12.结构体
结构体可以存储一组不同类型的数据,是一种复合类型。Go抛弃了类与继承,同时也抛弃了构造方法,刻意弱化了面向对象的功能,Go并非是一个传统OOP的语言,但是Go依旧有着OOP的影子,通过结构体和方法也可以模拟出一个类。下面是一个简单的结构体的例子:
Go
type Programmer struct {
Name string
Age int
Job string
Language []string
}定义
结构体定义需要使用 type 和 struct 语句。struct 语句定义一个新的数据类型,结构体中有一个或多个成员。type 语句设定了结构体的名称。结构体的格式如下:
Go
type struct_variable_type struct {
member definition
member definition
...
member definition
}一旦定义了结构体类型,它就能用于变量的声明,语法格式如下:
variable_name := structure_variable_type {value1, value2...valuen} 或 variable_name := structure_variable_type { key1: value1, key2: value2..., keyn: valuen}
实例
Go
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
// 创建一个新的结构体
fmt.Println(Books{"Go 语言", "www.Li.com", "Go 语言笔记", 6495407})
// 也可以使用 key => value 格式
fmt.Println(Books{title: "Go 语言", author: "www.Li.com", subject: "Go 语言笔记", book_id: 6495407})
// 忽略的字段为 0 或 空
fmt.Println(Books{title: "Go 语言", author: "www.Li.com"})
}输出结果为
{Go 语言 www.Li.com Go 语言笔记 6495407} {Go 语言 www.Li.com Go 语言笔记 6495407} {Go 语言 www.Li.com 0}
实例化
Go不存在构造方法,大多数情况下采用如下的方式来实例化结构体,初始化的时候就像map一样指定字段名称再初始化字段值
programmer := Programmer{ Name: "jack", Age: 19, Job: "coder", Language: []string{"Go", "C++"}, }
不过也可以省略字段名称,当省略字段名称时,就必须初始化所有字段,通常不建议使用这种方式,因为可读性很糟糕。
programmer := Programmer{ "jack", 19, "coder", []string{"Go", "C++"}}
如果实例化过程比较复杂,你也可以编写一个函数来实例化结构体,就像下面这样,你也可以把它理解为一个构造函数
type Person struct { Name string Age int Address string Salary float64 } func NewPerson(name string, age int, address string, salary float64) *Person { return &Person{Name: name, Age: age, Address: address, Salary: salary} }
不过Go并不支持函数与方法重载,所以你无法为同一个函数或方法定义不同的参数。如果你想以多种方式实例化结构体,要么创建多个构造函数,要么建议使用options模式。
访问结构体成员
如果要访问结构体成员,需要使用点号 . 操作符,格式为:
结构体.成员名结构体类型变量使用 struct 关键字定义,实例如下:
实例
Go
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
var Book1 Books /* 声明 Book1 为 Books 类型 */
var Book2 Books /* 声明 Book2 为 Books 类型 */
/* book 1 描述 */
Book1.title = "Go 语言"
Book1.author = "www.Li.com"
Book1.subject = "Go 语言笔记"
Book1.book_id = 6495407
/* book 2 描述 */
Book2.title = "Python 笔记"
Book2.author = "www.Li.com"
Book2.subject = "Python 语言笔记"
Book2.book_id = 6495700
/* 打印 Book1 信息 */
fmt.Printf( "Book 1 title : %s\n", Book1.title)
fmt.Printf( "Book 1 author : %s\n", Book1.author)
fmt.Printf( "Book 1 subject : %s\n", Book1.subject)
fmt.Printf( "Book 1 book_id : %d\n", Book1.book_id)
/* 打印 Book2 信息 */
fmt.Printf( "Book 2 title : %s\n", Book2.title)
fmt.Printf( "Book 2 author : %s\n", Book2.author)
fmt.Printf( "Book 2 subject : %s\n", Book2.subject)
fmt.Printf( "Book 2 book_id : %d\n", Book2.book_id)
}以上实例执行运行结果为:
Book 1 title : Go 语言 Book 1 author : www.Li.com Book 1 subject : Go 语言笔记 Book 1 book_id : 6495407 Book 2 title : Python 笔记 Book 2 author : www.Li.com Book 2 subject : Python 语言笔记 Book 2 book_id : 6495700
结构体作为函数参数
你可以像其他数据类型一样将结构体类型作为参数传递给函数。并以以上实例的方式访问结构体变量:
实例
Go
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
var Book1 Books /* 声明 Book1 为 Books 类型 */
var Book2 Books /* 声明 Book2 为 Books 类型 */
/* book 1 描述 */
Book1.title = "Go 语言"
Book1.author = "www.Li.com"
Book1.subject = "Go 语言笔记"
Book1.book_id = 6495407
/* book 2 描述 */
Book2.title = "Python 笔记"
Book2.author = "www.Li.com"
Book2.subject = "Python 语言笔记"
Book2.book_id = 6495700
/* 打印 Book1 信息 */
printBook(Book1)
/* 打印 Book2 信息 */
printBook(Book2)
}
func printBook( book Books ) {
fmt.Printf( "Book title : %s\n", book.title)
fmt.Printf( "Book author : %s\n", book.author)
fmt.Printf( "Book subject : %s\n", book.subject)
fmt.Printf( "Book book_id : %d\n", book.book_id)
}以上实例执行运行结果为:
Book title : Go 语言 Book author : www.Li.com Book subject : Go 语言笔记 Book book_id : 6495407 Book title : Python 笔记 Book author : www.Li.com Book subject : Python 语言笔记 Book book_id : 6495700
选项模式
选项模式是Go语言中一种很常见的设计模式,可以更为灵活的实例化结构体,拓展性强,并且不需要改变构造函数的函数签名。假设有下面这样一个结构体
type Person struct { Name string Age int Address string Salary float64 Birthday string }
声明一个PersonOptions类型,它接受一个*Person类型的参数,它必须是指针,因为我们要在闭包中对Person赋值。
type PersonOptions func(p *Person)
接下来创建选项函数,它们一般是With开头,它们的返回值就是一个闭包函数。
func WithName(name string) PersonOptions {
return func(p *Person) {
p.Name = name
}
}
func WithAge(age int) PersonOptions {
return func(p *Person) {
p.Age = age
}
}
func WithAddress(address string) PersonOptions {
return func(p *Person) {
p.Address = address
}
}
func WithSalary(salary float64) PersonOptions {
return func(p *Person) {
p.Salary = salary
}
}
实际声明的构造函数签名如下,它接受一个可变长PersonOptions类型的参数。
func NewPerson(options ...PersonOptions) *Person { // 优先应用options p := &Person{} for _, option := range options { option(p) } // 默认值处理 if p.Age < 0 { p.Age = 0 } ...... return p }
这样一来对于不同实例化的需求只需要一个构造函数即可完成,只需要传入不同的Options函数即可
func main() { pl := NewPerson( WithName("John Doe"), WithAge(25), WithAddress("123 Main St"), WithSalary(10000.00), ) p2 := NewPerson( WithName("Mike jane"), WithAge(30), ) }
函数式选项模式在很多开源项目中都能看见,gRPC Server的实例化方式也是采用了该设计模式。函数式选项模式只适合于复杂的实例化,如果参数只有简单几个,建议还是用普通的构造函数来解决。
组合
在Go中,结构体之间的关系是通过组合来表示的,可以显式组合,也可以匿名组合,后者使用起来更类似于继承,但本质上没有任何变化。例如:
显式组合的方式
type Person struct { name string age int } type Student struct { p Person school string } type Employee struct { p Person job string }
在使用时需要显式的指定字段p
student := Student{ p: Person{name: "jack", age: 18}, school: "lili school", } fmt.Println(student.p.name)
而匿名组合可以不用显式的指定字段
type Person struct { name string age int } type Student struct { Person school string } type Employee struct { Person job string }
匿名字段的名称默认为类型名,调用者可以直接访问该类型的字段和方法,但除了更加方便以外与第一种方式没有任何的区别。
student := Student{ Person: Person{name: "jack",age: 18}, school: "lili school", } fmt.Println(student.name)
指针
你可以定义指向结构体的指针类似于其他指针变量,格式如下:
var struct_pointer *Books
以上定义的指针变量可以存储结构体变量的地址。查看结构体变量地址,可以将 & 符号放置于结构体变量前:
struct_pointer = &Book1
使用结构体指针访问结构体成员,使用 "." 操作符:
struct_pointer.title
接下来让我们使用结构体指针重写以上实例,代码如下:
实例
Go
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
var Book1 Books /* 声明 Book1 为 Books 类型 */
var Book2 Books /* 声明 Book2 为 Books 类型 */
/* book 1 描述 */
Book1.title = "Go 语言"
Book1.author = "www.Li.com"
Book1.subject = "Go 语言笔记"
Book1.book_id = 6495407
/* book 2 描述 */
Book2.title = "Python 笔记"
Book2.author = "www.Li.com"
Book2.subject = "Python 语言笔记"
Book2.book_id = 6495700
/* 打印 Book1 信息 */
printBook(&Book1)
/* 打印 Book2 信息 */
printBook(&Book2)
}
func printBook( book *Books ) {
fmt.Printf( "Book title : %s\n", book.title)
fmt.Printf( "Book author : %s\n", book.author)
fmt.Printf( "Book subject : %s\n", book.subject)
fmt.Printf( "Book book_id : %d\n", book.book_id)
}以上实例执行运行结果为:
Book title : Go 语言 Book author : www.Li.com Book subject : Go 语言笔记 Book book_id : 6495407 Book title : Python 笔记 Book author : www.Li.com Book subject : Python 语言笔记 Book book_id : 6495700
标签
结构体标签是一种元编程的形式,结合反射可以做出很多奇妙的功能,格式如下
`key1:"val1" key2:"val2"`
标签是一种键值对的形式,使用空格进行分隔。结构体标签的容错性很低,如果没能按照正确的格式书写结构体,那么将会导致无法正常读取,但是在编译时却不会有任何的报错,下方是一个使用示例。
type Programmer struct { Name string json:"name" Age int yaml:"age" Job string toml:"job" Language []string properties:"language" }
结构体标签最广泛的应用就是在各种序列化格式中的别名定义,标签的使用需要结合反射才能完整发挥出其功能。
内存对齐
Go结构体字段的内存分布遵循内存对齐的规则,这么做可以减少CPU访问内存的次数,相应的占用的内存要多一些,属于空间换时间的一种手段。假设有如下结构体
type Num struct { A int64 B int32 C int16 D int8 E int32 }
已知这些类型的占用字节数
-
int64占8个字节 -
int32占4个字节 -
int16占2字节 -
int8占一个字节
整个结构体的内存占用似乎是8+4+2+1+4=19个字节吗,当然不是这样,根据内存对齐规则而言,结构体的内存占用长度至少是最大字段的整数倍,不足的则补齐。该结构体中最大的是int64占用8个字节,那么内存分布如下图所示
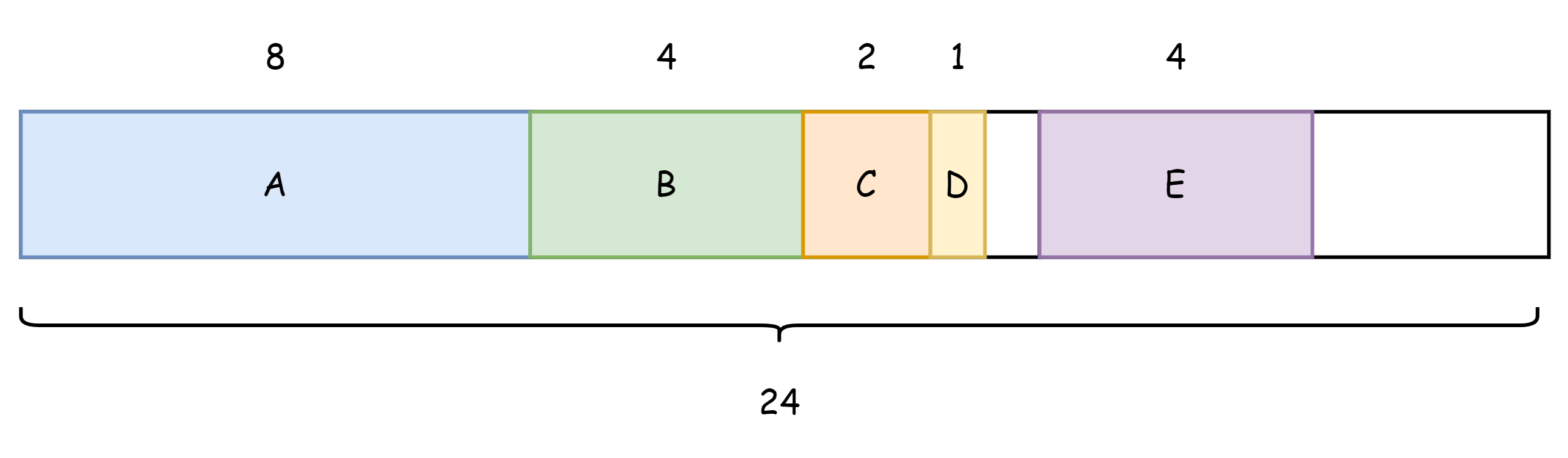
所以实际上是占用24个字节,其中有5个字节是无用的。
再来看下面这个结构体
type Num struct { A int8 B int64 C int8 }
明白了上面的规则后,可以很快的理解它的内存占用也是24个字节,尽管它只有三个字段,足足浪费了14个字节。

但是我们可以调整字段,改成如下的顺序
type Num struct {
A int8
C int8
B int64
}如此一来就占用的内存就变为了16字节,浪费了6个字节,减少了8个字节的内存浪费。
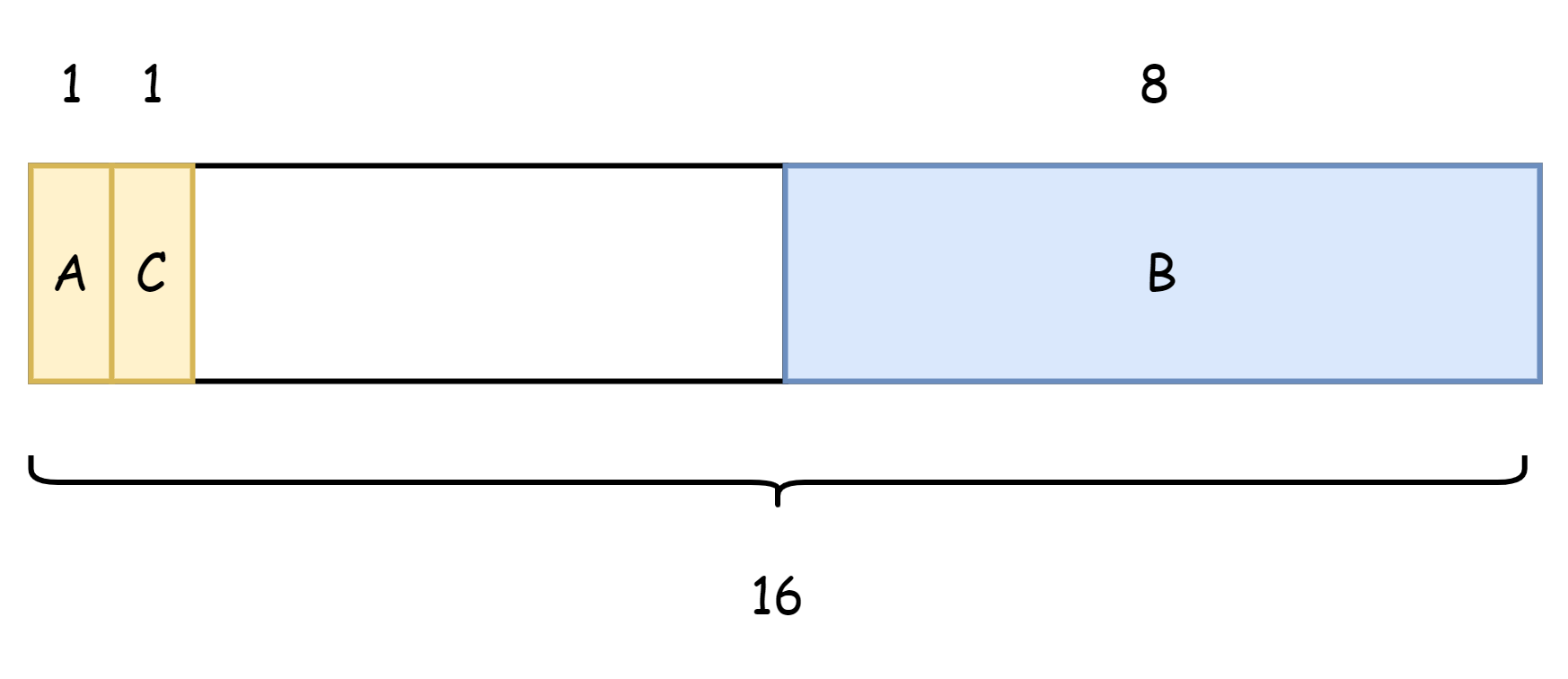
从理论上来说,让结构体中的字段按照合理的顺序分布,可以减少其内存占用。不过实际编码过程中,并没有必要的理由去这样做,它不一定能在减少内存占用这方面带来实质性的提升,但一定会提高开发人员的血压和心智负担,尤其是在业务中一些结构体的字段数可能多大几十个或者数百个,所以仅做了解即可。
提示
如果你真的想通过此种方法来节省内存,可以看看这两个库
他们会检查你的源代码中的结构体,计算并重新排布结构体字段来最小化结构体占用的内存。
空结构体
空结构体没有字段,不占用内存空间,我们可以通过unsafe.SizeOf函数来计算占用的字节大小
func main() {
type Empty struct {}
fmt.Println(unsafe.Sizeof(Empty{}))
}输出
0空结构体的使用场景有很多,比如之前提到过的,作为map的值类型,可以将map作为set来进行使用,又或者是作为通道的类型,表示仅做通知类型的通道。
13.数组
Go 语言提供了数组类型的数据结构。
数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
相对于去声明 number0, number1, ..., number99 的变量,使用数组形式 numbers0, numbers1 ..., numbers99 更加方便且易于扩展。
数组元素可以通过索引(位置)来读取(或者修改),索引从 0 开始,第一个元素索引为 0,第二个索引为 1,以此类推。

声明数组
Go 语言数组声明需要指定元素类型及元素个数,语法格式如下:
var arrayName [size]dataType
其中,arrayName 是数组的名称,size 是数组的大小,dataType 是数组中元素的数据类型。
以下定义了数组 balance 长度为 10 类型为 float32:
var balance [10]float32
初始化数组
以下演示了数组初始化:
以下实例声明一个名为 numbers 的整数数组,其大小为 5,在声明时,数组中的每个元素都会根据其数据类型进行默认初始化,对于整数类型,初始值为 0。
var numbers [5]int
还可以使用初始化列表来初始化数组的元素:
var numbers = [5]int{1, 2, 3, 4, 5}
以上代码声明一个大小为 5 的整数数组,并将其中的元素分别初始化为 1、2、3、4 和 5。
另外,还可以使用 := 简短声明语法来声明和初始化数组:
numbers := [5]int{1, 2, 3, 4, 5}
以上代码创建一个名为 numbers 的整数数组,并将其大小设置为 5,并初始化元素的值。
注意: 在 Go 语言中,数组的大小是类型的一部分,因此不同大小的数组是不兼容的,也就是说 5int 和 10int 是不同的类型。
以下定义了数组 balance 长度为 5 类型为 float32,并初始化数组的元素:
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
我们也可以通过字面量在声明数组的同时快速初始化数组:
balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
如果数组长度不确定,可以使用 ... 代替数组的长度,编译器会根据元素个数自行推断数组的长度:
var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0} 或 balance := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
如果设置了数组的长度,我们还可以通过指定下标来初始化元素:
// 将索引为 1 和 3 的元素初始化 balance := [5]float32{1:2.0,3:7.0}
初始化数组中 {} 中的元素个数不能大于 \[\] 中的数字。
如果忽略 \[\] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小:
balance[4] = 50.0
以上实例读取了第五个元素。数组元素可以通过索引(位置)来读取(或者修改),索引从 0 开始,第一个元素索引为 0,第二个索引为 1,以此类推。

访问数组元素
数组元素可以通过索引(位置)来读取。格式为数组名后加中括号,中括号中为索引的值。例如:
var salary float32 = balance[9]
以上实例读取了数组 balance 第 10 个元素的值。
以下演示了数组完整操作(声明、赋值、访问)的实例:
实例 1
Go
package main
import "fmt"
func main() {
var n [10]int /* n 是一个长度为 10 的数组 */
var i,j int
/* 为数组 n 初始化元素 */*
for i = 0; i < 10; i++ {
n[i] = i + 100 /* 设置元素为 i + 100 */
}
/* 输出每个数组元素的值 */
for j = 0; j < 10; j++ {
fmt.Printf("Element[%d] = %d\n", j, n[j] )
}
}以上实例执行结果如下:
Element[0] = 100 Element[1] = 101 Element[2] = 102 Element[3] = 103 Element[4] = 104 Element[5] = 105 Element[6] = 106 Element[7] = 107 Element[8] = 108 Element[9] = 109
实例 2
Go
package main
import "fmt"
func main() {
var i,j,k int
// 声明数组的同时快速初始化数组
balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
/* 输出数组元素 */
for i = 0; i < 5; i++ {
fmt.Printf("balance[%d] = %f\n", i, balance[i] )
}
balance2 := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
/* 输出每个数组元素的值 */
for j = 0; j < 5; j++ {
fmt.Printf("balance2[%d] = %f\n", j, balance2[j] )
}
// 将索引为 1 和 3 的元素初始化
balance3 := [5]float32{1:2.0,3:7.0}
for k = 0; k < 5; k++ {
fmt.Printf("balance3[%d] = %f\n", k, balance3[k] )
}
}以上实例执行结果如下:
balance[0] = 1000.000000 balance[1] = 2.000000 balance[2] = 3.400000 balance[3] = 7.000000 balance[4] = 50.000000 balance2[0] = 1000.000000 balance2[1] = 2.000000 balance2[2] = 3.400000 balance2[3] = 7.000000 balance2[4] = 50.000000 balance3[0] = 0.000000 balance3[1] = 2.000000 balance3[2] = 0.000000 balance3[3] = 7.000000 balance3[4] = 0.000000
多维数组
Go 语言支持多维数组,以下为常用的多维数组声明方式:
var variable_name [SIZE1][SIZE2]...[SIZEN] variable_type
以下实例声明了三维的整型数组:
var threedim [5][10][4]int
二维数组
二维数组是最简单的多维数组,二维数组本质上是由一维数组组成的。二维数组定义方式如下:
var arrayName [ x ][ y ] variable_type
variable_type 为 Go 语言的数据类型,arrayName 为数组名,二维数组可认为是一个表格,x 为行,y 为列,下图演示了一个二维数组 a 为三行四列:
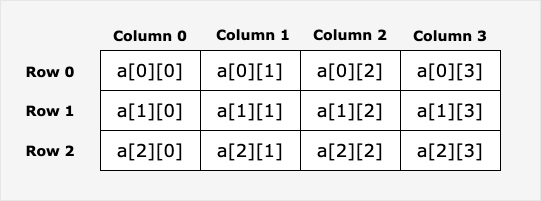
二维数组中的元素可通过 ai来访问。
实例
Go
package main
import "fmt"
func main() {
// Step 1: 创建数组
values := [][]int{}
// Step 2: 使用 append() 函数向空的二维数组添加两行一维数组
row1 := []int{1, 2, 3}
row2 := []int{4, 5, 6}
values = append(values, row1)
values = append(values, row2)
// Step 3: 显示两行数据
fmt.Println("Row 1")
fmt.Println(values[0])
fmt.Println("Row 2")
fmt.Println(values[1])
// Step 4: 访问第一个元素
fmt.Println("第一个元素为:")
fmt.Println(values[0][0])
}以上实例运行输出结果为:
Row 1 [1 2 3] Row 2 [4 5 6] 第一个元素为: 1
初始化二维数组
多维数组可通过大括号来初始值。以下实例为一个 3 行 4 列的二维数组:
a := [3][4]int{ {0, 1, 2, 3} , /* 第一行索引为 0 */ {4, 5, 6, 7} , /* 第二行索引为 1 */ {8, 9, 10, 11}, /* 第三行索引为 2 */ }
注意:
以上代码中倒数第二行的}必须要有逗号,因为最后一行的}不能单独一行,也可以写成这样:
a := [3][4]int{ {0, 1, 2, 3} , /* 第一行索引为 0 */ {4, 5, 6, 7} , /* 第二行索引为 1 */ {8, 9, 10, 11}} /* 第三行索引为 2 */
实例
以下实例初始化一个 2 行 2 列 的二维数组:
Go
package main
import "fmt"
func main() {
// 创建二维数组
sites := [2][2]string{}
// 向二维数组添加元素
sites[0][0] = "Google"
sites[0][1] = "Li"
sites[1][0] = "Taobao"
sites[1][1] = "Weibo"
// 显示结果
fmt.Println(sites)
}以上实例运行输出结果为:
[[Google Li] [Taobao Weibo]]
访问二维数组
二维数组通过指定坐标来访问。如数组中的行索引与列索引,例如:
val := a[2][3] 或 var value int = a[2][3]
以上实例访问了二维数组 val 第三行的第四个元素。
二维数组可以使用循环嵌套来输出元素:
实例
Go
package main
import "fmt"
func main() {
/* 数组 - 5 行 2 列*/
var a = [5][2]int{ {0,0}, {1,2}, {2,4}, {3,6},{4,8}}
var i, j int
/* 输出数组元素 */
for i = 0; i < 5; i++ {
for j = 0; j < 2; j++ {
fmt.Printf("a[%d][%d] = %d\n", i,j, a[i][j] )
}
}
}以上实例运行输出结果为:
a[0][0] = 0 a[0][1] = 0 a[1][0] = 1 a[1][1] = 2 a[2][0] = 2 a[2][1] = 4 a[3][0] = 3 a[3][1] = 6 a[4][0] = 4 a[4][1] = 8
以下实例创建各个维度元素数量不一致的多维数组:
实例
Go
package main
import "fmt"
func main() {
// 创建空的二维数组
animals := [][]string{}
// 创建三一维数组,各数组长度不同
row1 := []string{"fish", "shark", "eel"}
row2 := []string{"bird"}
row3 := []string{"lizard", "salamander"}
// 使用 append() 函数将一维数组添加到二维数组中
animals = append(animals, row1)
animals = append(animals, row2)
animals = append(animals, row3)
// 循环输出
for i := range animals {
fmt.Printf("Row: %v\n", i)
fmt.Println(animals[i])
}
}以上实例运行输出结果为:
Row: 0 [fish shark eel] Row: 1 [bird] Row: 2 [lizard salamander]
向函数传递数组
Go 语言中的数组是值类型,因此在将数组传递给函数时,实际上是传递数组的副本。
如果你想向函数传递数组参数,你需要在函数定义时,声明形参为数组,我们可以通过以下两种方式来声明:
方式一
形参设定数组大小:
func myFunction(param [10]int) { .... }
方式二
形参未设定数组大小:
func myFunction(param []int) { .... }
如果你想要在函数内修改原始数组,可以通过传递数组的指针来实现。
实例
让我们看下以下实例,实例中函数接收整型数组参数,另一个参数指定了数组元素的个数,并返回平均值:
func getAverage(arr []int, size int) float32 { var i int var avg, sum float32 for i = 0; i < size; ++i { sum += arr[i] } avg = sum / size return avg; }
实例
接下来我们来调用这个函数:
Go
package main
import "fmt"
func main() {
/* 数组长度为 5 */
var balance = [5]int {1000, 2, 3, 17, 50}
var avg float32
/* 数组作为参数传递给函数 */
avg = getAverage( balance, 5 ) ;
/* 输出返回的平均值 */
fmt.Printf( "平均值为: %f ", avg );
}
func getAverage(arr [5]int, size int) float32 {
var i,sum int
var avg float32
for i = 0; i < size;i++ {
sum += arr[i]
}
avg = float32(sum) / float32(size)
return avg;
}以上实例执行输出结果为:
平均值为: 214.399994
以上实例中我们使用的形参并未设定数组大小。
浮点数计算输出有一定的偏差,你也可以转整型来设置精度。
实例
Go
package main
import (
"fmt"
)
func main() {
a := 1.69
b := 1.7
c := a * b // 结果应该是2.873
fmt.Println(c) // 输出的是2.8729999999999998
}设置固定精度:
实例
Go
package main
import (
"fmt"
)
func main() {
a := 1690 // 表示1.69
b := 1700 // 表示1.70
c := a * b // 结果应该是2873000表示 2.873
fmt.Println(c) // 内部编码
fmt.Println(float64(c) / 1000000) // 显示
}如果你想要在函数内修改原始数组,可以通过传递数组的指针来实现。
以下实例演示如何向函数传递数组,函数接受一个数组和数组的指针作为参数:
实例
Go
package main
import "fmt"
// 函数接受一个数组作为参数
func modifyArray(arr [5]int) {
for i := 0; i < len(arr); i++ {
arr[i] = arr[i] * 2
}
}
// 函数接受一个数组的指针作为参数
func modifyArrayWithPointer(arr *[5]int) {
for i := 0; i < len(*arr); i++ {
(*arr)[i] = (*arr)[i] * 2
}
}
func main() {
// 创建一个包含5个元素的整数数组
myArray := [5]int{1, 2, 3, 4, 5}
fmt.Println("Original Array:", myArray)
// 传递数组给函数,但不会修改原始数组的值
modifyArray(myArray)
fmt.Println("Array after modifyArray:", myArray)
// 传递数组的指针给函数,可以修改原始数组的值
modifyArrayWithPointer(&myArray)
fmt.Println("Array after modifyArrayWithPointer:", myArray)
}在上面的例子中,modifyArray 函数接受一个数组,并尝试修改数组的值,但在主函数中调用后,原始数组并未被修改。相反,modifyArrayWithPointer 函数接受一个数组的指针,并通过指针修改了原始数组的值。
以上实例执行输出结果为:
Original Array: [1 2 3 4 5] Array after modifyArray: [1 2 3 4 5] Array after modifyArrayWithPointer: [2 4 6 8 10]
14.切片
在Go中,数组和切片两者看起来长得几乎一模一样,但功能有着不小的区别,数组是定长的数据结构,长度被指定后就不能被改变,而切片是不定长的,切片在容量不够时会自行扩容。
Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
初始化
切片的初始化方式有以下几种
var nums []int // 值 nums := []int{1, 2, 3} // 直接初始化切片,[] 表示是切片类型,{1,2,3} 初始化值依次是 1,2,3,其 cap=len=3。 nums := make([]int, 0, 0) // 值 nums := new([]int) // 指针
可以看到切片与数组在外貌上的区别,仅仅只是少了一个初始化长度。通常情况下,推荐使用make来创建一个空切片,只是对于切片而言,make函数接收三个参数:类型,长度len,容量capacity。举个例子解释一下长度与容量的区别,假设有一桶水,水并不是满的,桶的高度就是桶的容量,代表着总共能装多少高度的水,而桶中水的高度就是代表着长度,水的高度一定小于等于桶的高度,否则水就溢出来了。所以,切片的长度代表着切片中元素的个数,切片的容量代表着切片总共能装多少个元素,切片与数组最大的区别在于切片的容量会自动扩张,而数组不会。
提示:
切片的底层实现依旧是数组,是引用类型,可以简单理解为是指向底层数组的指针。
通过var nums []int这种方式声明的切片,默认值为nil,所以不会为其分配内存,而在使用make进行初始化时,建议预分配一个足够的容量,可以有效减少后续扩容的内存消耗。
s := arr[:]
初始化切片 s,是数组 arr 的引用。
s := arr[startIndex:endIndex]
将 arr 中从下标 startIndex 到 endIndex-1 下的元素创建为一个新的切片。
s := arr[startIndex:]
默认 endIndex 时将表示一直到arr的最后一个元素。
s := arr[:endIndex]
默认 startIndex 时将表示从 arr 的第一个元素开始。
s1 := s[startIndex:endIndex]
通过切片 s 初始化切片 s1。
s :=make([]int,len,cap)
通过内置函数 make() 初始化切片s ,\[\]int 标识为其元素类型为 int 的切片。
len() 和 cap() 函数
切片是可索引的,并且可以由 len() 方法获取长度。
切片提供了计算容量的方法 cap() 可以测量切片最长可以达到多少。
实例
Go
package main
import "fmt"
func main() {
var numbers = make([]int,3,5)
printSlice(numbers)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}以上实例运行输出结果为:
len=3 cap=5 slice=[0 0 0]
空(nil)切片
一个切片在未初始化之前默认为 nil,长度为 0,实例如下:
实例
Go
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers)
if(numbers == nil){
fmt.Printf("切片是空的")
}
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}以上实例运行输出结果为:
len=0 cap=0 slice=[] 切片是空的
切片截取
可以通过设置下限及上限来设置截取切片 lower-bound:upper-bound,实例如下:
实例
Go
package main
import "fmt"
func main() {
/* 创建切片 */
numbers := []int{0,1,2,3,4,5,6,7,8}
printSlice(numbers)
/* 打印原始切片 */
fmt.Println("numbers ==", numbers)
/* 打印子切片从索引1(包含) 到索引4(不包含)*/
fmt.Println("numbers[1:4] ==", numbers[1:4])
/* 默认下限为 0*/
fmt.Println("numbers[:3] ==", numbers[:3])
/* 默认上限为 len(s)*/
fmt.Println("numbers[4:] ==", numbers[4:])
numbers1 := make([]int,0,5)
printSlice(numbers1)
/* 打印子切片从索引 0(包含) 到索引 2(不包含) */
number2 := numbers[:2]
printSlice(number2)
/* 打印子切片从索引 2(包含) 到索引 5(不包含) */
number3 := numbers[2:5]
printSlice(number3)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}执行以上代码输出结果为:
len=9 cap=9 slice=[0 1 2 3 4 5 6 7 8] numbers == [0 1 2 3 4 5 6 7 8] numbers[1:4] == [1 2 3] numbers[:3] == [0 1 2] numbers[4:] == [4 5 6 7 8] len=0 cap=5 slice=[] len=2 cap=9 slice=[0 1] len=3 cap=7 slice=[2 3 4]
append() 和 copy() 函数
如果想增加切片的容量,我们必须创建一个新的更大的切片并把原分片的内容都拷贝过来。 下面描述了从拷贝切片的 copy 方法和向切片追加新元素的 append 方法。
使用
切片的基本使用与数组完全一致,区别只是切片可以动态变化长度,下面看几个例子。
切片可以通过append函数实现许多操作,函数签名如下,slice是要添加元素的目标切片,elems是待添加的元素,返回值是添加后的切片。
func append(slice []Type, elems ...Type) []Type
首先创建一个长度为0,容量为0的空切片,然后在尾部插入一些元素,最后输出长度和容量。
nums := make([]int, 0, 0) nums = append(nums, 1, 2, 3, 4, 5, 6, 7) fmt.Println(len(nums), cap(nums)) // 7 8 可以看到长度与容量并不一致。
新 slice 预留的 buffer容量 大小是有一定规律的。 在golang1.18版本更新之前网上大多数的文章都是这样描述slice的扩容策略的: 当原 slice 容量小于 1024 的时候,新 slice 容量变成原来的 2 倍;原 slice 容量超过 1024,新 slice 容量变成原来的1.25倍。 在1.18版本更新之后,slice的扩容策略变为了: 当原slice容量(oldcap)小于256的时候,新slice(newcap)容量为原来的2倍;原slice容量超过256,新slice容量newcap = oldcap+(oldcap+3*256)/4
拷贝
切片在拷贝时需要确保目标切片有足够的长度,例如
func main() { dest := make([]int, 0) src := []int{1, 2, 3, 4, 5, 6, 7, 8, 9} fmt.Println(src, dest) fmt.Println(copy(dest, src)) fmt.Println(src, dest) } [1 2 3 4 5 6 7 8 9] [] 0 [1 2 3 4 5 6 7 8 9] []
将长度修改为10,输出如下
[1 2 3 4 5 6 7 8 9] [0 0 0 0 0 0 0 0 0 0] 9 [1 2 3 4 5 6 7 8 9] [1 2 3 4 5 6 7 8 9 0]
实例
Go
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers)
/* 允许追加空切片 */
numbers = append(numbers, 0)
printSlice(numbers)
/* 向切片添加一个元素 */
numbers = append(numbers, 1)
printSlice(numbers)
/* 同时添加多个元素 */
numbers = append(numbers, 2,3,4)
printSlice(numbers)
/* 创建切片 numbers1 是之前切片的两倍容量*/
numbers1 := make([]int, len(numbers), (cap(numbers))*2)
/* 拷贝 numbers 的内容到 numbers1 */
copy(numbers1,numbers)
printSlice(numbers1)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}以上代码执行输出结果为:
len=0 cap=0 slice=[] len=1 cap=1 slice=[0] len=2 cap=2 slice=[0 1] len=5 cap=6 slice=[0 1 2 3 4] len=5 cap=12 slice=[0 1 2 3 4]
插入元素
切片元素的插入也是需要结合append函数来使用,现有切片如下,
nums := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
从头部插入元素
nums = append([]int{-1, 0}, nums...) fmt.Println(nums) // [-1 0 1 2 3 4 5 6 7 8 9 10]
从中间下标i插入元素
nums = append(nums[:i+1], append([]int{999, 999}, nums[i+1:]...)...) fmt.Println(nums) // i=3,[1 2 3 4 999 999 5 6 7 8 9 10]
从尾部插入元素,就是append最原始的用法
nums = append(nums, 99, 100) fmt.Println(nums) // [1 2 3 4 5 6 7 8 9 10 99 100]
删除元素
切片元素的删除需要结合append函数来使用,现有如下切片
nums := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
从头部删除n个元素
nums = nums[n:] fmt.Println(nums) //n=3 [4 5 6 7 8 9 10]
从尾部删除n个元素
nums = nums[:len(nums)-n] fmt.Println(nums) //n=3 [1 2 3 4 5 6 7]
从中间指定下标i位置开始删除n个元素
nums = append(nums[:i], nums[i+n:]...) fmt.Println(nums)// i=2,n=3,[1 2 6 7 8 9 10]
删除所有元素
nums = nums[:0] fmt.Println(nums) // []
遍历
切片的遍历与数组完全一致,for循环
func main() { slice := []int{1, 2, 3, 4, 5, 7, 8, 9} for i := 0; i < len(slice); i++ { fmt.Println(slice[i]) } }
for range循环
func main() { slice := []int{1, 2, 3, 4, 5, 7, 8, 9} for index, val := range slice { fmt.Println(index, val) } }
多维切片
先来看下面的一个例子,官方文档也有解释:Effective Go - 二维切片open in new window
var nums [5][5]int for _, num := range nums { fmt.Println(num) } fmt.Println() slices := make([][]int, 5) for _, slice := range slices { fmt.Println(slice) }
输出结果为
[0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [] [] [] [] []
可以看到,同样是二维的数组和切片,其内部结构是不一样的。数组在初始化时,其一维和二维的长度早已固定,而切片的长度是不固定的,切片中的每一个切片长度都可能是不相同的,所以必须要单独初始化,切片初始化部分修改为如下代码即可。
slices := make([][]int, 5) for i := 0; i < len(slices); i++ { slices[i] = make([]int, 5) fmt.Println(slices[i]) }
最终输出结果为
[0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0]
拓展表达式
提示:只有切片才能使用拓展表达式
切片与数组都可以使用简单表达式来进行切割,但是拓展表达式只有切片能够使用,该特性于Go1.2版本添加,主要是为了解决切片共享底层数组的读写问题,主要格式为如下,需要满足关系low<= high <= max <= cap,使用拓展表达式切割的切片容量为max-low
slice[low:high:max]
low与high依旧是原来的含义不变,而多出来的max则指的是最大容量,例如下方的例子中省略了max,那么s2的容量就是cap(s1)-low
s1 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9} // cap = 9 s2 := s1[3:4] // cap = 9 - 3 = 6
那么这么做就会有一个明显的问题,s1与s2是共享的同一个底层数组,在对s2进行读写时,有可能会影响的s1的数据,下列代码就属于这种情况
s1 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9} // cap = 9 s2 := s1[3:4] // cap = 9 - 3 = 6 // 添加新元素,由于容量为6.所以没有扩容,直接修改底层数组 s2 = append(s2, 1) fmt.Println(s2) fmt.Println(s1)
最终的输出为
[4 1] [1 2 3 4 1 6 7 8 9]
可以看到明明是向s2添加元素,却连s1也一起修改了,拓展表达式就是为了解决此类问题而生的,只需要稍微修改一下就能解决该问题
func main() { s1 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9} // cap = 9 s2 := s1[3:4:4] // cap = 4 - 3 = 1 // 容量不足,分配新的底层数组 s2 = append(s2, 1) fmt.Println(s2) fmt.Println(s1) }
现在得到的结果就是正常的
[4 1] [1 2 3 4 5 6 7 8 9]
clear
在go1.21新增了clear内置函数,clear会将切片内所有的值置为零值,
Go
package main
import (
"fmt"
)
func main() {
s := []int{1, 2, 3, 4}
clear(s)
fmt.Println(s)
}输出
[0 0 0 0]
如果想要清空切片,可以
func main() { s := []int{1, 2, 3, 4} s = s[:0:0] fmt.Println(s) }
限制了切割后的容量,这样可以避免覆盖原切片的后续元素。
15.Map(映射)
一般来说,映射表数据结构实现通常有两种,哈希表(hash table)和搜索树(search tree),区别在于前者无序,后者有序。在Go中,map的实现是基于哈希桶(也是一种哈希表),所以也是无序的。
Map 是一种无序的键值对的集合。
Map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。
Map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,Map 是无序的,遍历 Map 时返回的键值对的顺序是不确定的。
在获取 Map 的值时,如果键不存在,返回该类型的零值,例如 int 类型的零值是 0,string 类型的零值是 ""。
Map 是引用类型,如果将一个 Map 传递给一个函数或赋值给另一个变量,它们都指向同一个底层数据结构,因此对 Map 的修改会影响到所有引用它的变量。
定义
在Go中,map的键类型必须是可比较的,比如string,int是可比较的,而[]int是不可比较的,也就无法作为map的键。初始化一个map有两种方法,第一种是字面量,格式如下:
map[keyType]valueType{}
举几个例子
mp := map[int]string{ 0: "a", 1: "a", 2: "a", 3: "a", 4: "a", } mp := map[string]int{ "a": 0, "b": 22, "c": 33, }
第二种方法是使用内置函数make,对于map而言,接收两个参数,分别是类型与初始容量,格式如下:
map_variable := make(map[KeyType]ValueType, initialCapacity)
其中 KeyType 是键的类型,ValueType 是值的类型,initialCapacity 是可选的参数,用于指定 Map 的初始容量。Map 的容量是指 Map 中可以保存的键值对的数量,当 Map 中的键值对数量达到容量时,Map 会自动扩容。如果不指定 initialCapacity,Go 语言会根据实际情况选择一个合适的值。
实例如下:
mp := make(map[string]int, 8) mp := make(map[string][]int, 10)
map是引用类型,零值或未初始化的map可以访问,但是无法存放元素,所以必须要为其分配内存。
func main() { var mp map[string]int mp["a"] = 1 fmt.Println(mp) } panic: assignment to entry in nil map
提示
在初始化map时应当尽量分配一个合理的容量,以减少扩容次数。
访问
访问一个map的方式就像通过索引访问一个数组一样。
func main() { mp := map[string]int{ "a": 0, "b": 1, "c": 2, "d": 3, } fmt.Println(mp["a"]) //0 fmt.Println(mp["b"]) //1 fmt.Println(mp["d"]) //3 fmt.Println(mp["f"]) //0 }
通过代码可以观察到,即使map中不存在"f"这一键值对,但依旧有返回值。map对于不存的键其返回值是对应类型的零值,并且在访问map的时候其实有两个返回值,第一个返回值对应类型的值,第二个返回值一个布尔值,代表键是否存在,例如:
func main() { mp := map[string]int{ "a": 0, "b": 1, "c": 2, "d": 3, } if val, exist := mp["f"]; exist { fmt.Println(val) } else { fmt.Println("key不存在") } }
对map求长度
func main() { mp := map[string]int{ "a": 0, "b": 1, "c": 2, "d": 3, } fmt.Println(len(mp)) }
存值
map存值的方式也类似数组存值一样,例如:
func main() { mp := make(map[string]int, 10) mp["a"] = 1 mp["b"] = 2 fmt.Println(mp) }
存值时使用已存在的键会覆盖原有的值
func main() { mp := make(map[string]int, 10) mp["a"] = 1 mp["b"] = 2 if _, exist := mp["b"]; exist { mp["b"] = 3 } fmt.Println(mp) }
但是也存在一个特殊情况,那就是键为math.NaN()时
func main() { mp := make(map[float64]string, 10) mp[math.NaN()] = "a" mp[math.NaN()] = "b" mp[math.NaN()] = "c" _, exist := mp[math.NaN()] fmt.Println(exist) //false fmt.Println(mp) //map[NaN:c NaN:a NaN:b] }
通过结果可以观察到相同的键值并没有覆盖,反而还可以存在多个,也无法判断其是否存在,也就无法正常取值。因为NaN是IEE754标准所定义的,其实现是由底层的汇编指令UCOMISD完成,这是一个无序比较双精度浮点数的指令,该指令会考虑到NaN的情况,因此结果就是任何数字都不等于NaN,NaN也不等于自身,这也造成了每次哈希值都不相同。关于这一点社区也曾激烈讨论过,但是官方认为没有必要去修改,所以应当尽量避免使用NaN作为map的键。
删除
delete(m map[Type]Type1, key Type)
删除一个键值对需要用到内置函数delete,例如
func main() { mp := map[string]int{ "a": 0, "b": 1, "c": 2, "d": 3, } fmt.Println(mp) //map[a:0 b:1 c:2 d:3] delete(mp, "a") fmt.Println(mp) //map[b:1 c:2 d:3] }
需要注意的是,如果值为NaN,甚至没法删除该键值对。
func main() { mp := make(map[float64]string, 10) mp[math.NaN()] = "a" mp[math.NaN()] = "b" mp[math.NaN()] = "c" fmt.Println(mp) //map[NaN:c NaN:a NaN:b] delete(mp, math.NaN()) fmt.Println(mp) //map[NaN:c NaN:a NaN:b] }
遍历
通过for range可以遍历map,例如
func main() { mp := map[string]int{ "a": 0, "b": 1, "c": 2, "d": 3, } for key, val := range mp { fmt.Println(key, val) } } c 2 d 3 a 0 b 1
可以看到结果并不是有序的,也印证了map是无序存储。值得一提的是,NaN虽然没法正常获取,但是可以通过遍历访问到,例如
func main() { mp := make(map[float64]string, 10) mp[math.NaN()] = "a" mp[math.NaN()] = "b" mp[math.NaN()] = "c" for key, val := range mp { fmt.Println(key, val) } } NaN a NaN c NaN b
清空
在go1.21之前,想要清空map,就只能对每一个map的key进行delete
func main() { m := map[string]int{ "a": 1, "b": 2, } for k, _ := range m { delete(m, k) } fmt.Println(m) }
但是go1.21更新了clear函数,就不用再进行之前的操作了,只需要一个clear就可以清空
func main() { m := map[string]int{ "a": 1, "b": 2, } clear(m) fmt.Println(m) }
输出
map[]
Set
Set是一种无序的,不包含重复元素的集合,Go中并没有提供类似的数据结构实现,但是map的键正是无序且不能重复的,所以也可以使用map来替代set。
func main() { set := make(map[int]struct{}, 10) for i := 0; i < 10; i++ { set[rand.Intn(100)] = struct{}{} } fmt.Println(set) } map[0:{} 18:{} 25:{} 40:{} 47:{} 56:{} 59:{} 81:{} 87:{}]
提示: 一个空的结构体不会占用内存
实例1:
Go
package main
import "fmt"
func main() {
var siteMap map[string]string /*创建集合 */
siteMap = make(map[string]string)
/* map 插入 key - value 对,各个国家对应的首都 */
siteMap [ "Google" ] = "谷歌"
siteMap [ "Baidu" ] = "百度"
siteMap [ "Wiki" ] = "维基百科"
/*使用键输出地图值 */
for site := range siteMap {
fmt.Println(site, "首都是", siteMap [site])
}
/*查看元素在集合中是否存在 */
name, ok := siteMap [ "Facebook" ] /*如果确定是真实的,则存在,否则不存在 */
/*fmt.Println(name) */
/*fmt.Println(ok) */
if (ok) {
fmt.Println("Facebook 的 站点是", name)
} else {
fmt.Println("Facebook 站点不存在")
}
}以上实例运行结果为:
Wiki 首都是 维基百科 Google 首都是 谷歌 Baidu 首都是 百度 Facebook 站点不存在
实例2:
Go
package main
import "fmt"
func main() {
/* 创建map */
countryCapitalMap := map[string]string{"France": "Paris", "Italy": "Rome", "Japan": "Tokyo", "India": "New delhi"}
fmt.Println("原始地图")
/* 打印地图 */
for country := range countryCapitalMap {
fmt.Println(country, "首都是", countryCapitalMap[country])
}
/*删除元素*/
delete(countryCapitalMap, "France")
fmt.Println("法国条目被删除")
fmt.Println("删除元素后地图")
/*打印地图*/
for country := range countryCapitalMap {
fmt.Println(country, "首都是", countryCapitalMap [ country ])
}
}以上实例运行结果为:
原始地图 India 首都是 New delhi France 首都是 Paris Italy 首都是 Rome Japan 首都是 Tokyo 法国条目被删除 删除元素后地图 Italy 首都是 Rome Japan 首都是 Tokyo India 首都是 New delhi
注意
map并不是一个并发安全的数据结构,Go团队认为大多数情况下map的使用并不涉及高并发的场景,引入互斥锁会极大的降低性能,map内部有读写检测机制,如果冲突会触发fatal error。例如下列情况有非常大的可能性会触发fatal。
func main() { group.Add(10) // map mp := make(map[string]int, 10) for i := 0; i < 10; i++ { go func() { // 写操作 for i := 0; i < 100; i++ { mp["helloworld"] = 1 } // 读操作 for i := 0; i < 10; i++ { fmt.Println(mp["helloworld"]) } group.Done() }() } group.Wait() } fatal error: concurrent map writes
在这种情况下,需要使用互斥锁sync.Map来替代。
16.指针
Go 语言中指针是很容易学习的,Go 语言中使用指针可以更简单的执行一些任务。
接下来让我们来一步步学习 Go 语言指针。
我们都知道,变量是一种使用方便的占位符,用于引用计算机内存地址。
Go 语言的取地址符是 &,放到一个变量前使用就会返回相应变量的内存地址。
以下实例演示了变量在内存中地址:
实例
Go
package main
import "fmt"
func main() {
var a int = 10
fmt.Printf("变量的地址: %x\n", &a )
}执行以上代码输出结果为:
变量的地址: 20818a220
什么是指针
现在我们已经了解了什么是内存地址和如何去访问它。接下来我们将具体介绍指针。什么是指针
一个指针变量指向了一个值的内存地址。
类似于变量和常量,在使用指针前你需要声明指针。指针声明格式如下:
var var_name *var-type
var-type 为指针类型,var_name 为指针变量名,* 号用于指定变量是作为一个指针。以下是有效的指针声明:
var ip *int /* 指向整型*/ var fp *float32 /* 指向浮点型 */
本例中这是一个指向 int 和 float32 的指针。
创建
解引用符则有两个用途,第一个是访问指针所指向的元素,也就是解引用,例如
func main() { num := 2 p := &num rawNum := *p fmt.Println(rawNum) }
p是一个指针,对指针类型解引用就能访问到指针所指向的元素。还有一个用途就是声明一个指针,例如:
func main() { var numPtr *int fmt.Println(numPtr) } <nil>
*int即代表该变量的类型是一个int类型的指针,不过指针不能只声明,还得初始化,需要为其分配内存,否则就是一个空指针,无法正常使用。要么使用取地址符将其他变量的地址赋值给该指针,要么就使用内置函数new手动分配,例如:
func main() { var numPtr *int numPtr = new(int) fmt.Println(numPtr) }
更多的是使用短变量
func main() { numPtr := new(int) fmt.Println(numPtr) }
new函数只有一个参数那就是类型,并返回一个对应类型的指针,函数会为该指针分配内存,并且指针指向对应类型的零值,例如:
func main() { fmt.Println(*new(string)) fmt.Println(*new(int)) fmt.Println(*new([5]int)) fmt.Println(*new([]float64)) } 0 [0 0 0 0 0] []
如何使用指针
指针使用流程:
-
定义指针变量。
-
为指针变量赋值。
-
访问指针变量中指向地址的值。
在指针类型前面加上 * 号(前缀)来获取指针所指向的内容。
实例
Go
package main
import "fmt"
func main() {
var a int= 20 /* 声明实际变量 */
var ip *int /* 声明指针变量 */
ip = &a /* 指针变量的存储地址 */
fmt.Printf("a 变量的地址是: %x\n", &a )
/* 指针变量的存储地址 */
fmt.Printf("ip 变量储存的指针地址: %x\n", ip )
/* 使用指针访问值 */
fmt.Printf("*ip 变量的值: %d\n", *ip )
}以上实例执行输出结果为:
a 变量的地址是: 20818a220 ip 变量储存的指针地址: 20818a220 *ip 变量的值: 20
指针数组
在我们了解指针数组前,先看个实例,定义了长度为 3 的整型数组:
实例
Go
package main
import "fmt"
const MAX int = 3
func main() {
a := []int{10,100,200}
var i int
for i = 0; i < MAX; i++ {
fmt.Printf("a[%d] = %d\n", i, a[i] )
}
}以上代码执行输出结果为:
a[0] = 10 a[1] = 100 a[2] = 200
有一种情况,我们可能需要保存数组,这样我们就需要使用到指针。
以下声明了整型指针数组:
var ptr [MAX]*int;
ptr 为整型指针数组。因此每个元素都指向了一个值。以下实例的三个整数将存储在指针数组中:
实例
Go
package main
import "fmt"
const MAX int = 3
func main() {
a := []int{10,100,200}
var i int
var ptr [MAX]*int;
for i = 0; i < MAX; i++ {
ptr[i] = &a[i] /* 整数地址赋值给指针数组 */
}
for i = 0; i < MAX; i++ {
fmt.Printf("a[%d] = %d\n", i,*ptr[i] )
}
}以上代码执行输出结果为:
a[0] = 10 a[1] = 100 a[2] = 200
指向指针的指针
如果一个指针变量存放的又是另一个指针变量的地址,则称这个指针变量为指向指针的指针变量。
当定义一个指向指针的指针变量时,第一个指针存放第二个指针的地址,第二个指针存放变量的地址:

指向指针的指针变量声明格式如下:
var ptr **int;
以上指向指针的指针变量为整型。
访问指向指针的指针变量值需要使用两个 * 号,如下所示:
Go
package main
import "fmt"
func main() {
var a int
var ptr *int
var pptr **int
a = 3000
/* 指针 ptr 地址 */
ptr = &a
/* 指向指针 ptr 地址 */
pptr = &ptr
/* 获取 pptr 的值 */
fmt.Printf("变量 a = %d\n", a )
fmt.Printf("指针变量 *ptr = %d\n", *ptr )
fmt.Printf("指向指针的指针变量 **pptr = %d\n", **pptr)
}以上实例执行输出结果为:
变量 a = 3000 指针变量 *ptr = 3000 指向指针的指针变量 **pptr = 3000
指针作为函数参数
Go 语言允许向函数传递指针,只需要在函数定义的参数上设置为指针类型即可。
以下实例演示了如何向函数传递指针,并在函数调用后修改函数内的值,:
实例
Go
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int= 200
fmt.Printf("交换前 a 的值 : %d\n", a )
fmt.Printf("交换前 b 的值 : %d\n", b )
/* 调用函数用于交换值
* &a 指向 a 变量的地址
* &b 指向 b 变量的地址
*/
swap(&a, &b);
fmt.Printf("交换后 a 的值 : %d\n", a )
fmt.Printf("交换后 b 的值 : %d\n", b )
}
func swap(x *int, y *int) {
var temp int
temp = *x /* 保存 x 地址的值 */
*x = *y /* 将 y 赋值给 x */
*y = temp /* 将 temp 赋值给 y */
}以上实例允许输出结果为:
交换前 a 的值 : 100 交换前 b 的值 : 200 交换后 a 的值 : 200 交换后 b 的值 : 100
禁止指针运算
在Go中是不支持指针运算的,也就是说指针无法偏移,先来看一段C++代码:
int main() { int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9}; int *p = &arr[0]; cout << &arr << endl << p << endl << p + 1 << endl << &arr[1] << endl; } 0x31d99ff880 0x31d99ff880 0x31d99ff884 0x31d99ff884
可以看出数组的地址与数字第一个元素的地址一致,并且对指针加一运算后,其指向的元素为数组第二个元素。Go中的数组也是如此,不过区别在于指针无法偏移,例如
func main() { arr := [5]int{0, 1, 2, 3, 4} p := &arr println(&arr[0]) println(p) // 试图进行指针运算 p++ fmt.Println(p) }
这样的程序将无法通过编译,报错如下
main.go:10:2: invalid operation: p++ (non-numeric type *[5]int)
提示
标准库unsafe提供了许多用于低级编程的操作,其中就包括指针运算,前往标准库-unsafe了解细节。
new和make
在前面的几节已经很多次提到过内置函数new和make,两者有点类似,但也有不同,下面复习下。
func new(Type) *Type
-
返回值是类型指针
-
接收参数是类型
-
专用于给指针分配内存空间
func make(t Type, size ...IntegerType) Type
-
返回值是值,不是指针
-
接收的第一个参数是类型,不定长参数根据传入类型的不同而不同
-
专用于给切片,映射表,通道分配内存。
下面是一些例子:
new(int) // int指针 new(string) // string指针 new([]int) // 整型切片指针 make([]int, 10, 100) // 长度为10,容量100的整型切片 make(map[string]int, 10) // 容量为10的映射表 make(chan int, 10) // 缓冲区大小为10的通道
17.Range(范围)
Go 语言中 range 关键字用于 for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。
for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环。格式如下:
for key, value := range oldMap { newMap[key] = value }
以上代码中的 key 和 value 是可以省略。
如果只想读取 key,格式如下:
for key := range oldMap
或者这样:
for key, _ := range oldMap
如果只想读取 value,格式如下:
for _, value := range oldMap
数组和切片
遍历简单的切片,2**%d 的结果为 2 对应的次方数:
实例
Go
package main
import "fmt"
// 声明一个包含 2 的幂次方的切片
var pow = []int{1, 2, 4, 8, 16, 32, 64, 128}
func main() {
// 遍历 pow 切片,i 是索引,v 是值
for i, v := range pow {
// 打印 2 的 i 次方等于 v
fmt.Printf("2**%d = %d\n", i, v)
}
}以上实例运行输出结果为:
2**0 = 1 2**1 = 2 2**2 = 4 2**3 = 8 2**4 = 16 2**5 = 32 2**6 = 64 2**7 = 128
字符串
range 迭代字符串时,返回每个字符的索引和 Unicode 代码点(rune)。
实例
Go
package main
import "fmt"
func main() {
for i, c := range "hello" {
fmt.Printf("index: %d, char: %c\n", i, c)
}
}以上实例运行输出结果为:
index: 0, char: h index: 1, char: e index: 2, char: l index: 3, char: l index: 4, char: o
映射(Map)
for 循环的 range 格式可以省略 key 和 value,如下实例:
实例
Go
package main
import "fmt"
func main() {
// 创建一个空的 map,key 是 int 类型,value 是 float32 类型
map1 := make(map[int]float32)
// 向 map1 中添加 key-value 对
map1[1] = 1.0
map1[2] = 2.0
map1[3] = 3.0
map1[4] = 4.0
// 遍历 map1,读取 key 和 value
for key, value := range map1 {
// 打印 key 和 value
fmt.Printf("key is: %d - value is: %f\n", key, value)
}
// 遍历 map1,只读取 key
for key := range map1 {
// 打印 key
fmt.Printf("key is: %d\n", key)
}
// 遍历 map1,只读取 value
for _, value := range map1 {
// 打印 value
fmt.Printf("value is: %f\n", value)
}
}以上实例运行输出结果为:
key is: 4 - value is: 4.000000 key is: 1 - value is: 1.000000 key is: 2 - value is: 2.000000 key is: 3 - value is: 3.000000 key is: 1 key is: 2 key is: 3 key is: 4 value is: 1.000000 value is: 2.000000 value is: 3.000000 value is: 4.000000
忽略值
在遍历时可以使用 _ 来忽略索引或值。
实例
Go
package main
import "fmt"
func main() {
nums := []int{2, 3, 4}
// 忽略索引
for _, num := range nums {
fmt.Println("value:", num)
}
// 忽略值
for i := range nums {
fmt.Println("index:", i)
}
}以上实例运行输出结果为:
value: 2 value: 3 value: 4 index: 0 index: 1 index: 2
其他
range 遍历其他数据结构:
实例
Go
package main
import "fmt"
func main() {
//这是我们使用 range 去求一个 slice 的和。使用数组跟这个很类似
nums := []int{2, 3, 4}
sum := 0
for _, num := range nums {
sum += num
}
fmt.Println("sum:", sum)
//在数组上使用 range 将传入索引和值两个变量。上面那个例子我们不需要使用该元素的序号,所以我们使用空白符"_"省略了。有时侯我们确实需要知道它的索引。
for i, num := range nums {
if num == 3 {
fmt.Println("index:", i)
}
}
//range 也可以用在 map 的键值对上。
kvs := map[string]string{"a": "apple", "b": "banana"}
for k, v := range kvs {
fmt.Printf("%s -> %s\n", k, v)
}
//range也可以用来枚举 Unicode 字符串。第一个参数是字符的索引,第二个是字符(Unicode的值)本身。
for i, c := range "go" {
fmt.Println(i, c)
}
}以上实例运行输出结果为:
sum: 9 index: 1 a -> apple b -> banana 0 103 1 111
18.类型转换
类型转换用于将一种数据类型的变量转换为另外一种类型的变量。
Go 语言类型转换基本格式如下:
type_name(expression)
type_name 为类型,expression 为表达式。
数值类型转换
将整型转换为浮点型:
var a int = 10 var b float64 = float64(a)
以下实例中将整型转化为浮点型,并计算结果,将结果赋值给浮点型变量:
实例
Go
package main
import "fmt"
func main() {
var sum int = 17
var count int = 5
var mean float32
mean = float32(sum)/float32(count)
fmt.Printf("mean 的值为: %f\n",mean)
}以上实例执行输出结果为:
mean 的值为: 3.400000
字符串类型转换
将一个字符串转换成另一个类型,可以使用以下语法:
var str string = "10" var num int num, _ = strconv.Atoi(str)
以上代码将字符串变量 str 转换为整型变量 num。
注意,strconv.Atoi 函数返回两个值,第一个是转换后的整型值,第二个是可能发生的错误,我们可以使用空白标识符 _ 来忽略这个错误。
以下实例将字符串转换为整数
实例
Go
package main
import (
"fmt"
"strconv"
)
func main() {
str := "123"
num, err := strconv.Atoi(str)
if err != nil {
fmt.Println("转换错误:", err)
} else {
fmt.Printf("字符串 '%s' 转换为整数为:%d\n", str, num)
}
}以上实例执行输出结果为:
字符串 '123' 转换为整数为:123
整数转换为字符串
实例
Go
package main
import (
"fmt"
"strconv"
)
func main() {
num := 123
str := strconv.Itoa(num)
fmt.Printf("整数 %d 转换为字符串为:'%s'\n", num, str)
}以上实例执行输出结果为:
整数 123 转换为字符串为:'123'
字符串转换为浮点数
实例
Go
package main
import (
"fmt"
"strconv"
)
func main() {
str := "3.14"
num, err := strconv.ParseFloat(str, 64)
if err != nil {
fmt.Println("转换错误:", err)
} else {
fmt.Printf("字符串 '%s' 转为浮点型为:%f\n", str, num)
}
}以上实例执行输出结果为:
字符串 '3.14' 转为浮点型为:3.140000
浮点数转换为字符串
实例
Go
package main
import (
"fmt"
"strconv"
)
func main() {
num := 3.14
str := strconv.FormatFloat(num, 'f', 2, 64)
fmt.Printf("浮点数 %f 转为字符串为:'%s'\n", num, str)
}以上实例执行输出结果为:
浮点数 3.140000 转为字符串为:'3.14'
接口类型转换
接口类型转换有两种情况**:类型断言** 和类型转换。
类型断言
类型断言用于将接口类型转换为指定类型,其语法为:
value.(type) 或者 value.(T)
其中 value 是接口类型的变量,type 或 T 是要转换成的类型。
如果类型断言成功,它将返回转换后的值和一个布尔值,表示转换是否成功。
实例
Go
package main
import "fmt"
func main() {
var i interface{} = "Hello, World"
str, ok := i.(string)
if ok {
fmt.Printf("'%s' is a string\n", str)
} else {
fmt.Println("conversion failed")
}
}以上实例中,我们定义了一个接口类型变量 i,并将它赋值为字符串 "Hello, World"。然后,我们使用类型断言将 i 转换为字符串类型,并将转换后的值赋值给变量 str。最后,我们使用 ok 变量检查类型转换是否成功,如果成功,我们打印转换后的字符串;否则,我们打印转换失败的消息。
类型转换
类型转换用于将一个接口类型的值转换为另一个接口类型,其语法为:
T(value)
T 是目标接口类型,value 是要转换的值。
在类型转换中,我们必须保证要转换的值和目标接口类型之间是兼容的,否则编译器会报错。
实例
Go
package main
import "fmt"
// 定义一个接口 Writer
type Writer interface {
Write([]byte) (int, error)
}
// 实现 Writer 接口的结构体 StringWriter
type StringWriter struct {
str string
}
// 实现 Write 方法
func (sw *StringWriter) Write(data []byte) (int, error) {
sw.str += string(data)
return len(data), nil
}
func main() {
// 创建一个 StringWriter 实例并赋值给 Writer 接口变量
var w Writer = &StringWriter{}
// 将 Writer 接口类型转换为 StringWriter 类型
sw := w.(*StringWriter)
// 修改 StringWriter 的字段
sw.str = "Hello, World"
// 打印 StringWriter 的字段值
fmt.Println(sw.str)
}解析:
-
定义接口和结构体:
-
Writer接口定义了Write方法。 -
StringWriter结构体实现了Write方法。
-
-
类型转换:
-
将
StringWriter实例赋值给Writer接口变量w。 -
使用
w.(*StringWriter)将Writer接口类型转换为StringWriter类型。
-
-
访问字段:
- 修改
StringWriter的字段str,并打印其值。
- 修改
空接口类型
空接口 interface{} 可以持有任何类型的值。在实际应用中,空接口经常被用来处理多种类型的值。
实例
Go
package main
import (
"fmt"
)
func printValue(v interface{}) {
switch v := v.(type) {
case int:
fmt.Println("Integer:", v)
case string:
fmt.Println("String:", v)
default:
fmt.Println("Unknown type")
}
}
func main() {
printValue(42)
printValue("hello")
printValue(3.14)
}在这个例子中,printValue 函数接受一个空接口类型的参数,并使用类型断言和类型选择来处理不同的类型。
19.接口
接口是一个非常重要的概念,它描述了一组抽象的规范,而不提供具体的实现。对于项目而言会使得代码更加优雅可读,对于开发者而言也会减少很多心智负担,代码风格逐渐形成了规范,于是就有了现在人们所推崇的面向接口编程。
概念
Go关于接口的发展历史有一个分水岭,在Go1.17及以前,官方在参考手册中对于接口的定义为:一组方法的集合。
An interface type specifies a method set called its interface.
接口实现的定义为
A variable of interface type can store a value of any type with a method set that is any superset of the interface. Such a type is said to implement the interface
翻译过来就是:当一个类型的方法集是一个接口的方法集的超集时,且该类型的值可以由该接口类型的变量存储,那么称该类型实现了该接口。
不过在Go1.18时,关于接口的定义发生了变化,接口定义为:一组类型的集合。
An interface type defines a type set.
接口实现的定义为
A variable of interface type can store a value of any type that is in the type set of the interface. Such a type is said to implement the interface
翻译过来就是:当一个类型位于一个接口的类型集内,且该类型的值可以由该接口类型的变量存储,那么称该类型实现了该接口。并且还给出了如下的额外定义。
当如下情况时,可以称类型T实现了接口I
T不是一个接口,并且是接口I类型集中的一个元素
T是一个接口,并且T的类型集是接口I类型集的一个子集
如果T实现了一个接口,那么T的值也实现了该接口。
Go在1.18最大的变化就是加入了泛型,新接口定义就是为了泛型而服务的,不过一点也不影响之前接口的使用,同时接口也分为了两类,
-
基本接口(
Basic Interface):只包含方法集的接口就是基本接口 -
通用接口(
General Interface):只要包含类型集的接口就是通用接口
什么是方法集,方法集就是一组方法的集合,同样的,类型集就是一组类型的集合。
提示
这一堆概念很死板,理解的时候要根据代码来思考。
基本接口
前面讲到了基本接口就是方法集,就是一组方法的集合。
声明
先来看看接口长什么样子。
type Person interface { Say(string) string Walk(int) }
这是一个Person接口,有两个对外暴露的方法Walk和Say,在接口里,函数的参数名变得不再重要,当然如果想加上参数名和返回值名也是允许的。
初始化
仅仅只有接口是无法被初始化的,因为它仅仅只是一组规范,并没有具体的实现,不过可以被声明。
func main() { var person Person fmt.Println(person) }
输出
<nil>
实现
先来看一个例子,一个建筑公司想一种特殊规格的起重机,于是给出了起重机的特殊规范和图纸,并指明了起重机应该有起重和吊货的功能,建筑公司并不负责造起重机,只是给出了一个规范,这就叫接口 ,于是公司A接下了订单,根据自家公司的独门技术造出了绝世起重机并交给了建筑公司,建筑公司不在乎是用什么技术实现的,也不在乎什么绝世起重机,只要能够起重和吊货就行,仅仅只是当作一台普通起重机来用,根据规范提供具体的功能,这就叫实现 ,。只根据接口的规范来使用功能,屏蔽其内部实现,这就叫面向接口编程 。过了一段时间,绝世起重机出故障了,公司A也跑路了,于是公司B依据规范造了一台更厉害的巨无霸起重机,由于同样具有起重和吊货的功能,可以与绝世起重机无缝衔接,并不影响建筑进度,建筑得以顺利完成,内部实现改变而功能不变,不影响之前的使用,可以随意替换,这就是面向接口编程的好处。
接下来会用Go描述上述情形
Go
// 起重机接口
type Crane interface {
JackUp() string
Hoist() string
}
// 起重机A
type CraneA struct {
work int //内部的字段不同代表内部细节不一样
}
func (c CraneA) Work() {
fmt.Println("使用技术A")
}
func (c CraneA) JackUp() string {
c.Work()
return "jackup"
}
func (c CraneA) Hoist() string {
c.Work()
return "hoist"
}
// 起重机B
type CraneB struct {
boot string
}
func (c CraneB) Boot() {
fmt.Println("使用技术B")
}
func (c CraneB) JackUp() string {
c.Boot()
return "jackup"
}
func (c CraneB) Hoist() string {
c.Boot()
return "hoist"
}
type ConstructionCompany struct {
Crane Crane // 只根据Crane类型来存放起重机
}
func (c *ConstructionCompany) Build() {
fmt.Println(c.Crane.JackUp())
fmt.Println(c.Crane.Hoist())
fmt.Println("建筑完成")
}
func main() {
// 使用起重机A
company := ConstructionCompany{CraneA{}}
company.Build()
fmt.Println()
// 更换起重机B
company.Crane = CraneB{}
company.Build()
}输出
使用技术A jackup 使用技术A hoist 建筑完成 使用技术B jackup 使用技术B hoist 建筑完成
上面例子中,可以观察到接口的实现是隐式的,也对应了官方对于基本接口实现的定义:方法集是接口方法集的超集,所以在Go中,实现一个接口不需要implements关键字显式的去指定要实现哪一个接口,只要是实现了一个接口的全部方法,那就是实现了该接口。有了实现之后,就可以初始化接口了,建筑公司结构体内部声明了一个Crane类型的成员变量,可以保存所有实现了Crane接口的值,由于是Crane 类型的变量,所以能够访问到的方法只有JackUp 和Hoist,内部的其他方法例如Work和Boot都无法访问。
之前提到过任何自定义类型都可以拥有方法,那么根据实现的定义,任何自定义类型都可以实现接口,下面举几个比较特殊的例子。
Go
type Person interface {
Say(string) string
Walk(int)
}
type Man interface {
Exercise()
Person
}Man接口方法集是Person的超集,所以Man也实现了接口Person,不过这更像是一种"继承"。
Go
type Number int
func (n Number) Say(s string) string {
return "bibibibibi"
}
func (n Number) Walk(i int) {
fmt.Println("can not walk")
}类型Number的底层类型是int,虽然这放在其他语言中看起来很离谱,但Number的方法集确实是Person 的超集,所以也算实现。
Go
type Func func()
func (f Func) Say(s string) string {//未使用
f()
return "bibibibibi"
}
func (f Func) Walk(i int) { //未使用
f()
fmt.Println("can not walk")
}
func main() {
var function Func
function = func() {
fmt.Println("do somthing")
}
function()
}同样的,函数类型也可以实现接口。
输出结果为
do something
实例 1
以下两个实例演示了接口的使用:
Go
package main
import (
"fmt"
)
type Phone interface {
call()
}
type NokiaPhone struct {
}
func (nokiaPhone NokiaPhone) call() {
fmt.Println("I am Nokia, I can call you!")
}
type IPhone struct {
}
func (iPhone IPhone) call() {
fmt.Println("I am iPhone, I can call you!")
}
func main() {
var phone Phone
phone = new(NokiaPhone)
phone.call()
phone = new(IPhone)
phone.call()
}在上面的例子中,我们定义了一个接口 Phone,接口里面有一个方法call()。然后我们在main 函数里面定义了一个Phone 类型变量,并分别为之赋值为 NokiaPhone 和 IPhone。然后调用 call() 方法,输出结果如下:
I am Nokia, I can call you! I am iPhone, I can call you!
实例2
Go
package main
import "fmt"
type Shape interface {
area() float64
}
type Rectangle struct {
width float64
height float64
}
func (r Rectangle) area() float64 {
return r.width * r.height
}
type Circle struct {
radius float64
}
func (c Circle) area() float64 {
return 3.14 * c.radius * c.radius
}
func main() {
var s Shape
s = Rectangle{width: 10, height: 5}
fmt.Printf("矩形面积: %f\n", s.area())
s = Circle{radius: 3}
fmt.Printf("圆形面积: %f\n", s.area())
}以上实例中,我们定义了一个 Shape 接口,它定义了一个方法 area(),该方法返回一个 float64 类型的面积值。然后,我们定义了两个结构体 Rectangle 和 Circle,它们分别实现了 Shape 接口的area() 方法。在 main() 函数中,我们首先定义了一个 Shape 类型的变量 s,然后分别将 Rectangle 和Circle 类型的实例赋值给它,并通过 area() 方法计算它们的面积并打印出来,输出结果如下:
矩形面积: 50.000000 圆形面积: 28.260000
需要注意的是,接口类型变量可以存储任何实现了该接口的类型的值 。在示例中,我们将 Rectangle 和 Circle 类型的实例都赋值给了 Shape 类型的变量 s,并通过 area() 方法调用它们的面积计算方法。
空接口
type Any interface{ }
Any接口内部没有方法集合,根据实现的定义,所有类型都是Any接口的的实现,因为所有类型的方法集都是空集的超集,所以Any接口可以保存任何类型的值。
Go
func main() {
var anything Any
anything = 1
println(anything)
fmt.Println(anything)
anything = "something"
println(anything)
fmt.Println(anything)
anything = complex(1, 2)
println(anything)
fmt.Println(anything)
anything = 1.2
println(anything)
fmt.Println(anything)
anything = []int{}
println(anything)
fmt.Println(anything)
anything = map[string]int{}
println(anything)
fmt.Println(anything)
}输出
(0xe63580,0xeb8b08) 1 (0xe63d80,0xeb8c48) something (0xe62ac0,0xeb8c58) (1+2i) (0xe62e00,0xeb8b00) 1.2 (0xe61a00,0xc0000080d8) [] (0xe69720,0xc00007a7b0) map[]
通过输出会发现,两种输出的结果不一致,其实接口内部可以看成是一个由(val,type)组成的元组,type是具体类型,在调用方法时会去调用具体类型的具体值。
interface{}
这也是一个空接口,不过是一个匿名空接口,在开发时通常会使用匿名空接口来表示接收任何类型的值,例子如下
func main() { DoSomething(map[int]string{}) } func DoSomething(anything interface{}) interface{} { return anything }
在后续的更新中,官方提出了另一种解决办法,为了方便起见,可以使用any来替代interace{},两者是完全等价的,因为前者仅仅只是一个类型别名,如下
type any = interface{}
在比较空接口时,会对其底层类型进行比较,如果类型不匹配的话则为false,其次才是值的比较,例如
func main() { var a interface{} var b interface{} a = 1 b = "1" fmt.Println(a == b) a = 1 b = 1 fmt.Println(a == b) }
输出为
false true
如果底层的类型是不可比较的,那么会panic,对于Go而言,内置数据类型是否可比较的情况如下
| 类型 | 可比较 | 依据 |
|---|---|---|
| 数字类型 | 是 | 值是否相等 |
| 字符串类型 | 是 | 值是否相等 |
| 数组类型 | 是 | 数组的全部元素是否相等 |
| 切片类型 | 否 | 不可比较 |
| 结构体 | 是 | 字段值是否全部相等 |
| map类型 | 否 | 不可比较 |
| 通道 | 是 | 地址是否相等 |
| 指针 | 是 | 指针存储的地址是否相等 |
| 接口 | 是 | 底层所存储的数据是否相等 |
在Go中有一个专门的接口类型用于代表所有可比较类型,即comparable
type comparable interface{ comparable }
提示:如果尝试对不可比较的类型进行比较,则会panic(无法预知的异常,表示十分严重的程序问题,程序需要立即停止来处理该问题,否则程序立即停止运行并输出堆栈信息)21章有详细说明
20.泛型
示例
在开始之前,先来看一个简单的例子。
func Sum(a, b int) int { return a + b }
这是一个功能十分简单的函数,作用就是将两个int类型的整数相加并返回结果,倘若想要传入两个float64类型的浮点数求和的话,显然是不可以的,因为类型不匹配。一种解决办法就是再定义一个新的函数,如下
func SumFloat64(a, b float64) float64 { return a + b }
那么问题来了,如果开发一个数学工具包,计算所有数字类型的两数之和,难道要每一个类型都要编写一个函数吗?显然是不太可能的,或者也可以使用any类型加反射来判断,如下
func SumAny(a, b any) (any, error) { tA, tB := reflect.ValueOf(a), reflect.ValueOf(b) if tA.Kind() != tB.Kind() { return nil, errors.New("disMatch type") } switch tA.Kind() { case reflect.Int: case reflect.Int32: ... } }
但是这样写会显得十分复杂,而且性能低下。但是Sum函数的逻辑都是一模一样的,都只不过是将两个数相加而已,这时候就需要用到了泛型,所以为什么需要泛型,泛型是为了解决执行逻辑与类型无关的问题,这类问题不关心给出的类型是什么,只需要完成对应的操作就足够。所以泛型的写法如下
func Sum[T int | float64](a, b T) T { return a + b }
类型形参:T就是一个类型形参,形参具体是什么类型取决于传进来什么类型
类型约束 :int | float64构成了一个类型约束,这个类型约束内规定了哪些类型是允许的,约束了类型形参的类型范围
类型实参 :Sum[int](1,2),手动指定了int类型,int就是类型实参。
第一种用法,显式的指明使用哪种类型,如下
Sum[int](2012, 2022)
第二种用法,不指定类型,让编译器自行推断,如下
Sum(3.1415926, 1.114514)
看到这里后,应该对为什么要使用泛型,以及泛型解决了哪种问题有了一个大概的了解。将泛型引入项目后,开发上确实会比较方便,随之而来的是项目复杂度的增加,毫无节制的使用泛型会使得代码难以维护,所以应该在正确的地方使用泛型,而不是为了泛型而泛型。
泛型结构
这是一个泛型切片,类型约束为int | int32 | int64
type GenericSlice[T int | int32 | int64] []T
这里使用时就不能省略掉类型实参
GenericSlice[int]{1, 2, 3}
这是一个泛型哈希表,键的类型必须是可比较的,所以使用comparable接口,值的类型约束为V int | string | byte
type GenericMap[K comparable, V int | string | byte] map[K]V
使用
gmap1 := GenericMap[int, string]{1: "hello world"} gmap2 := make(GenericMap[string, byte], 0)
这是一个泛型结构体,类型约束为T int | string
type GenericStruct[T int | string] struct { Name string Id T }
使用
GenericStruct[int]{ Name: "jack", Id: 1024, } GenericStruct[string]{ Name: "Mike", Id: "1024", }
这是一个泛型切片形参的例子
type Company[T int | string, S []T] struct { Name string Id T Stuff S } //也可以如下 type Company[T int | string, S []int | string] struct { Name string Id T Stuff S }
使用
Company[int, []int]{ Name: "lili", Id: 1, Stuff: []int{1}, }
提示
在泛型结构体中,更推荐这种写法
Go
type Company[T int | string, S int | string] struct {
Name string
Id T
Stuff []S
}
SayAble是一个泛型接口,Person实现了该接口。
type SayAble[T int | string] interface {
Say() T
}
type Person[T int | string] struct {
msg T
}
func (p Person[T]) Say() T {
return p.msg
}
func main() {
var s SayAble[string]
s = Person[string]{"hello world"}
fmt.Println(s.Say())
}泛型结构注意点
泛型不能作为一个类型的基本类型
以下写法是错误的,泛型形参T是不能作为基础类型的
type GenericType[T int | int32 | int64] T
虽然下列的写法是允许的,不过毫无意义而且可能会造成数值溢出的问题,虽然并不推荐
type GenericType[T int | int32 | int64] int
泛型类型无法使用类型断言
对泛型类型使用类型断言将会无法通过编译,泛型要解决的问题是类型无关 的,如果一个问题需要根据不同类型做出不同的逻辑,那么就根本不应该使用泛型,应该使用interface{}或者any。
func Sum[T int | float64](a, b T) T { ints,ok := a.(int) // 不被允许 switch a.(type) { // 不被允许 case int: case bool: ... } return a + b }
匿名结构不支持泛型
匿名结构体是不支持泛型的,如下的代码将无法通过编译
testStruct := struct[T int | string] { Name string Id T }[int]{ Name: "jack", Id: 1 }
匿名函数不支持自定义泛型
以下两种写法都将无法通过编译
var sum[T int | string] func (a, b T) T sum := func[T int | string](a,b T) T{ ... }
但是可以使用已有的泛型类型,例如闭包中
func Sum[T int | float64](a, b T) T { sub := func(c, d T) T { return c - d } return sub(a,b) + a + b }
不支持泛型方法
方法是不能拥有泛型形参的,但是receiver可以拥有泛型形参。如下的代码将会无法通过编译
type GenericStruct[T int | string] struct { Name string Id T } func (g GenericStruct[T]) name[S int | float64](a S) S { return a }
类型集
在1.18以后,接口的定义变为了类型集(type set),含有类型集的接口又称为General interfaces即通用接口。
An interface type defines a type setopen in new window
类型集主要用于类型约束,不能用作类型声明,既然是集合,就会有空集,并集,交集,接下来将会讲解这三种情况。
并集
接口类型SignedInt是一个类型集,有符号整数类型的并集就是SignedInt,反过来SignedInt就是它们的超集。
type SignedInt interface { int8 | int16 | int | int32 | int64 }
基本数据类型如此,对待其它通用接口也是如此
type SignedInt interface { int8 | int16 | int | int32 | int64 } type UnSignedInt interface { uint8 | uint16 | uint32 | uint64 } type Integer interface { SignedInt | UnSignedInt }
交集
非空接口的类型集是其所有元素的类型集的交集,即如果一个接口包含多个非空类型集,那么该接口就是这些类型集的交集,例子如下
type SignedInt interface { int8 | int16 | int | int32 | int64 } type Integer interface { int8 | int16 | int | int32 | int64 | uint8 | uint16 | uint | uint32 | uint64 } type Number interface { SignedInt Integer }
例子中的交集肯定就是SignedInt,
func Do[T Number](n T) T { return n } Do[int](2) DO[uint](2) //无法通过编译
空集
空集就是没有交集,例子如下,下面例子中的Integer就是一个类型空集。
type SignedInt interface { int8 | int16 | int | int32 | int64 } type UnsignedInt interface { uint8 | uint16 | uint | uint32 | uint64 } type Integer interface { SignedInt UnsignedInt }
因为无符号整数和有符号整数两个肯定没有交集,所以交集就是个空集,下方例子中不管传什么类型都无法通过编译。
Do[Integer](1) Do[Integer](-100)
空接口
空接口与空集并不同,空接口是所有类型集的集合,即包含所有类型。
func Do[T interface{}](n T) T { return n } func main() { Do[struct{}](struct{}{}) Do[any]("abc") }
底层类型
当使用type关键字声明了一个新的类型时,即便其底层类型包含在类型集内,当传入时也依旧会无法通过编译。
type Int interface { int8 | int16 | int | int32 | int64 | uint8 | uint16 | uint | uint32 | uint64 } type TinyInt int8 func Do[T Int](n T) T { return n } func main() { Do[TinyInt](1) // 无法通过编译,即便其底层类型属于Int类型集的范围内 }
有两种解决办法,第一种是往类型集中并入该类型,但是这毫无意义,因为TinyInt与int8底层类型就是一致的,所以就有了第二种解决办法。
type Int interface { int8 | int16 | int | int32 | int64 | uint8 | uint16 | uint | uint32 | uint64 | TinyInt }
使用~符号,来表示底层类型,如果一个类型的底层类型属于该类型集,那么该类型就属于该类型集,如下所示
type Int interface { ~int8 | ~int16 | ~int | ~int32 | ~int64 | ~uint8 | ~uint16 | ~uint | ~uint32 | ~uint64 }
修改过后就可以通过编译了。
func main() { Do[TinyInt](1) // 可以通过编译,因为TinyInt在类型集Int内 }
类型集注意点
带有方法集的接口无法并入类型集
只要是带有方法集的接口,不论是基本接口,泛型接口,又或者是通用接口,都无法并入类型集中,同样的也无法在类型约束中并入。以下两种写法都是错误的,都无法通过编译。
type Integer interface { Sum(int, int) int Sub(int, int) int } type SignedInt interface { int8 | int16 | int | int32 | int64 | Integer } func Do[T Integer | float64](n T) T { return n }
类型集无法当作类型实参使用
只要是带有类型集的接口,都无法当作类型实参。
type SignedInt interface { int8 | int16 | int | int32 | int64 } func Do[T SignedInt](n T) T { return n } func main() { Do[SignedInt](1) // 无法通过编译 }
类型集中的交集问题
对于非接口类型,类型并集中不能有交集,例如下例中的TinyInt与~int8有交集。
type Int interface { ~int8 | ~int16 | ~int | ~int32 | ~int64 | ~uint8 | ~uint16 | ~uint | ~uint32 | ~uint64 | TinyInt // 无法通过编译 } type TinyInt int8
但是对于接口类型的话,就允许有交集,如下例
type Int interface { ~int8 | ~int16 | ~int | ~int32 | ~int64 | ~uint8 | ~uint16 | ~uint | ~uint32 | ~uint64 | TinyInt // 可以通过编译 } type TinyInt interface { int8 }
类型集不能直接或间接的并入自身
以下示例中,Floats 直接的并入了自身,而Double又并入了Floats,所以又间接的并入了自身。
type Floats interface { // 代码无法通过编译 Floats | Double } type Double interface { Floats }
comparable接口无法并入类型集
同样的,也无法并入类型约束中,所以基本上都是单独使用。
func Do[T comparable | Integer](n T) T { //无法通过编译 return n } type Number interface { // 无法通过编译 Integer | comparable } type Comparable interface { // 可以通过编译但是毫无意义 comparable }
使用
数据结构是泛型最常见的使用场景,下面借由两个数据结构来展示下泛型如何使用。
队列
下面用泛型实现一个简单的队列,首先声明队列类型,队列中的元素类型可以是任意的,所以类型约束为any
type Queue[T any] []T
总共只有四个方法Pop ,Peek,Push,Size,代码如下。
type Queue[T any] []T func (q *Queue[T]) Push(e T) { *q = append(*q, e) } func (q *Queue[T]) Pop(e T) (_ T) { if q.Size() > 0 { res := q.Peek() *q = (*q)[1:] return res } return } func (q *Queue[T]) Peek() (_ T) { if q.Size() > 0 { return (*q)[0] } return } func (q *Queue[T]) Size() int { return len(*q) }
在Pop和Peek方法中,可以看到返回值是_ T,这是具名返回值的使用方式,但是又采用了下划线_表示这是匿名的,这并非多此一举,而是为了表示泛型零值。由于采用了泛型,当队列为空时,需要返回零值,但由于类型未知,不可能返回具体的类型,借由上面的那种方式就可以返回泛型零值。也可以声明泛型变量的方式来解决零值问题,对于一个泛型变量,其默认的值就是该类型的零值,如下
func (q *Queue[T]) Pop(e T) T { var res T if q.Size() > 0 { res = q.Peek() *q = (*q)[1:] return res } return res }
堆
上面队列的例子,由于对元素没有任何的要求,所以类型约束为any。但堆就不一样了,堆是一种特殊的数据结构,它可以在O(1)的时间内判断最大或最小值,所以它对元素有一个要求,那就是必须是可以排序的类型,但内置的可排序类型只有数字和字符串,并且go的泛型约束不允许存在带方法的接口,所以在堆的初始化时,需要传入一个自定义的比较器,比较器由使用者提供,比较器也必须使用泛型,如下
type Comparator[T any] func(a, b T) int
下面是一个简单的二项最小堆的实现,先声明泛型结构体,依旧采用any进行约束,这样可以存放任意类型
type Comparator[T any] func(a, b T) int type BinaryHeap[T any] struct { s []T c Comparator[T] }
几个方法实现
Go
func (heap *BinaryHeap[T]) Peek() (_ T) {
if heap.Size() > 0 {
return heap.s[0]
}
return
}
func (heap *BinaryHeap[T]) Pop() (_ T) {
size := heap.Size()
if size > 0 {
res := heap.s[0]
heap.s[0], heap.s[size-1] = heap.s[size-1], heap.s[0]
heap.s = heap.s[:size-1]
heap.down(0)
return res
}
return
}
func (heap *BinaryHeap[T]) Push(e T) {
heap.s = append(heap.s, e)
heap.up(heap.Size() - 1)
}
func (heap *BinaryHeap[T]) up(i int) {
if heap.Size() == 0 || i < 0 || i >= heap.Size() {
return
}
for parentIndex := i>>1 - 1; parentIndex >= 0; parentIndex = i>>1 - 1 {
// greater than or equal to
if heap.compare(heap.s[i], heap.s[parentIndex]) >= 0 {
break
}
heap.s[i], heap.s[parentIndex] = heap.s[parentIndex], heap.s[i]
i = parentIndex
}
}
func (heap *BinaryHeap[T]) down(i int) {
if heap.Size() == 0 || i < 0 || i >= heap.Size() {
return
}
size := heap.Size()
for lsonIndex := i<<1 + 1; lsonIndex < size; lsonIndex = i<<1 + 1 {
rsonIndex := lsonIndex + 1
if rsonIndex < size && heap.compare(heap.s[rsonIndex], heap.s[lsonIndex]) < 0 {
lsonIndex = rsonIndex
}
// less than or equal to
if heap.compare(heap.s[i], heap.s[lsonIndex]) <= 0 {
break
}
heap.s[i], heap.s[lsonIndex] = heap.s[lsonIndex], heap.s[i]
i = lsonIndex
}
}
func (heap *BinaryHeap[T]) Size() int {
return len(heap.s)
}使用起来如下
Go
type Person struct {
Age int
Name string
}
func main() {
heap := NewHeap[Person](10, func(a, b Person) int {
return cmp.Compare(a.Age, b.Age)
})
heap.Push(Person{Age: 10, Name: "John"})
heap.Push(Person{Age: 18, Name: "mike"})
heap.Push(Person{Age: 9, Name: "lili"})
heap.Push(Person{Age: 32, Name: "miki"})
fmt.Println(heap.Peek())
fmt.Println(heap.Pop())
fmt.Println(heap.Peek())
}输出
{9 lili} {9 lili} {10 John}
有泛型的加持,原本不可排序的类型传入比较器后也可以使用堆了,这样做肯定比以前使用interface{}来进行类型转换和断言要优雅和方便很多。
小结
go的一大特点就是编译速度非常快,编译快是因为编译期做的优化少,泛型的加入会导致编译器的工作量增加,工作更加复杂,这必然会导致编译速度变慢,事实上当初go1.18刚推出泛型的时候确实导致编译更慢了,go团队既想加入泛型又不想太拖累编译速度,开发者用的顺手,编译器就难受,反过来编译器轻松了(最轻松的当然是直接不要泛型),开发者就难受了,现如今的泛型就是这两者之间妥协后的产物。
21.错误处理
error
error属于是一种正常的流程错误,它的出现是可以被接受的,大多数情况下应该对其进行处理,当然也可以忽略不管,error的严重级别不足以停止整个程序的运行。error本身是一个预定义的接口,该接口下只有一个方法Error(),该方法的返回值是字符串,用于输出错误信息。
type error interface { Error() string }
error在历史上也有过大改,在1.13版本时Go团队推出了链式错误,且提供了更加完善的错误检查机制,接下来都会一一介绍。
创建
创建一个error有以下几种方法,第一种是使用errors包下的New函数。
err := errors.New("这是一个错误")
第二种是使用fmt包下的Errorf函数,可以得到一个格式化参数的error。
err := fmt.Errorf("这是%d个格式化参数的的错误", 1)下面是一个完整的例子
func sumPositive(i, j int) (int, error) { if i <= 0 || j <= 0 { return -1, errors.New("必须是正整数") } return i + j, nil }
大部分情况,为了更好的维护性,一般都不会临时创建error,而是会将常用的error当作全局变量使用,例如下方节选自os\erros.go文件的代码
var ( ErrInvalid = fs.ErrInvalid // "invalid argument" ErrPermission = fs.ErrPermission // "permission denied" ErrExist = fs.ErrExist // "file already exists" ErrNotExist = fs.ErrNotExist // "file does not exist" ErrClosed = fs.ErrClosed // "file already closed" ErrNoDeadline = errNoDeadline() // "file type does not support deadline" ErrDeadlineExceeded = errDeadlineExceeded() // "i/o timeout" )
可以看到它们都是被var定义的变量
自定义错误
通过实现Error()方法,可以很轻易的自定义error,例如erros包下的errorString就是一个很简单的实现。
func New(text string) error { return &errorString{text} } // errorString结构体 type errorString struct { s string } func (e *errorString) Error() string { return e.s }
因为errorString实现太过于简单,表达能力不足,所以很多开源库包括官方库都会选择自定义error,以满足不同的错误需求。
传递
在一些情况中,调用者调用的函数返回了一个错误,但是调用者本身不负责处理错误,于是也将错误作为返回值返回,抛给上一层调用者,这个过程叫传递,错误在传递的过程中可能会层层包装,当上层调用者想要判断错误的类型来做出不同的处理时,可能会无法判别错误的类别或者误判,而链式错误正是为了解决这种情况而出现的。
type wrapError struct { msg string err error } func (e *wrapError) Error() string { return e.msg } func (e *wrapError) Unwrap() error { return e.err }
wrappError同样实现了error接口,也多了一个方法Unwrap,用于返回其内部对于原error的引用,层层包装下就形成了一条错误链表,顺着链表上寻找,很容易就能找到原始错误。由于该结构体并不对外暴露,所以只能使用fmt.Errorf函数来进行创建,例如
err := errors.New("这是一个原始错误") wrapErr := fmt.Errorf("错误,%w", err)
使用时,必须使用%w格式动词,且参数只能是一个有效的error。
处理
错误处理中的最后一步就是如何处理和检查错误,errors包提供了几个方便函数用于处理错误。
func Unwrap(err error) error
errors.Unwrap()函数用于解包一个错误链,其内部实现也很简单
func Unwrap(err error) error { u, ok := err.(interface { // 类型断言,是否实现该方法 Unwrap() error }) if !ok { //没有实现说明是一个基础的error return nil } return u.Unwrap() // 否则调用Unwrap }
解包后会返回当前错误链所包裹的错误,被包裹的错误可能依旧是一个错误链,如果想要在错误链中找到对应的值或类型,可以递归进行查找匹配,不过标准库已经提供好了类似的函数。
func Is(err, target error) bool
errors.Is函数的作用是判断错误链中是否包含指定的错误,例子如下
var originalErr = errors.New("this is an error") func wrap1() error { // 包裹原始错误 return fmt.Errorf("wrapp error %w", wrap2()) } func wrap2() error { // 原始错误 return originalErr } func main() { err := wrap1() if errors.Is(err, originalErr) { // 如果使用if err == originalErr 将会是false fmt.Println("original") } }
所以在判断错误时,不应该使用==操作符,而是应该使用errors.Is()。
func As(err error, target any) bool
errors.As()函数的作用是在错误链中寻找第一个类型匹配的错误,并将值赋值给传入的err。有些情况下需要将error类型的错误转换为具体的错误实现类型,以获得更详细的错误细节,而对一个错误链使用类型断言是无效的,因为原始错误是被结构体包裹起来的,这也是为什么需要As函数的原因。例子如下
Go
type TimeError struct { // 自定义error
Msg string
Time time.Time //记录发生错误的时间
}
func (m TimeError) Error() string {
return m.Msg
}
func NewMyError(msg string) error {
return &TimeError{
Msg: msg,
Time: time.Now(),
}
}
func wrap1() error { // 包裹原始错误
return fmt.Errorf("wrapp error %w", wrap2())
}
func wrap2() error { // 原始错误
return NewMyError("original error")
}
func main() {
var myerr *TimeError
err := wrap1()
// 检查错误链中是否有*TimeError类型的错误
if errors.As(err, &myerr) { // 输出TimeError的时间
fmt.Println("original", myerr.Time)
}
}target必须是指向error的指针,由于在创建结构体时返回的是结构体指针,所以error实际上*TimeError类型的,那么target就必须是**TimeError类型的。
不过官方提供的errors包其实并不够用,因为它没有堆栈信息,不能定位,一般会比较推荐使用官方的另一个增强包
github.com/pkg/errors
例子
Go
import (
"fmt"
"github.com/pkg/errors"
)
func Do() error {
return errors.New("error")
}
func main() {
if err := Do(); err != nil {
fmt.Printf("%+v", err)
}
}输出
some unexpected error happened main.Do D:/WorkSpace/Code/GoLeran/golearn/main.go:9 main.main D:/WorkSpace/Code/GoLeran/golearn/main.go:13 runtime.main D:/WorkSpace/Library/go/root/go1.21.3/src/runtime/proc.go:267 runtime.goexit D:/WorkSpace/Library/go/root/go1.21.3/src/runtime/asm_amd64.s:1650
通过格式化输出,就可以看到堆栈信息了,默认情况下是不会输出堆栈的。这个包相当于是标准库errors包的加强版,同样都是官方写的,不知道为什么没有并入标准库。
实例
Go
package main
import (
"fmt"
)
// 定义一个 DivideError 结构
type DivideError struct {
dividee int
divider int
}
// 实现 `error` 接口
func (de *DivideError) Error() string {
strFormat := `
Cannot proceed, the divider is zero.
dividee: %d
divider: 0
`
return fmt.Sprintf(strFormat, de.dividee)
}
// 定义 `int` 类型除法运算的函数
func Divide(varDividee int, varDivider int) (result int, errorMsg string) {
if varDivider == 0 {
dData := DivideError{
dividee: varDividee,
divider: varDivider,
}
errorMsg = dData.Error()
return
} else {
return varDividee / varDivider, ""
}
}
func main() {
// 正常情况
if result, errorMsg := Divide(100, 10); errorMsg == "" {
fmt.Println("100/10 = ", result)
}
// 当除数为零的时候会返回错误信息
if _, errorMsg := Divide(100, 0); errorMsg != "" {
fmt.Println("errorMsg is: ", errorMsg)
}
}执行以上程序,输出结果为:
100/10 = 10 errorMsg is: Cannot proceed, the divider is zero. dividee: 100 divider: 0
panic
panic中文译为恐慌,表示十分严重的程序问题,程序需要立即停止来处理该问题,否则程序立即停止运行并输出堆栈信息,panic是Go是运行时异常的表达形式,通常在一些危险操作中会出现,主要是为了及时止损,从而避免造成更加严重的后果。不过panic在退出之前会做好程序的善后工作,同时panic也可以被恢复来保证程序继续运行。
下方是一个向nil的map写入值的例子,肯定会触发panic
func main() { var dic map[string]int dic["a"] = 'a' } panic: assignment to entry in nil map
提示
只要任一协程发生panic,如果不将其捕获的话,整个程序都会崩溃
创建
显式的创建panic十分简单,使用内置函数panic即可,函数签名如下
func panic(v any)
panic函数接收一个类型为any的参数v,当输出错误堆栈信息时,v也会被输出。使用例子如下
func main() { initDataBase("", 0) } func initDataBase(host string, port int) { if len(host) == 0 || port == 0 { panic("非法的数据链接参数") } // ...其他的逻辑 }
当初始化数据库连接失败时,程序就不应该启动,因为没有数据库程序就运行的毫无意义,所以此处应该抛出panic
panic: 非法的数据链接参数善后
程序因为panic退出之前会做一些善后工作,例如执行defer语句。
func main() { defer fmt.Println("A") defer fmt.Println("B") fmt.Println("C") panic("panic") defer fmt.Println("D") }
输出为
C B A panic: panic
并且上游函数的defer语句同样会执行,例子如下
func main() { defer fmt.Println("A") defer fmt.Println("B") fmt.Println("C") dangerOp() defer fmt.Println("D") } func dangerOp() { defer fmt.Println(1) defer fmt.Println(2) panic("panic") defer fmt.Println(3) }
输出
C 2 1 B A panic: panic
defer中也可以嵌套panic,下面是一个比较复杂的例子
func main() { defer fmt.Println("A") defer func() { func() { panic("panicA") defer fmt.Println("E") }() }() fmt.Println("C") dangerOp() defer fmt.Println("D") } func dangerOp() { defer fmt.Println(1) defer fmt.Println(2) panic("panicB") defer fmt.Println(3) }
defer中嵌套的panic执行顺序依旧一致,发生panic时后续的逻辑将无法执行。
C 2 1 A panic: panicB panic: panicA
综上所述,当发生panic时,会立即退出所在函数,并且执行当前函数的善后工作,例如defer,然后层层上抛,上游函数同样的也进行善后工作,直到程序停止运行。
当子协程发生panic时,不会触发当前协程的善后工作,如果直到子协程退出都没有恢复panic,那么程序将会直接停止运行。
var waitGroup sync.WaitGroup func main() { demo() } func demo() { waitGroup.Add(1) defer func() { fmt.Println("A") }() fmt.Println("C") go dangerOp() waitGroup.Wait() // 父协程阻塞等待子协程执行完毕 defer fmt.Println("D") } func dangerOp() { defer fmt.Println(1) defer fmt.Println(2) panic("panicB") defer fmt.Println(3) waitGroup.Done() }
输出为
C 2 1 panic: panicB
可以看到demo()中的defer语句一个都没有执行,程序就直接退出了。需要注意的是,如果没有waitGroup来阻塞父协程的话,demo()的执行速度可能会快于子协程的执行速度,输出的结果就会变得非常有迷惑性,下面稍微修改一下代码
func main() { demo() } func demo() { defer func() { // 父协程善后工作要花费20ms time.Sleep(time.Millisecond * 20) fmt.Println("A") }() fmt.Println("C") go dangerOp() defer fmt.Println("D") } func dangerOp() { // 子协程要执行一些逻辑,要花费1ms time.Sleep(time.Millisecond) defer fmt.Println(1) defer fmt.Println(2) panic("panicB") defer fmt.Println(3) }
输出为
C D 2 1 panic: panicB
在本例中,当子协程发生panic时,父协程早已完成的函数的执行,进入了善后工作,在执行最后一个defer时,碰巧遇到了子协程发生panic,所以程序就直接退出运行。
恢复
标准公式如下:
defer func() { if r := recover(); r != nil { if err, ok := r.(string); ok { fmt.Println("捕获到错误:", err) } else { fmt.Println("捕获到未知错误:", r) } } }()
当发生panic时,使用内置函数recover()可以及时的处理并且保证程序继续运行,必须要在defer语句中运行,使用示例如下。
func main() { dangerOp() fmt.Println("程序正常退出") } func dangerOp() { defer func() { if err := recover(); err != nil { fmt.Println(err) fmt.Println("panic恢复") } }() panic("发生panic") }
调用者完全不知道dangerOp()函数内部发生了panic,程序执行剩下的逻辑后正常退出,所以输出如下
发生panic panic恢复 程序正常退出
但事实上recover()的使用有许多隐含的陷阱。例如在defer中再次闭包使用recover。
func main() { dangerOp() fmt.Println("程序正常退出") } func dangerOp() { defer func() { func() { if err := recover(); err != nil { fmt.Println(err) fmt.Println("panic恢复") } }() }() panic("发生panic") }
闭包函数可以看作调用了一个函数,panic是向上传递而不是向下,自然闭包函数也就无法恢复panic,所以输出如下。
panic: 发生panic 除此之外,还有一种很极端的情况,那就是panic()的参数是nil。
func main() { dangerOp() fmt.Println("程序正常退出") } func dangerOp() { defer func() { if err := recover(); err != nil { fmt.Println(err) fmt.Println("panic恢复") } }() panic(nil) }
这种情况panic确实会恢复,但是不会输出任何的错误信息。
输出
程序正常退出
总的来说recover函数有几个注意点
-
必须在
defer中使用 -
多次使用也只会有一个能恢复
panic -
闭包
recover不会恢复外部函数的任何panic -
panic的参数禁止使用nil
fatal
fatal是一种极其严重的问题,当发生fatal时,程序需要立刻停止运行,不会执行任何善后工作,通常情况下是调用os包下的Exit函数退出程序,如下所示
func main() { dangerOp("") } func dangerOp(str string) { if len(str) == 0 { fmt.Println("fatal") os.Exit(1) } fmt.Println("正常逻辑") }
输出
fatal
fatal级别的问题一般很少会显式的去触发,大多数情况都是被动触发。