级表之间的关系
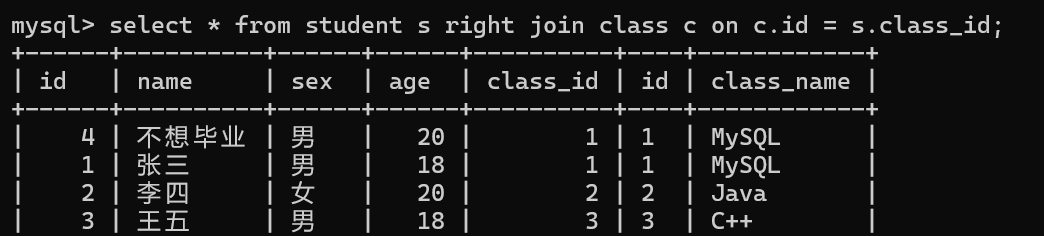 这时如果我们在班级表中新添加一个班级,并且没有学生在这个班级里会怎样呢?
这时如果我们在班级表中新添加一个班级,并且没有学生在这个班级里会怎样呢?
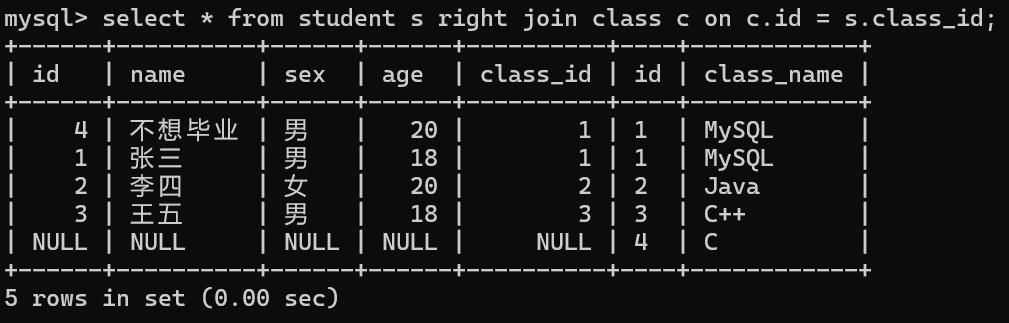 我们发现如果我们使用右外连接进行查询如果我们有没有学生的班级,他会将我们的表2的信息全部显示,而表1的信息后全部显示为null.
我们发现如果我们使用右外连接进行查询如果我们有没有学生的班级,他会将我们的表2的信息全部显示,而表1的信息后全部显示为null.
(3)全外连接
结合了左外连接和右外连接的特点,返回左右表中的所有记录。如果某一边表中没有匹配的记录,则结果集中对应字段会显示为NULL。
由于我们的MySQL不支持全外连接,我们就不做演示了
四、自连接
所谓自连接就是自己与自己取笛卡尔积,可以把行转化成列,而我们在进行查询的时候可以使用where条件对结果进行过滤,或者说实现行与行之间的比较。
注意:在做表连接时,我们需要为进行自连接表起不同的别名。
而利用这种方式我们就可以利用自连接的方式,去得到同一个表中java成绩大于MySQL成绩的信息。
 五、子查询
五、子查询
定义:我们的子查询又叫嵌套查询,它是根据把一个SELECT语句的结果当做别一个SELECT语句的条件,来进行查询的方式
语法:
select * from table1 where col_name1 {= | IN} ( select col_name1 from table2 where col_name2 {= | IN} ( select ...) ... );
而我们的子查询却又分成三种查询模式:单行子查询,多行子查询,多列子查询。
(1)单行子查询
简单来说就是嵌套的查询中只返回一行数据。
例如:我们想要查询与"不想毕业"同学的同班同学

像这样,一个查询的条件时另一个查询的结果,就是我们的子查询,而由于另一个查询的结果是一行数据,那么我们就称它是单行子查询。
(2)多行子查询
嵌套的查询中返回多行数据,但是我们需要使用NOT IN关键字得到返回的范围
例如:我们想要查询"MySQL"或"Java"课程的成绩信息

像这样,一个查询的条件时另一个查询的多个结果,而我们用in关键字去存入这些结果,再根据这些in中的条件去得到另一个查询的结果,我们就称它是多行子查询。
(3)多列子查询
单行子查询和多行子查询都只返回一列数据,多列子查询中可以返回多个列的数据
注意:外层查询与嵌套的内层查询的列要匹配
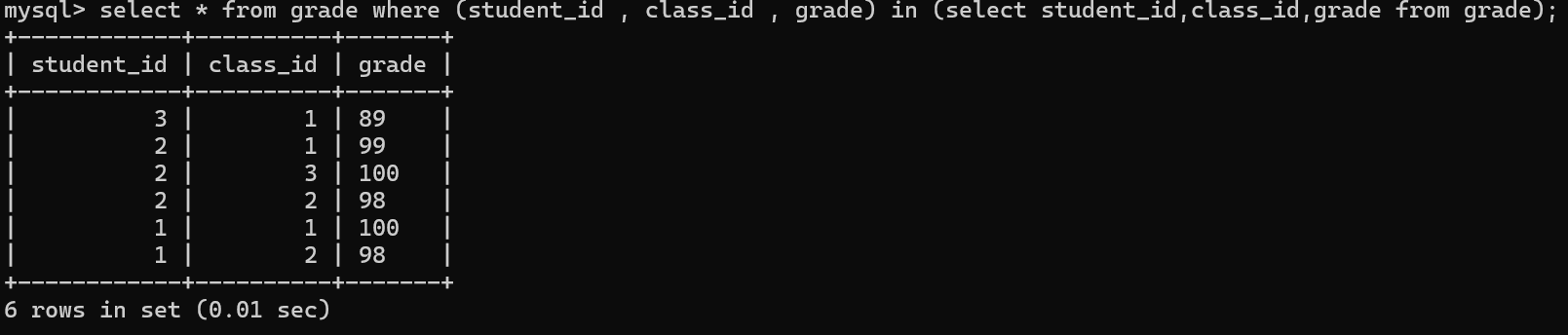
我们举个简单的例子:根据 多列子查询去得到成绩中的所有列(虽然这么查询没必要,但是注意是好了解多列子查询)
然而除了这三种子查询方式,我们还有一种方式,通过临时表在from中进行查询
(4)临时表
当一个查询产生结果时,MySQL自动创建一个临时表,然后把结果集放在这个临时表中,最终返回给用户,在from子句中也可以使用临时表进行子查询或表连接操作。
例如:我们要查询所有比"Java班"平均分高的成绩信息
在原本的思路中我们是要先查出"Java班"平均分,然后根据这个平均分作为条件,进行筛选比平均分高的成绩信息。

但是在这里,我们其实可以利用子查询的方式,将这个求平均分的方式的临时表,通过调用临时表中列的值的方式求出所有比"Java班"平均分高的成绩信息

六、合并查询
在实际应用中,在我们进行两表的select操作返回的结果,肯会有多个相同的结果,而在这种情况下我们就可以使用集合操作符union,union all,来确定是否进行去重
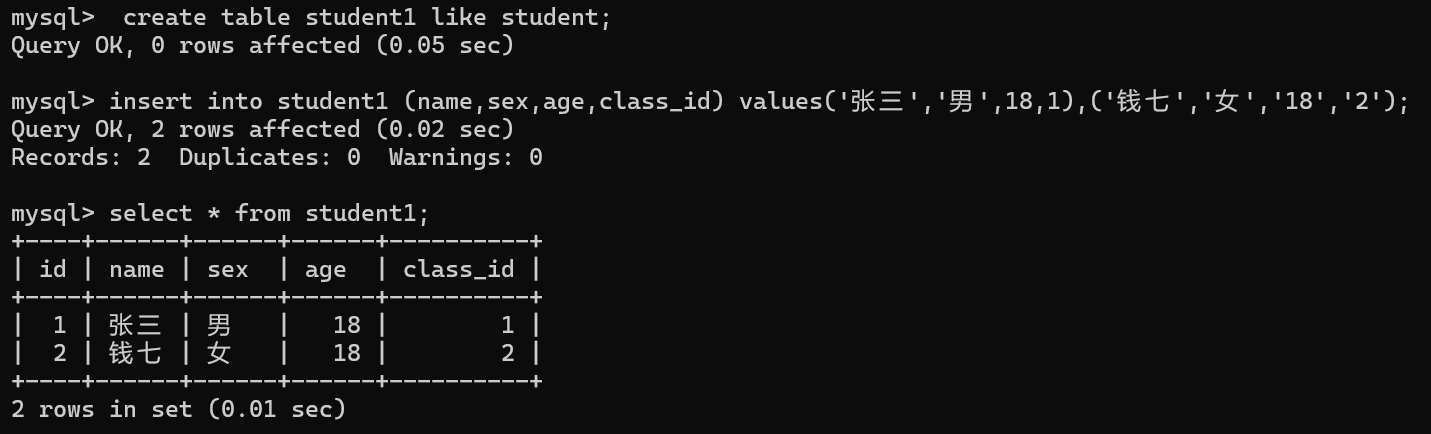
首先我们根据student表的形态再创建一个相同的表student1,同时进行数据的插入
(1)union
该操作符用于取得两个结果集的并集。当用该操作符时,会自动去掉结果集中的重复行。(去重)。
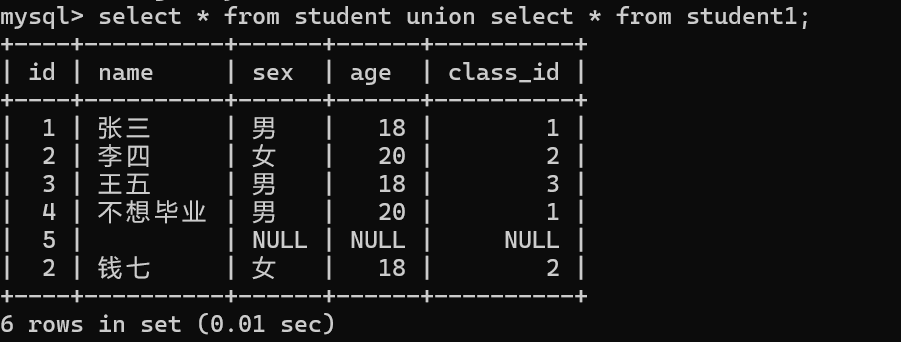
在这里我们会将student1中张三这一重复行的数据进行去重
(2)union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。(不去重)。
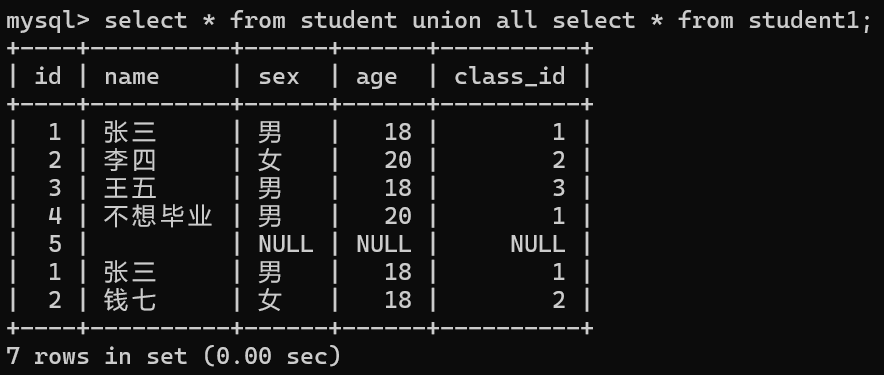
在这里我们会将student1中张三这一重复行的数据也显示在结果中。
好了今天的分享就到这里了,还请大家多多关注,我们下一篇见!