Apriori算法是经典的关联规则挖掘算法 ,用于从事务型数据库中发现频繁项集和强关联规则,特别常用于购物篮分析等场景。
🧠 核心思想(Apriori原则)
一个项集是频繁的,前提是它的所有子集也必须是频繁的。
即:"若某项集不频繁,它的超集也一定不频繁"。
这个原则用于大大减少候选项集的数量,提高挖掘效率。
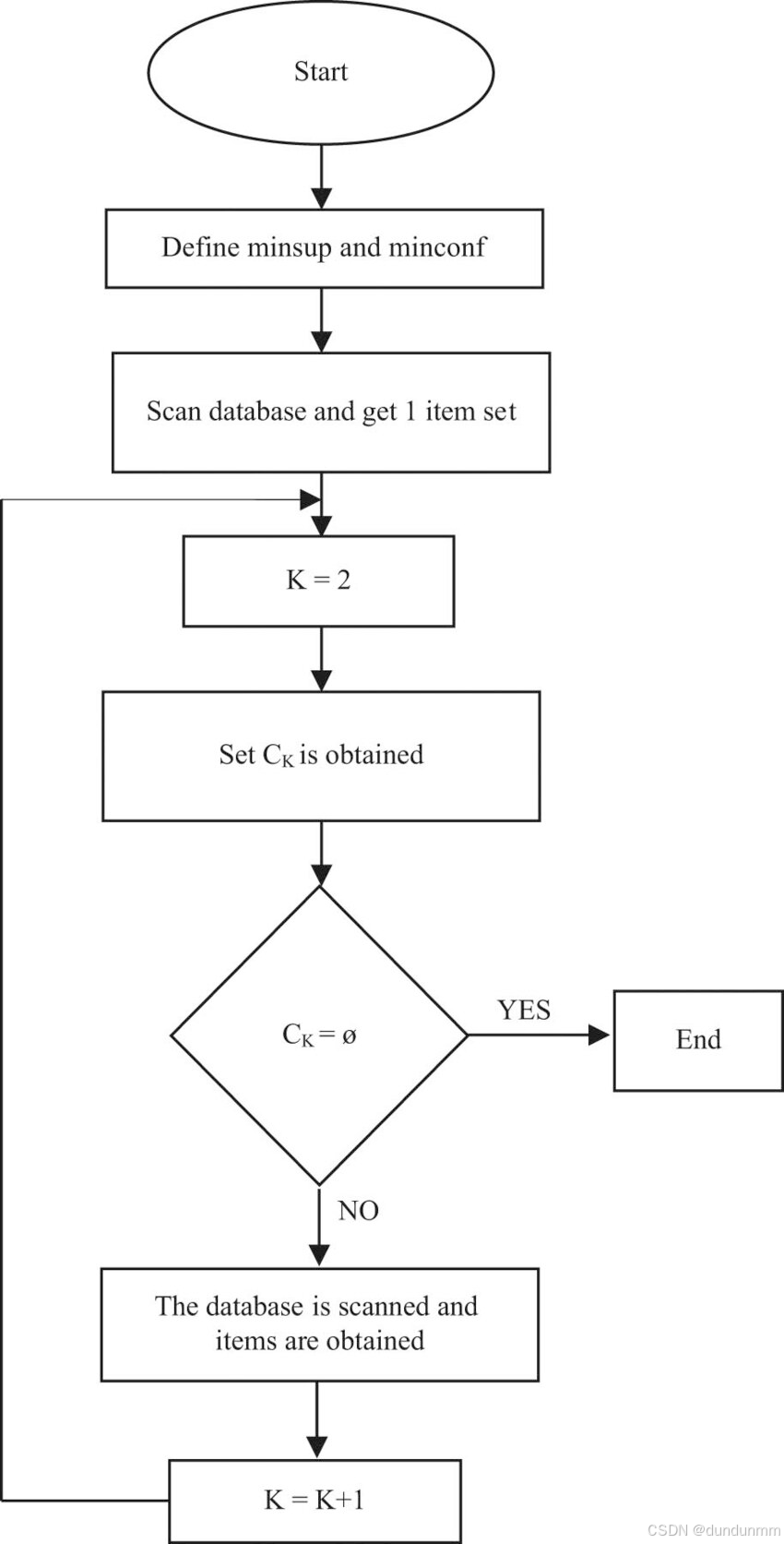
🚶 Apriori算法执行步骤
下面是算法流程(以最小支持度为前提):
① 扫描数据库,找出所有频繁1项集(L1)
-
统计每个单个商品出现的次数
-
丢掉那些支持度小于最小阈值的项
② 生成候选2项集(C2),计算频繁2项集(L2)
-
将L1中的元素两两组合成C2
-
扫描数据库计算这些组合的支持度
-
保留满足最小支持度的组合,得到L2
③ 使用 L2 构造 C3,找出 L3......
- 重复步骤直到没有更多频繁项集为止
④ 基于频繁项集生成关联规则
-
从每个频繁项集中拆分出可能的规则A⇒B
-
计算这些规则的置信度和提升度
-
筛选满足置信度和提升度阈值的规则
✅ 示例(简化版)
事务如下:
| 事务ID | 商品列表 |
|---|---|
| T1 | 牛奶, 面包 |
| T2 | 牛奶, 尿布, 啤酒 |
| T3 | 面包, 尿布, 可乐 |
| T4 | 牛奶, 面包, 尿布 |
| T5 | 面包, 啤酒 |
最小支持度设为 0.4(2次出现)
-
L1:频繁1项集:{牛奶}, {面包}, {尿布}, {啤酒} ✅({可乐}只出现1次,删除)
-
C2(候选2项集):组合上面频繁1项集,比如 {牛奶, 面包}, {尿布, 啤酒} 等
-
L2:选出支持度 ≥0.4 的组合,如 {牛奶, 面包}, {尿布, 啤酒}(若满足)
-
L3:组合L2项集再继续下去......
-
对频繁项集,如 {牛奶, 尿布} 生成关联规则:
- 例如 牛奶 ⇒ 尿布,计算置信度 = 支持(牛奶和尿布) / 支持(牛奶)
📦 应用场景
-
零售行业的购物篮分析
-
推荐系统(推荐某个商品时同时推荐相关联商品)
-
医疗诊断中发现药物组合
-
Web日志分析(用户点击路径)
好的!下面是使用 Python 和 mlxtend 库来实现 Apriori 算法的完整示例。这个库简洁高效,适合教学和实践。
✅ 步骤一:安装依赖(如尚未安装)
pip install mlxtend✅ 步骤二:准备事务数据
我们使用"啤酒与尿布"的经典示例:
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
# 示例数据
dataset = [
['牛奶', '面包'],
['牛奶', '尿布', '啤酒'],
['面包', '尿布', '可乐'],
['牛奶', '面包', '尿布'],
['面包', '啤酒']
]
# 转换为0/1编码的DataFrame
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
print(df)输出:
啤酒 可乐 尿布 牛奶 面包
0 False False False True True
1 True False True True False
2 False True True False True
3 False False True True True
4 True False False False True✅ 步骤三:使用 Apriori 算法找出频繁项集
from mlxtend.frequent_patterns import apriori
# 设定最小支持度为0.4(即至少2次)
frequent_itemsets = apriori(df, min_support=0.4, use_colnames=True)
print(frequent_itemsets)输出示例:
support itemsets
0 0.6 {面包}
1 0.6 {尿布}
2 0.6 {牛奶}
3 0.4 {啤酒}
4 0.4 {牛奶, 面包}
5 0.4 {牛奶, 尿布}
6 0.4 {尿布, 面包}✅ 步骤四:生成关联规则
from mlxtend.frequent_patterns import association_rules
# 使用置信度最小值筛选规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.6)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])输出示例:
antecedents consequents support confidence lift
0 {牛奶} {面包} 0.4 0.67 1.11
1 {面包} {牛奶} 0.4 0.67 1.11
2 {牛奶} {尿布} 0.4 0.67 1.11✅ 总结
-
频繁项集 通过
apriori()计算,保留支持度高的组合; -
关联规则 通过
association_rules()生成,评估置信度、提升度等; -
可调整
min_support和min_threshold控制挖掘深度。