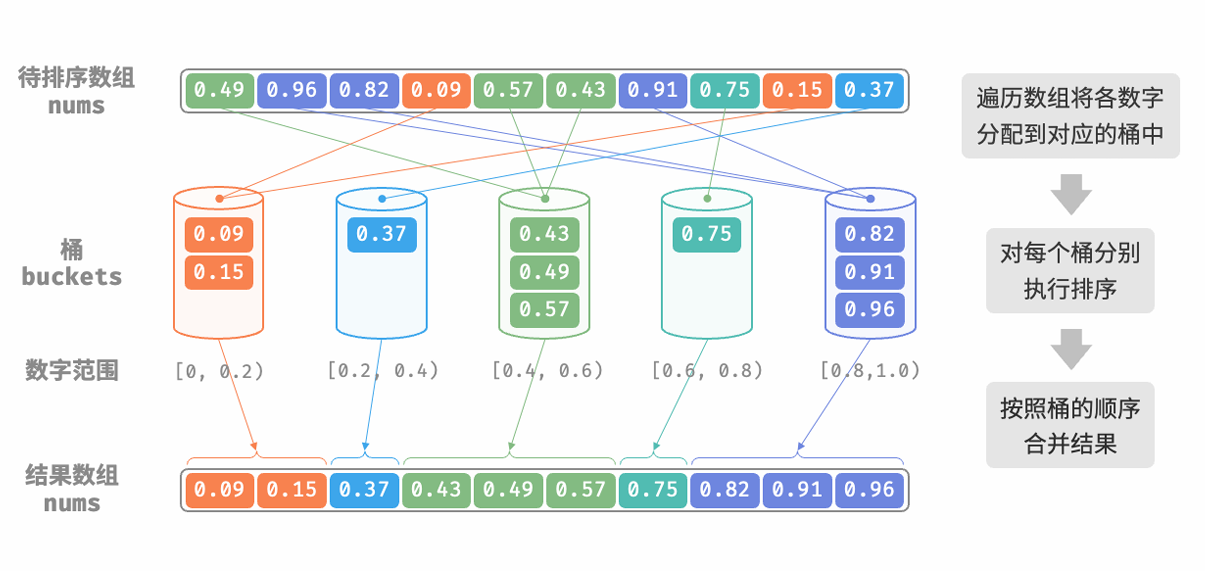
def bucket_sort(nums: list[float]):
"""桶排序"""
# 初始化 k = n/2 个桶,预期向每个桶分配 2 个元素
k = len(nums) // 2
buckets = [[] for _ in range(k)]
# 1. 将数组元素分配到各个桶中
for num in nums:
# 输入数据范围为 [0, 1),使用 num * k 映射到索引范围 [0, k-1]
i = int(num * k)
# 将 num 添加进桶 i
buckets[i].append(num)
# 2. 对各个桶执行排序
for bucket in buckets:
# 使用内置排序函数,也可以替换成其他排序算法
bucket.sort()
# 3. 遍历桶合并结果
i = 0
for bucket in buckets:
for num in bucket:
nums[i] = num
i += 1
if __name__ == "__main__":
# 设输入数据为浮点数,范围为 [0, 1)
nums = [0.49, 0.96, 0.82, 0.09, 0.57, 0.43, 0.91, 0.75, 0.15, 0.37]
bucket_sort(nums)
print("桶排序完成后 nums =", nums)