hadoop客户端环境准备
找到资料包路径下的Windows依赖文件夹,拷贝hadoop-3.1.0到非中文路径(比如d:\hadoop-3.1.0)
++①++打开环境变量
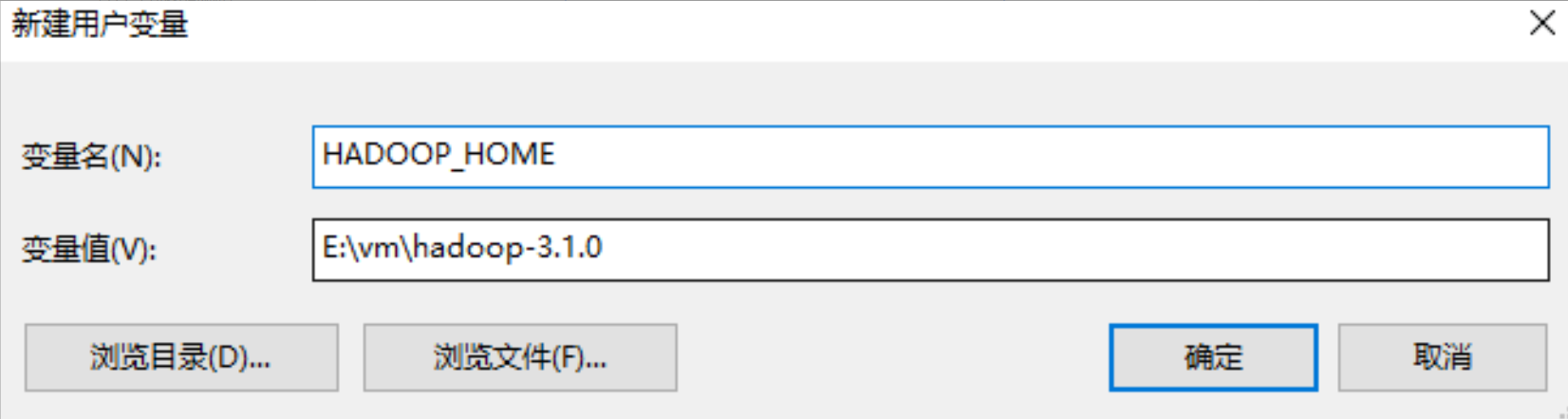
++②++在下方系统变量中新建HADOOP_HOME环境变量,值就是保存hadoop的目录。
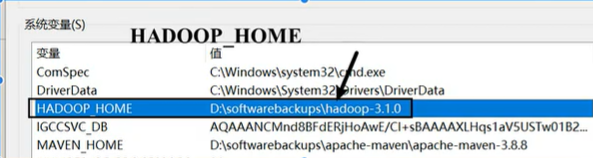
效果如下:
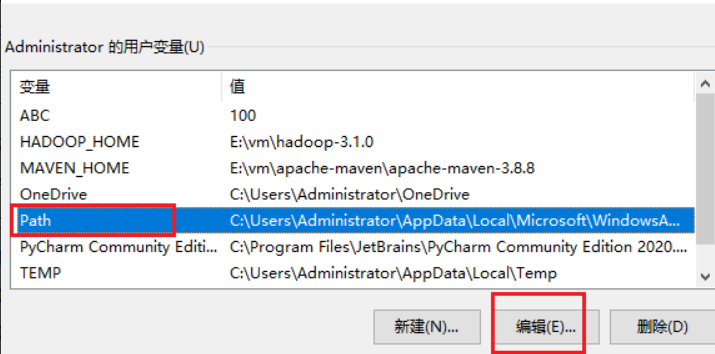
++③++配置Path环境变量。
++④++新建一项
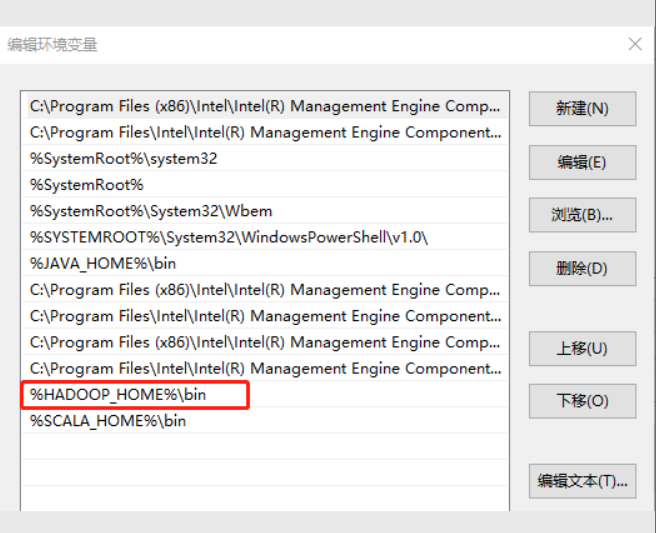
++⑤++打开电脑终端验证Hadoop环境变量是否正常

Maven的配置同上
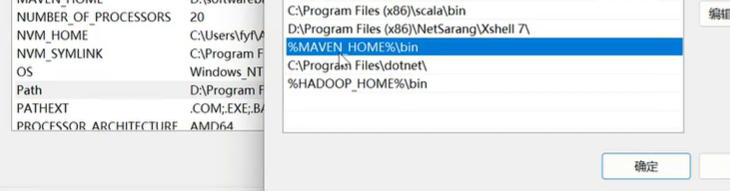

hadoop客户端环境准备
找到资料包路径下的Windows依赖文件夹,拷贝hadoop-3.1.0到非中文路径(比如d:\hadoop-3.1.0)
++①++打开环境变量
++②++在下方系统变量中新建HADOOP_HOME环境变量,值就是保存hadoop的目录。
效果如下:
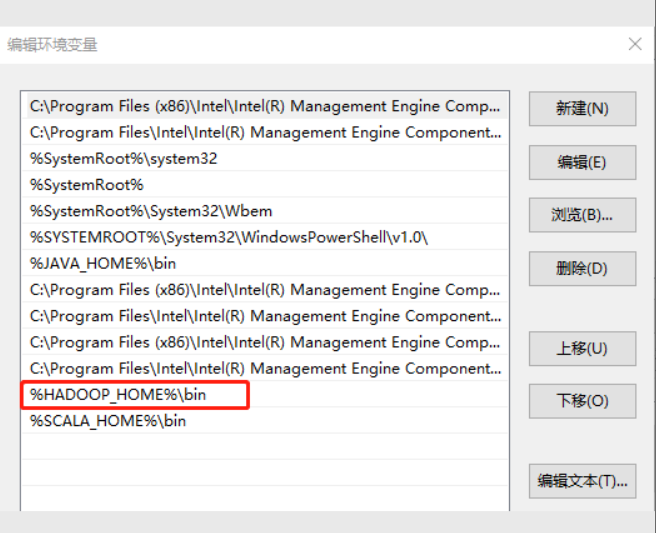
++③++配置Path环境变量。
++④++新建一项
++⑤++打开电脑终端验证Hadoop环境变量是否正常
Maven的配置同上