一直想要学习一下对比学习,这里正好有机会学习整理一下,方便以后查阅。
相关博客链接:监督(Supervised)、半监督(Semi-Supervised)、无监督(Unsupervised)、自监督(Self-Supervised)学习
对比学习(Contrastive Learning)
- [Contrastive Learning](#Contrastive Learning)
-
- [1. 什么是对比学习](#1. 什么是对比学习)
- [2. 工作流程](#2. 工作流程)
- [3. 损失函数](#3. 损失函数)
- [4. 发展历程](#4. 发展历程)
-
- [4.1 早期工作(2000s-2010s)](#4.1 早期工作(2000s-2010s))
- [4.2 计算机视觉中的突破(2018-2020)](#4.2 计算机视觉中的突破(2018-2020))
- [4.3 无负样本对比学习(2020-2021)](#4.3 无负样本对比学习(2020-2021))
- [4.4 多模态与跨领域扩展(2021-至今)](#4.4 多模态与跨领域扩展(2021-至今))
- [4.5 理论与优化(2022-至今)](#4.5 理论与优化(2022-至今))
- [5. 主要方法对比](#5. 主要方法对比)
- [6. 应用](#6. 应用)
- [7. 优势 and 缺点](#7. 优势 and 缺点)
-
- [7.1 优势](#7.1 优势)
- [7.2 缺点](#7.2 缺点)
- [8. 未来趋势](#8. 未来趋势)
- 对比学习在有监督分类任务上的应用(InfoNCE+Cross-Entropy)
- 参考资料
Contrastive Learning
1. 什么是对比学习
对比学习(Contrastive Learning)是一种自监督学习方法。

对比学习在深度学习中的位置
通过对比正样本(相似数据)和负样本(不相似数据),学习数据的高质量表示。它在无需标注数据的情况下,利用数据的内在结构(如图像的空间一致性、文本的语义关联),生成监督信号,广泛应用于计算机视觉、自然语言处理和多模态任务。
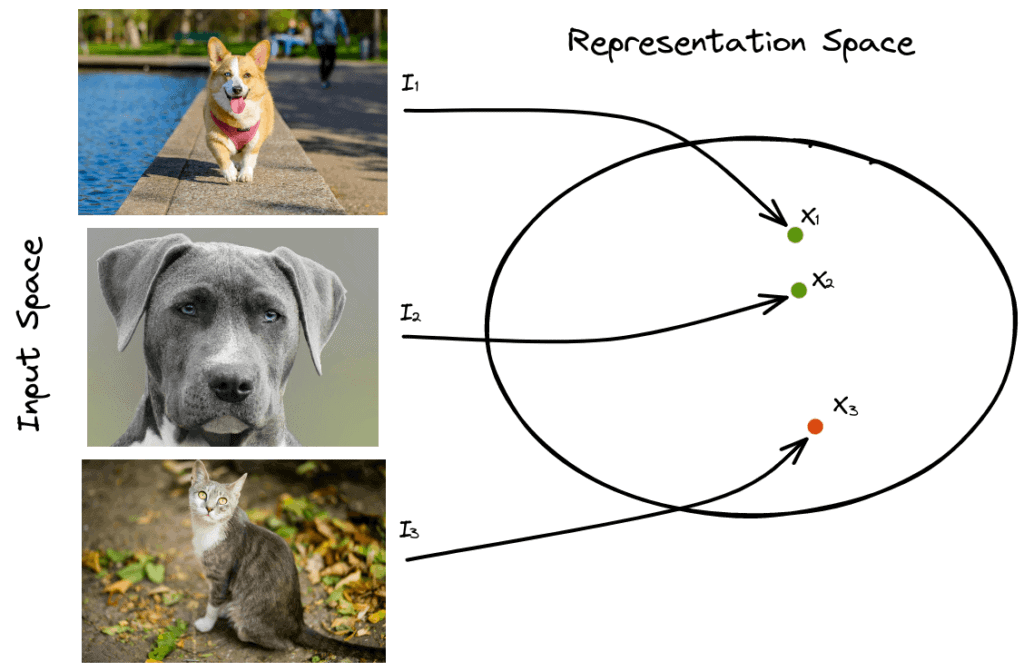
对比学习原理示意
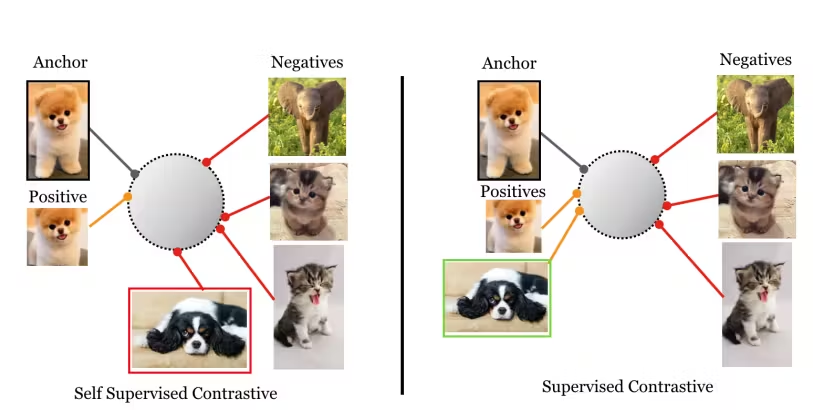
有监督对比学习原理示意
2. 工作流程
对比学习的工作流程通常包括以下步骤:
- 数据增强:对输入数据(如图像)应用随机增强(如随机裁剪、翻转、颜色抖动),生成正样本对。例如,同一图像的两个增强视图被视为正样本,其他图像的视图为负样本。
- 特征提取:使用神经网络(如卷积神经网络CNN或Transformer)将输入数据映射到特征空间,生成特征向量。
- 对比损失优化:计算正样本和负样本的相似度,优化InfoNCE损失或其他对比损失(如Cosine Loss)。
- 下游任务微调:使用预训练的特征表示,微调模型以适配特定任务。

3. 损失函数
损失函数是对比学习的核心,定义了如何衡量正样本和负样本的相似性。以下是主要损失函数的技术细节:
-
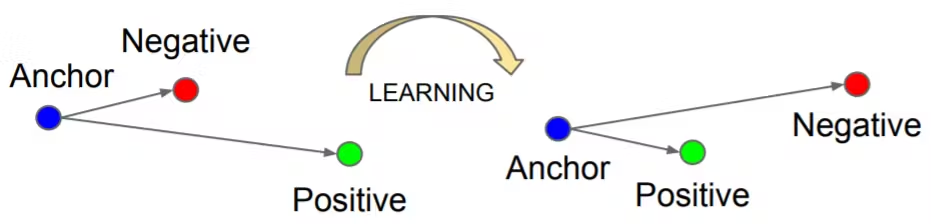
对比损失(Contrastive Loss) :
最早用于深度度量学习,目标是使同类样本的嵌入距离最小化,不同类样本的嵌入距离最大化。公式为:
L = 1 2 N ∑ i = 1 N ( y i d i 2 + ( 1 − y i ) max ( m a r g i n − d i , 0 ) 2 ) L = \frac{1}{2N} \sum_{i=1}^{N} \left( y_i d_i^2 + (1 - y_i) \max(margin - d_i, 0)^2 \right) L=2N1i=1∑N(yidi2+(1−yi)max(margin−di,0)2)其中, N N N是样本对数, y i = 0 y_i=0 yi=0表示相似, y i = 1 y_i=1 yi=1表示不相似, d i d_i di是嵌入之间的距离, m a r g i n margin margin是超参数,定义不相似样本的最小距离。
来源:Learning a Similarity Metric Discriminatively, with Application to Face Verification。
-
Triplet损失(Triplet Loss) :
由FaceNet提出,使用一个锚点(anchor)、一个正样本(positive)和一个负样本(negative),确保锚点与正样本的距离小于锚点与负样本的距离,公式为:
L = ∑ x ∈ X max ( 0 , ∥ f ( x ) − f ( x + ) ∥ 2 2 − ∥ f ( x ) − f ( x − ) ∥ 2 2 + ϵ ) L = \sum_{\mathbf{x} \in \mathcal{X}} \max(0, \|f(\mathbf{x}) - f(\mathbf{x}^+)\|^2_2 - \|f(\mathbf{x}) - f(\mathbf{x}^-)\|^2_2 + \epsilon) L=x∈X∑max(0,∥f(x)−f(x+)∥22−∥f(x)−f(x−)∥22+ϵ)其中, ϵ \epsilon ϵ是边距参数,选择具有挑战性的负样本至关重要。
来源:FaceNet: A Unified Embedding for Face Recognition and Clustering。
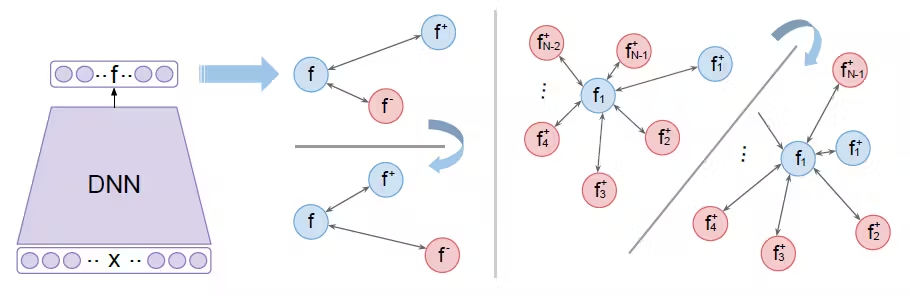
- N-pair损失(N-pair Loss) :
推广Triplet损失,包含一个正样本和 N − 1 N-1 N−1个负样本,公式为:
L = log ( 1 + ∑ i = 1 N − 1 exp ( f ( x ) ⊤ f ( x i − ) − f ( x ) ⊤ f ( x + ) ) ) L = \log(1 + \sum_{i=1}^{N-1} \exp(f(\mathbf{x})^\top f(\mathbf{x}^-_i) - f(\mathbf{x})^\top f(\mathbf{x}^+))) L=log(1+i=1∑N−1exp(f(x)⊤f(xi−)−f(x)⊤f(x+)))
等价于使用一个负样本的softmax损失,提高效率。
来源:Improved Deep Metric Learning with Multi-class N-pair Loss Objective。
- InfoNCE损失(NT-Xent) :
用于SimCLR,最大化不同增强视图之间的协议,公式为:
L = − 1 N ∑ i = 1 N log exp ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N 1 k ≠ i exp ( s i m ( z i , z k ) / τ ) L = - \frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(sim(z_i, z_j) / \tau)}{\sum_{k=1}^{2N} \mathbb{1}_{k \\neq i} \exp(sim(z_i, z_k) / \tau)} L=−N1i=1∑Nlog∑k=12N1k=iexp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
其中, s i m ( u , v ) = u ⊤ v ∣ ∣ u ∣ ∣ ∣ ∣ v ∣ ∣ sim(u, v) = \frac{u^\top v}{||u|| ||v||} sim(u,v)=∣∣u∣∣∣∣v∣∣u⊤v是余弦相似度, τ \tau τ是温度参数,批次中的其他样本作为负样本。
来源:A Simple Framework for Contrastive Learning of Visual Representations。
其他损失函数包括:
- Lifted Structured Loss:利用批次中的所有成对边,提高效率,挖掘困难负样本。
- Noise Contrastive Estimation (NCE):通过逻辑回归区分目标和噪声,扩展到多个负样本。
- Soft-Nearest Neighbors Loss:扩展到多个正样本,使用温度(\tau)调整特征集中度。
以下是关键损失函数和技术参数的对比:
| 损失函数 | 公式 | 关键参数 | 应用场景 |
|---|---|---|---|
| 对比损失 | L = 1 2 N ∑ i = 1 N ( y i d i 2 + ( 1 − y i ) max ( m a r g i n − d i , 0 ) 2 ) L = \frac{1}{2N} \sum_{i=1}^{N} \left( y_i d_i^2 + (1 - y_i) \max(margin - d_i, 0)^2 \right) L=2N1∑i=1N(yidi2+(1−yi)max(margin−di,0)2) | m a r g i n margin margin | 早期度量学习 |
| Triplet损失 | L = ∑ x ∈ X max ( 0 , ∣ f ( x ) − f ( x + ) ∣ 2 2 − ∣ f ( x ) − f ( x − ) ∣ 2 2 + ϵ ) L = \sum_{\mathbf{x} \in \mathcal{X}} \max(0, |f(\mathbf{x}) - f(\mathbf{x}^+)|^2_2 - |f(\mathbf{x}) - f(\mathbf{x}^-)|^2_2 + \epsilon) L=∑x∈Xmax(0,∣f(x)−f(x+)∣22−∣f(x)−f(x−)∣22+ϵ) | ϵ \epsilon ϵ | 人脸识别 |
| N-pair损失 | L = log ( 1 + ∑ i = 1 N − 1 exp ( f ( x ) ⊤ f ( x i − ) − f ( x ) ⊤ f ( x + ) ) ) L = \log(1 + \sum_{i=1}^{N-1} \exp(f(\mathbf{x})^\top f(\mathbf{x}^-_i) - f(\mathbf{x})^\top f(\mathbf{x}^+))) L=log(1+∑i=1N−1exp(f(x)⊤f(xi−)−f(x)⊤f(x+))) | N − 1 N-1 N−1负样本 | 高效多负样本对比 |
| InfoNCE(NT-Xent) | L = − 1 N ∑ i = 1 N log exp ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N 1 k ≠ i exp ( s i m ( z i , z k ) / τ ) L = - \frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(sim(z_i, z_j) / \tau)}{\sum_{k=1}^{2N} \mathbb{1}_{k \\neq i} \exp(sim(z_i, z_k) / \tau)} L=−N1∑i=1Nlog∑k=12N1k=iexp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ) | τ \tau τ温度参数 | SimCLR, 大批量训练 |
4. 发展历程
对比学习的发展经历了从早期理论到现代高效方法的演变,以下按时间线详细阐述:
4.1 早期工作(2000s-2010s)
- 理论基础:对比学习的根源可以追溯到噪声对比估计(Noise-Contrastive Estimation, NCE)和负采样(Negative Sampling),最初用于语言模型(如Word2Vec)。这些方法通过对比目标词与上下文词(正样本)和其他随机词(负样本),学习词向量。
- 代表工作 :
- Word2Vec (2013):Mikolov等提出的Word2Vec通过负采样学习词嵌入,奠定了对比学习在NLP中的基础。
- Deep InfoMax (2018):Hjelm等提出通过最大化全局和局部特征的互信息,学习图像表示,扩展对比学习到视觉领域。
4.2 计算机视觉中的突破(2018-2020)
- 背景:监督学习(如ImageNet预训练)依赖昂贵的标注数据,促使研究者探索自监督方法。对比学习在视觉领域爆发,受益于深度网络(如ResNet、ViT)和数据增强技术。
- 代表工作 :
- CPC (Contrastive Predictive Coding, 2018):Oord等提出,通过预测序列中未来部分的表示,学习图像和语音的特征,引入时间序列对比任务。
- MoCo (Momentum Contrast, 2019):He等提出动量编码器(Momentum Encoder)和队列机制,存储大量负样本,解决大批量训练的内存限制,在ImageNet上取得显著成果。
- SimCLR (Simple Framework for Contrastive Learning, 2020):Chen等简化对比学习框架,强调强数据增强(如随机裁剪、颜色变换)和大批量训练,证明数据增强是关键因素,在ImageNet上达到接近监督学习的性能。
- MoCo v2 (2020):Chen等结合SimCLR的改进(如投影头、增强策略),进一步提升MoCo性能。
4.3 无负样本对比学习(2020-2021)
- 背景:传统对比学习依赖大量负样本,计算和存储成本高。新方法探索避免负样本,聚焦正样本之间的关系,降低计算复杂性。
- 代表工作 :
- BYOL (Bootstrap Your Own Latent, 2020):Grill等提出不使用负样本,通过两个网络(在线网络和目标网络)自举学习,目标网络通过动量更新,稳定训练过程。
- SimSiam (2021):Chen等进一步简化BYOL,去除动量编码器,直接优化正样本对的相似性,证明对比学习无需负样本也能学习有效表示。
- SwAV (Swapping Assignments between Views, 2020):Caron等结合聚类和对比学习,通过在线聚类分配伪标签,增强表示一致性。
4.4 多模态与跨领域扩展(2021-至今)
- 背景:对比学习扩展到多模态(如图像-文本、视频-音频)和非视觉领域(如NLP、图数据)。大规模数据集(如WebImageText、LAION)和Transformer架构推动了性能提升。
- 代表工作 :
- CLIP (Contrastive Language-Image Pretraining, 2021):Radford等使用图像-文本对进行对比学习,学习跨模态表示,在零样本分类、图像检索等任务中表现出色。
- ALIGN (2021):Jia等类似CLIP,强调大规模噪声数据的高效利用。
- Video Contrastive Learning:方法如VideoMoCo、CVRL扩展对比学习到视频领域,利用时序信息。
4.5 理论与优化(2022-至今)
- 理论进展:研究者分析对比学习的收敛性、表示崩塌问题(Representation Collapse)以及正负样本的作用,提出正则化方法(如Spectral Contrastive Loss)防止表示退化。
- 优化方法:蒸馏技术(如DINO)结合对比学习和自监督蒸馏;数据高效方法(如iBOT)结合掩码建模和对比学习。
- 大规模应用:对比学习成为视觉基础模型(如DINOv2、EVA-CLIP)的重要组成部分。
5. 主要方法对比
以下表格总结了主要对比学习方法的对比:
| 方法 | 年份 | 核心创新 | 正样本生成 | 负样本 | 损失函数 | 适用场景 |
|---|---|---|---|---|---|---|
| CPC | 2018 | 预测序列未来表示 | 时序上下文 | 有 | InfoNCE | 图像、语音 |
| MoCo | 2019 | 动量编码器+负样本队列 | 数据增强视图 | 有 | InfoNCE | 图像分类、检测 |
| SimCLR | 2020 | 强数据增强+大批量训练 | 数据增强视图 | 有 | InfoNCE | 图像分类、检测 |
| BYOL | 2020 | 无负样本,自举学习 | 数据增强视图 | 无 | MSE(预测误差) | 图像分类 |
| SimSiam | 2021 | 无负样本,简化BYOL | 数据增强视图 | 无 | Cosine Loss | 图像分类 |
| SwAV | 2020 | 在线聚类+对比学习 | 数据增强视图+伪标签 | 有 | Sinkhorn | 图像分类、检测 |
| CLIP | 2021 | 图像-文本跨模态对比 | 图像-文本对 | 有 | InfoNCE | 多模态任务 |
| DINO | 2021 | 自监督蒸馏+对比学习 | 数据增强视图 | 无 | Cross-Entropy | 图像分类、分割 |
6. 应用
对比学习生成的表示广泛应用于:
- 计算机视觉:图像分类(如ImageNet)、目标检测(如COCO)、语义分割(如ADE20K)、图像检索和生成。
- 多模态任务:图像-文本检索(如CLIP)、视觉问答(VQA)、图像标注。
- 视频处理:动作识别(如Kinetics)、视频分类和检索。
- 自然语言处理:句嵌入(如Sentence-BERT)、文本分类和匹配。
- 图数据:图节点分类、图表示学习(如GraphCL)。
7. 优势 and 缺点
7.1 优势
- 无需标注:利用无标注数据,降低数据准备成本。
- 通用性:学习的表示适用于多种下游任务。
- 高效性:相较监督学习,预训练阶段更灵活,微调成本低。
- 鲁棒性:数据增强和对比机制使表示对噪声和变换鲁棒。
- 多模态支持:跨模态对比学习(如CLIP)扩展了应用场景。
7.2 缺点
- 计算成本高:大批量训练(如SimCLR)或负样本队列(如MoCo)需要大量内存和算力。
- 负样本依赖:传统方法需要大量负样本,可能引入噪声或不相关信息。
- 表示崩塌:若正负样本设计不当,特征可能退化为常数(需正则化或无负样本方法)。
- 数据增强依赖:性能高度依赖增强策略,需针对任务精心设计。
- 领域迁移性:在特定领域(如医学影像)可能需要重新设计增强或正样本策略。
8. 未来趋势
- 无负样本方法:进一步探索BYOL、SimSiam等无负样本框架,降低计算复杂性。
- 多模态融合:结合图像、文本、音频、视频等多模态数据,构建统一表示。
- 数据高效学习:针对小规模或特定领域数据优化对比学习。
- 理论深入:分析对比学习的收敛性、表示质量和泛化能力。
- 与生成模型结合:结合MAE、扩散模型等生成式自监督方法,提升表示的语义性。
- 高效部署:通过蒸馏、量化等技术,降低模型规模和推理成本。
对比学习在有监督分类任务上的应用(InfoNCE+Cross-Entropy)
可以通过联合 InfoNCE 和交叉熵损失(Cross-Entropy Loss)来训练一个分类模型。这种方法结合了对比学习的优势(学习鲁棒的特征表示)和交叉熵损失的分类能力,能够提升模型的性能,尤其在有标签的数据集上。联合损失的训练方式通常是将 InfoNCE 损失(用于增强类内紧凑性和类间分离性)与交叉熵损失(用于直接优化分类性能)进行加权组合。
相关论文
以下是一些与联合 InfoNCE 和交叉熵损失相关的代表性论文,提供了理论依据和实验验证:
-
"Supervised Contrastive Learning" (Khosla et al., 2020)
- 链接 : arXiv:2004.11362
- 贡献: 提出了 Supervised Contrastive Loss(SupCon),利用标签信息构造正负样本对,并展示了 SupCon 损失与交叉熵损失联合训练的优越性。论文中明确提到可以通过加权组合 SupCon 损失和交叉熵损失来优化分类模型。
- 相关内容: 论文实验表明,SupCon 损失在预训练阶段学习到更鲁棒的特征表示,结合交叉熵损失微调后,分类性能显著提升。
-
"Decoupled Contrastive Learning" (Yeh et al., 2021)
- 链接 : arXiv:2110.06848
- 贡献: 提出了一种改进的对比学习框架,探讨了如何在有监督场景中结合对比损失和分类损失。论文中提到联合训练可以缓解对比学习中的表示坍塌问题。
-
"A Simple Framework for Contrastive Learning of Visual Representations" (Chen et al., 2020, SimCLR)
- 链接 : arXiv:2002.05709
- 贡献: 虽然主要聚焦无监督对比学习,但 SimCLR 的 InfoNCE 损失被广泛扩展到有监督场景。许多后续工作(如 SupCon)基于 InfoNCE 提出联合训练策略。
-
"Combining Contrastive and Supervised Learning for Visual Representation Learning" (Various works)
- 多篇后续论文探讨了如何在有监督场景中结合 InfoNCE 和交叉熵损失。例如,CLIP(Radford et al., 2021, arXiv:2103.00020)的跨模态对比学习也启发了有监督联合训练的研究。
这些论文提供了联合 InfoNCE 和交叉熵损失的理论支持,SupCon 论文是最直接相关的参考。
代码示例
以下是一个基于 PyTorch 的代码示例,展示如何在 CIFAR-10 数据集上使用联合 InfoNCE(Supervised Contrastive Loss)和交叉熵损失训练一个分类模型。代码包括数据增强、模型架构、联合损失函数和两阶段训练(联合训练 + 微调)。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import numpy as np
# 超参数
batch_size = 256
embedding_dim = 128
epochs = 10
temperature = 0.1
learning_rate = 0.001
supcon_weight = 1.0 # SupCon 损失的权重
ce_weight = 1.0 # 交叉熵损失的权重
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1. 数据增强
def get_transforms():
transform = transforms.Compose([
transforms.RandomResizedCrop(size=32, scale=(0.2, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
return transform
# 2. 模型架构(编码器 + 投影头 + 分类头)
class JointModel(nn.Module):
def __init__(self, base_encoder, projection_dim=128, num_classes=10):
super(JointModel, self).__init__()
self.encoder = base_encoder
# 投影头:用于对比学习
self.projector = nn.Sequential(
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, projection_dim)
)
# 分类头:用于交叉熵损失
self.classifier = nn.Linear(512, num_classes)
def forward(self, x):
# 提取特征
h = self.encoder(x)
# 投影到对比学习空间
z = self.projector(h)
# 分类输出
logits = self.classifier(h)
return h, z, logits
# 3. Supervised Contrastive Loss (InfoNCE-based)
def supcon_loss(features, labels, temperature):
"""
features: [batch_size, projection_dim]
labels: [batch_size]
"""
batch_size = features.shape[0]
# 归一化特征
features = F.normalize(features, dim=1)
# 计算相似度矩阵
similarity_matrix = torch.matmul(features, features.T) / temperature
# 创建标签掩码:同一类的样本为正样本
labels = labels.contiguous().view(-1, 1)
mask = torch.eq(labels, labels.T).float().to(device)
# 去除自比较
mask_self = torch.eye(batch_size, dtype=torch.bool).to(device)
mask = mask.masked_fill(mask_self, 0)
# 计算正样本和负样本的相似度
exp_sim = torch.exp(similarity_matrix) * (1 - mask_self.float())
pos_sum = torch.sum(exp_sim * mask, dim=1, keepdim=True)
neg_sum = torch.sum(exp_sim * (1 - mask), dim=1, keepdim=True)
# 避免除零
pos_sum = torch.clamp(pos_sum, min=1e-9)
neg_sum = torch.clamp(neg_sum, min=1e-9)
# 计算损失
loss = -torch.log(pos_sum / (pos_sum + neg_sum))
loss = loss.mean()
return loss
# 4. 联合训练函数
def train_joint(model, train_loader, optimizer, epochs):
model.train()
ce_criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
total_loss = 0
total_supcon_loss = 0
total_ce_loss = 0
for batch_idx, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
# 前向传播
h, z, logits = model(images)
# 计算 SupCon 损失
supcon_loss_val = supcon_loss(z, labels, temperature)
# 计算交叉熵损失
ce_loss_val = ce_criterion(logits, labels)
# 联合损失
loss = supcon_weight * supcon_loss_val + ce_weight * ce_loss_val
# 反向传播
loss.backward()
optimizer.step()
total_loss += loss.item()
total_supcon_loss += supcon_loss_val.item()
total_ce_loss += ce_loss_val.item()
avg_loss = total_loss / len(train_loader)
avg_supcon_loss = total_supcon_loss / len(train_loader)
avg_ce_loss = total_ce_loss / len(train_loader)
print(f"Epoch [{epoch+1}/{epochs}], Total Loss: {avg_loss:.4f}, "
f"SupCon Loss: {avg_supcon_loss:.4f}, CE Loss: {avg_ce_loss:.4f}")
# 5. 测试函数
def test_model(model, test_loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
_, _, logits = model(images)
_, predicted = logits.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
accuracy = 100. * correct / total
return accuracy
# 6. 主函数
def main():
# 数据加载
transform = get_transforms()
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# 模型
base_encoder = torchvision.models.resnet18(pretrained=False)
base_encoder.fc = nn.Identity() # 移除原始全连接层
model = JointModel(base_encoder, projection_dim=embedding_dim, num_classes=10).to(device)
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练
print("Training with Joint SupCon and Cross-Entropy Loss...")
train_joint(model, train_loader, optimizer, epochs)
# 测试
accuracy = test_model(model, test_loader)
print(f"\nTest Accuracy: {accuracy:.2f}%")
if __name__ == "__main__":
main()代码说明
-
数据增强:
- 使用与 SimCLR 和 SupCon 类似的数据增强策略(如随机裁剪、颜色抖动等),增强模型对数据变换的鲁棒性。
- 直接使用原始图像和标签,无需生成两组增强视图(与无监督 SimCLR 不同)。
-
模型架构:
- 使用 ResNet-18 作为基础编码器,移除原始全连接层。
- 添加投影头(两层 MLP),用于计算 SupCon 损失。
- 添加分类头(线性层),用于计算交叉熵损失。
- 模型同时输出编码器特征(
h)、投影特征(z)和分类 logits(logits)。
-
联合损失函数:
- SupCon Loss:基于 InfoNCE 的有监督对比损失,利用标签构造正样本对(同一类)和负样本对(不同类)。
- Cross-Entropy Loss:标准分类损失,直接优化分类性能。
- 联合损失:
loss = supcon_weight * supcon_loss + ce_weight * ce_loss,其中supcon_weight和ce_weight控制两种损失的相对重要性(默认均为 1.0)。
-
训练流程:
- 在每个 batch 中,模型同时计算 SupCon 损失(基于投影特征
z)和交叉熵损失(基于分类 logits)。 - 联合损失用于反向传播,优化整个模型(编码器、投影头和分类头)。
- 每轮输出总损失、SupCon 损失和交叉熵损失,便于监控训练过程。
- 在每个 batch 中,模型同时计算 SupCon 损失(基于投影特征
-
测试:
- 在训练完成后,使用测试集评估分类准确率,仅使用分类头的输出(
logits)。
- 在训练完成后,使用测试集评估分类准确率,仅使用分类头的输出(
关键特点
-
联合训练:
- SupCon 损失增强类内紧凑性和类间分离性,生成鲁棒的特征表示。
- 交叉熵损失直接优化分类边界,提高分类性能。
- 联合训练结合了两者的优势,避免了传统两阶段训练(先对比学习,后微调)的复杂性。
-
灵活性:
- 通过调整
supcon_weight和ce_weight,可以平衡对比学习和分类任务的优先级。例如:- 增大
supcon_weight强调特征学习。 - 增大
ce_weight强调分类性能。
- 增大
- 通过调整
-
性能提升:
- 联合损失通常比单独使用交叉熵损失生成更鲁棒的特征,尤其在数据量较少或类别不平衡时。
参考资料
- 对比学习论文综述【论文精读】
- 全网最易懂:10分钟深入了解对比学习!
- The Beginner's Guide to Contrastive Learning
- Contrastive Representation Learning
- An Introduction to Contrastive Learning
- What's the intuition behind contrastive learning or approach?
- Full Guide to Contrastive Learning
- Contrastive Learning: A Comprehensive Guide
- Contrastive Learning: A Tutorial
- An In-Depth Guide to Contrastive Learning: Techniques, Models, and Applications
- Contrastive Learning
- 求通俗易懂解释下nce loss?
- Noise Contrastive Estimation
- Why Use InfoNCE Loss in Self-supervised Learning
- 损失函数InfoNCE loss和cross entropy loss以及温度系数
- InfoNCE Loss公式及源码理解