文章目录
说明
- 文章属于个人学习笔记内容,仅供学习和交流。
- 内容参考深度学习原理与实践》陈仲铭版和个人学习经历和收获而来。
基础知识
人工智能、机器学习、深度学习的关系
- 人工智能的问题基本上分为6个方向:问题求解、知识推理、规划问题、不确定性推理、通信感知与行动、学习问题。
- 机器学习主要有 3 个方向:分类、回归、关联性分析 。

- 深度学习的定义是:具有两层以上的神经网络。
-
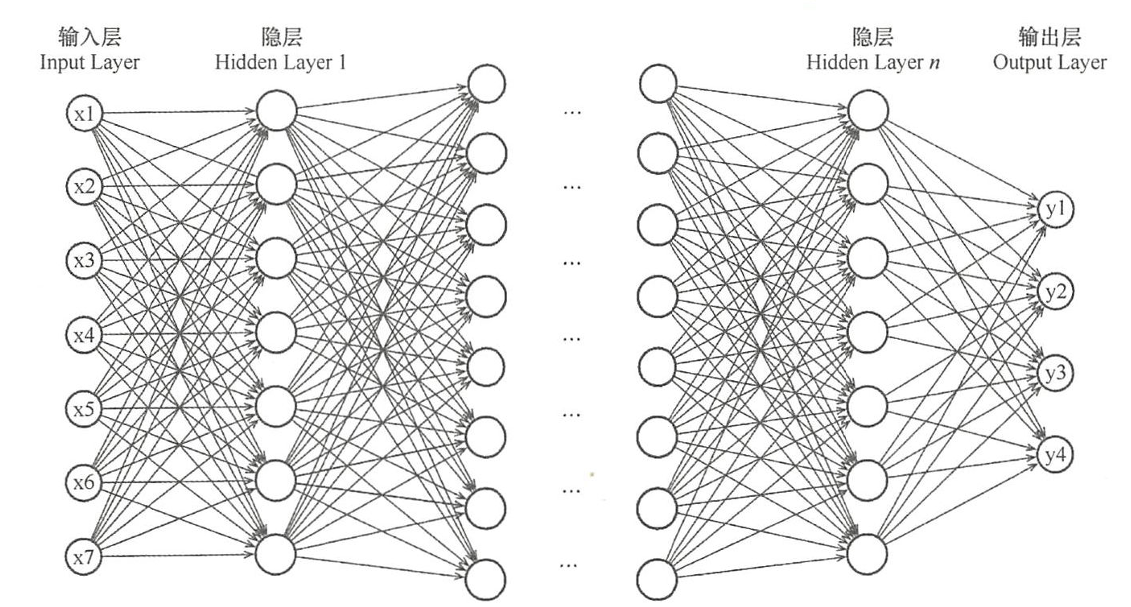
深度神经网络其实是深度学习的基础,深度学习的应用和技术绝大部分都是基于深度神经网络框架。
-
神经网络的特点:具有更多的神经元;具有更复杂的网络连接方式;拥有惊人的计算量;能够自动提取数据高维特征。
-
深度网络主要是指具有深层的神经网络,包括:人工神经网络(ANN)、卷积神经网络(CNN)、循环神经网络(RNN)。
机器学习
- 机器学习按照方法主要可以分为两大类:监督学习和无监督学习。其中监督学习主要由分类和回归等问题组成,深度学习则属于监督学习当中的一种;无监督学习主要由聚类和关联分析等问题组成。
- 机器学习中的监督学习是指使用算法对有标注的数据进行解析,从数据中学习特定的结构模型,使用模型来对未知的新数据进行预测。通俗来说,监督学习就是通过对数据进行分析,找到数据的表达模型,然后套用该模型来做决策。
- 监督学习的一般方法主要分为训练和预测阶段 。
- 在训练阶段(对数据进行分析的阶段),根据原始的数据进行特征提取【特征工程】。得到特征后,使用决策树、随机森林等模型算法去分析数据之间的特征或者关系,最终得到关于输入数据的模型(Model)。
- 在预测阶段,同样提取数据后,使用训练阶段获得的模型对特征向量进行预测,得到最终的标签(Labels)。
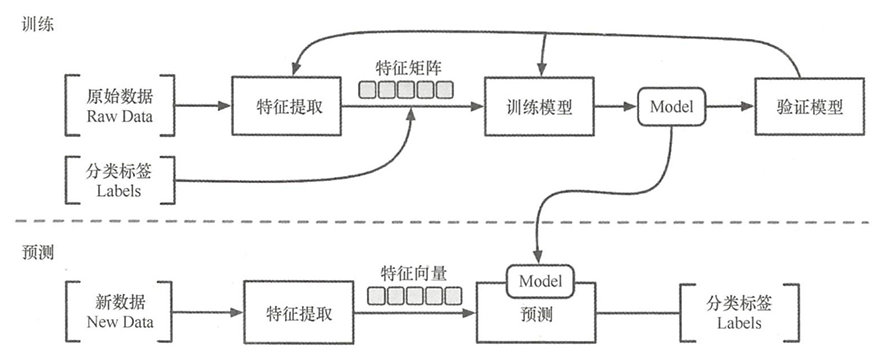
- 机器学习算法中不同的模型使用自己特定的规则去解释输入的数据,然后对新输入的数据进行预测和判断。例如决策树的模型,是构建一个树形结构,一个节点代表一种数据类型,一个叶子节点则代表一种类别;线性回归模型利用线性回归方程创建一组参数来表示输入的数据之间的关系;神经网络则有一组权重参数向量来代表节点之间的关系。
传统机器学习的缺陷
- 在实际情况中,如果输入的数据受到影响导致特征数据变化,传统机器学习的算法的有效性就会降低,如当遇到雨雪天气时,马路一旁的标志牌变模糊,抑或标志牌被树木遮挡时,标志牌的特征也会改变。
选择深度学习的原因
- 深度学习自动筛选数据,自动提取数据高维特征。选择深度学习,一方面它节省时间,降低工作量,提高工作效率;另一方面是深度学习的效果,在众多领域能够获得比人类预测的更好的效果:此外,深度学习还可以与大数据无缝结合,输入庞大的数据集进行大数据端到端的学习过程,这种大道至简 的理念吸引着无数的研究者。
深度学习的关键问题
- 深度学习开发的关键问题:
- 深度网络模型需要输入的数据类型?
- 深度网络模型需要提取的数据内容?
- 深度网络模型的选择?
- 使用模型后预期的结果?
- 第一个问题,数据类型可以是图片、文挡、语音,根据具体的任务需求确定。
- 第二个问题,明确要从模型中提取数据体类型后,就可以更加清晰地定义网络模型的损失函数。
- 第三个问题,落实到神经网络的实现中,例如卷积神经网络 CNN 中大概用的网络层数,循环神经网络 RNN 中应该定义的循环层数和时间步等。
- 第四个问题,更加有利于把深度学习的算法与模型结合到工程项目当中,真正帮助我们解决实际问题。
深度学习的应用
- 图像处理:Mask R-CNN对图像进行目标检测和图形语义分割。

- 高精度地图:通过使用深度学习的感知算法对激光雷达和摄像头采集到的路面信息进行融合,制作成高精度地图。

- 机器人:深度学习技术的突破使得机器人的复杂感知变为可能。
- 医疗健康诊断:利用深度学习技术对细胞影像图进行分剖,检查病变细胞
深度学习的加速硬件GPU
-
硬件加速器是深度学习应用的核心要素,能够获得巨大的计算性能提升。
-
GPU 作为硬件加速器之一, 通过大量图形处理单元与 CPU协同工作,对深度学习、数据分析,以及大量计算的工程应用进行加速。
-
统一计算设备架构(Compute Unified Device Architecture, CUDA)。随着 GPU 的发展, GPU 开始主要为显示图像做优化,在计算上超越通用的 CPU。 NVIDIA 推出 CUDA这一通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
-
GPU 是大规模并行架构,擅长处理并行任务。GPU 的并行架构非常合适深度学习需要高效的矩阵操作和大量的卷积操作。
-
GPU的特性:高宽带;高速缓存性能;并行单元多。
-
用 GPU来进行深度学习,在 L 1 L1 L1高速缓存中和 G P U GPU GPU的寄存器上存储大量的数据,反复使用卷积操作和矩阵乘法操作,而不用担心运算应度慢的问题。 假设有一个 100 M B 100MB 100MB的矩阵,根据寄存器的数量和高速缓存的大小把该矩阵分解成多个如 3 × 3 3×3 3×3的小矩阵,然后以 10 − 80 T B / s 10-80TB/s 10−80TB/s的速度与一个三通道的 3 × 3 3×3 3×3的小矩阵相乘完成一次卷积操作。
-
对于深度学习的加速器GPU,初学者推荐使用 NVIDIA显卡。英伟达公司押注人工智能与深度学习,GPU资源充分。CUDA平台来说,其社区完善,很多开源解决方案为后续编程。
环境搭建
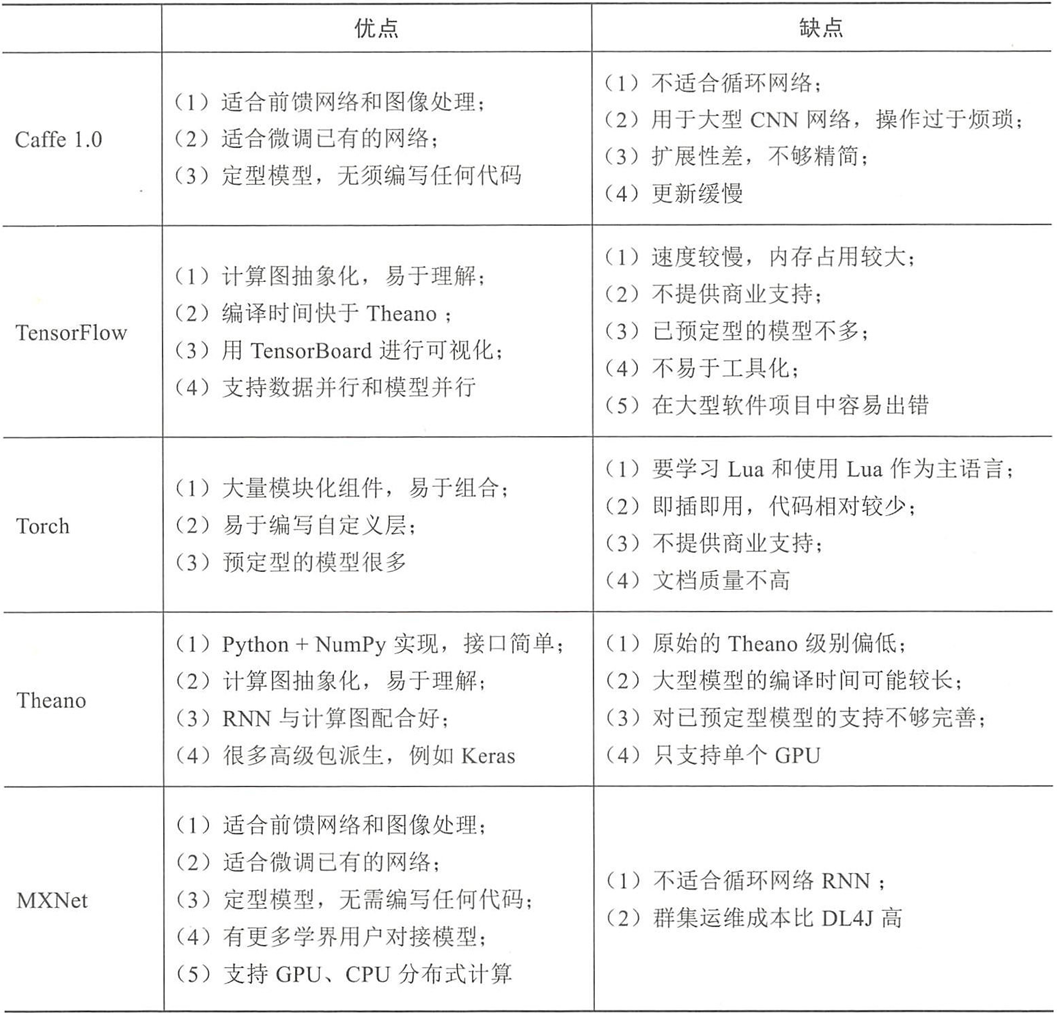
主流深度学习框架对比
- 五大主流深度学习框架优缺点对比表