1 问题域
业务发展的初期,我们的数据库架构往往是单库单表,外加读写分离来快速的支撑业务,随着用户量和订单量的增加,数据库的计算和存储往往会成为我们系统的瓶颈,业界的实践多数采用分而治之的思想:分库分表,通过分库分表应对存系统读写性能瓶颈和存储瓶颈;分库分表帮我们解决问题的同时,也带来了复杂性;比如多条件的分页查询,多条件的联表查询变得复杂起来,通过调研我们发现针对这些分页,联表的复杂查询,业界常用的解决方案有以下两种:1 构建ES宽表 ,2 构建查询条件到表主键Mapping映射表;本表文章介绍我们的实践:基于公司的中间件DTS构建实时性的ES宽表。所谓的宽表是通过主键将多张表关联成一张表,比如订单维度的宽表字段包含:订单主表,订单明细表,商品表,用户表等表字段。
2 ES宽表构建解决方案域
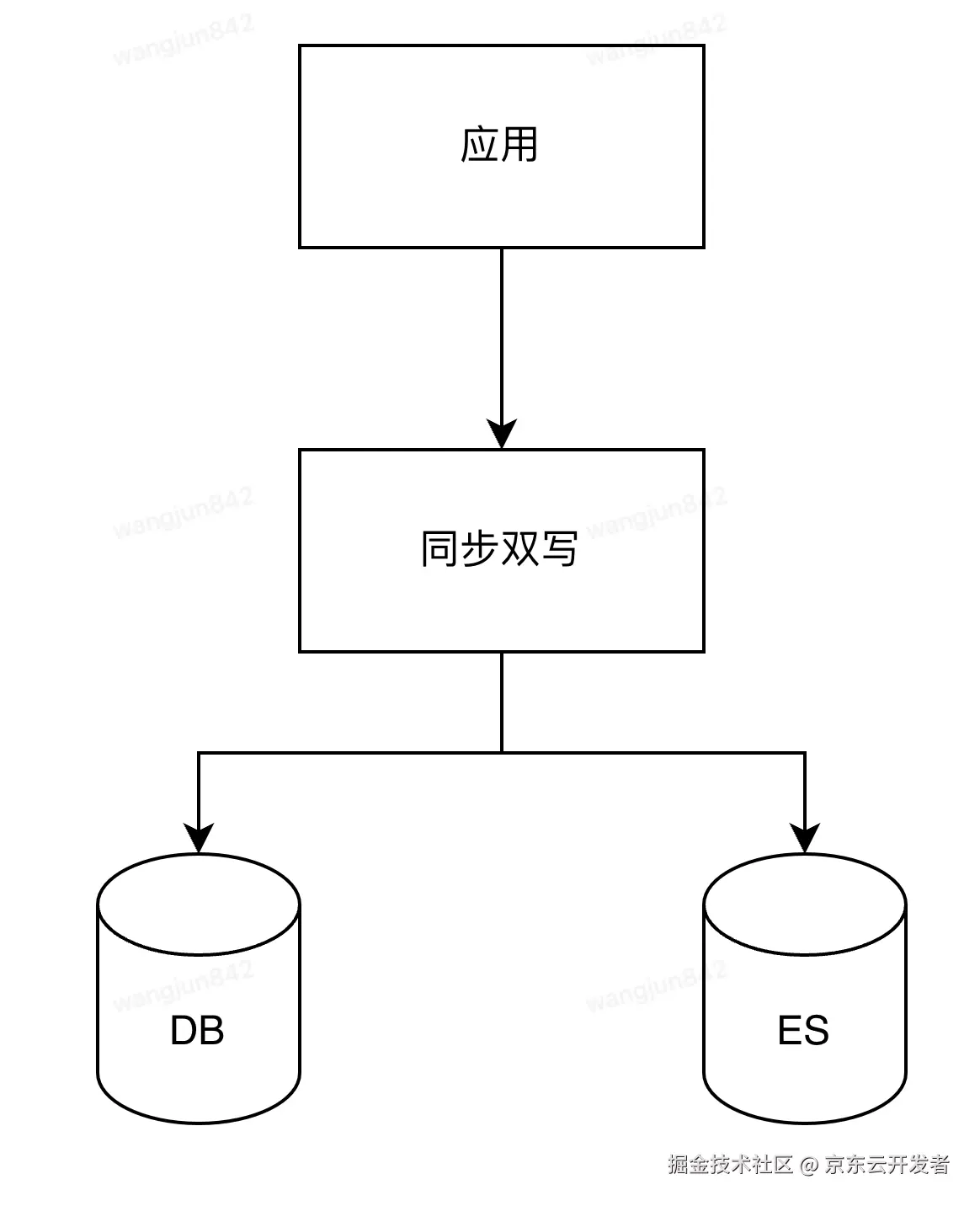
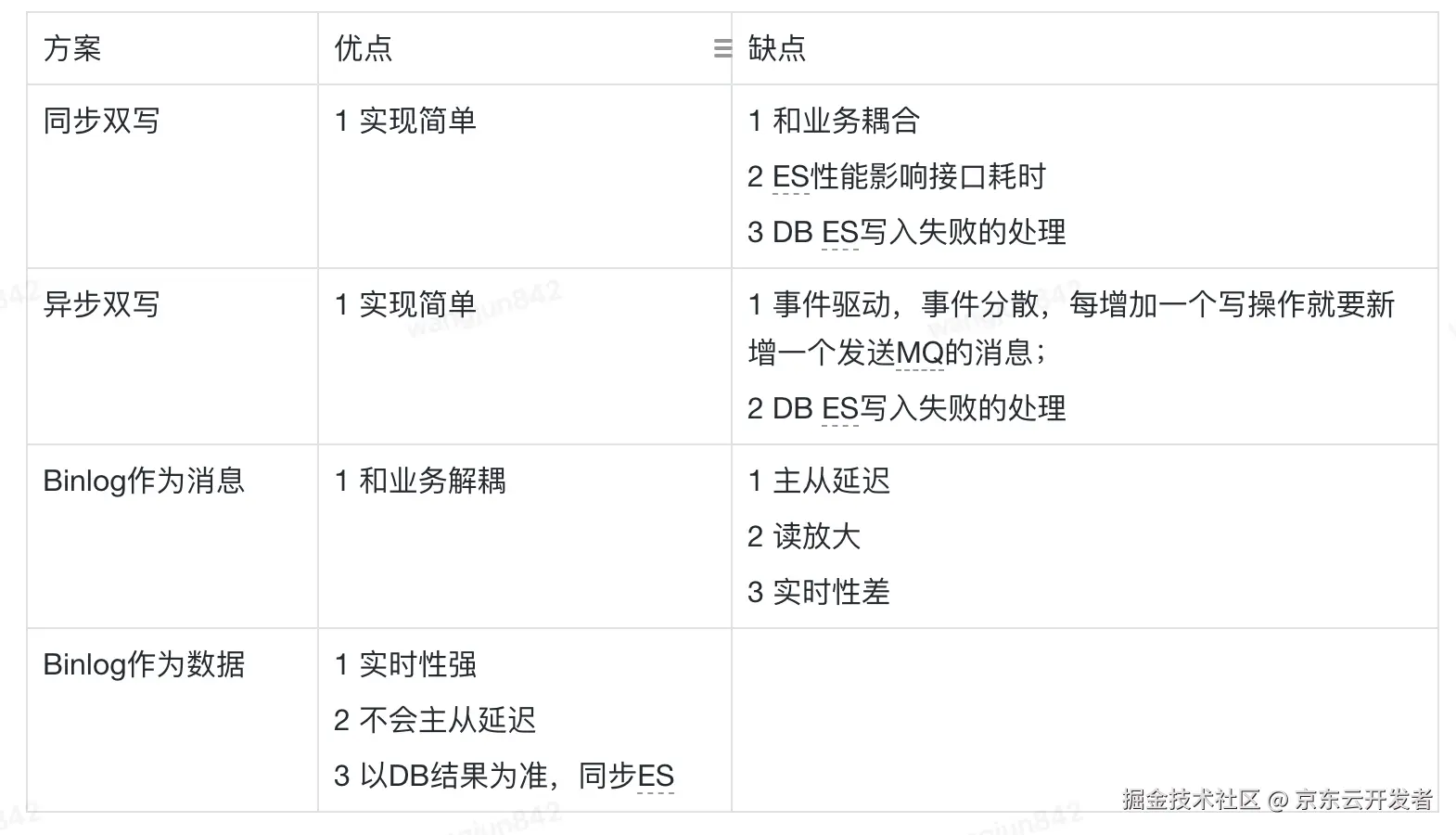
2.1 同步双写
应用在接收到写请求后,同步写DB成功,然后再同步写ES。
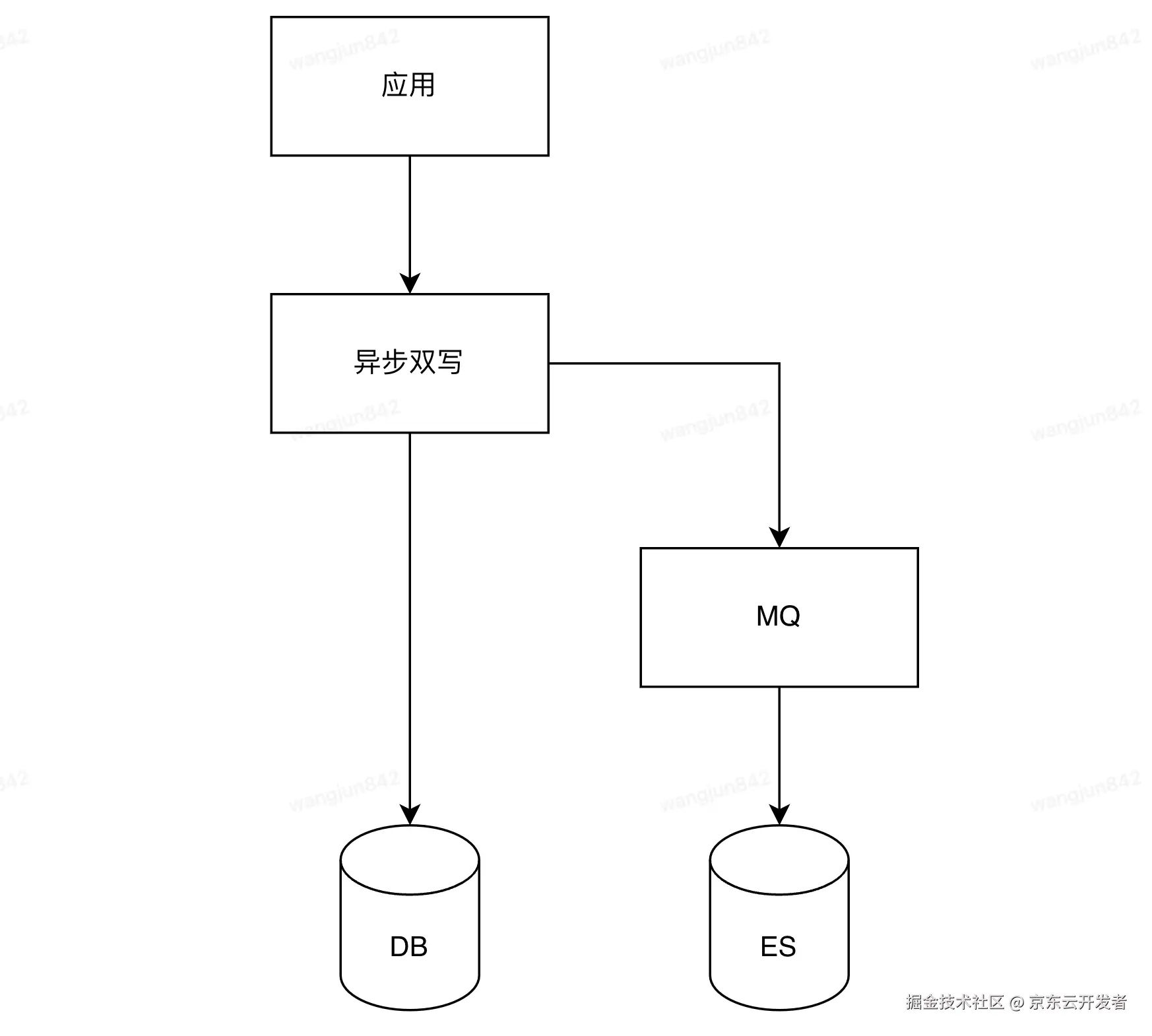
2.2 异步双写
应用在接收到写请求后,同步写DB成功,异步发送MQ,消费MQ异步写ES。
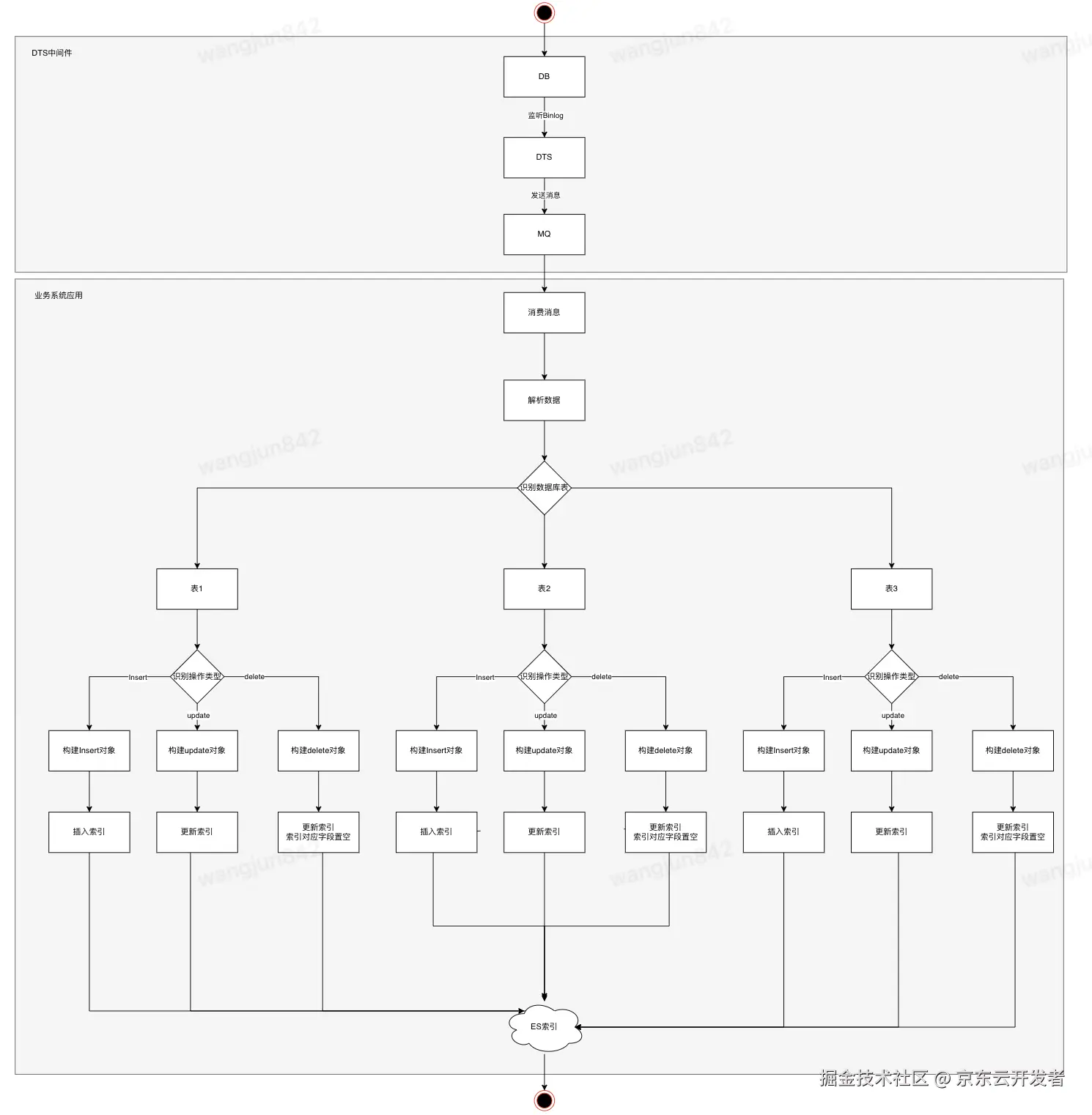
2.3 基于Binlog的实时同步
2.3.1 Binlog作为消息
将Binlog作为消息,或者驱动的Event,接收到消息后,RPC调取下游的业务系统,获取业务数据进行数组的组装,写入ES。
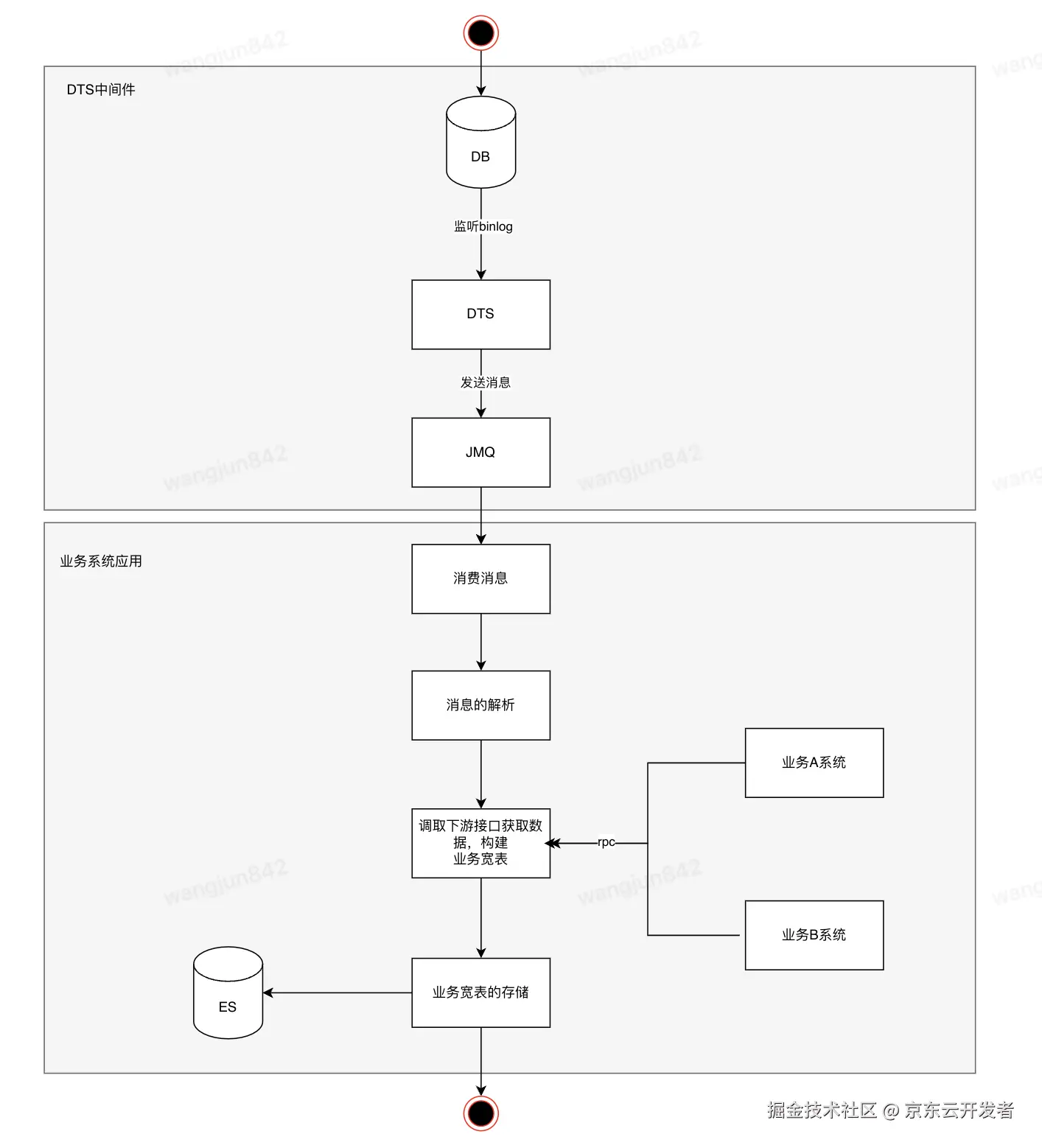
2.3.2 Binlog作为数据
解析Binlog中的数据,获取库表,字段变更前后的内容,INSERT, UPDATE, DELETE事件,基于Binlog中的数据去构建宽表,写入ES。
3 解决方案优缺点对比
4 我们的实践
4.1 Binlog作为数据构建ES宽表
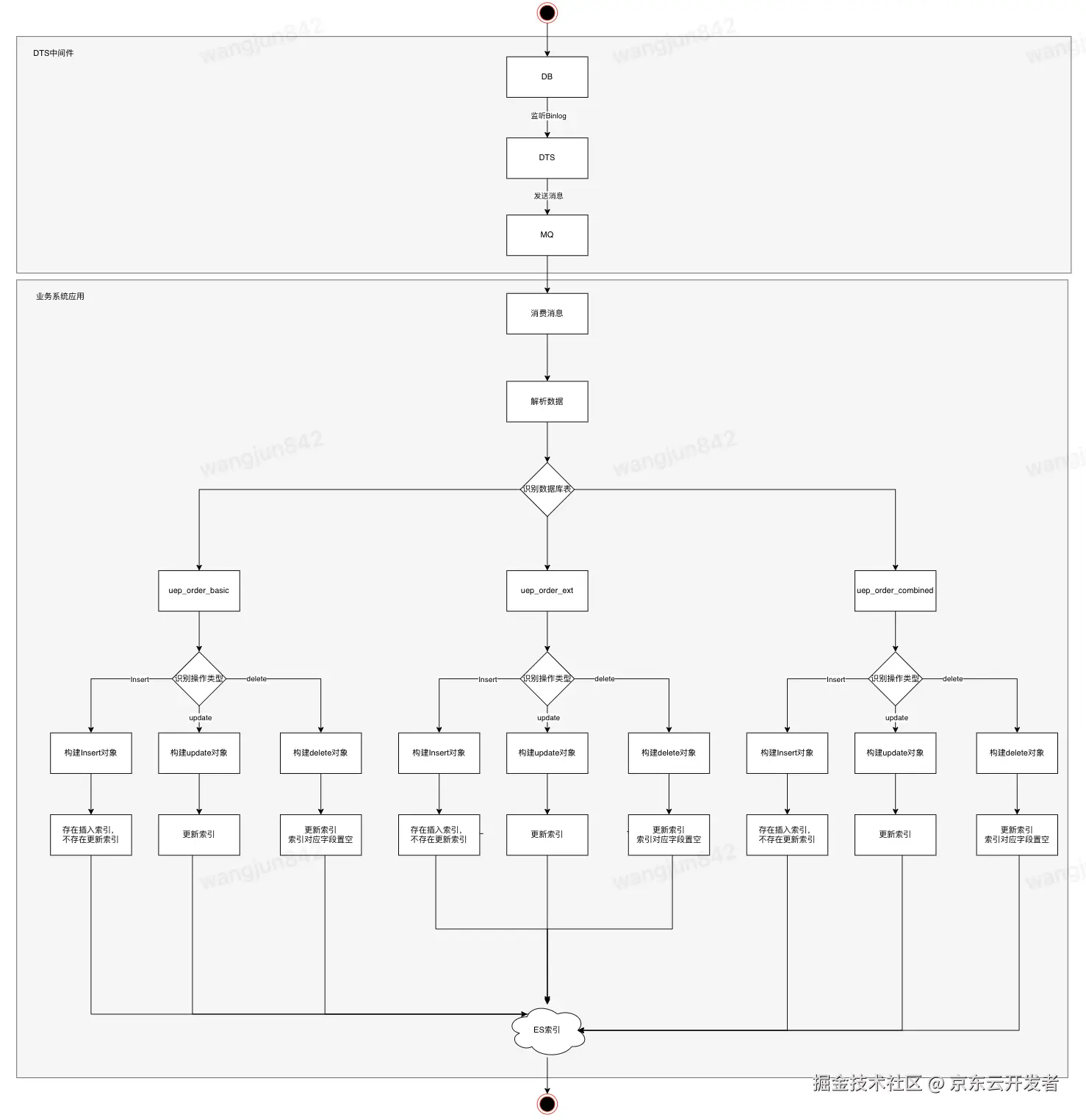
4.1.1 顺序性的保证
上游DTS监听的binlog是有序的;发送消息时,业务方可以配置业务主键例如uep_order_no,DTS可以根据业务主键进行hash,将该条消息发送到对应的队列保证局部有序性;消费者消费时,同一个订单号uep_order_no映射到同一个分区,保证顺序消费;
4.1.2 幂等性的保证
DTS可以保证消息不丢失,但不保证消息不重复,可能发送重复的消息需要业务方保证幂等性,
UPDATE/DELETE操作天然具有幂等性
INSERT操作在进行操作前需要先判断下数据是否存在,不存在则插入,存在则更新
4.1.3 数据一致性的保证
由于数据存储在Mysql和ES两种存储媒介,可以采用定时任务对账机制保证数据的一致性,如果数据不一致采用补偿任务进行补偿操作
4.1.4 存量数据迁移
采用定时任务分页将数据从Mysql迁移到ES
4.2 ES复杂检索
4.2.1 检索的分类
多条件的复杂查询,采用Bool查询;
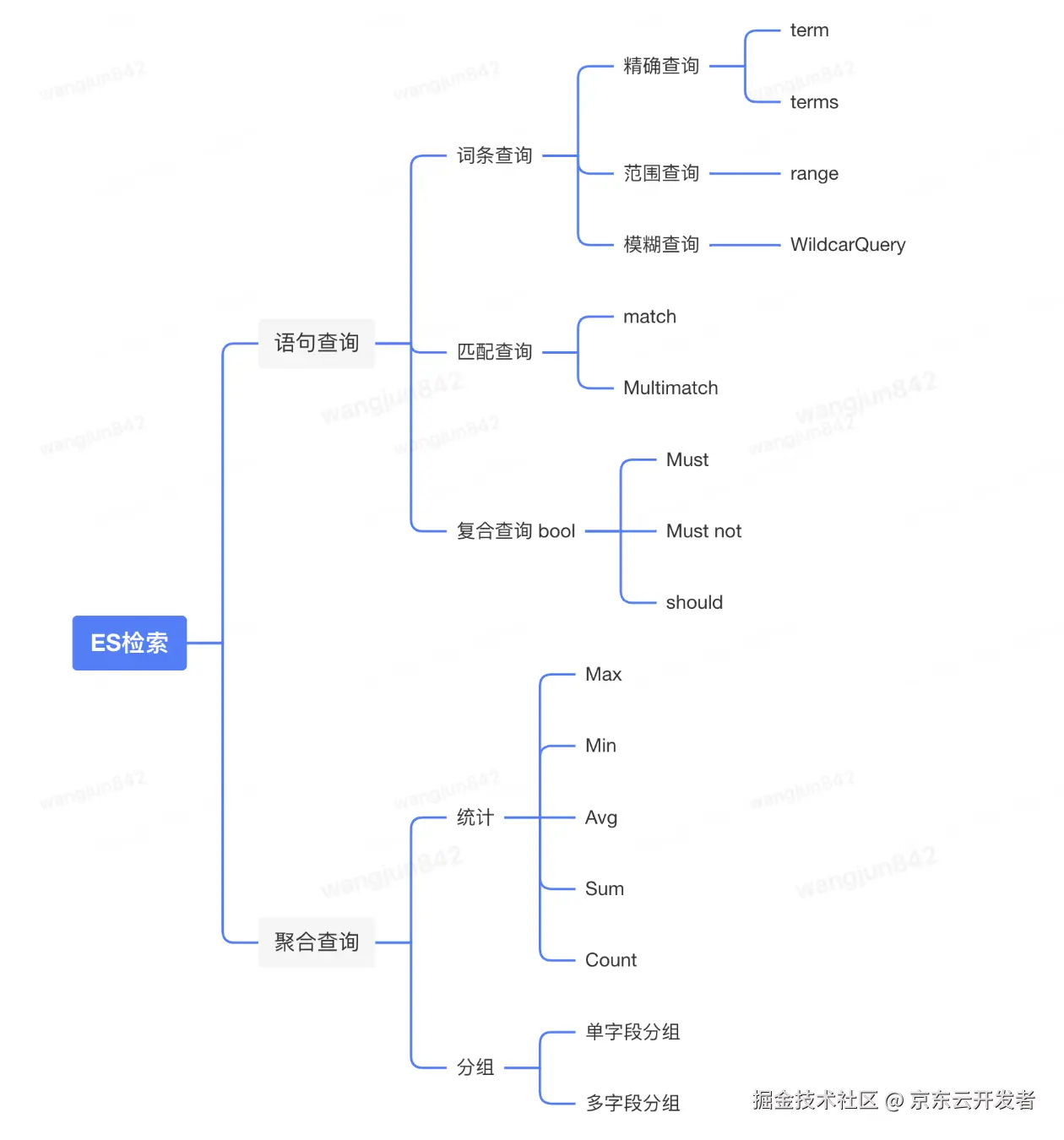
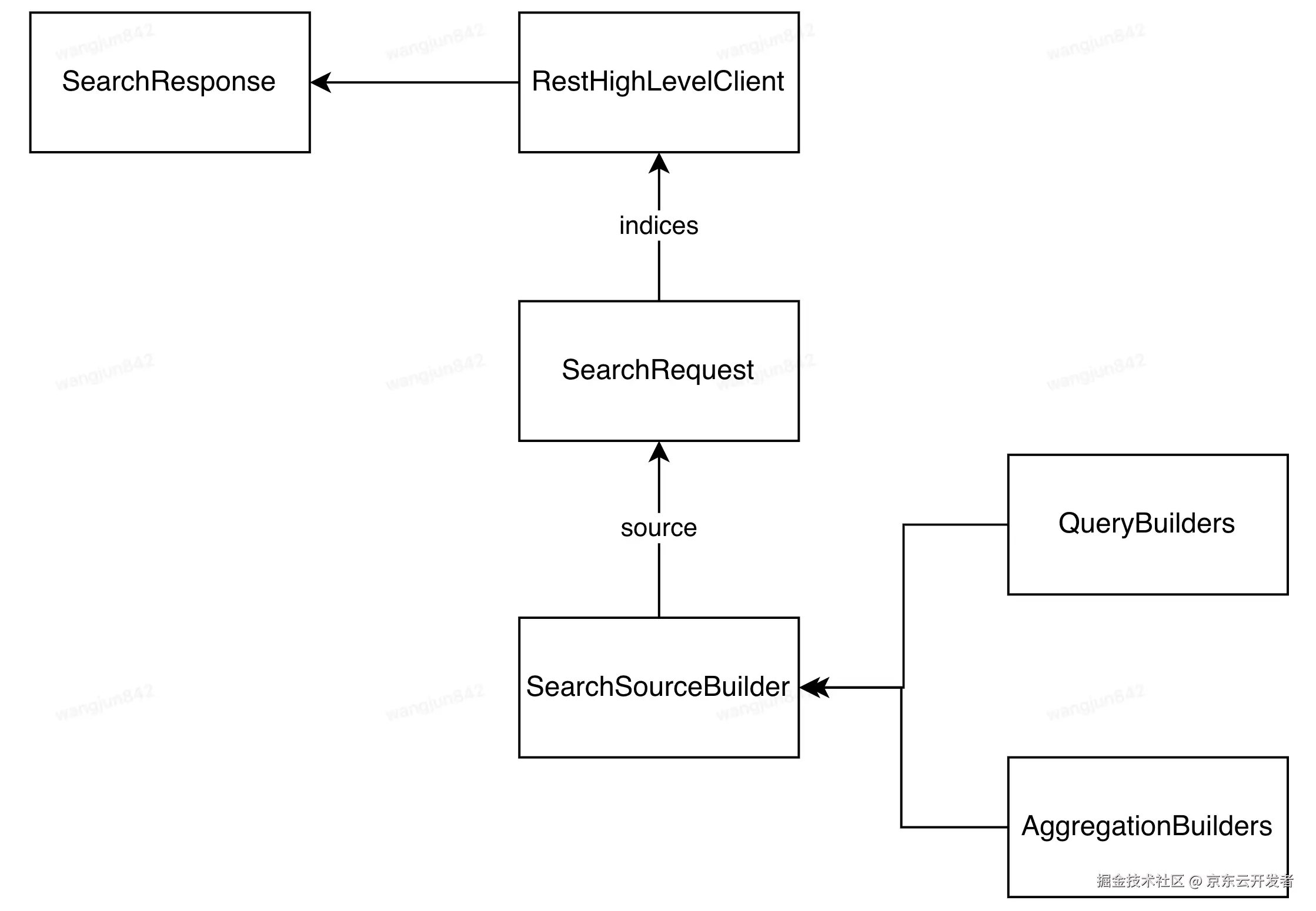
4.2.2 查询条件构建