文章目录
- [5.1 观察视图](#5.1 观察视图)
-
- [5.1.1 视图模型---相机模型](#5.1.1 视图模型—相机模型)
- [5.1.2 视图模型--正交视图模型](#5.1.2 视图模型--正交视图模型)
- [5.2 用户变换](#5.2 用户变换)
- [5.3 OpenGL变换](#5.3 OpenGL变换)
-
- [5.3.1 高级技巧:用户裁减和剪切](#5.3.1 高级技巧:用户裁减和剪切)
- [5.3.2 OpenGL变换的控制(视口变换)](#5.3.2 OpenGL变换的控制(视口变换))
- [5.4 transform feedback](#5.4 transform feedback)
-
- [5.4.1 transform feedback对象](#5.4.1 transform feedback对象)
- [5.4.2 transform feedback缓存](#5.4.2 transform feedback缓存)
-
- [transform feedback缓存初始化过程](#transform feedback缓存初始化过程)
- [5.4.3 配置transform feedback的变量](#5.4.3 配置transform feedback的变量)
-
- [通过ogl api配置xfb变量](#通过ogl api配置xfb变量)
- 通过着色器配置xfb变量
- [5.4.4 transform feedback的启动和停止](#5.4.4 transform feedback的启动和停止)
- [5.4.5 transform feedback的示例:粒子系统](#5.4.5 transform feedback的示例:粒子系统)
5.1 观察视图
- 本章我们将学习如何将模型的三维坐标投影到固定的平面的二维幕坐标上。
- 将三维空间的模型投影到二维的关键方法,就是齐次坐标 (homogeneous coordinate的应用、矩阵乘法的线性变换方法 ,以及视口映射。
5.1.1 视图模型---相机模型
- 常见的视图模型操作可以类比为使用照相机拍摄照片的过程:
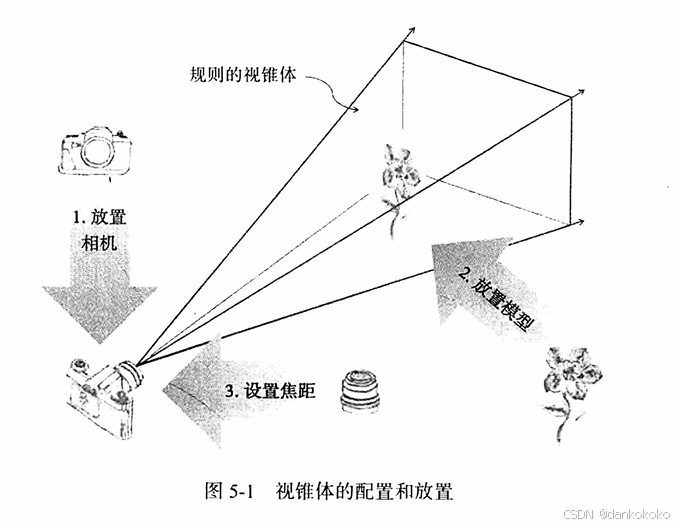
- 将相机移动到准备拍摄的位置,将它对准某个方向。
- 将准备拍摄的对象移动到场景中必要的位置上(模型变换,model transform)。
- 可以认为上面的第1步和第2步做的是同一件事情,只不过方向相反而已。
- 主要目的都是构建一个独立的、统一的空间系统,将场景中所有的物体都变换到视图空间,或者人眼空间(eye space)当中。
- 设置相机的焦距,或者调整缩放比例(投影变换,projection transform)。
- 拍摄照片(应用变换结果)。
- 对结果图像进行拉伸或者挤压,将它变换到需要的图片大小(视口变换,viewport transform)。
这一步同样需要对深度信息进行拉伸或者挤压(深度范围的缩放)。
第三步是选择捕捉场景的范围大小,而这一步是对结果的拉伸或挤压。
- 在OpenGL中,可以直接在着色器中完成第一步和第三步,也就是说传递给opengl的坐标应该是已经完成模型视图变换和投影变换的。
- 我们可以告诉opengl如何完成第五步,也可以让固定渲染管线自动完成这个变换过程(详见5.3节)
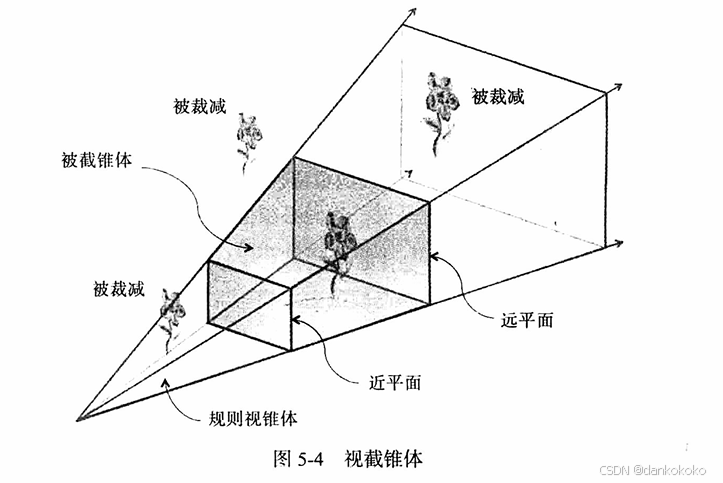
OpenGL的整个处理过程中所用到的坐标系统:

- 其实就是一般都存在模型、视图、投影变换:
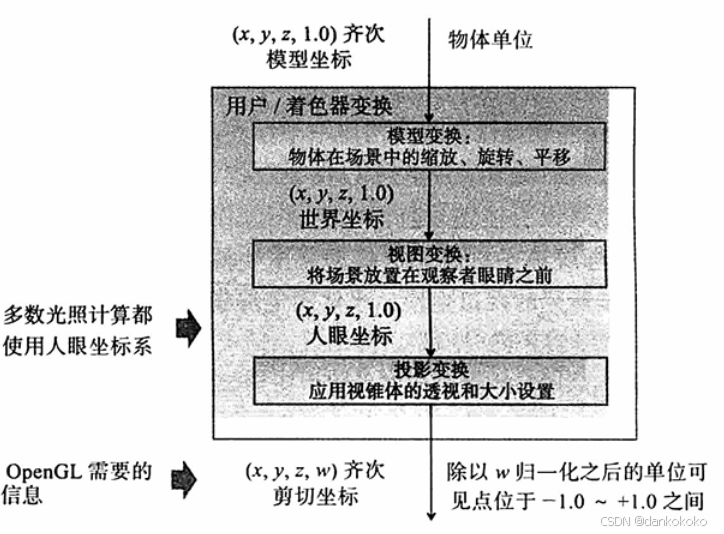
- 模型变换:局部到世界
- 相机/视图变换:相机位置为原点,再通过at和up获得正确的坐标系(例如相机向上对齐y轴,看向z轴或-z轴,x轴由at和up的叉乘获得)
此时物体的坐标会被重新计算为相对于相机的位置,从而方便后续的投影变换(如透视投影或正交投影)。
- 投影变换:压缩到标准化设备坐标,进而压缩到2D并存放进帧缓冲区。
- 典型的透视投影矩阵形式为:是先将平截锥体压缩成矩形,然后再进行一次正交投影获得
非线性深度值:- 正交投影矩阵:
因为w为1,所以不需要透视除法。- 更多深度值参考

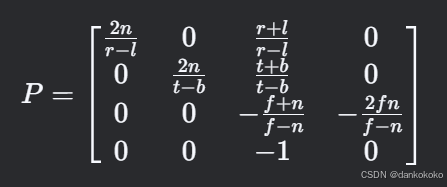

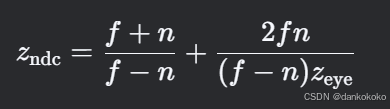
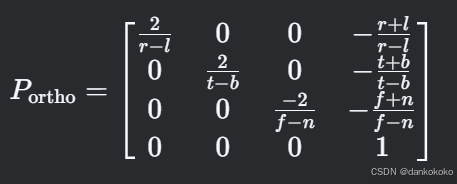
- 计算流程:
视锥体
- 设置的焦距或者缩放的数值,其实就是在相机拍摄场景时,设置取景用的矩形锥体的宽度或者窄度。同时,也是计算用于透视投影的"近大远小"效果的相关参数,具体在除以w的透视除法中。
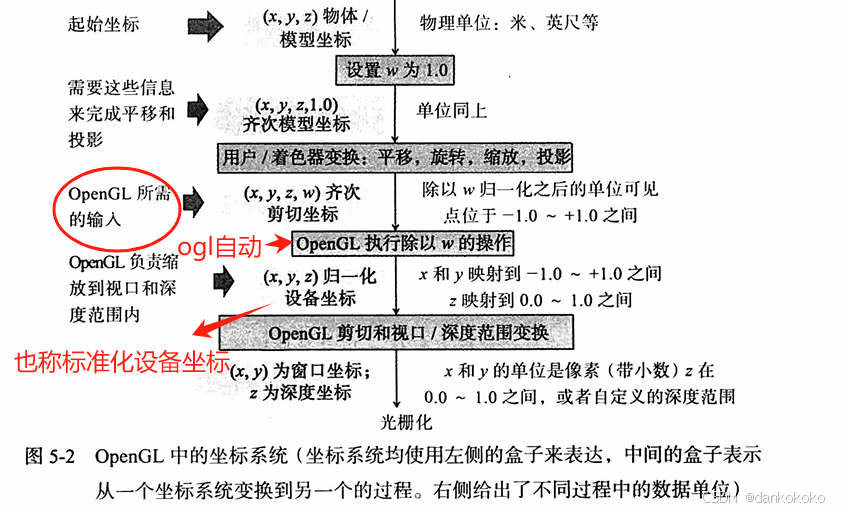
- 同时还设置近平面和远平面来去除过近(无限大的)和过远(深度值将涵盖一个非常大的范围)的物体。
视锥体的剪切
- 如果某个图元落在组成视锥体的四个平面之外,那么它将不会被绘制(它将被裁减,cull)。
- 如果有一个图元正好穿过这里的某个平面,OpenGL将会对此图元进行剪切(clip)。
- 它会负责计算几何体与平面的交集,然后将落入视锥体范围内的形状进行计算后会生成新的几何体。
- 着色器中也可以使用用户自定义的平面来进行剪切,详见后文。
5.1.2 视图模型--正交视图模型
- 它的主要作用是在投影之后依然保持物体的真实大小以及相互之间的角度。
- 我们可以简单地通过忽略x、y、z三个坐标轴中的一个来实现这一效果,也就是用其余两个构成二维坐标。
5.2 用户变换
- 在光栅化之前的各个阶段都是可编程来定制的,这对于坐标的处理方式以及变换方式才有这巨大的灵活性。
- 但是,最终还是要将输出传递给后继的几个固定阶段(不可编程),所以最后必需要生成可以用于透视除法的齐次坐标(也称作剪切坐标,clip coordinate)。
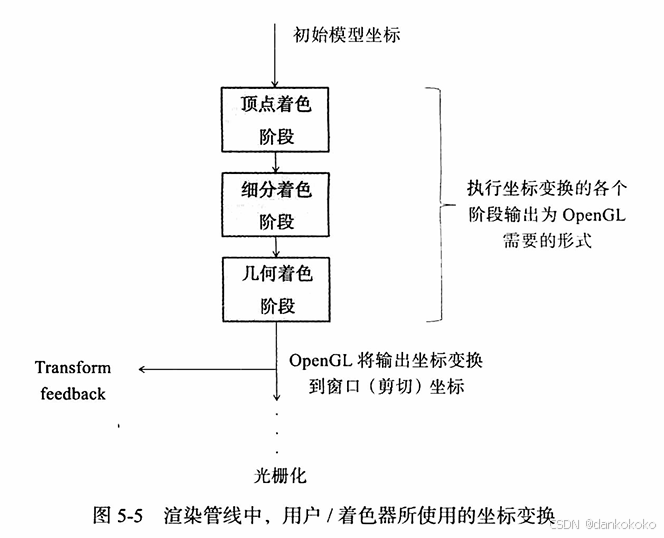
- 空间变换都是线性变换方式,可以通过齐次坐标的矩阵乘法来完成。这是opengl变换的关键所在。
- 在着色器中当中,使用矩阵对一个顶点进行变换的过程如下所示:
cpp
#version 330 core
uniform mat4 Transform;//对于各个顶点都是一致的(图元级别的粒度)
in vec4 Vertex;//每次传递的逐顶点数据
void main()
{
gl_Positon = Transform * Vertex;
}
- 线性变换是可以级联的,因此可以将任意数量的线性变换过程合并为一次矩阵乘法。
- 需要注意矩阵乘法没有交换律。
5.2.1 矩阵乘法的回顾
- 新向量的每个分量都是所有旧向量分量的一个线性函数,因为是通过矩阵进行线性变换,也意味着逆矩阵可以还原操作。
- 向量(0,0,0,0)与矩阵相乘的结果仍然是(0,0,0,0),这也是3x3的矩阵与三维向量相乘时无法表达平移操作的原因。
5.2.2 齐次坐标
- 准备进行变换的几何体本身就是三维形式,之所以将三维的笛卡尔坐标转换为四维的齐次坐标,主要是为了可以进一步完成透视变换 和使用线性变换来实现模型的平移。
- 更具体是因为想将能进行平移的仿射变换变成统一的线性变换。
- 因为我们规定w=1为point,而w=0为向量,即它表示一个"无限远的点"。
- 因此如果w越大,表示坐标位于更远的位置,那么透视除法除以w后,前三分量都会越小,绘制比例就越小,那么就能实现透视效果。
5.2.3 线性变换与矩阵
SRT
- 平移
cpp
Tmat4<T> translate(T x, T y, T z);- 缩放
cpp
Tmat4<T> scale(T x, T y, T z);如果想进行非同型变换(单独分量缩放),最好在视图变换完成之后再进行,过早进行会导致物体在旋转的时候变形。
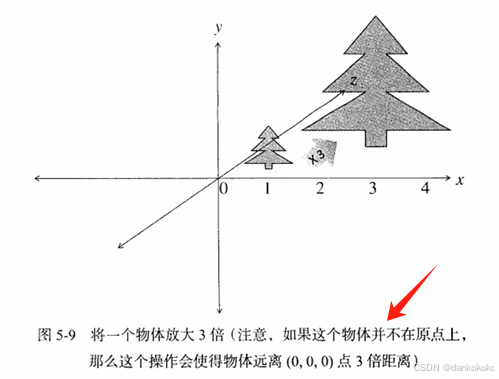
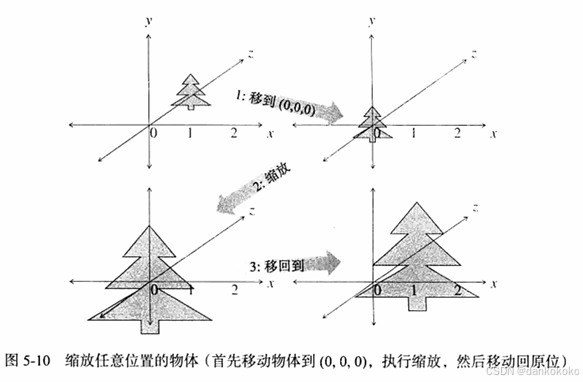
- 旋转
cpp
// 分别代表绕各个轴旋转的度数
Tmat4<T> rotate(T angle, T x, T y, T z);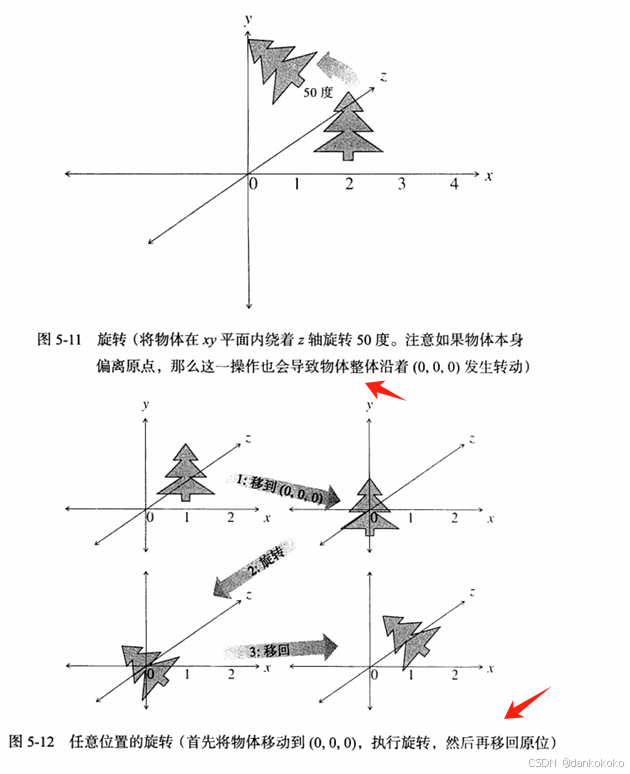
透视投影
- 观察点总是原点,并看向正z。
- 透视除法是ogl内部完成的。
cpp
// 视图
Tmat4<T> lookat(const vecN<T,3>& eye, const vecN<T,3>& center, const vecN<T,3>& up);
// 透视
mat4 frustum(float left, float right, float bottom, float top, float n, float f);
// 透视
mat4 perspective(float fovy, float aspect, float n, float f);
- 投影变换:压缩到标准化设备坐标,进而压缩到2D并存放进帧缓冲区。
- 典型的透视投影矩阵形式为:是先将平截锥体压缩成矩形,然后再进行一次正交投影获得
非线性深度值:
正交投影
cpp
mat4 ortho(float left, float right, float bottom, float top, float n, float f);
- 正交投影矩阵:
因为w为1,所以不需要透视除法。
5.2.4 法线变换
- 除了顶点的变换之外,还需要对表面法线进行变换,也就是从某个点出发,方向与物体表面垂直的一个向量。
- 法线是需要进行归一化的,也就是它的长度必须为1.0,主要是出于光照计算的目的。
- 法线向量通常是只有三个分量的向量,没有使用齐次坐标,因为物体表面的平移不会影响到法线的值。
- 但是我们并不能直接使用顶点的变换矩阵,而是先令M为3X3的矩阵,再令其为世界和视图矩阵的3X3形式,不包含投影矩阵,然后取M的逆矩阵的转置来当作法线变换矩阵。
- 并且如果M变换的内容(世界与视图变换)只涉及旋转和等轴缩放,那么M可以只包含旋转信息,不考虑缩放(因为法线会进行归一化处理,也是是单位化)。
逐像素计算法向量
- dFdx(v) = 该像素点右边的v值 - 该像素点的v值 // v 可以是任意值
- dFdy(v) = 该像素点下面的v值 - 该像素点的v值
- fwidth(v) = abs( dFdx(v) + dFdy(v))
- dFdx和dFdy都是计算dFdy计算一个变量在 x 方向或y方向的梯度,可用于计算法向量或光照效果。
- fwidth计算的是在x和y方向上的变化的绝对值的和。
- 都只能在片元着色器中使用。
- 且都是接收什么类型的参数,返回值就是什么类型的。
- 逐像素计算法向量
cpp
varying vec3 pos;
vec3 normal = normalize( cross(dFdx(pos), dFdy(pos)) );- 平滑颜色
cpp
// 从纹理中获取颜色
vec4 color = texture(texture1, TexCoords);
// 计算颜色在x方向的变化率
float colorChangeX = ddx(color.r); // 计算红色通道在x方向的变化
// 使用变化率对颜色进行调整
FragColor = vec4(color.rgb + vec3(colorChangeX), color.a);5.2.5 OpenGL矩阵
- 可以将矩阵通过uniform或逐顶点属性位置设置给着色器即可。
uniform mat4
cpp
// 着色器中定义
uniform mat4 model_matrix;
// 程序中定义
vmath::mat4 model_matrix;
glUseProgram(shaderProgram);
GLint render_model_matrix_loc = glGetUniformLocation(shaderProgram, "model_matrix");
model_matrix = vmath::translate(-3.0f, 0.0f, -5.0f);
// GL_FALSE是指以列为主序读取,按列进行传递,1代表uniform不是数组
glUniformMatrix4fv(render_model_matrix_loc, 1, GL_FALSE, model_matrix);给顶点属性设置矩阵(使用buffer)
cpp
// 着色器中定义
// Instanced vertex attributes
"// model_matrix will be used as a per-instance transformation matrix\n"
"// Note that a mat4 consumes 4 consecutive locations, so\n"
"// this will actually sit in locations, 3, 4, 5, and 6.\n"
layout (location = 3) in mat4 model_matrix;
// 程序中定义
int instanceNum = 4;//定义4个mat4的vertex attributes
glGenBuffers(1, &model_matrix_buffer);
glBindBuffer(GL_ARRAY_BUFFER, model_matrix_buffer);
glBufferData(GL_ARRAY_BUFFER, instanceNum * sizeof(vmath::mat4), NULL, GL_DYNAMIC_DRAW);
int matrix_loc = glGetAttribLocation(shaderProgram, "model_matrix");
// Loop over each column of the matrix...在矩阵的每一列上循环
for (int i = 0; i < 4; i++)
{
// Set up the vertex attribute
glVertexAttribPointer(matrix_loc + i, // 第i个属性
4,// 每个属性都是4分量
GL_FLOAT, // 数据类型
GL_FALSE, //不需要归一化
//一个顶点的stride,即更新的时候的跨步(按顶点更新或者instance更新)!
sizeof(vmath::mat4),
(void*)(sizeof(vmath::vec4) * i)); //在buffer中取当前这种属性的开头位置
// Enable it
glEnableVertexAttribArray(matrix_loc + i); // 启用这个属性索引
// Make it instanced
glVertexAttribDivisor(matrix_loc + i, 1);//每 1个实例都会分配一个新的属性值(需要更新属性值的属性索引为matrix_loc + i).
}
// Set model matrices for each instance
vmath::mat4* matrices = (vmath::mat4*)glMapBuffer(GL_ARRAY_BUFFER, GL_WRITE_ONLY);
for (int n = 0; n < instanceNum; n++)
{
matrices[n] = vmath::translate((float)n + (-4.0f), 0.0f, -5.0f);
}
glUnmapBuffer(GL_ARRAY_BUFFER);ogl中矩阵行与列

- 只有一种情形下我们需要考虑矩阵的列主序或者行主序关系,那就是将GLSL矩阵放人自定义的内存块时。
为了通知GLSL从内存中正确加载矩阵数据,需要使用布局限定符row_major和 column_major。
layout(shared,row_major)uniform{...};

5.3 OpenGL变换
z坐标的变化范围
- 如果我们需要通知OpenGL在何处放置近平面和远平面,即定义视口变换过程中z坐标的变化范围,可以使用:
cpp
//默认情况下它们分别是0.0和1.0,这个函数的参数设置范围必须是[0,1]之间的数值。
void glDepthRange( GLdouble nearVal,
GLdouble farVal);
void glDepthRangef( GLfloat nearVal,
GLfloat farVal);视口
cpp
void glViewport(GLint x,
GLint y,
GLsizei width,
GLsizei height);
在程序窗口中定义一个矩形的像素区域,并且将最终渲染的图像映射到其中。这里的x和y参数设置了视口(viewport)的左下角坐标,而width和height 设置了视口矩形的像素大小。默认情况下视口初始值设置为(0,0,winWidth,winHeight),其中winWidth和 winHeight 为窗口的像素尺寸。
多视口
- 可以使用gIViewport()来选择一个更小的绘制区域;例如,我们可以通过分割窗口来模拟同一个窗口中多个视图分裂的效果。
- OpcnGL提供了相应的命令支持,并且可以在几何着色阶段选择具体要进行绘制的视口,例如多视口,详见10.6
z的精度/深度冲突z-fighting
- 计算过程中,硬件的浮点数精度支持是有限的,从而导致在数学上深度坐标应该是不同的,但是硬件中最终记录的浮点数z值可能是相同的(甚至与实际结果相反),因而导致相互距离较为接近的物体会发生闪烁交叠的情形。
- 经过透视变换之后,z的精度问题可能会恶化,无论对于深度坐标还是其他类型的坐标值都是如此:此时如果深度坐标远离近剪切平面,那么它的位置精度将越来越低
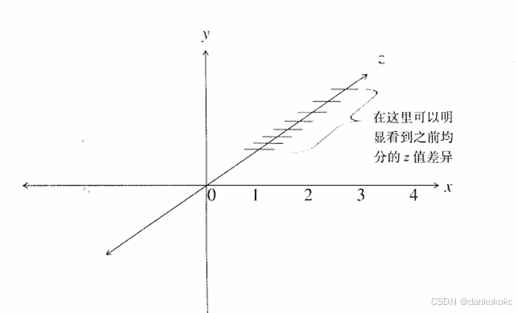
这是因为透视投影深度值是非线性
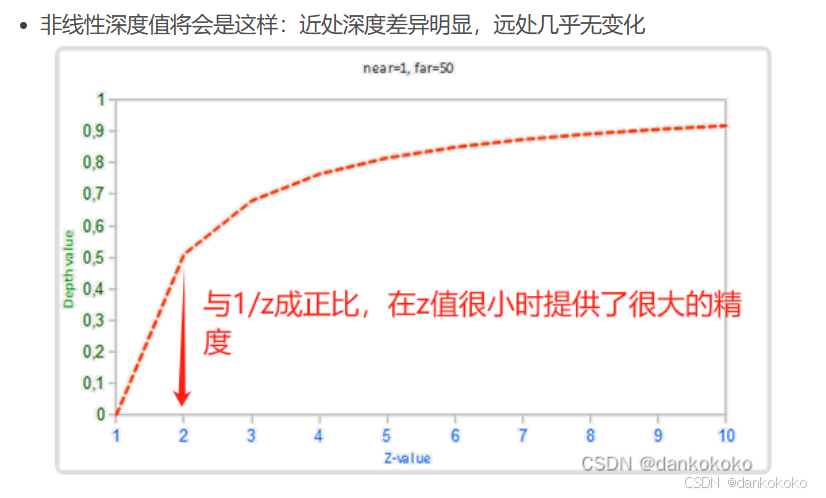
- 就算没有经过透视变换,浮点数的精度也是有限的,这样在深度值较大的时候会带来更多的问题。
- 这个问题的根源是我们在一个过小的z值区域内绘制了过多的数据。如果要避免这个问题,我们需要尽量将远平面与近平面靠近,并且尽可能不要在一个很小的区域内绘制过多的z值。
5.3.1 高级技巧:用户裁减和剪切
- OpenGL会自动根据视口和近平面与远平面的设置来裁减(筛选的意思)和剪切几何体。
用户裁减和剪切的意思就是再添加一些任意方向的平面,与几何数据相交,例如只允许几何体在平面的一侧可见,而另一侧不可见。
- OpenGL的用户裁减和剪切操作需要特殊的内置顶点着色器数组gl_CullDistance\[\]和gl_ClipDistance\[\]联合产生作用。
这两个变量允许我们控制裁减和剪切平面与顶点的关系。它们的值经过插值之后设置给顶点之间的各个片元。
- 定义平面(A,B,C,D)

- gl_CullDistance\[\]和gl_ClipDistance\[\]数组的每个元素都对应于一个平面(其实是顶点和定义的平面的点乘结果)。
- 平面的数量是有限的,通常为8个或者更多,并且是两者共用的。这个总数可以通过gl_MaxCombinedClipAndCullDistance来查询,还可以通过gl_MaxClipDistance和gl_MaxCullDistance来查询。
- gl_CullDistance\[\]和gl_ClipDistance\[\]变量在声明时并没有指定大小,而我们用到的平面数量(数组元素)是在着色器中设置的。因此需要重新声明它的大小。
- gl_CullDistance\[\]和gl_ClipDistance\[\]必须包含所有已经通过OpenGLAPI启用的剪切平面;如果它没有包括所有启用的剪切平面,那么得到的结果可能是不确定的。启用:
cpp
glEnable[GL_CLIP_PLANE0+i]着色器中必须写入所有启用的平面距离值,否则可能会得到奇怪的剪切结果。
- gl_CullDistance\[\]和gl_ClipDistance\[\]在片元着色器中也是可用的,没有被剪切的片元可以读取每个剪切平面的距离插值结果.
gl_ClipDistance的简单用法
cpp
#version 450 core
uniform vec4 plane;
in vec4 vertex;
float gl_ClipDistance[1];//使用一个剪切平面
void main()
{
// 计算平面方程
gl_ClipDistance[0] = dot(vertex,plane);
}- 这个变量的含义是,距离为0表示顶点落在平面之上,正数值表示顶点在剪切平面的内侧(或说保留这个顶点),负数值表示顶点在剪切平面的外侧(或裁减这个顶点)。
- 在图元中剪切距离是线性插值的。OpenGL会负责将完全落在某个裁减平面之外的图元剔除。(如果图元与所有的裁减平面相交且有一部分落在它们的内侧,则认为它应当被保留。)
- 此外,OpenGL会直接抛弃所有距离值小于0的片元。
5.3.2 OpenGL变换的控制(视口变换)
- 默认情况下,OpenGL会映射剪切空间的坐标(0,0)到窗口空间的中心,x坐标轴正向指向右侧,y坐标轴正向指向上方。因此(-1,-1)将位于窗口的左下方,(1,1)将位于窗口的右上方。
- 有些图形系统会将深度取值范围映射到-1.0,1.0,也有些是将剪切空间中-z的坐标值表示观察者身后的位置,因此可见的深度范围在剪切空间中会被映射到0.0到1.0。
- OpenGL允许你重新配置这两种映射方式
cpp
// 设置剪切坐标到窗口坐标的映射方式。
// origin设置的是窗口坐标x和y的原点
// 而depth 设置的是剪切空间深度值映射到glDepthRange()所设置的数值的方式。
// origin Must be one of GL_LOWER_LEFT or GL_UPPER_LEFT.
// GL_LOWER_LEFT :xy坐标(-1.0,-1.0)对应窗口坐标的左下角.
// GL_UPPER_LEFT:xy坐标(-1.0,-1.0)对应窗口坐标的左上角.
// depth Must be one of GL_NEGATIVE_ONE_TO_ONE or GL_ZERO_TO_ONE.
// GL_NEGATIVE_ONE_TO_ONE :那么窗口空间中的深度对应于剪切空间的[-1.0,1.0].
// GL_ZERO_TO_ONE:那么剪切空间的[0.0,1.0]范围将被映射到窗口空间的深度值,此时0.0表示近平面,1.0表示远平面。
//剪切空间的z负值变换后将处于近平面的后方,但是观察者眼前(近处)的数据精度值会变得更高。
void glClipControl( GLenum origin,
GLenum depth);5.4 transform feedback
- 是OpenGL管线中,顶点处理阶段结束之后,图元装配和光栅化之前的一个步骤。
更准确地说,transfomfeedback是与图元装配过程紧密结合的,这是因为整个图元数据都会被捕获到级存对象中。而这里我们可以认为是缓存的空间不够,因此必须丢弃一部分图元。为了确保这一过程,需要在transform feedback阶段给出当前的图元类型信息。
- 可以重新捕获即将装配为图元(点、线段、三角形)的顶点然后将它们的部分或者全部属性传递到缓存对象中。
5.4.1 transform feedback对象
- transform feedback对象主要用于管理将顶点捕捉到缓存对象的相关状态,包括所有用于记录顶点数据的缓存对象、用于标识缓存对象的充满程度的计数器、以及用于标识 transform feedback当前是否启用的状态量。
- 系统会内置一个默认的对象。这个默认 transform feedback对象的id为0.
- 分配一个transform feedback对象的名称:
cpp
// 会包含一个默认的transformfeedback状态,并在需要的时候绑定到环境
void glCreateTransformFeedbacks(GLsizei n,GLuint *ids);- 如果要将一个transform feedback对象绑定到当前环境,需要使用:
cpp
// target must be GL_TRANSFORM_FEEDBACK.
void glBindTransformFeedback(GLenum target,GLuint id);- 判断某个值是否是一个transform feedback对象的名称:
cpp
GLboolean glIsTransformFeedback(GLuint id);- 删除
cpp
// 如果ids不是transform feedback对象名称或者为0则会忽略。
void glDeleteTransformFeedbacks(GLsizei n,const GLuint *ids);删除对象的操作会延迟到所有相关的操作结束之后才进行。也就是说,如果当前transform feedback对象处于启用状态,而我们调用 glDeleteTransformFeedbacks(),那么只有本次 transform feedback结束之后,才会删除对象。
5.4.2 transform feedback缓存
-
transformfeedback缓存绑定点的总数是一个与具体设备实现相关的常量,可以通过GL_MAX_TRANSFORM_FEEDBACK_BUFFERS的值来查询,至少64个。
-
可以同时给transformfeedback对象绑定多个缓存,也可以绑定缓存对象的多个子块。
-
我们甚至可以将同一个缓存对象的不同子块同时绑定到不同的transform feedback 缓存绑定点。
-
将整个缓存对象绑定到某个 transform feedback缓存绑定点:
cpp
// 将名为buffer的缓存对象绑定到名为xfb的transformfeedback对象上,其缓存绑定点索引通过index设置。
void glTransformFeedbackBufferBase( GLuint xfb,
GLuint index,
GLuint buffer);
glBindBufferBase- 将一个缓存对象的一部分绑定到某个 transform feedback缓存绑定点:
cpp
void glTransformFeedbackBufferRange(GLuint xfb,
GLuint index,
GLuint buffer,
GLintptr offset,
GLsizei size);这个函数可以用来将同一个缓存对象的不同区域绑定到不同的transform feedback绑定点,我们需要保证这些区域是互不交叠的
transform feedback缓存初始化过程
cpp
GLunit buffer;
glCreateBuffers(1,&buffer);
glNamedBufferStorage(buffer,1024*1024,NULL,0);
glTransformFeedbackBufferRange(xfb,0,buffer,0,512*1024);
glTransformFeedbackBufferRange(xfb,1,buffer,512*1024,512*1024);
// 也可以使用glBindBuffersRange来替代调用两次glTransformFeedbackBufferRangeglNamedBufferStorage中flags参数设置为0,ogl会假设该缓存对象的用途:它不会被映射,也不会在 CPU端改变内容。
5.4.3 配置transform feedback的变量
通过ogl api配置xfb变量
- 设置 transform feedback 过程中要记录哪些变量:
cpp
//count设置 varyings 数组中所包含的字符串的数量。
//设置使用 varyings 来记录transformfeedback的信息,
//varyings是一个字符串数组,其中记录所有输出到片元(或者几何)着色器中的,同时需要通过transformfeedback获取的变化量。
// bufferMode must be GL_INTERLEAVED_ATTRIBS or GL_SEPARATE_ATTRIBS.它标识transform feedback中捕获的变量是如何分配的。
// GL_INTERLEAVED_ATTRIBS :所有的变量是一个接着一个记录在绑定到当前transformfeedback对象的第一个绑定点的缓存对象里的。
//GL_SEPARATE_ATTRIBS:那么每个变量都会记录到一个单独的缓存对象中。
void glTransformFeedbackVaryings( GLuint program,
GLsizei count,
const char **varyings,
GLenum bufferMode);
//
static const char*const vars[] =
{
"foo","bar","baz"
};
glTransformFeedbackVaryings(prog,sizeof(vars)/sizeof(vars[0]),vars,GL_INTERLEAVED_ATTRIBS);
glLinkProgram(prog);
- glTransformFeedbackVaryings中所选择的变量只有程序对象再一次被链接的时候才会起作用。
- 现在只要执行prog就会将写人到VERTEX 2foo、bar和baz的数据记录到当前transformfeedback对象所绑定的缓存当中
- GL_INTERLEAVED_ATTRIBS
- GL_SEPARATE_ATTRIBS
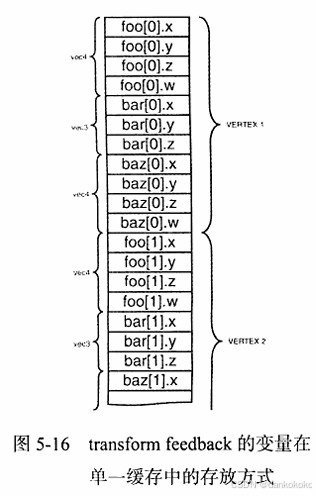
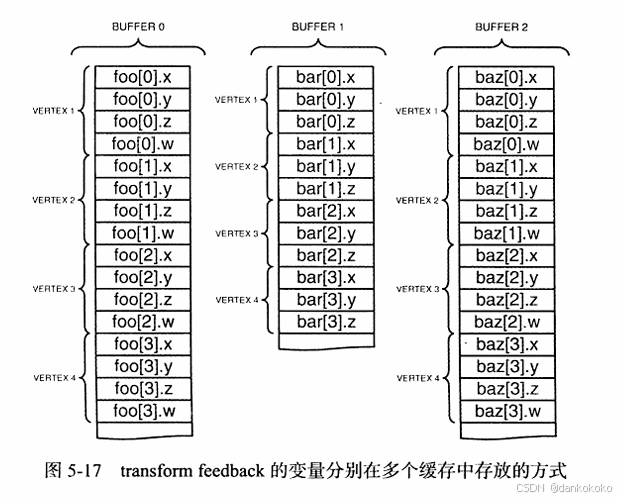
- 两种mode都是紧密排列的,但是有时候还是需要使用不同的对齐方式,用于在缓存中留一些空隙不写入数据。例如gl_SkipComponents和gl_NextBuffer,并且只有mode为GL_INTERLEAVED_ATTRIBS才可使用。
- 遇到内置变量gl_SkipComponents,就会在 transform feedback 缓存中留出一个指定数量(1、2、3、4)的空隙(例如gl_SkipComponents1).
cpp
static const char*const vars[] =
{
"foo","gl_SkipComponents2","baz"
};
glTransformFeedbackVaryings(prog,sizeof(vars)/sizeof(vars[0]),vars,GL_INTERLEAVED_ATTRIBS);
glLinkProgram(prog);- 遇到内置变量gl_NextBuffer,那么它会将变量传递到当前绑定的下一个 transform feedback缓存中。
- 遇到两个或者多个gl_NextBuffer 的示例,那么它将会直接跳过当前的绑定点,并且在当前绑定的缓存中不会记录任何的数据。
cpp
```cpp
static const char*const vars[] =
{
"foo","gl_SkipComponents1","baz","gl_SkipComponents2",
"gl_NextBuffer ",
"gl_SkipComponents4","baz","gl_SkipComponents2",
"gl_NextBuffer ",
"gl_NextBuffer ",
"iron","gl_SkipComponents3","copper"
};
glTransformFeedbackVaryings(prog,sizeof(vars)/sizeof(vars[0]),vars,GL_INTERLEAVED_ATTRIBS);
glLinkProgram(prog);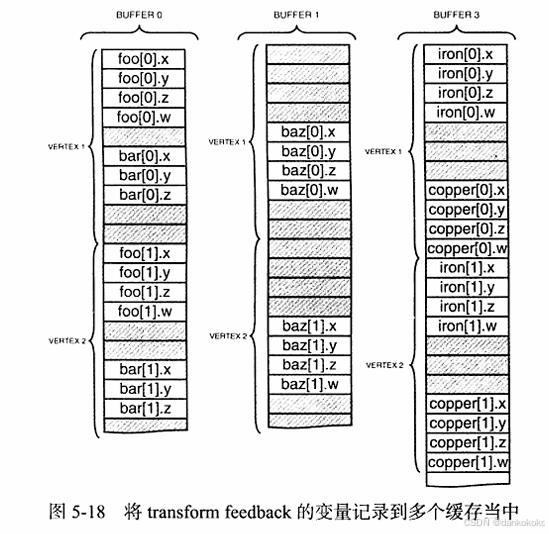
通过着色器配置xfb变量
- 如果使用着色器配置,就尽量不要使用glTransformFeedbackVaryings。
- 需要使用以下的着色器layout限定符:
- xfb_buffer 设置变量对应的缓存。
- xfb_offset设置变量在缓存中的位置,决定了是否捕获该变量。
- xfb_stride 设置数据从一个顶点到下一个的排列方式,用来实现使用api时可设置的空隙。
- 跨幅和偏移量的设置值必须是4的倍数,除非其中包含了双精度(double)类型的数据,此时必须设置为8的倍数。


- 我们可以针对一个缓存的情况设置默认的跨幅,此时不需要指定变量:
layout(xfb_buffer=l,xfb_stride=40) out;,之后对这个缓存的数据再使用xfb offset的时候,会直接采用之前的默认跨幅值。
5.4.4 transform feedback的启动和停止
- transform feedback可以随时启动或者停止,甚至暂停。
- 如果transform feedback正处于暂停的状态,那么再次启动它将会从之前暂停的位置开始记录。
- 启用:
cpp
//设置 transform feedback准备记录的图元类型.
//
void glBeginTransformFeedback(GLenum primitiveMode);
- 限制条件
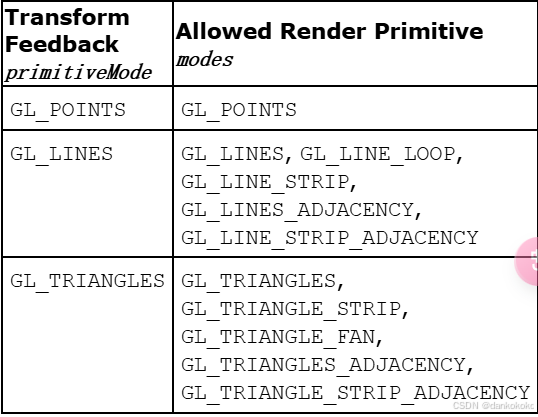
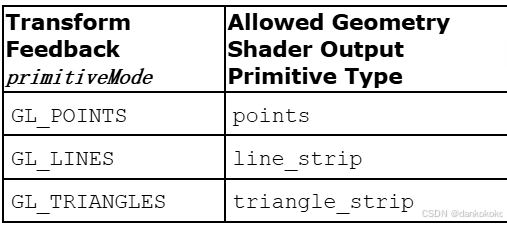
- 在这之后的绘制命令中的图元类型必须 与这里的primitiveMode相符,或者几何着色器(如果存在的话)的输出类型必须与primitiveMode相符。
- 当前绑定的 transform feedback 对象不可改变。
- 不允许将其他的缓存绑定到GLTRANSFORMFEEDBACKBUFFER 的绑定点。
- 当前的程序对象不可改变。

- 暂停:当transform feedback暂停之后,它依然是启用状态,但是暂时不会向 transform feedback缓存中记录任何数据。
cpp
// 如果当前的 transform feedback没有启用,或者已经处于暂停状态,glPauseTransformFeedback将产生一个错误。
void glPauseTransformFeedback(void);- 重启:
cpp
//重新启用一个之前通过glPauseTransformFeedback暂停的transform feedback过程。
// 如果transformfeedback没有启用或者已经启用但是没有处于暂停状态,glResumeTransformFeedback会产生一个错误。
void glResumeTransformFeedback(void);
- 结束:
cpp
//如果已经完成了所有transform feedback图元的渲染,我们可以使用该函数重新切换到正常的渲染模式
void glEndTransformFeedback(void);5.4.5 transform feedback的示例:粒子系统
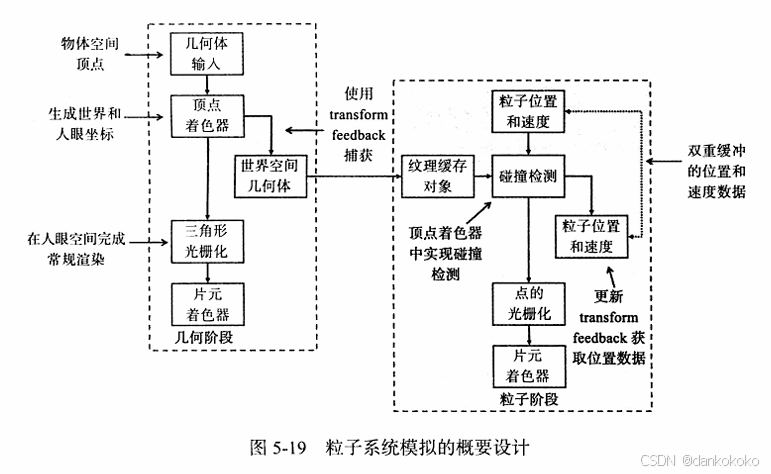
- 这个程序通过两个步骤使用 transform feedback实现了一个粒子系统。
- 第一步当中,使用transformfeedback获取/截取OpenGL管线中的几何数据,同时进行粒子的绘制。 - 在第二步同时使用捕获的几何数据和另一个transformfeedback的实例一起实现一个粒子系统,其中使用顶点着色器来实现粒子和之前渲染的几何体的碰撞检测,并更新粒子位置(所以粒子的截取需要使用到兩個buffer)。
cpp
#include<iostream>
#include<glad/glad.h>
#include<GLFW/glfw3.h>
#include <GL/gl.h>
#include "vmath.h"
#include "shader.h"
// Vertex Shader source code
const char* vertexShaderSource = "#version 450 core\n"
"layout (location = 0) in vec4 position;\n"
"layout (location = 1) in vec4 color;\n"
"out vec4 vs_fs_color;\n"
"uniform mat4 model_matrix;\n"
"uniform mat4 projection_matrix;\n"
"out vec4 world_space_position;\n"
"out vec3 vs_fs_normal;\n"
"void main()\n"
"{\n"
" vec4 pos = (model_matrix * (position * vec4(1.0, 1.0, 1.0, 1.0)));\n"
" world_space_position = pos;\n"
" gl_Position = pos;\n"
" //vs_fs_normal = normalize(vec3(0,0,-1));\n"
" vec3 normal = vec3(0,0,-1);\n"
" vs_fs_normal = normalize((model_matrix * vec4(normal, 0.0)).xyz);\n"
" vs_fs_color = color;\n"
"}\0";
//Fragment Shader source code
const char* fragmentShaderSource = "#version 450 core\n"
"in vec4 vs_fs_color;\n"
"layout (location = 0) out vec4 color;\n"
"void main()\n"
"{\n"
" color = vs_fs_color;\n"
"}\n\0";
const GLfloat vertices[] =
{
-0.5f, -0.5f, 0.0f,1.0f,
0.5f, -0.5f, 0.0f,1.0f,
0.0f, 0.5f, 0.0f,1.0f,
};
//const GLfloat verticesOutline[] =
//{
// -0.55f, -0.55f, -0.01f,1.0f,
// 0.55f, -0.55f, -0.01f,1.0f,
// 0.0f, 0.55f, -0.01f , 1.0f,
//
//};
const GLfloat verticesOutline[] =
{
-0.55f, -0.55f, 0.0f,1.0f,
0.55f, -0.55f, 0.0f,1.0f,
0.0f, 0.55f, 0.0f , 1.0f,
};
const GLfloat colors[] =
{
1.0f, 0.0f, 0.0f,1.0f,
1.0f, 0.0f, 0.0f,1.0f ,
1.0f, 0.0f, 0.0f,1.0f ,
};
const GLubyte colorsNeedNormal[] =
{
255, 255, 255,255,
255, 255, 0,255 ,
255, 0, 255,255 ,
};
// 编译链接着色器的辅助函数
unsigned int shaderProgram(const char* vertexSrc, const char* fragmentSrc) {
// 创建并编译顶点着色器
unsigned int vertexShader = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vertexShader, 1, &vertexSrc, NULL);
glCompileShader(vertexShader);
int result;
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &result);
if (result == GL_FALSE)
{
int length;
glGetShaderiv(vertexShader, GL_INFO_LOG_LENGTH, &length);
char* message = (char*)alloca(length * sizeof(char));
glGetShaderInfoLog(vertexShader, length, &length, message);
std::cout << message << std::endl;
glDeleteShader(vertexShader);
return -1;
}
// 创建并编译片段着色器
unsigned int fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentSrc, NULL);
glCompileShader(fragmentShader);
glGetShaderiv(fragmentShader, GL_COMPILE_STATUS, &result);
if (result == GL_FALSE)
{
int length;
glGetShaderiv(fragmentShader, GL_INFO_LOG_LENGTH, &length);
char* message = (char*)alloca(length * sizeof(char));
glGetShaderInfoLog(fragmentShader, length, &length, message);
std::cout << message << std::endl;
glDeleteShader(fragmentShader);
return -1;
}
// 创建着色器程序并链接
unsigned int program = glCreateProgram();
glAttachShader(program, vertexShader);
glAttachShader(program, fragmentShader);
glLinkProgram(program);
// 删除临时着色器对象
glDeleteShader(vertexShader);
glDeleteShader(fragmentShader);
return program;
}
GLint model_matrix_loc;
GLint projection_matrix_loc;
GLint triangle_count_loc;
GLint time_step_loc;
GLint render_model_matrix_loc;
GLint render_projection_matrix_loc;
const int point_count = 5000;
GLuint geometry_tex;
GLuint vao[2];
GLuint vbo[2];
GLuint xfb;
GLuint geometry_vbo;
GLuint render_vao;
//unsigned int render_prog;
unsigned int update_prog;
unsigned int redShader;
int i, j;
static unsigned int seed = 0x13371337;
static inline float random_float()
{
float res;
unsigned int tmp;
seed *= 16807;
tmp = seed ^ (seed >> 4) ^ (seed << 15);
*((unsigned int*)&res) = (tmp >> 9) | 0x3F800000;
return (res - 1.0f);
}
static vmath::vec3 random_vector(float minmag = 0.0f, float maxmag = 1.0f)
{
vmath::vec3 randomvec(random_float() * 2.0f - 1.0f, random_float() * 2.0f - 1.0f, random_float() * 2.0f - 1.0f);
randomvec = normalize(randomvec);
randomvec *= (random_float() * (maxmag - minmag) + minmag);
return randomvec;
}
static inline int min(int a, int b)
{
return a < b ? a : b;
}
void Initialize()
{
update_prog = shaderProgram(update_vs_source, white_fs);
static const char* varyings[] =
{
"position_out", "velocity_out"
};
glTransformFeedbackVaryings(update_prog, 2, varyings, GL_INTERLEAVED_ATTRIBS);
glLinkProgram(update_prog);
glUseProgram(update_prog);
model_matrix_loc = glGetUniformLocation(update_prog, "model_matrix");
projection_matrix_loc = glGetUniformLocation(update_prog, "projection_matrix");
triangle_count_loc = glGetUniformLocation(update_prog, "triangle_count");
time_step_loc = glGetUniformLocation(update_prog, "time_step");
//
static const char* varyings2[] =
{
"world_space_position"
};
glTransformFeedbackVaryings(redShader, 1, varyings2, GL_INTERLEAVED_ATTRIBS);
glLinkProgram(redShader);
glUseProgram(redShader);
render_model_matrix_loc = glGetUniformLocation(redShader, "model_matrix");
render_projection_matrix_loc = glGetUniformLocation(redShader, "projection_matrix");
// 输入和输出粒子buffer
glGenVertexArrays(2, vao);
glGenBuffers(2, vbo);
for (i = 0; i < 2; i++)
{
glBindBuffer(GL_TRANSFORM_FEEDBACK_BUFFER, vbo[i]);
glBufferData(GL_TRANSFORM_FEEDBACK_BUFFER, point_count * (sizeof(vmath::vec4) + sizeof(vmath::vec3)), NULL, GL_DYNAMIC_COPY);
if (i == 0)
{
struct buffer_t {
vmath::vec4 position;
vmath::vec3 velocity;
} *buffer = (buffer_t*)glMapBuffer(GL_TRANSFORM_FEEDBACK_BUFFER, GL_WRITE_ONLY);
for (j = 0; j < point_count; j++)
{
buffer[j].velocity = random_vector();
buffer[j].position = vmath::vec4(buffer[j].velocity + vmath::vec3(-0.5f, 40.0f, 0.0f), 1.0f);
buffer[j].velocity = vmath::vec3(buffer[j].velocity[0], buffer[j].velocity[1] * 0.3f, buffer[j].velocity[2] * 0.3f);
}
glUnmapBuffer(GL_TRANSFORM_FEEDBACK_BUFFER);
}
glBindVertexArray(vao[i]);
glBindBuffer(GL_ARRAY_BUFFER, vbo[i]);
glVertexAttribPointer(0, 4, GL_FLOAT, GL_FALSE, sizeof(vmath::vec4) + sizeof(vmath::vec3), NULL);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, sizeof(vmath::vec4) + sizeof(vmath::vec3), (GLvoid*)sizeof(vmath::vec4));
glEnableVertexAttribArray(0);
glEnableVertexAttribArray(1);
}
//
glGenBuffers(1, &geometry_vbo);
glGenTextures(1, &geometry_tex);
glBindBuffer(GL_TEXTURE_BUFFER, geometry_vbo);
glBufferData(GL_TEXTURE_BUFFER, 800 * 600 * sizeof(vmath::vec4), NULL, GL_DYNAMIC_COPY);
glBindTexture(GL_TEXTURE_BUFFER, geometry_tex);
glTexBuffer(GL_TEXTURE_BUFFER, GL_RGBA32F, geometry_vbo);
glGenVertexArrays(1, &render_vao);
glBindVertexArray(render_vao);
glBindBuffer(GL_ARRAY_BUFFER, geometry_vbo);
glVertexAttribPointer(0, 4, GL_FLOAT, GL_FALSE, 0, NULL);
glEnableVertexAttribArray(0);
glClearColor(0.0f, 0.0f, 0.0f, 1.0f);
glClearDepth(1.0f);
}
float t = 0;
float q = 0.0f;
void Display()
{
static int frame_count = 0;
static const vmath::vec3 X(1.0f, 0.0f, 0.0f);
static const vmath::vec3 Y(0.0f, 1.0f, 0.0f);
static const vmath::vec3 Z(0.0f, 0.0f, 1.0f);
if (t > 1.0)
t = 0;
vmath::mat4 projection_matrix(vmath::frustum(-1.0f, 1.0f, -800.0/600.0, 800.0/600.0, 1.0f, 5000.0f) /** vmath::translate(0.0f, 0.0f, -100.0f)*/);
vmath::mat4 model_matrix(
vmath::rotate(t * 360.0f, 0.0f, 1.0f, 0.0f) *
vmath::rotate(t * 360.0f * 3.0f, 0.0f, 0.0f, 1.0f));
t += 0.01;
glUseProgram(redShader);
glUniformMatrix4fv(render_model_matrix_loc, 1, GL_FALSE, model_matrix);
glUniformMatrix4fv(render_projection_matrix_loc, 1, GL_FALSE, projection_matrix);
}
int main() {
// 初始化GLFW
if (!glfwInit()) {
std::cerr << "Failed to initialize GLFW" << std::endl;
return -1;
}
// 创建窗口
GLFWwindow* window = glfwCreateWindow(800, 600, "Stencil Border with Depth", NULL, NULL);
if (!window) {
std::cerr << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);
gladLoadGL();
// 创建着色器程序
redShader = shaderProgram(vertexShaderSource, fragmentShaderSource);
Initialize();
// 配置顶点数据
unsigned int VAOs[2], VBOs[2];
glGenVertexArrays(2, VAOs);
glGenBuffers(2, VBOs);
// 设置原始三角形VAO
glBindVertexArray(VAOs[0]);
glBindBuffer(GL_ARRAY_BUFFER, VBOs[0]);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices) + sizeof(colorsNeedNormal), NULL, GL_STATIC_DRAW);
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(vertices), vertices);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(vertices), sizeof(colorsNeedNormal), colorsNeedNormal);
glVertexAttribPointer(0, 4, GL_FLOAT, GL_FALSE, 0, NULL);
glVertexAttribPointer(1, 4, GL_UNSIGNED_BYTE, GL_TRUE, 0, (const GLvoid*)sizeof(vertices));
glEnableVertexAttribArray(0);
glEnableVertexAttribArray(1);
// 设置边框三角形VAO
glBindVertexArray(VAOs[1]);
glBindBuffer(GL_ARRAY_BUFFER, VBOs[1]);
glBufferData(GL_ARRAY_BUFFER, sizeof(verticesOutline) + sizeof(colors), NULL, GL_STATIC_DRAW);
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(verticesOutline), verticesOutline);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(verticesOutline), sizeof(colors), colors);
glVertexAttribPointer(0, 4, GL_FLOAT, GL_FALSE, 0, NULL);
glVertexAttribPointer(1, 4, GL_FLOAT, GL_FALSE, 0, (const GLvoid*)sizeof(vertices));
glEnableVertexAttribArray(0);
glEnableVertexAttribArray(1);
// 主渲染循环
while (!glfwWindowShouldClose(window))
{
static const float black[] = { 0.0f,0.0f,0.0f,0.0f };
glClearBufferfv(GL_COLOR, 0, black);
glClear(GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
// 启用模板测试
glEnable(GL_STENCIL_TEST);
glEnable(GL_DEPTH_TEST);
glDepthFunc(GL_LEQUAL);
//glEnable(GL_CULL_FACE);
// --- 第1步:绘制红色三角形 ---
glStencilFunc(GL_ALWAYS, 1, 0xFF); // 总是通过模板测试,将三角形对应像素模板值写入1
glStencilOp(GL_REPLACE, GL_REPLACE, GL_REPLACE); // 通过时替换为1
//glUseProgram(redShader);
glBindBufferBase(GL_TRANSFORM_FEEDBACK_BUFFER, 0, geometry_vbo);
static int frame_count = 0;
static const vmath::vec3 X(1.0f, 0.0f, 0.0f);
static const vmath::vec3 Y(0.0f, 1.0f, 0.0f);
static const vmath::vec3 Z(0.0f, 0.0f, 1.0f);
/* if (t > 1.0)
t = 0;*/
vmath::mat4 projection_matrix(vmath::frustum(-1.0f, 1.0f, -800.0 / 600.0, 800.0 / 600.0, 1.0f, 5000.0f) /** vmath::translate(0.0f, 0.0f, -100.0f)*/);
vmath::mat4 model_matrix(/*vmath::translate(0.0f,0.0f,-t)**/
vmath::rotate(t * 360.0f, 0.0f, 1.0f, 0.0f) *
vmath::rotate(t * 360.0f * 3.0f, 0.0f, 0.0f, 1.0f));
t += 0.00001;
glUseProgram(redShader);
glUniformMatrix4fv(render_model_matrix_loc, 1, GL_FALSE, model_matrix);
glUniformMatrix4fv(render_projection_matrix_loc, 1, GL_FALSE, projection_matrix);
glBindVertexArray(VAOs[0]);
glBeginTransformFeedback(GL_TRIANGLES);
glDrawArrays(GL_TRIANGLES, 0, 3);
glEndTransformFeedback();
// --- 第2步:绘制白色边框 ---
glStencilFunc(GL_NOTEQUAL, 1, 0xFF); // 仅模板值≠1的区域绘制
glStencilOp(GL_KEEP, GL_KEEP, GL_KEEP); // 不修改模板缓冲
glBindVertexArray(VAOs[1]);
glDrawArrays(GL_TRIANGLES, 0, 3);
// 禁用模板测试
glDisable(GL_STENCIL_TEST);
// 粒子
glBindTexture(GL_TEXTURE_BUFFER, geometry_tex);
glTexBuffer(GL_TEXTURE_BUFFER, GL_RGBA32F, geometry_vbo);
glUseProgram(update_prog);
model_matrix = vmath::mat4::identity();
glUniformMatrix4fv(model_matrix_loc, 1, GL_FALSE, model_matrix);
glUniform1i(triangle_count_loc, 1);
if (t > q)
{
glUniform1f(time_step_loc, (t - q) * 2000.0f);
}
q = t;
if ((frame_count & 1) != 0)
{
glBindVertexArray(vao[1]);
glBindBufferBase(GL_TRANSFORM_FEEDBACK_BUFFER, 0, vbo[0]);
}
else
{
glBindVertexArray(vao[0]);
glBindBufferBase(GL_TRANSFORM_FEEDBACK_BUFFER, 0, vbo[1]);
}
glBeginTransformFeedback(GL_POINTS);
glDrawArrays(GL_POINTS, 0, min(point_count, (frame_count >> 3)));
glEndTransformFeedback();
glBindVertexArray(0);
frame_count++;
// test
for (i = 0; i < 2; i++)
{
glBindBuffer(GL_TRANSFORM_FEEDBACK_BUFFER, vbo[i]);
if (i == 0)
{
struct buffer_t {
vmath::vec4 position;
vmath::vec3 velocity;
} *buffer = (buffer_t*)glMapBuffer(GL_TRANSFORM_FEEDBACK_BUFFER, GL_READ_ONLY);
for (j = 0; j < point_count; j++)
{
vmath::vec4 position = buffer[j].position;
vmath::vec3 velocity = buffer[j].velocity;
}
glUnmapBuffer(GL_TRANSFORM_FEEDBACK_BUFFER);
}
}
// 交换缓冲区和处理事件
glfwSwapBuffers(window);
glfwPollEvents();
//++t;
}
// 清理资源
//glDeleteVertexArrays(2, VAOs);
//glDeleteBuffers(2, VBOs);
glDeleteProgram(redShader);
glfwTerminate();
return 0;
}