基于Flask的笔记本电脑数据可视化分析系统
一个功能完整的Web应用系统,集成了数据采集、存储、分析和可视化展示,为电商数据分析提供专业解决方案。
📋 目录
- 项目概述
- 技术栈
- 项目结构
- 核心功能
- 代码实现
- 数据可视化
- 部署说明
- 项目特色
- 总结与展望
- 联系方式
🎯 项目概述
本项目是一个基于Flask框架开发的笔记本电脑销售数据可视化分析系统,主要功能包括:
- 数据采集:通过爬虫技术获取淘宝笔记本电脑销售数据
- 数据管理:完整的CRUD操作,支持数据增删改查
- 用户管理:用户注册、登录、个人信息管理
- 数据可视化:多种图表类型,直观展示销售数据
- 实时分析:销售趋势、品牌对比、地区分布等分析
应用场景
- 电商数据分析
- 市场趋势研究
- 竞品分析
- 销售策略制定
- 数据可视化展示
🛠️ 技术栈
后端技术
- Flask 2.0+:轻量级Web框架,灵活易扩展
- SQLAlchemy:ORM框架,数据库操作更安全
- PyMySQL:MySQL数据库连接驱动
- Werkzeug:密码加密、文件上传等工具库
- jieba:中文分词库,文本处理
数据库
- MySQL 8.0+:关系型数据库,存储结构化数据
- 数据库名 :
design_171_computer
前端技术
- Bootstrap 4:响应式CSS框架
- jQuery 3.6+:JavaScript库,DOM操作
- ECharts 5.0+:数据可视化图表库
- DataTables:表格插件,分页搜索
- Feather Icons:图标库
爬虫技术
- Selenium:Web自动化测试工具
- BeautifulSoup:HTML解析库
- DrissionPage:网页自动化库
- requests:HTTP请求库
开发工具
- Python 3.8+
- VS Code / PyCharm
- Git:版本控制
📁 项目结构
基于Flask的笔记本电脑数据可视化分析系统/
├── code/ # 主项目目录
│ ├── main.py # 主应用文件,路由和业务逻辑
│ ├── models.py # 数据模型定义
│ ├── settings.py # 配置文件
│ ├── design_171_computer.sql # 数据库结构文件
│ ├── static/ # 静态资源
│ │ ├── css/ # 样式文件
│ │ ├── js/ # JavaScript文件
│ │ ├── image/ # 图片资源
│ │ ├── font/ # 字体文件
│ │ └── uploads/ # 文件上传目录
│ ├── templates/ # HTML模板
│ │ ├── base.html # 基础模板
│ │ ├── index.html # 首页
│ │ ├── login.html # 登录页
│ │ ├── data_manage.html # 数据管理页
│ │ ├── user_list.html # 用户管理页
│ │ ├── chart_name_cloud.html # 词云图页
│ │ ├── view_screen.html # 可视化大屏
│ │ └── ... # 其他页面模板
│ ├── 爬虫/ # 数据采集模块
│ │ ├── 淘宝笔记本电脑.py # 淘宝数据爬取
│ │ ├── 网易云排行榜.py # 音乐数据爬取
│ │ └── ... # 其他爬虫脚本
│ ├── 数据库存储/ # 数据存储模块
│ │ ├── insert_data.py # 数据插入
│ │ └── into_mysql_table.py # 数据库表创建
│ └── 数据清洗/ # 数据处理模块
│ └── brand_computer_data.csv
├── README.md # 项目说明文档
└── requirements.txt # 依赖包列表🚀 核心功能
1. 用户管理系统
用户注册与登录
- 支持用户名、密码、邮箱、手机号注册
- 密码加密存储,使用Werkzeug安全哈希
- Session管理,登录状态保持
个人信息管理
- 用户信息编辑(用户名、邮箱、手机号、地址、性别、生日)
- 头像上传功能
- 密码修改功能
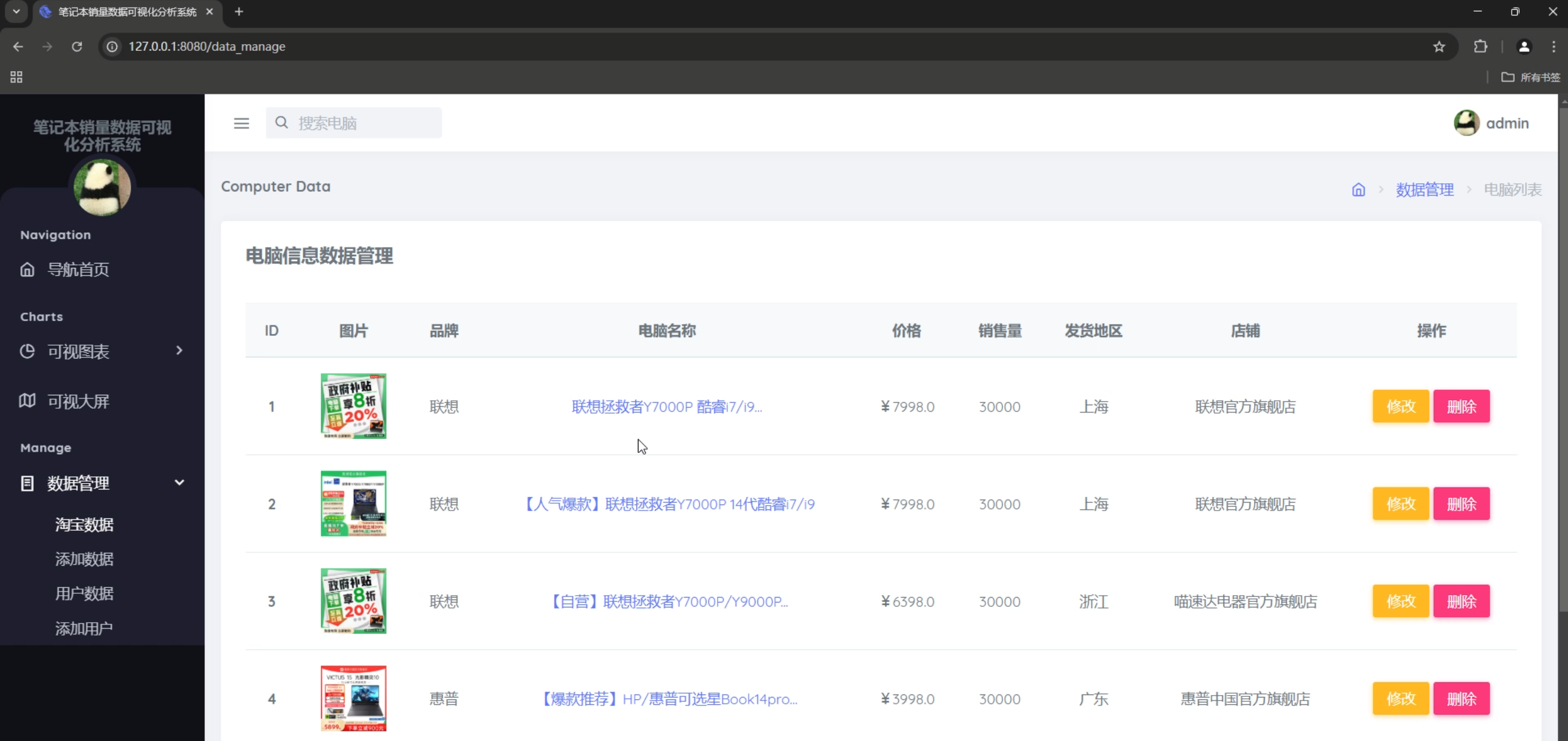
2. 数据管理系统
商品数据管理
- 商品信息CRUD操作
- 分页浏览,每页显示6条数据
- 按商品名称搜索
- 支持图片、链接、价格、销量等信息管理
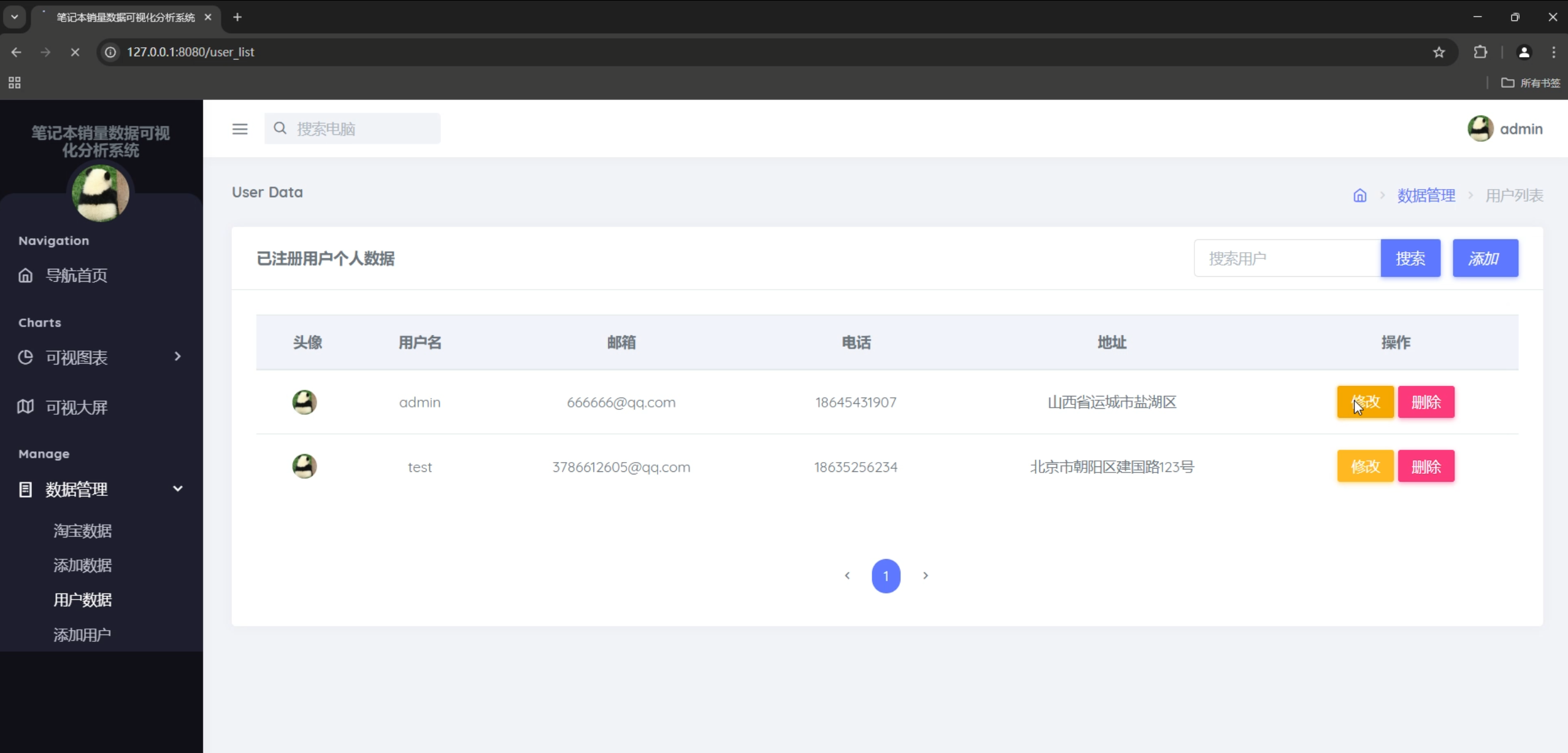
用户数据管理
- 用户列表分页显示
- 多字段搜索(用户名、邮箱、手机号、地址)
- 用户信息编辑和删除
3. 数据可视化系统
*** 🐼 项目源码获取,码界筑梦坊各平台同名,博客底部含联系方式卡片,欢迎咨询!***
基于Python的笔记本电脑数据可视化分析系统
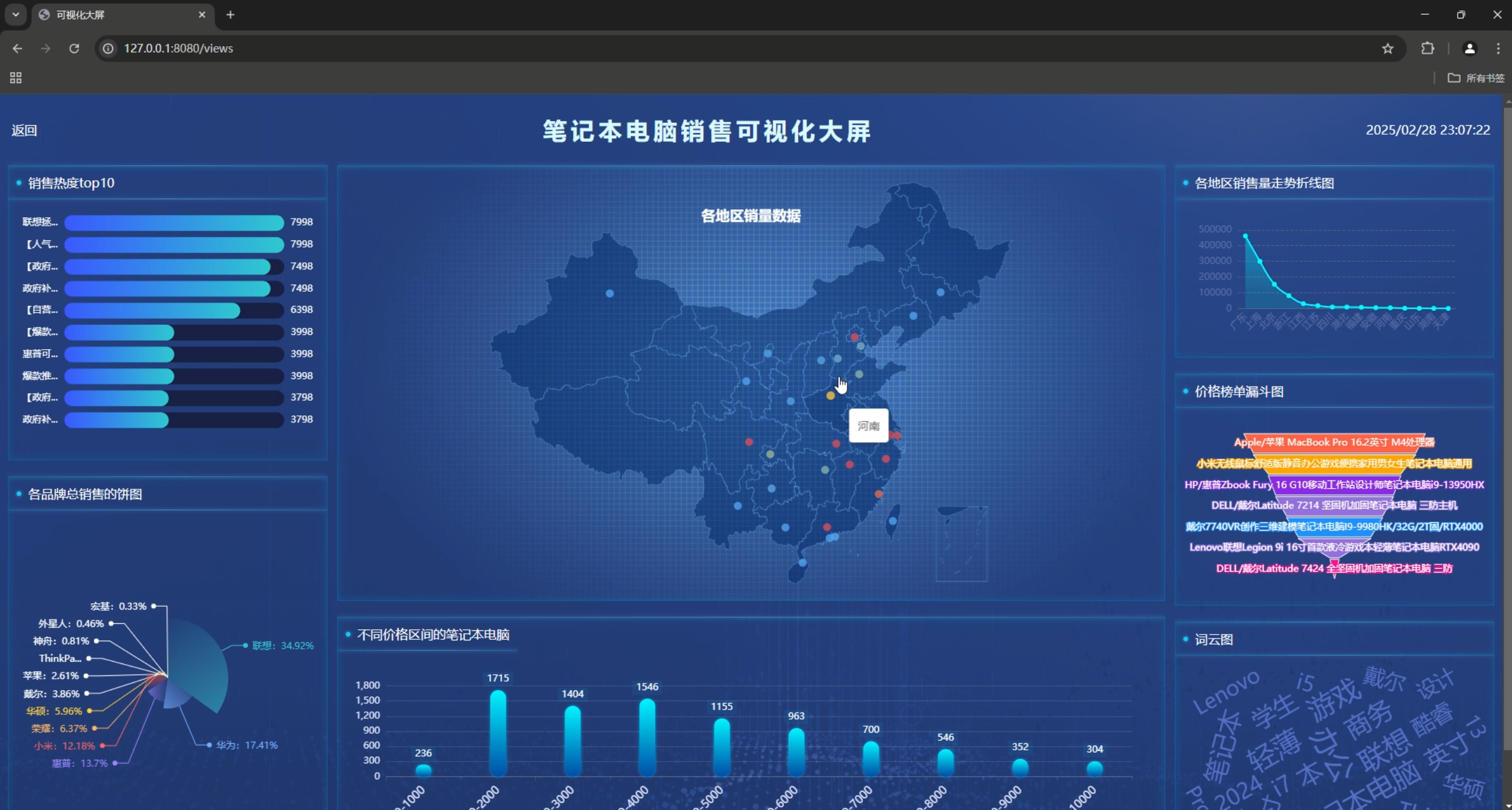
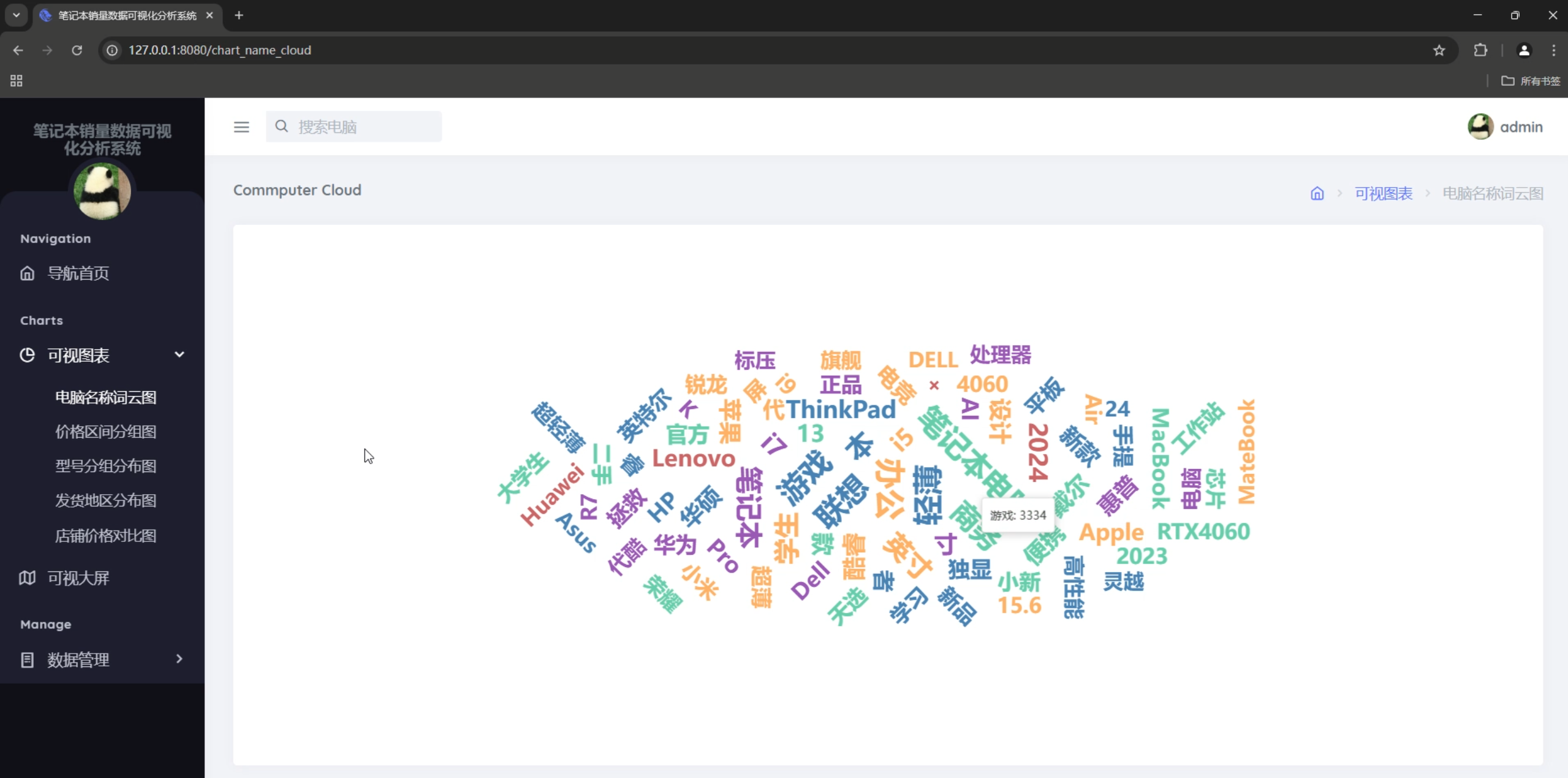
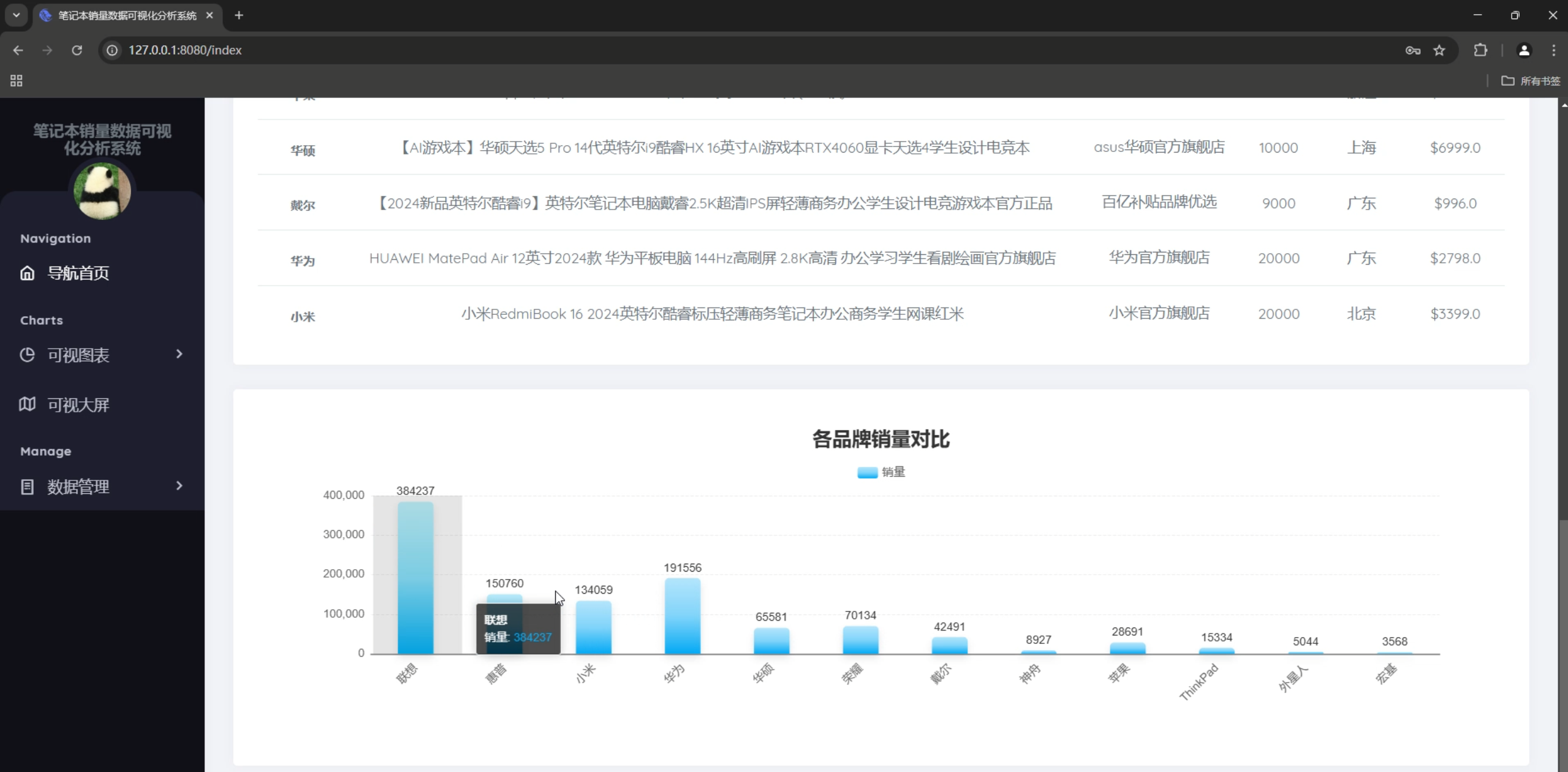
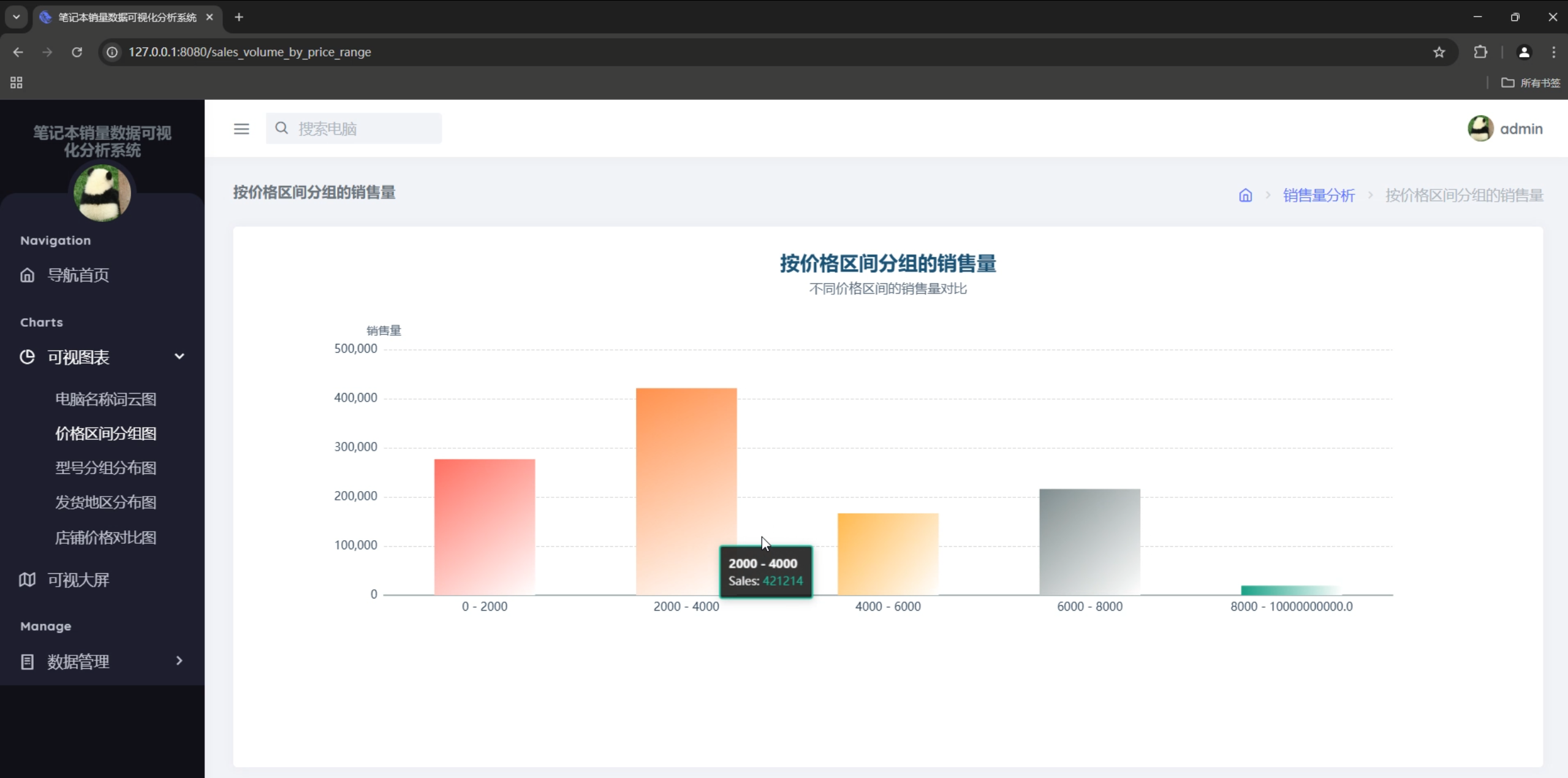
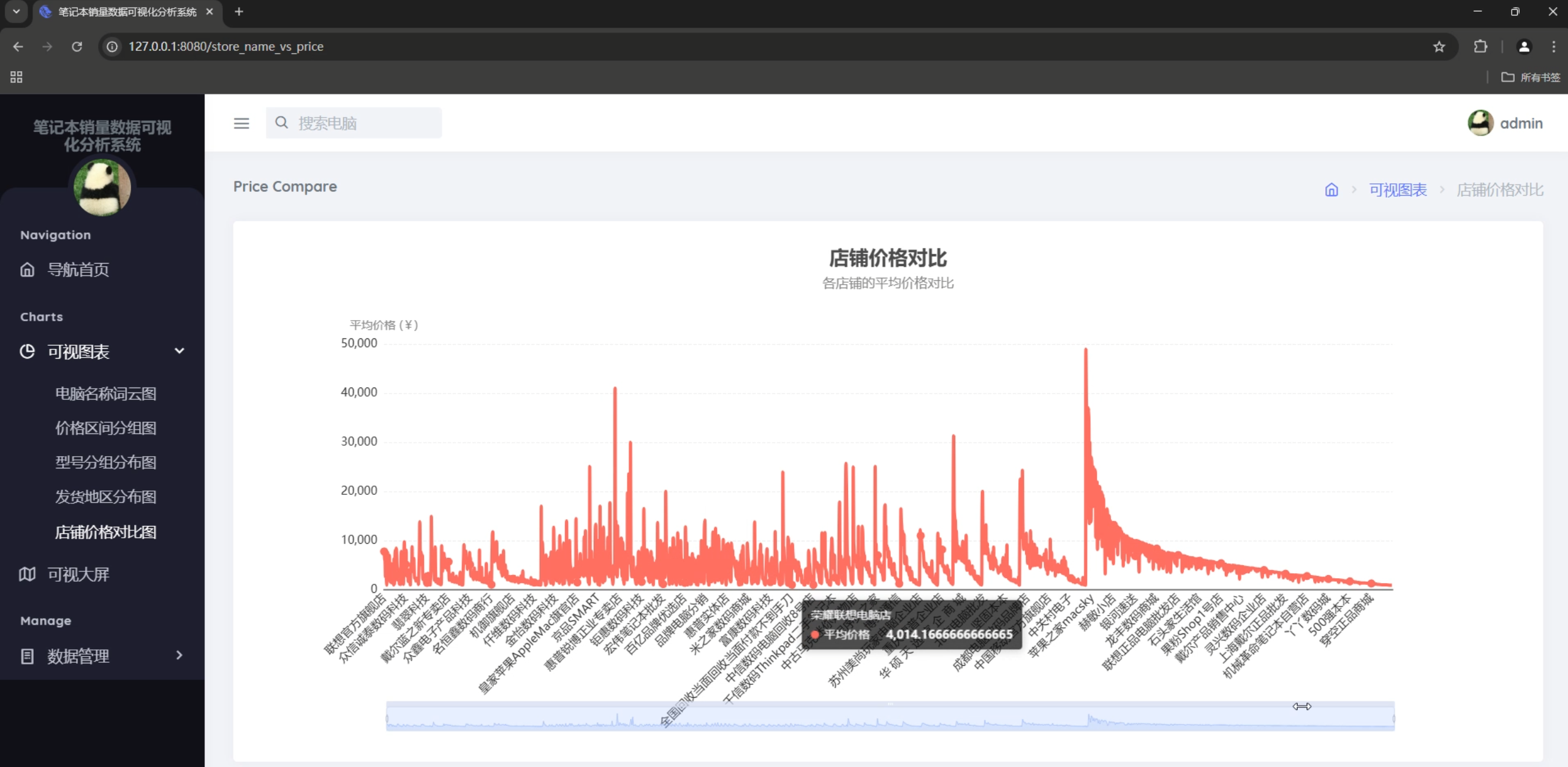
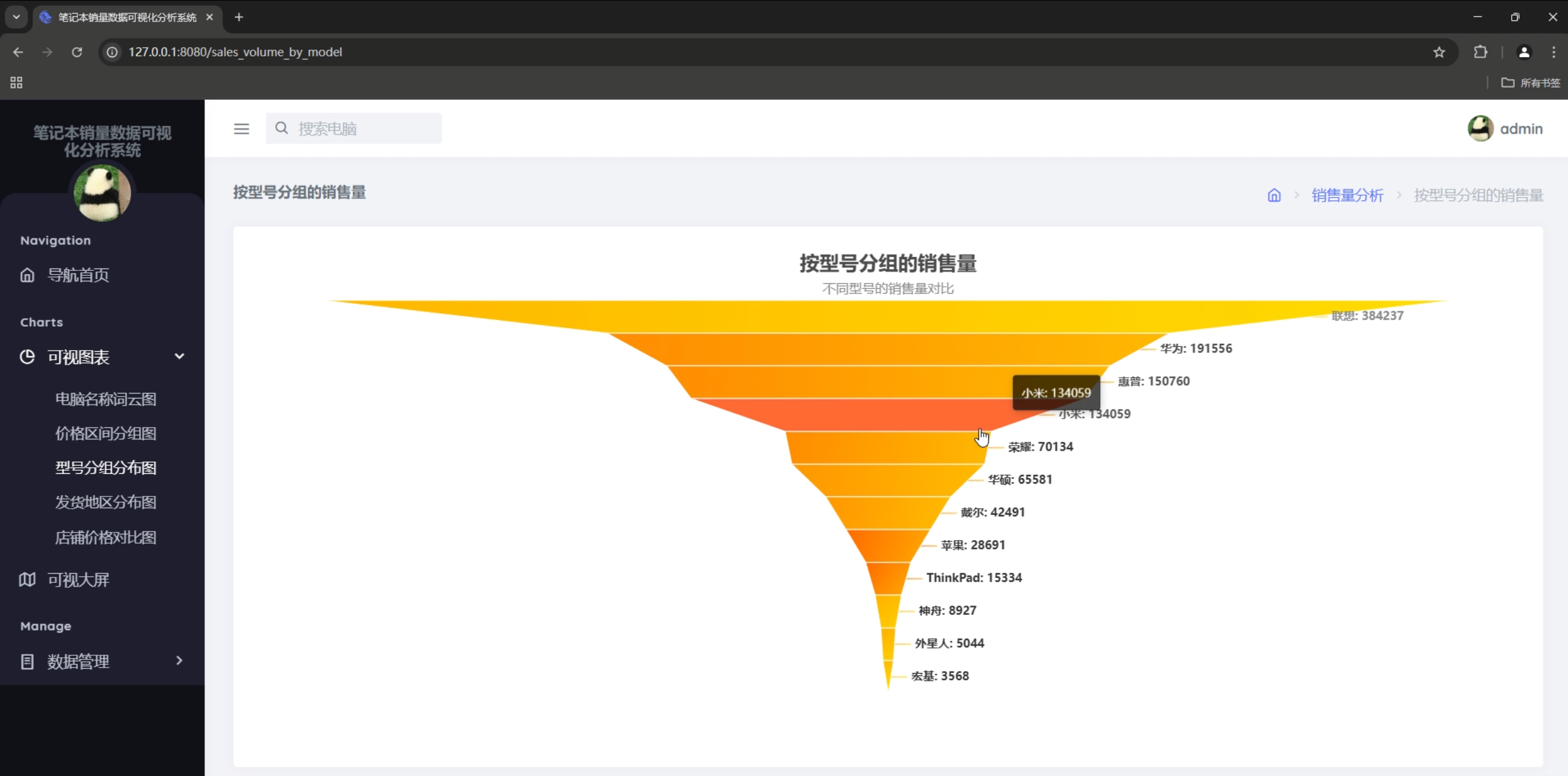
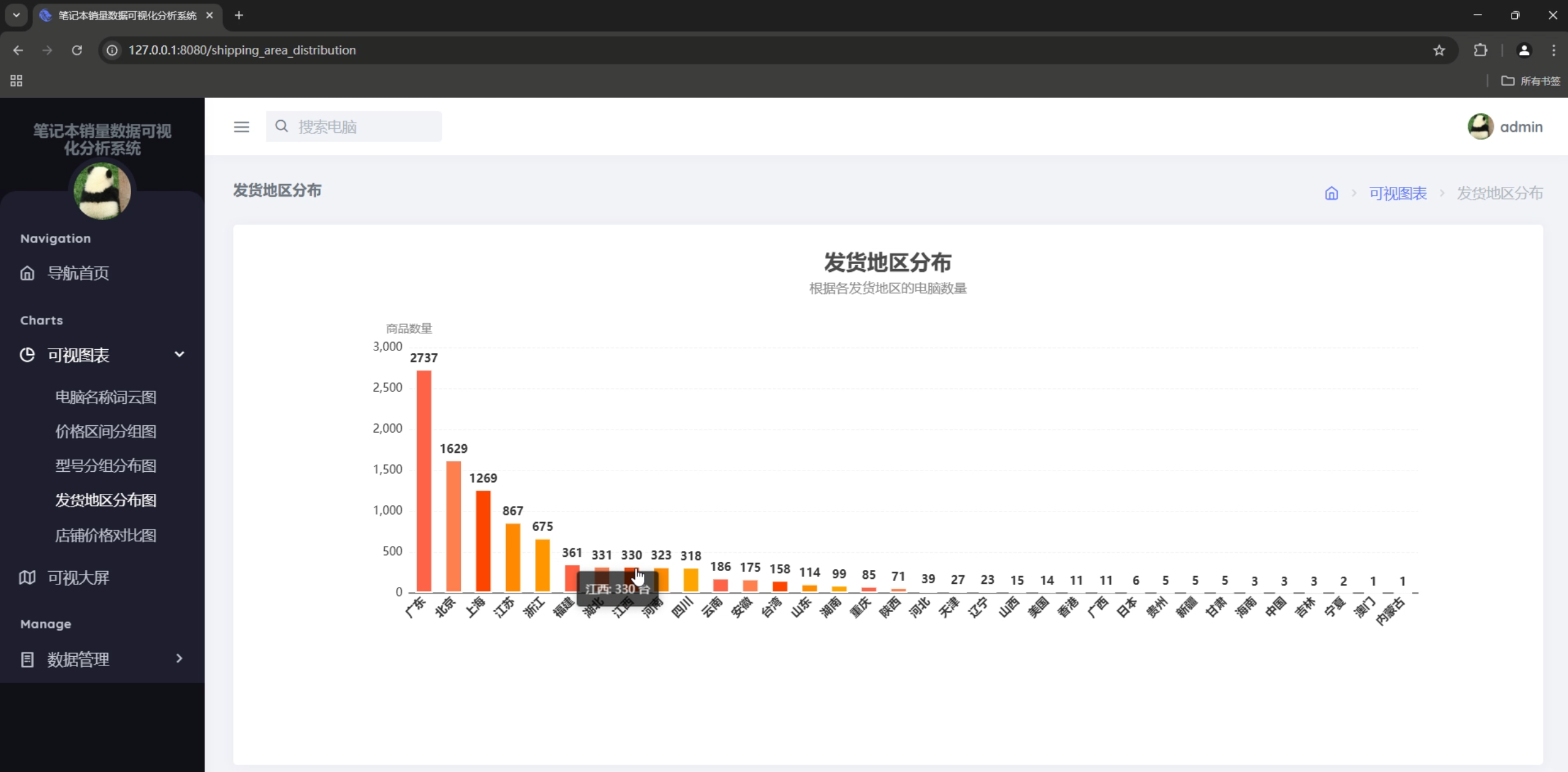
图表类型
- 词云图:商品名称高频词展示
- 柱状图:销售量Top10、价格区间分布
- 饼图:品牌销售量占比
- 折线图:地区销售趋势
- 漏斗图:价格榜单
- 地图:发货地区分布
可视化大屏
- 实时数据展示
- 多图表组合展示
- 响应式布局设计
4. 数据分析功能
销售数据分析
- 品牌销售量对比
- 价格区间分析
- 地区分布统计
- 店铺价格对比
文本分析
- 商品名称分词
- 高频词统计
- 停用词过滤
💻 代码实现
1. 主应用文件 (main.py)
python
from flask import Flask, render_template, jsonify, redirect, session, request, g, url_for, flash
from sqlalchemy import inspect, func
from werkzeug.security import generate_password_hash, check_password_hash
from werkzeug.utils import secure_filename
from models import Computer, User
from settings import Config, db
import csv
main = Flask(__name__)
main.config["SECRET_KEY"] = os.urandom(24)
main.config.from_object(Config)
db.init_app(main)
# 用户登录路由
@main.route('/', methods=['GET', 'POST'])
def login():
if request.method == 'GET':
return render_template("login.html")
elif request.method == 'POST':
username = request.form.get("username")
password = request.form.get("password")
user = User.query.filter_by(username=username).first()
if user and check_password_hash(user.password, password):
session['user'] = username
session['image'] = user.image
return redirect('/index')
else:
return render_template('login.html',
message="用户名或密码错误",
message_type="danger")
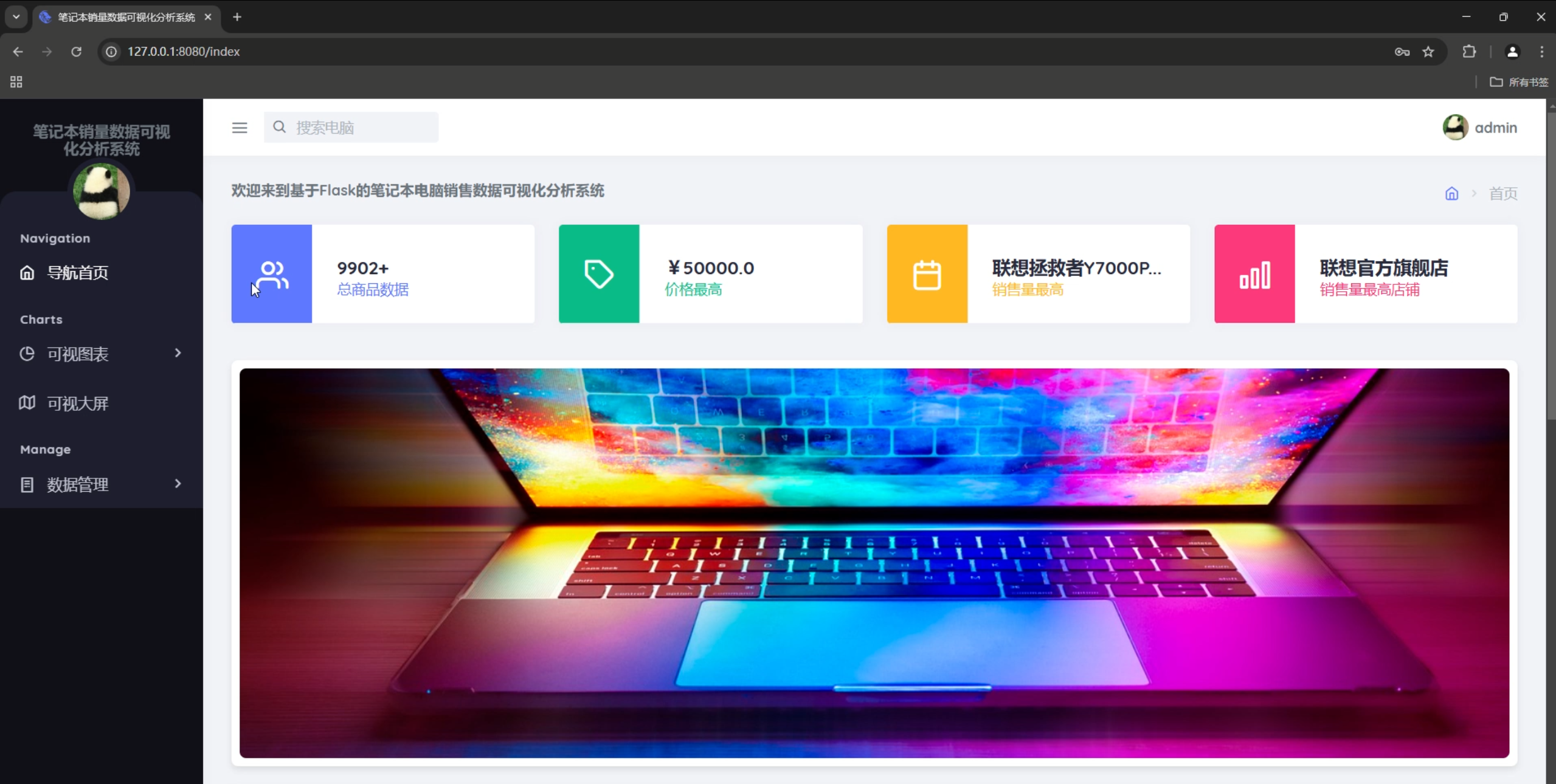
# 首页路由
@main.route("/index")
def main_index():
username = session.get('user')
data_count = Computer.query.count()
price_max = Computer.query.order_by(Computer.price.desc()).first()
sales_max = Computer.query.order_by(Computer.sales_volume.desc()).first()
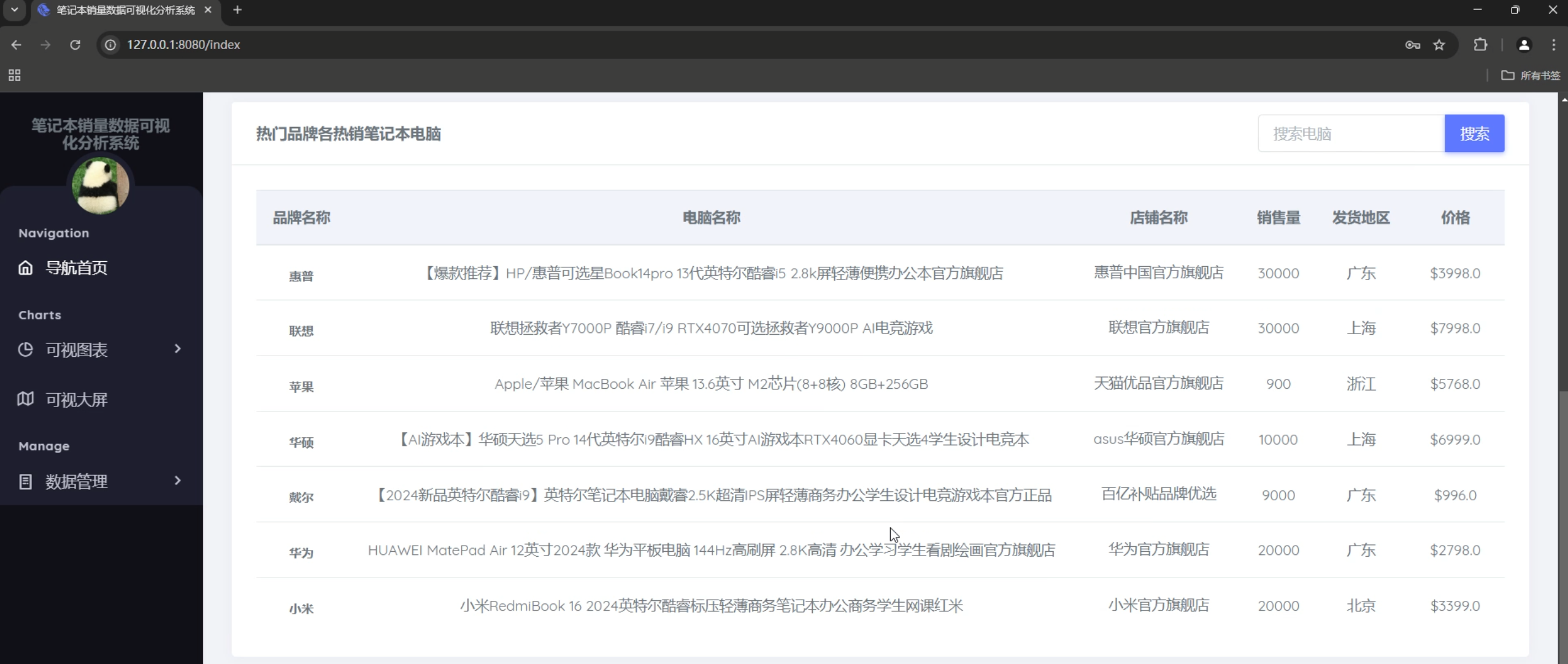
# 各品牌热销商品
hp = Computer.query.filter_by(brand='惠普').order_by(Computer.sales_volume.desc()).first()
levono = Computer.query.filter_by(brand='联想').order_by(Computer.sales_volume.desc()).first()
apple = Computer.query.filter_by(brand='苹果').order_by(Computer.sales_volume.desc()).first()
# ... 其他品牌
return render_template("index.html",
username=username,
data_count=data_count,
price_max=price_max,
sales_max=sales_max,
hp=hp, levono=levono, apple=apple)2. 数据模型 (models.py)
python
from settings import db
import jieba
class Computer(db.Model):
__tablename__ = 'brand_data'
id = db.Column(db.Integer, primary_key=True)
brand = db.Column(db.String(100), nullable=False)
name = db.Column(db.String(100), nullable=False)
img = db.Column(db.String(1000), nullable=False)
link = db.Column(db.String(1000), nullable=False)
price = db.Column(db.Float, nullable=False)
sales_volume = db.Column(db.Integer, nullable=False)
shipping_area = db.Column(db.String(100), nullable=False)
store_name = db.Column(db.String(100), nullable=False)
# 分词函数
def jieba_cut_name(self):
return list(jieba.cut(self.name))
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True)
image = db.Column(db.String(200), nullable=True)
username = db.Column(db.String(100), nullable=False)
email = db.Column(db.String(100), unique=True, nullable=False)
phone_number = db.Column(db.String(15), nullable=False)
password = db.Column(db.String(255), nullable=False)
location = db.Column(db.String(100), nullable=True)
gender = db.Column(db.String(10), nullable=True)
birthday = db.Column(db.Date, nullable=True)3. 配置文件 (settings.py)
python
from flask_sqlalchemy import SQLAlchemy
import pymysql
pymysql.install_as_MySQLdb()
db = SQLAlchemy()
class Config:
DEBUG = False
SQLALCHEMY_DATABASE_URI = 'mysql://root:123456@127.0.0.1:3306/design_171_computer'
SQLALCHEMY_TRACK_MODIFICATIONS = True4. 数据可视化API
python
# 销售量Top10柱状图
@main.route("/sales_bar", methods=["GET"])
def sales_bar():
bar_line = Computer.query.with_entities(
Computer.name,
Computer.price,
Computer.sales_volume
).order_by(Computer.sales_volume.desc()).limit(10).all()
data = []
for row in bar_line:
info_dict = {
'name': row.name,
'price': row.price,
'sales_volume': row.sales_volume,
}
data.append(info_dict)
return jsonify({'data': data})
# 词云图数据
@main.route('/word_name_chart', methods=['GET'])
def word_name_chart():
computers = Computer.query.all()
all_words = []
stopwords = load_stopwords()
for computer in computers:
word_list = computer.jieba_cut_name()
filtered_words = [word for word in word_list if word not in stopwords]
all_words.extend(filtered_words)
word_counts = Counter(all_words)
top_60_words = word_counts.most_common(80)
data = [{'word': word, 'count': count} for word, count in top_60_words]
return jsonify({'data': data})5. 爬虫脚本示例
python
# 爬虫/淘宝笔记本电脑.py
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 淘宝数据爬取
def crawl_taobao_data():
option = webdriver.ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=option)
# 爬取逻辑实现
# ...📊 数据可视化
1. ECharts图表配置
javascript
// 词云图配置
function cloud_chart(data) {
var chart = echarts.init(document.getElementById('cloud'));
var option = {
series: [{
type: 'wordCloud',
shape: 'circle',
left: 'center',
top: 'center',
width: '70%',
height: '80%',
right: null,
bottom: null,
sizeRange: [12, 60],
rotationRange: [-90, 90],
rotationStep: 45,
gridSize: 8,
drawOutOfBound: false,
textStyle: {
fontFamily: 'sans-serif',
fontWeight: 'bold',
color: function () {
return 'rgb(' + [
Math.round(Math.random() * 160),
Math.round(Math.random() * 160),
Math.round(Math.random() * 160)
].join(',') + ')';
}
},
emphasis: {
focus: 'self',
textStyle: {
shadowBlur: 10,
shadowColor: '#333'
}
},
data: data
}]
};
chart.setOption(option);
}2. 可视化大屏布局
html
<!-- templates/view_screen.html -->
<div class="mainbox">
<ul class="clearfix nav1">
<li style="width: 22%">
<div class="box">
<div class="tit">销售热度top10</div>
<div class="boxnav" id="bar_one" style="height: 330px;"></div>
</div>
<div class="box">
<div class="tit">各品牌总销售的饼图</div>
<div class="boxnav" style="height: 406px">
<div id="pie"></div>
</div>
</div>
</li>
<li style="width: 56%">
<div class="box">
<div class="boxnav mapc" style="height: 550px;">
<div class="map" id="map"></div>
</div>
</div>
</li>
<li style="width: 22%">
<div class="box">
<div class="tit">各地区销售量走势折线图</div>
<div class="boxnav" id="line-chart" style="height: 200px;"></div>
</div>
</li>
</ul>
</div>🚀 部署说明
环境要求
bash
# Python版本
Python 3.8+
# 数据库
MySQL 8.0+
# 操作系统
Windows 10+ / Linux / macOS安装步骤
- 克隆项目
bash
git clone [项目地址]
cd 基于Flask的笔记本电脑数据可视化分析系统/code- 安装依赖
bash
pip install -r requirements.txt- 配置数据库
bash
# 创建数据库
mysql -u root -p
CREATE DATABASE design_171_computer;
# 导入数据
mysql -u root -p design_171_computer < design_171_computer.sql- 修改配置
python
# settings.py
SQLALCHEMY_DATABASE_URI = 'mysql://用户名:密码@主机:端口/数据库名'- 运行应用
bash
python main.py访问地址
- 首页:http://localhost:5000/index
- 登录:http://localhost:5000/
- 数据管理:http://localhost:5000/data_manage
- 可视化大屏:http://localhost:5000/views
✨ 项目特色
1. 技术优势
- 轻量级架构:Flask框架,启动快速,资源占用少
- 模块化设计:清晰的目录结构,便于维护和扩展
- 响应式界面:Bootstrap框架,支持多设备访问
- 丰富图表:ECharts图表库,支持多种数据可视化
2. 功能亮点
- 完整用户系统:注册、登录、权限管理
- 数据CRUD:完整的数据增删改查功能
- 智能搜索:支持多字段模糊搜索
- 实时分析:动态数据更新,实时展示
3. 应用价值
- 教学演示:适合Web开发学习
- 数据分析:电商数据可视化分析
- 项目模板:可快速扩展其他业务场景
🔮 总结与展望
项目总结
本项目成功实现了一个功能完整的笔记本电脑销售数据可视化分析系统,具有以下特点:
- 技术架构合理:采用Flask + MySQL + ECharts的技术栈,技术选型恰当
- 功能模块完整:涵盖用户管理、数据管理、可视化分析等核心功能
- 代码结构清晰:模块化设计,代码可读性和可维护性良好
- 用户体验优秀:响应式设计,界面美观,操作便捷
未来展望
-
功能扩展
- 增加更多图表类型
- 支持数据导出功能
- 添加数据备份功能
-
性能优化
- 引入Redis缓存
- 优化数据库查询
- 支持大数据量处理
-
技术升级
- 升级到Flask 3.0
- 引入异步处理
- 支持微服务架构
-
部署优化
- Docker容器化部署
- Nginx反向代理
- HTTPS安全访问
📞 联系方式
码界筑梦坊 - 专注技术分享与学习交流
各大平台同名账号
本文档持续更新中,如有问题或建议,欢迎在评论区留言或通过上述联系方式联系。
最后更新时间: 2025年8月
项目地址: GitHub仓库链接
许可证: MIT License