目录
- 小米-多模态算法工程师
-
- 1、对多模态大模型的了解
-
- [1.1 CLIP](#1.1 CLIP)
- [1.2 BLIP](#1.2 BLIP)
- [1.3 BLIP-2](#1.3 BLIP-2)
- 2、文生图、图生图?
- 3、目前的图像或视频编码器,核心思想方法是什么?
- 4、
小米-多模态算法工程师
1、对多模态大模型的了解
1.1 CLIP
CLIP利用对比学习(Contrastive Learning)对图像和文本进行联合训练。
1.2 BLIP
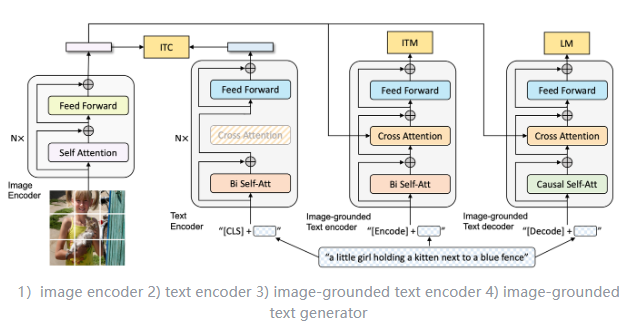
BLIP的模型架构包括4个关键部分:图像编码器、文本编码器、图像-文本匹配编码器和图像-文本解码器
- Image Encoder :VIT 用于提取图像特征
- Text Encoder:BLIP使用了BERT作为文本编码器。
- 图像-文本匹配编码器 (Image-grounded Text Encoder): 用于判断当前的文本描述和图像是否匹配,进行图像-文本的匹配任务。
该模型的输入是图像特征(通过图像编码器提取)和文本特征(通过文本编码器提取),并通过交叉注意力机制(Cross Attention)在每个Transformer层中结合视觉特征。- 图像-文本解码器 (Image-grounded Text Decoder): 用于生成图像的文本描述(caption)。该模块的架构与图像-文本匹配编码器相似,同样采用交叉注意力机制,将图像特征与文本特征结合进行生成任务。

1.3 BLIP-2
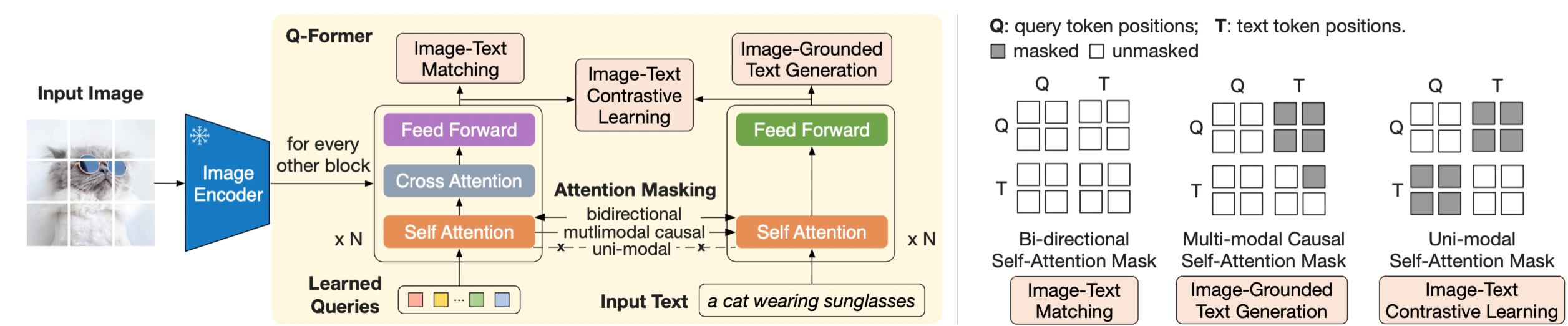
BLIP-2 的主要目标是通过cross-modal alignment(跨模态对齐)来连接图像和文本之间的差距。它包含两个主要的学习阶段:
①Representation Learning :通过 Q-Former 提取与文本相关的图像特征。BLIP-2 使用了 Q-Former 框架,包含两个Transformer结构-Former-Image 和 Q-Former-Text。这两个模型通过交叉注意力机制相互关注,从而有效地从视觉和文本中提取相关的特征。其中 Q-Former-Image:负责处理图像信息,它的输入是一个可学习的 query 向量集,这些查询向量经过 Q-Former-Image 后,输出图像的特征。Q-Former-Text:负责处理文本信息,它的输入是文本特征,并通过与图像特征的交叉注意力机制来提取文本相关的视觉特征。Q-Former 以交叉注意力的方式关注冻结的图像编码器提取的视觉特征,确保图像的视觉信息能够被有效地映射到文本特征空间中。
通过三个损失进行优化 Image-Text Contrastive Learning (ITC) Image-grounded Text Generation (ITG) Image-Text Matching (ITM)
②Generative Learning :将 Q-Former 提取的视觉特征对齐到文本模态,利用下游的大语言模型(LLM)进行进一步的生成任务。
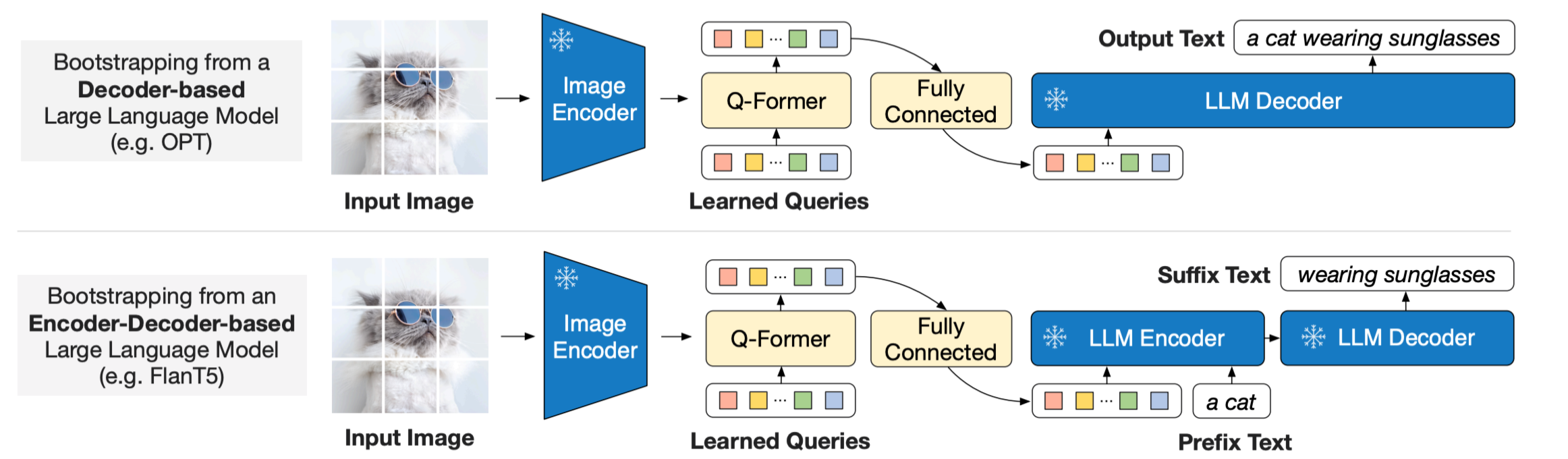
BLIP-2 将 Q-Former 提取的视觉特征对齐到文本模态,并通过一个线性层将其转化为文本特征,送入下游的大语言模型(LLM)。
2、文生图、图生图?
经典的文生图模型如 AttnGAN 和 StackGAN,利用多层次的生成网络逐步生成高分辨率的图像。
变分自编码器(VAE) 和 扩散模型
Transformer模型
3、目前的图像或视频编码器,核心思想方法是什么?
编码器负责将图像或视频输入转换为高维特征表示,这些特征会被后续的模型(如分类器、生成器、检测器等)使用
- 卷积神经网络(CNN):CNN 是传统图像编码器的核心,早期的模型如 VGG16 和 ResNet 利用卷积层和池化层提取图像的低级和高级特征 . ResNet VGG16
- Transformer Vision Transformer (ViT)
对于视频编码器
- 3D卷积层
- 双流网络
- TimeSformer