想要通过llama.cpp的方式跑deepseek R1模型。在按照https://huggingface.co/unsloth/DeepSeek-R1-GGUF教程去配环境时报错了。具体如下:
(base) oem@core:~/Desktop/deepseek_llama.cpp$ sudo cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON
-- Warning: ccache not found - consider installing it for faster compilation or disable this warning with GGML_CCACHE=OFF
-- CMAKE_SYSTEM_PROCESSOR: x86_64
-- Including CPU backend
-- x86 detected
-- Adding CPU backend variant ggml-cpu: -march=native
-- Found CUDAToolkit: /usr/local/cuda/targets/x86_64-linux/include (found version "12.9.41")
-- CUDA Toolkit found
-- Using CUDA architectures: native
CMake Error at ggml/src/ggml-cuda/CMakeLists.txt:25 (enable_language):
The CMAKE_CUDA_COMPILER:
/usr/bin/nvcc
is not a full path to an existing compiler tool.
Tell CMake where to find the compiler by setting either the environment
variable "CUDACXX" or the CMake cache entry CMAKE_CUDA_COMPILER to the full
path to the compiler, or to the compiler name if it is in the PATH.
-- Configuring incomplete, errors occurred!具体是说,CUDA编译的路径是 /usr/bin/nvcc。但是这个目录不存在。
首先查看nvcc的目录,运行下面命令:
which nvcc如果有输出,则跳过第1步,如果没有输出,则跳到第3步。
第1步
输入which nvcc后,假设有输出,例如输出/usr/local/cuda/bin/nvcc
,则把命令改成:
sudo cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc输入此命令后,如果报错下面内容,说明deepseek-llama.cpp 项目 要求 至少支持 CUDA 17(也就是C++17 for CUDA)。而你的版本太老了。此时跳到第2步。
-- Warning: ccache not found - consider installing it for faster compilation or disable this warning with GGML_CCACHE=OFF
-- CMAKE_SYSTEM_PROCESSOR: x86_64
-- Including CPU backend
-- x86 detected
-- Adding CPU backend variant ggml-cpu: -march=native
-- CUDA Toolkit found
-- Using CUDA architectures: native
-- The CUDA compiler identification is NVIDIA 10.1.243 with host compiler GNU 8.4.0
-- Detecting CUDA compiler ABI info
-- Detecting CUDA compiler ABI info - done
-- Check for working CUDA compiler: /usr/bin/nvcc - skipped
-- Detecting CUDA compile features
-- Detecting CUDA compile features - done
-- CUDA host compiler is GNU 8.4.0
-- Including CUDA backend
-- Configuring done (3.8s)
CMake Error in ggml/src/ggml-cuda/CMakeLists.txt:
Target "ggml-cuda" requires the language dialect "CUDA17" (with compiler
extensions). But the current compiler "NVIDIA" does not support this, or
CMake does not know the flags to enable it.
-- Generating done (0.2s)
CMake Generate step failed. Build files cannot be regenerated correctly.第2步
当前CUDA版本太老了,那就把它卸载了重新装。按照下面命令卸载cuda及其驱动:
#退出图形界面
sudo systemctl isolate multi-user.target
#卸载旧驱动
sudo apt-get --purge remove '*cuda*' '*nvidia*'
sudo apt-get autoremove
#检查驱动是否卸载干净
lsmod | grep nvidia
#若上述命令打印出东西,如打印出nvidia_drm,则执行:
sudo rmmod nvidia_drm #运行sudo rmmod XXX命令,直到lsmod | grep nvidia打印不出内容第3步
现在系统没有驱动也没有cuda了,可以安装高版本的cuda了。
去NVIDIA官网,按照官网的配置教程来:https://developer.nvidia.com/cuda-12-2-0-download-archive
我的系统是linux,X86_64,Ubantu,我选择的是deb(local)形式。得到下面命令:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda-repo-ubuntu2004-12-9-local_12.9.0-575.51.03-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-12-9-local_12.9.0-575.51.03-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2004-12-9-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda注意第3条命令,最好用cuda-repo-ubuntu2004-12-9-local_12.9.0-575.51.03-1_amd64.deb而不用cuda-repo-ubuntu2004-12-2-local_12.2.0-535.54.03-1_amd64.deb。因为驱动如果是535版本的和5.15.x的内核版本不兼容。
运行上述命令后,使用sudo reboot重启一下。
输入nvidia-smi,可以得到以下内容,圈出来的内容是驱动的版本:
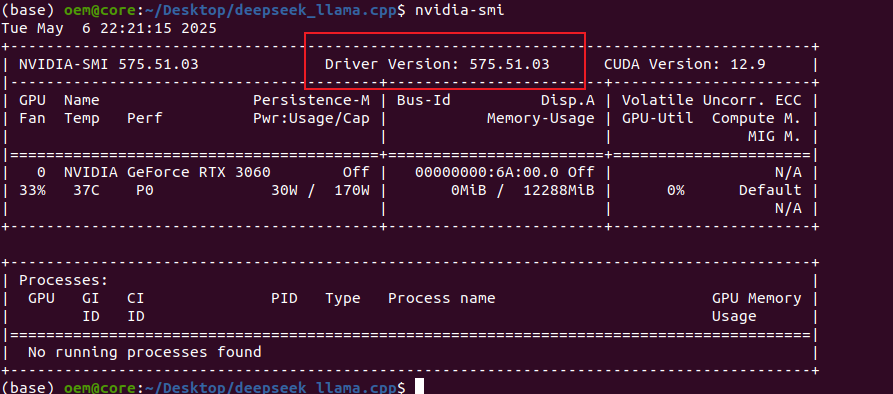 然后再输入以下内容,把nvcc的路径添加到环境变量中:
然后再输入以下内容,把nvcc的路径添加到环境变量中:
which nvcc
nvcc --version
export PATH=/usr/local/cuda/bin:$PATH #注意:这里的路径是which nvcc打印的内容去掉nvcc后的路径
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH #注意:这里的路径是which nvcc打印的内容去掉nvcc后的路径再加上lib64的路径
source ~/.bashrc做完这些后,再去执行sudo cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc命令,应该能成功了。