回顾一下什么叫多轮建模:
要综合判断一个模型好不好,一次随机抽样是不行的, 得多次抽样建模,看看整体的性能如何才行(特别是对于这种小训练集)。
所以我的思路是, 随机抽取训练集和验证集2000次(随你),然后构建2000个ML模型(譬如2000个朴素贝叶斯),得出2000批性能参数。 那怎么实现呢,下面上R语言代码,以朴素贝叶斯为例:
R
library(caret)
library(e1071)
library(pROC)
# 加载数据集
dataset <- read.csv("X disease code fs.csv")
cat("数据集加载成功。\n")
X <- dataset[, 2:14]
Y <- dataset[, 1]
# 初始化结果数据框
results <- data.frame(
Random_Seed = integer(),
Sensitivity_Test = numeric(),
Specificity_Test = numeric(),
AUC_Test = numeric(),
Sensitivity_Train = numeric(),
Specificity_Train = numeric(),
AUC_Train = numeric()
)
cat("结果数据框初始化完成。\n")
# 遍历随机种子
for (n in 1:2000) {
set.seed(n)
cat("设置随机种子为", n, "\n")
# 划分数据集
trainIndex <- createDataPartition(Y, p = 0.7, list = FALSE)
X_train <- X[trainIndex, ]
X_test <- X[-trainIndex, ]
y_train <- Y[trainIndex]
y_test <- Y[-trainIndex]
cat("数据集划分为训练集和测试集。\n")
# 标准化特征
preProcValues <- preProcess(X_train, method = c("center", "scale"))
X_train <- predict(preProcValues, X_train)
X_test <- predict(preProcValues, X_test)
cat("特征标准化完成。\n")
# 训练朴素贝叶斯模型
model <- naiveBayes(X_train, y_train)
cat("朴素贝叶斯模型训练完成。\n")
# 进行预测
y_pred <- predict(model, X_test)
y_train_pred <- predict(model, X_train)
cat("完成对训练集和测试集的预测。\n")
# 计算混淆矩阵
cm_test <- confusionMatrix(as.factor(y_pred), as.factor(y_test))
cm_train <- confusionMatrix(as.factor(y_train_pred), as.factor(y_train))
cat("混淆矩阵计算完成。\n")
# 计算AUC分数
auc_test <- auc(as.numeric(y_test), as.numeric(y_pred))
auc_train <- auc(as.numeric(y_train), as.numeric(y_train_pred))
cat("AUC分数计算完成:测试集 =", auc_test, ",训练集 =", auc_train, "\n")
# 提取敏感性和特异性
sen_test <- cm_test$byClass["Sensitivity"]
sep_test <- cm_test$byClass["Specificity"]
sen_train <- cm_train$byClass["Sensitivity"]
sep_train <- cm_train$byClass["Specificity"]
cat("敏感性和特异性提取完成。\n")
# 追加结果
results <- rbind(results, data.frame(
Random_Seed = n,
Sensitivity_Test = sen_test,
Specificity_Test = sep_test,
AUC_Test = auc_test,
Sensitivity_Train = sen_train,
Specificity_Train = sep_train,
AUC_Train = auc_train
))
cat("第", n, "次迭代的结果已追加。\n")
}
# 保存结果到CSV
write.csv(results, "jet_NB_par.csv", row.names = FALSE)
cat("结果已保存到jet_NB_par.csv。\n")简单解说:
(A)其实就是一个for循环语句,for (n in 1:2000) ,2000次就是2000,你要是想运行10000次,就改成10000;
(B)运行以后呢,可以看到模型在迭代,显示的是运行到第几个模型了:
(C)用代码 write.csv(results, "jet_NB_par.csv", row.names = FALSE) 输出成excel查看,输出地址就是你的工作路径,不懂的话可以使用代码 getwd()展 示出来。
(D)打开工作路径,可以发现jet_NB_par这个文件:

(E)打开文件,调整一下格式:
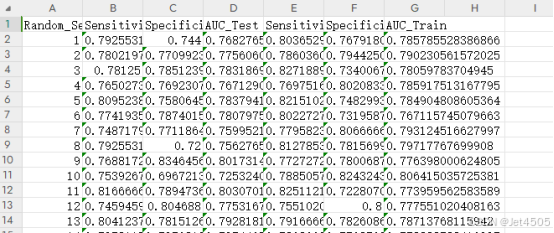
(F)然后可以操作了,比如test-sen排个序,看看最好的有多好;比如看看2000次的平均值和标准差:AUC平均值0.77-0.78左右。剩下的自己玩了,不说那么多了,发挥你们的妄想空间。