数据可视化的目的是为了数据分析,而非仅仅是数据的图形化展示。
项目介绍
项目案例为电商双11美妆数据分析,分析品牌销售量、性价比等。
数据集包括更新日期、ID、title、品牌名、克数容量、价格、销售数量、评论数量、店名等信息。
1、数据初步了解

运行结果
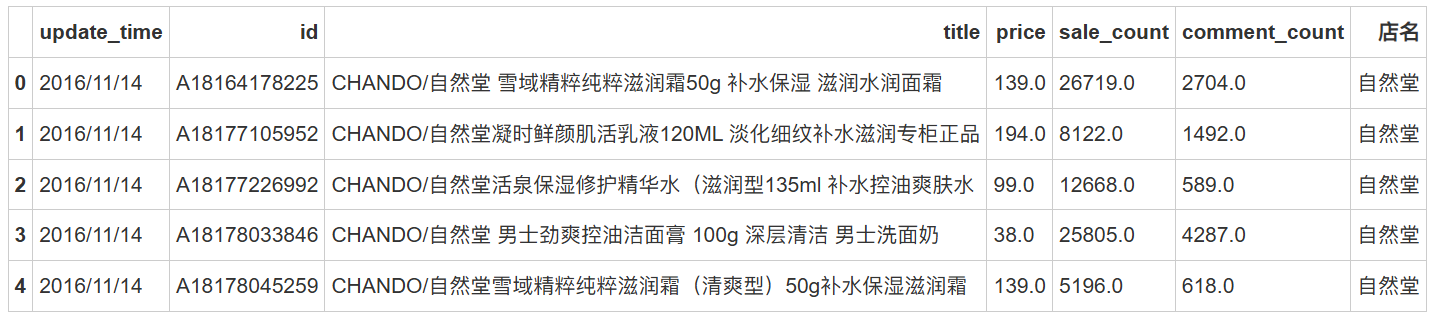
数据预处理
使用pandas库进行数据预处理,包括查看数据特征、处理缺失值和重复值。
df.describe() #查看各数字类型特征的一些统计量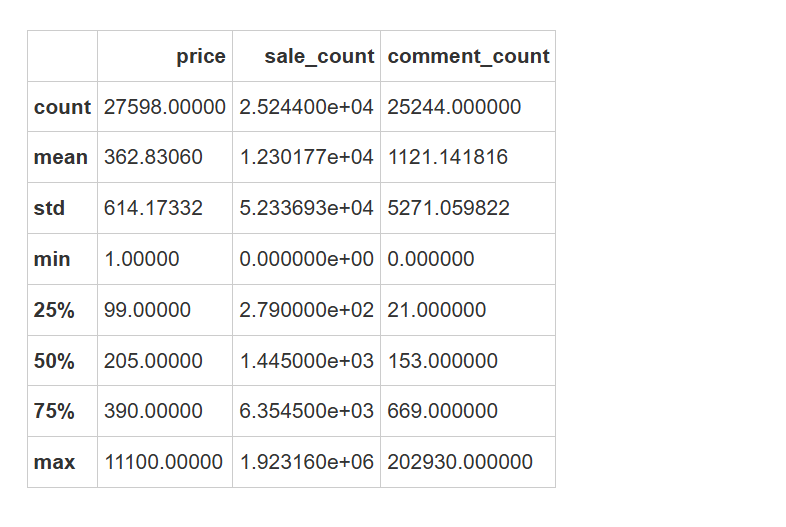
处理缺失值的方法包括填充(如用0填充)和删除空行。
python
data = df.drop_duplicates(inplace = False)##去重
data.reset_index(inplace = True,drop = True)##重置行索引
data.shape处理重复值需有充分理由,确保删除的是无效重复数据。
python
data=data.fillna(0) #用0填补缺失值
data.isnull().any() #查看是否还有空值
数据分类
创建主类别和子类别,基于数据集中的关键词进行分类。
关键词如"美白乳"、"润肤乳"等属于乳液类。
分类字典包含关键字、主类别和子类别。





性别分类
新增"是否为男士专用"列,通过检测关键词如"男士"、"男生"等进行分类。

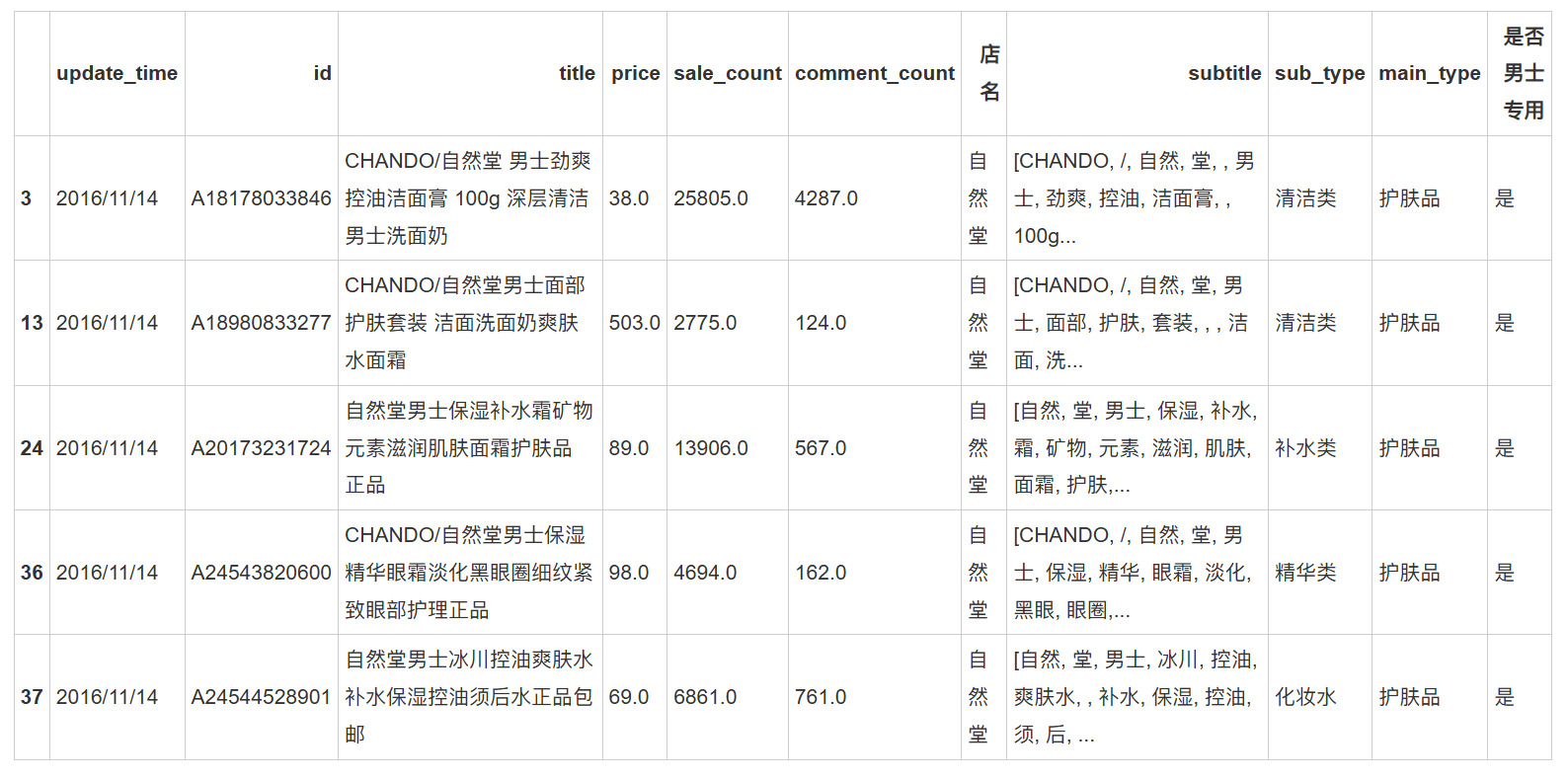
销售额计算
销售额通过销售量和销售单价相乘得出。
新增"销售额"列,并计算各店铺的销售情况。
python
data['销售额'] = data.price * data.sale_count
data.head()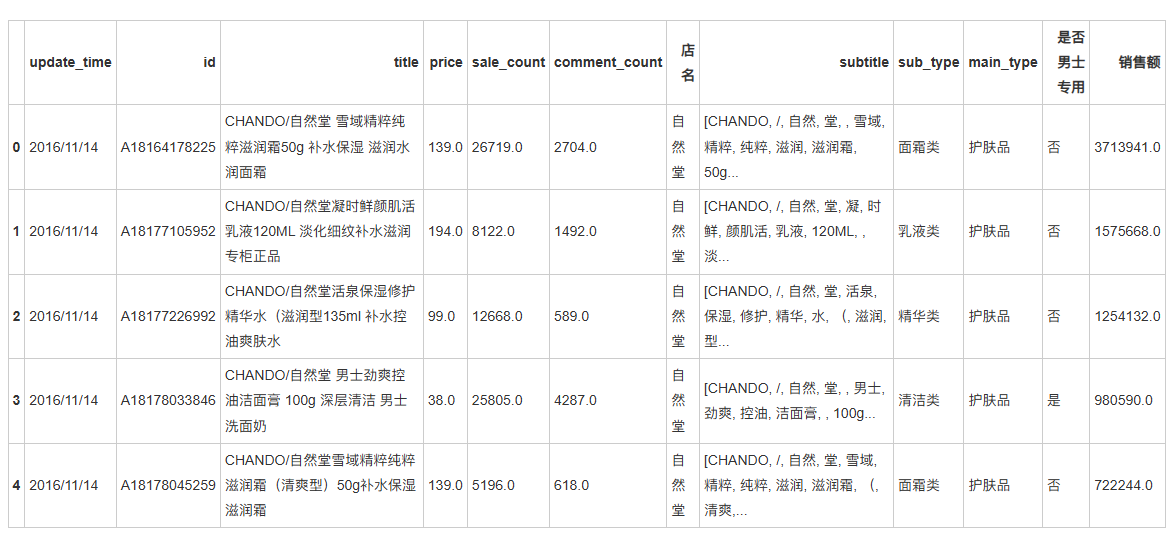
数据可视化
绘制各店铺商品数量、销量、总销售额和平均单价的图表。
python
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = [u'SimHei'] ##显示中文,设置字体
plt.rcParams['axes.unicode_minus'] = False ##显示符号
plt.figure(figsize = (12,10))
# 各店铺的商品数量
plt.subplot(2,2,1)
plt.tick_params(labelsize=15)
data['店名'].value_counts().sort_values().plot.bar()
plt.title('各品牌商品数',fontsize = 20)
plt.ylabel('商品数量',fontsize = 15)
plt.xlabel('店名')
# 各店铺的销量
plt.subplot(2,2,2)
plt.tick_params(labelsize=15)
data.groupby('店名').sale_count.sum().sort_values().plot.bar()
plt.title('各品牌所有商品的销量',fontsize = 20 )
plt.ylabel('商品总销量',fontsize = 15)
#各店铺总销售额
plt.subplot(2,2,3)
plt.tick_params(labelsize=15)
data.groupby('店名')['销售额'].sum().sort_values().plot.bar()
plt.title('各品牌总销售额', fontsize = 20)
plt.ylabel('商品总销售额' , fontsize = 15)
#旋转显示plt.xticks(rotation=45)
##补充绘图,挖掘数据,各品牌的平均每单单价,三个销量为0的品牌暂时不考虑
plt.subplot(2,2,4)
plt.tick_params(labelsize = 15)
avg_price=data.groupby('店名')['销售额'].sum()/data.groupby('店名').sale_count.sum() ###每个品牌售出的商品的平均单价
avg_price.sort_values().plot.bar()
plt.title('各品牌平均每单单价', fontsize = 20)
plt.ylabel('售出商品的平均单价' , fontsize = 15)
##自适应调整子图间距
plt.tight_layout()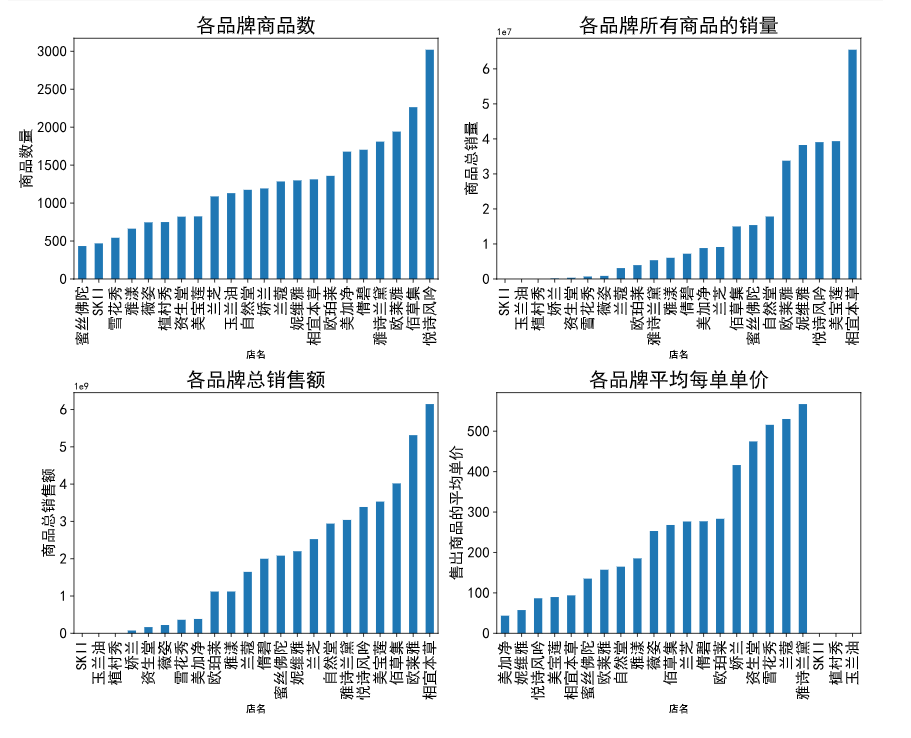
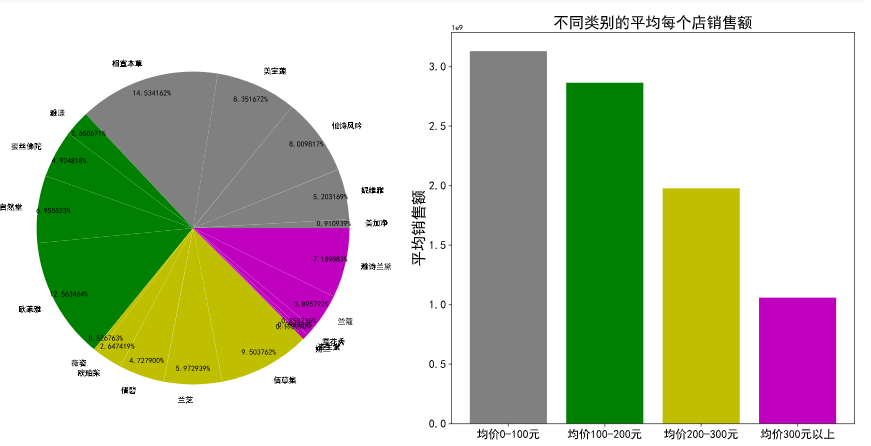
使用柱形图和饼图展示数据,并将按价格区间将商品分为ABCD四类,并绘制销售额占比图。
python
A=avg_price[(avg_price <= 100) & (avg_price > 0) ].index
B=avg_price[(avg_price <= 200) & (avg_price > 100) ].index
C=avg_price[(avg_price <= 300) & (avg_price > 200) ].index
D=avg_price[avg_price > 300 ].index
#四类ABCD分别代表0-100,100-200,200-300,300以上平均单价区间的各品牌
sum_sale=data.groupby('店名')['销售额'].sum()
plt.figure(figsize = (16,8))
plt.tick_params(labelsize=10)
###各类、各品牌的销售额占比
plt.subplot(1,2,1)
sum_sale_byprice=sum_sale[A].sort_values().append(sum_sale[B].sort_values()).append(sum_sale[C].sort_values()).append(sum_sale[D].sort_values())
plt.pie(x=sum_sale_byprice,labels =sum_sale_byprice.index ,colors = ['grey']*len(A)+['g']*len(B)+['y']*len(C)+['m']*len(D),autopct='%0f%%',pctdistance=0.9)
###各类的平均每个店销售额
plt.subplot(1,2,2)
plt.tick_params(labelsize = 15)
plt.bar('均价0-100元',np.mean(sum_sale[A]),color = 'grey')
plt.bar('均价100-200元',np.mean(sum_sale[B]),color = 'g')
plt.bar('均价200-300元',np.mean(sum_sale[C]),color = 'y')
plt.bar('均价300元以上',np.mean(sum_sale[D]),color = 'm')
plt.title('不同类别的平均每个店销售额',fontsize = 20)
plt.ylabel('平均销售额',fontsize = 20)
plt.tight_layout()