目录
[01 变量定义](#01 变量定义)
[02 自增语法](#02 自增语法)
[03 指针](#03 指针)
[04 go不支持的语法](#04 go不支持的语法)
[05 string](#05 string)
[06 定长数组-forrange](#06 定长数组-forrange)
[07 动态数组追加元素](#07 动态数组追加元素)
[08 切片截取-copy-make介绍](#08 切片截取-copy-make介绍)
[09 map介绍](#09 map介绍)
[10 函数](#10 函数)
[11 内存逃逸](#11 内存逃逸)
[12 import](#12 import)
[13 命令行参数-switch](#13 命令行参数-switch)
[14 标签与continue-goto-break配合使用](#14 标签与continue-goto-break配合使用)
[15 枚举const-iota](#15 枚举const-iota)
[16 结构体基本语法](#16 结构体基本语法)
[17 init函数](#17 init函数)
[18 defer-文件读取-匿名函数](#18 defer-文件读取-匿名函数)
01 变量定义
二、基础语法
1. 变量定义
```go
package main
import "fmt" //goland会帮我们自动导入程序中使用的包
func main() {
//变量定义: var
//常量定义: const
//01-先定义变量,再赋值 var 变量名 数据类型
var name string
name = "duke" //Ctrl + Alt +l 可以快速格式化代码
var age int
age = 20
fmt.Println("name:", name)
fmt.Printf("name is :%s, %d\n", name, age)
//02 定义时直接赋值
var gender = "man"
fmt.Println("gender:", gender)
//03 定义直接赋值,使用自动推导 (最常用的)
address := "北京"
fmt.Println("address:", address)
//灰色部分表示形参
test(10, "str")
//04-平行赋值
i, j := 10, 20 //同时定义两个变量
fmt.Println("变换前==》 i:", i, ", j:", j)
i, j = j, i
fmt.Println("变换后==》i:", i, ", j:", j)
}
func test(a int, b string) {
fmt.Println(a)
fmt.Println(b)
}
```
!1585881281278(assets/1585881281278.png)
02 自增语法
基础数据类型:
```go
int,int8 int16, int32, int64
uint8 ... uint64
float32
float64
true/false
```
2. 自增语法
c语言:i++, i--, --i, ++i
go语言:i++, i--, 没有--i,++i, 自增语法必须单独一行
```go
package main
import "fmt"
func main() {
i := 20
i++
//++i //这个也是错的, 语义更加明确
//fmt.Println("i:", i++) //这是错误的,不允许和其他代码放在一起,必须单独一行
fmt.Println("i:", i)
}
```
03 指针
3. 指针
```go
package main
import "fmt"
func main() {
//go语义也有指针
//结构体成员调用时: c语言: ptr->name go语言: ptr.name
//go语言在使用指针时,会使用内部的垃圾回收机制(gc : garbage collector),开发人员不需要手动释放内存
//c语言不允许返回栈上的指针,go语言可以返回栈上的指针,程序会在编译的时候就确定了变量的分配位置:
//编译的时候,如果发现有必要的话,就将变量分配到堆上
name := "lily"
ptr := &name
fmt.Println("name:", *ptr)
fmt.Println("name ptr:", ptr)
//02-使用new关键字定义
name2Ptr := new(string)
*name2Ptr = "Duke"
fmt.Println("name2:", *name2Ptr)
fmt.Println("name2 ptr:", name2Ptr)
//可以返回栈上的指针,编译器在编译程序时,会自动判断这段代码,将city变量分配在堆上
res := testPtr()
fmt.Println("res city :", *res, ", address:", res)
//空指针,在c语言: null, c++: nullptr,go: nil
//if两端不用加()
//即使有一行代码,也必须使用{}
if res == nil {
fmt.Println("res 是空,nil")
} else {
fmt.Println("res 是非空")
}
}
//定义一个函数,返回一个string类型的指针, go语言返回写在参数列表后面
func testPtr() *string {
city := "深圳"
ptr := &city
return ptr
}
04 go不支持的语法
4. 不支持的语法汇总
-
自增--i, ++i不支持
-
不支持地址加减
-
不支持三目运算符 ? :
-
只有false才能代码逻辑假,数字0和nil不能(只有false/true才能表示逻辑真假,数字不能代表逻辑值)
```go
package main
import "fmt"
func main() {
//if 0 {
// fmt.Println("hello")
//}
//if nil {
// fmt.Println("hello")
//}
if true {
fmt.Println("hello")
}
//a, b := 1, 2
//x := a > b ? 0:-1
}
```
5. 字符串string
```go
package main
import "fmt"
func main() {
//1- 定义
name := "duke"
//需要换行,原生输出字符串时,使用反引号``
usage := `./a.out <option>
-h help
-a xxxx`
//c语言使用单引号 + \来解决
fmt.Println("name :", name)
fmt.Println("usage :", usage)
//2. 长度,访问
//C++: name.length
//GO: string没有.length方法,可以使用自由函数len()进行处理
//len: 很常用
l1 := len(name)
fmt.Println("l1:", l1)
//不需要加()
for i := 0; i < len(name); i++ {
fmt.Printf("i: %d, v: %c\n", i, namei)
}
//3-拼接
i, j := "hello", "world"
fmt.Println("i+j=", i+j)
//使用const修饰为常量,不能修改
const address = "beijing" //在编译期就确定了类型,是预处理,所以不需要推导
const test = 100
//address = "上海"
fmt.Println("address:", address)
//可以直接对比字符串,使用ASCII的值进行比较
if i > j {
;
}
}
```
05 string
5. 定长数组
```go
package main
import "fmt"
func main() {
//1-定义,定义一个具有10个数字的数组
//c语言定义: int nums10 ={1,2,3,4}
//go语言定义:
// nums := 10int{1,2,3,4} (常用方式)
// var nums = 10int{1,2,3,4}
// var nums 10int = 10int{1,2,3,4}
nums := 10int{1, 2, 3, 4,0,0,0,0}
//2-遍历,方式一
for i := 0; i < len(nums); i++ {
fmt.Println("i:", i, ", j:", numsi)
}
//方式二: for range ===> python支持
//key是数组下标,value是数组的值
for key, value := range nums {
//key=0, value=1 => nums0
value += 1
//value全程只是一个临时变量,不断的被重新赋值,修改它不会修改原始数组
fmt.Println("key:", key, ", value:", value, "num:", numskey)
}
//在go语言中,如果想忽略一个值,可以使用_
//如果两个都忽略,那么 就不能使用 := ,而应该直接使用 =
for _, value := range nums {
fmt.Println("_忽略key, value:", value)
}
//不定长数组定义
//3-使用make进行创建数组
}
```
06 定长数组-forrange
6. 不定长数组(切片、slice)
切片:slice,它的底层也是数组,可以动态改变长度
- 切片1:
```go
package main
import "fmt"
func main() {
//切片:slice,它的底层也是数组,可以动态改变长度
//定义一个切片,包含多个地名
//names := 10string{"北京", "上海", "广州", "深圳"}
names := \[\]string{"北京", "上海", "广州", "深圳"}
for i, v := range names {
fmt.Println("i:", i, "v:", v)
}
names1 := append(names, "海南")
fmt.Println("names:", names)
fmt.Println("names1:", names1)
fmt.Println("追加元素前,name的长度:", len(names), ",容量:", cap(names))
names = append(names, "海南")
//fmt.Println("names追加元素后赋值给自己:", names)
fmt.Println("追加元素后,name的长度:", len(names), ",容量:", cap(names))
names = append(names, "西藏")
fmt.Println("追加元素后,name的长度:", len(names), ",容量:", cap(names))
//2.对于一个切片,不仅有'长度'的概念len(),还有一个'容量'的概念cap()
nums := \[\]int{}
for i := 0; i < 50; i++ {
nums = append(nums, i)
fmt.Println("len:", len(nums), ", cap:", cap(nums))
}
}
```
!1585895660673(assets/1585895660673.png)
小结:
-
可以使用append进行追加数据
-
len获取长度,cap获取容量
-
如果容量不足,再次追加数据时,会动态分配2倍空间
07 动态数组追加元素
- ==切片2:==
```go
package main
import "fmt"
func main() {
names := 7string{"北京", "上海", "广州", "深圳", "洛阳", "南京", "秦皇岛"}
//想基于names创建一个新的数组
names1 := 3string{}
names10 = names0
names11 = names1
names12 = names2
//切片可以基于一个数组,灵活的创建新的数组
names2 := names0:3 //左闭右开
fmt.Println("names2:", names2)
names22 = "Hello"
fmt.Println("修改names2之后, names2:", names2)
fmt.Println("修改names2之后, names:", names)
//1. 如果从0元素开始截取,那么冒号左边的数字可以省略
names3 := names:5
fmt.Println("name3:", names3)
//2. 如果截取到数组最后一个元素,那么冒号右边的数字可以省略
names4 := names5:
fmt.Println("name4:", names4)
//3. 如果想从左至右全部使用,那么冒号左右两边的数字都可以省略
names5 := names:
fmt.Println("name5:", names5)
//4. 也可以基于一个字符串进行切片截取 : 取字符串的字串 helloworld
sub1 := "helloworld"5:7
fmt.Println("sub1:", sub1) //'wo'
//5. 可以在创建空切片的时候,明确指定切片的容量,这样可以提高运行效率
//创建一个容量是20,当前长度是0的string类型切片
//make的时候,初始的值都是对应类型的零值 : bool ==> false, 数字==> 0, 字符串 ==> 空
str2 := make(\[\]string, 10, 20) //第三个参数不是必须的,如果没填写,则默认与长度相同
fmt.Println("str2:", &str20)
fmt.Println("str2: len:", len(str2), ", cap:", cap(str2))
str20 = "hello"
str21 = "world"
//6.如果想让切片完全独立于原始数组,可以使用copy()函数来完成
namesCopy := make(\[\]string, len(names))
//func copy(dst, src \[\]Type) int
//names是一个数组,copy函数介收的参数类型是切片,所以需要使用:将数组变成切片
copy(namesCopy, names:)
namesCopy0 = "香港"
fmt.Println("namesCopy:", namesCopy)
fmt.Println("naemes本身:", names)
}
```
08 切片截取-copy-make介绍
!1585898372086(assets/1585898372086.png)
7.字典(map)
哈希表 , key=>value, 存储的key是经过哈希运算的
```go
package main
import "fmt"
func main() {
//1. 定义一个字典
//学生id ==> 学生名字 idNames
var idNames mapintstring //定义一个map,此时这个map是不能直接赋值的,它是空的
idNames0 = "duke"
idNames1 = "lily"
for key, value := range idNames {
fmt.Println("key:", key, ", value:", value)
}
}
```
!1585898733163(assets/1585898733163.png)
- 使用map之前,一定要对map进行分配空间
```go
package main
import "fmt"
func main() {
//1. 定义一个字典
//学生id ==> 学生名字 idNames
var idNames mapintstring //定义一个map,此时这个map是不能直接赋值的,它是空的
//2. 分配空间,使用make,可以不指定长度,但是建议直接指定长度,性能更好
idScore := make(mapintfloat64) //这个也是正确的
idNames = make(mapintstring, 10) //建议使用这种方式
//3. 定义时直接分配空间
//idNames1 := make(mapintstring, 10) //这是最常用的方法
idNames0 = "duke"
idNames1 = "lily"
//4. 遍历map
for key, value := range idNames {
fmt.Println("key:", key, ", value:", value)
}
//5. 如何确定一个key是否存在map中
//在map中不存在访问越界的问题,它认为所有的key都是有效的,所以访问一个不存在的key不会崩溃,返回这个类型的零值
//零值: bool=》false, 数字=》0,字符串=》空
name9 := idNames9
fmt.Println("name9:", name9) //空
fmt.Println("idScore100:", idScore100) //0
//无法通过获取value来判断一个key是否存在,因此我们需要一个能够校验key是否存在的方式
value, ok := idNames1 //如果id=1是存在的,那么value就是key=1对应值,ok返回true, 反之返回零值,false
if ok {
fmt.Println("id=1这个key是存在的,value为:", value)
}
value, ok = idNames10
if ok {
fmt.Println("id=10这个key是存在的,value为:", value)
} else {
fmt.Println("id=10这个key不存在,value为:", value)
}
//6. 删除map中的元素
//使用自由函数delete来删除指定的key
fmt.Println("idNames删除前:", idNames)
delete(idNames, 1) //"lily"被kill
delete(idNames, 100) //不会报错
fmt.Println("idNames删除后:", idNames)
//并发任务处理的时候,需要对map进行上锁 //TODO
}
```
!1585899844151(assets/1585899844151.png)
09 map介绍
8. 函数
```go
package main
import "fmt"
//2.如果有多个返回值,需要使用圆括号包裹,多个参数之间使用,分割
func test2(a int, b int, c string) (int, string, bool) {
return a + b, c, true
}
func test3(a, b int, c string) (res int, str string, bl bool) {
var i, j, k int
i = 1
j = 2
k = 3
fmt.Println(i, j, k)
//直接使用返回值的变量名字参与运算
res = a + b
str = c
bl = true
//当返回值有名字的时候,可以直接简写return
return
//return a + b, c, true
}
//如果返回值只有一个参数,并且没有名字,那么不需要加圆括号
func test4() int {
return 10
}
func main() {
v1, s1, _ := test2(10, 20, "hello")
fmt.Println("v1:", v1, ",s1:", s1)
v3, s3, _ := test3(20, 30, "world")
fmt.Println("v3:", v3, ", s3:", s3)
}
```
10 函数
内存逃逸:
```go
package main
import "fmt"
func main() {
p1 := testPtr1()
fmt.Println("*p1:", *p1)
}
//定义一个函数,返回一个string类型的指针, go语言返回写在参数列表后面
func testPtr1() *string {
name := "Duke"
p0 := &name
fmt.Println("*p0:", *p0)
city := "深圳"
ptr := &city
return ptr
}
```
```go
go build -o test.exe --gcflags "-m -m -l" 11-内存逃逸.go > 1.txt 2>&1
grep -E "name|city" 1.txt --color
```
!1585902031122(assets/1585902031122.png)
9. import
创建目录结构:
!1585903432739(assets/1585903432739.png)
add.go
```go
package add
func add(a, b int) int {
return a + b
}
```
sub.go
```go
package sub
//在go语言中,同一层级目录,不允许出现多个包名
func Sub(a, b int) int {
test4() //由于test4与sub.go在同一个包下面,所以可以使用,并且不需要sub.形式
return a - b
}
```
11 内存逃逸
utils.go
```go
package sub
//package utils //不允许出现多个包名
import "fmt"
func test4() {
fmt.Println("this is test4() in sub/utils!")
}
```
main.go
```go
package main
import (
SUB "12-import/sub" //SUB是我们自己重命名的包名
//"12-import/sub" //sub是文件名,同时也是包名
. "12-import/sub" //.代表用户在调用这个包里面的函数时,不需要使用包名.的形式,不见一使用的
"fmt"
)
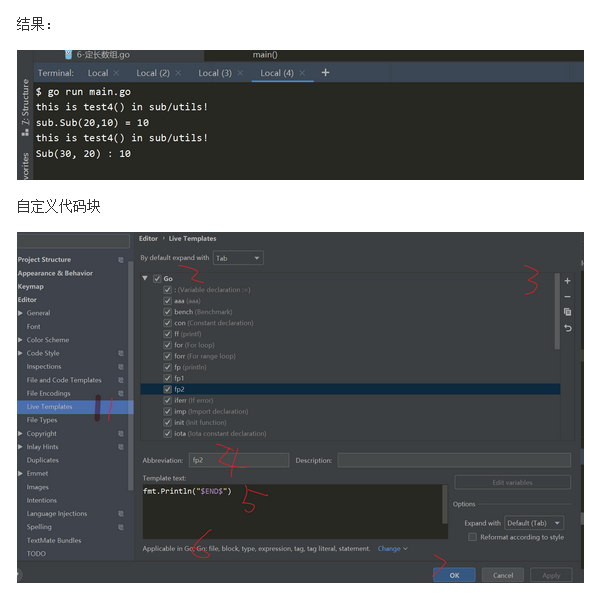
func main() {
//res := sub.Sub(20, 10) //包名.函数去调用
res := SUB.Sub(20, 10) //包名.函数去调用
fmt.Println("sub.Sub(20,10) =", res)
res1 := Sub(30, 20)
fmt.Println("Sub(30, 20) :", res1)
//这个无法被调用,是因为函数的首写字母是小写的
//如果一个包里面的函数想对外提供访问权限,那么一定要首写字母大写,
// 大写字母开头的函数相当于 public,
// 小写字母开头的函数相当于 private, 只有相同包名的文件才能使用
//add.add(10,20)
}
```
结果:
!1585903519834(assets/1585903519834.png)
12 import
13 命令行参数-switch
- 案例:递归遍历指定目录的文件!
```sh
#!/bin/bash
#案例:递归遍历指定目录的文件!
#目录由用户通过命令行传入:
#./recursive.sh ..
recursive()
{
#接收用户输入的目录
#currDir="$1"
local currDir="$1"
echo "====> 当前目录为:" "$currDir"
#遍历当前目录
for i in `ls $currDir`
do
#这样才是有效的路径,后续才能正确判断性质
#item="currDir+"/"+i" <<=== 这是错误的, /usr/+/+test.txt
item="currDir/i"
#echo "item: " $item
#如果i是文件,则打印
if -f "$item" ; then
echo "文件找到: $item"
elif -d "$item" ;then
#如果i是文件夹,则递归遍历
echo "文件夹找到:" "$item"
recursive $item
else
echo "未知文件:" "$item"
fi
done
}
14 标签与continue-goto-break配合使用
#判读输入参数的个数
if $# -ne 1 ;then
echo "Usage: recursive <文件目录>"
exit
fi
recursive $1
```
调试
shell调试参数:
-
-n 帮助我们快速检查脚本的语法,而不是逐条执行
-
脚本如果很大,中间执行过程很长,如果不能实现发现脚本错误,会浪费时间
-
```sh
bash -n ./recursive.sh
```
-
!1585713051107(assets/1585713051107.png)
-
-x,执行脚本的同时将代码执行过程打印到屏幕,便于追踪
-
bash -x recursive.sh ==》 作用于整个脚本
-
可以在代码中,对指定的代码段进行调试
-
set -x ==> 启动调试
-
xxxx
-
set +x ==> 停止调试
!1585713439412(assets/1585713439412.png)
- -v,一边执行脚本,一边打印错误输出(很少用)
shift 8 ==> *, 快速定位当前光标所值单词(向下寻找,n)
shift 3 ==> #, 快速定位当前光标所值单词(向上寻找,n)
15 枚举const-iota
三、正则表达式
-
以S开头的字符串
-
^: 可以限定一个字符开头
-
```sh
目标:ShelloShello world
表达式:^Shello
```
-
以数字结尾的字符串
-
$:可以限定结尾
-
表示数字方式:
-
0123456789
-
0-9
-
```sh
目标:helloworld9
表达式:helloworld0-9$
```
-
匹配空字符串(没有任何字符)
-
^$
-
字符串只包含三个数字
-
三个数字:\0-9\\\0-9\\\0-9\\
-
字符串只有3到5个字母
-
字母表示:
-
a-zA-Z, 中间不要加空格
-
三个到五个字母:a-zA-Z{3,5}
-
重复次数{m, n}:
-
匹配前面修饰字符的次数,最少m次,最多n次
-
匹配不是a-z的任意字符
-
^ 在\[\]内部的时候,表示取反(注意,不是限定开头)
-
^\^0-9\\ : 以非数字开头的字符
-
内反,外头
-
\^a-z\\ <<<===
-
字符串有0到1个数字或者字母或者下划线
-
表示0-1的方法
-
{0,1}
-
? : 表示0,1个
-
a-zA-Z0-9_?
-
```sh
内容
hello
hello1
hello*
正则:
helloa-zA-Z0-9_?
匹配结果:
hello
hello1
hello
```
16 结构体基本语法
-
字符串有1个或多个空白符号(\t\n\r等)
-
\s ==》 代表空格
-
+:一个或多个
-
```h
内容:hello world
正则:hello\s+world
结果:hello world
```
-
字符串有0个或者若干个任意字符(除了\n)
-
.: 点,代表任意字符,除了\n
-
*:星号,重复前一个字符0-n次
-
匹配任意字符,任意次数:通常做法,是: .* ==> 相当于通配符里面的 *
-
```sh
内容:hello asdfaasdfasdfadfasdfasdf asdfasdfasdf world
正则:hello.*world
结果:hello asdfaasdfasdfadfasdfasdf asdfasdfasdf world
```
-
.{,} ==> 与 .*效果相同
-
小结:
-
? ===> 重复前面一个字符0-1
-
\+ ===> 重复前面一个字符1-n
-
\* ===> 重复前面一个字符0-n
-
. ===> 表示任意字符
-
^ ===> 限定以某个字符开头
-
\^a-z ===> 在方括号内,表示取反(非a-z的任意字符)
-
$ ===> 限定以某个字符结尾
-
数字 ====》 0123456789 或0-9
-
字母 ===> abcd a-zA-Z
-
匹配0或任意多组ABC,比如ABC,ABCABCABC
-
使用()进行分组,组成新的匹配单元
-
(ABC)*
-
字符串要么是ABC,要么是123
-
(ABC|123)
-
```sh
内容:
ABC
ABCABCABCD
123456
hellowlrd
正则:(ABC|123)
```
17 init函数
-
字符串只有一个点号
-
^\\.$
-
匹配十进制3位整数 :
-
0~999 , 5, 10 , 200, 999
-
分段匹配:
-
一位数:
-
0-9
-
二位数:
-
1-9\]\\\[0-9\\
-
三位数:
-
\1-9\\0-9{2}
-
整合:
-
^ (0-9|1-9\0-9\\{1,2})$
-
匹配0-255的整数, ip地址
-
分段
-
一位:0-9
-
二位:1-9\0-9\\
-
三位:
-
100- 199
-
10-9{2}
-
200-249
-
20-4\0-9\\
-
250-255
-
250-5
- 整合:
-
`^((0-9|1-90-9|10-9{2}|20-40-9|250-5)\.){3}(0-9|1-90-9|10-9{2}|20-40-9|250-5)$`
-
192.168.1.1
-
匹配端口号
-
0~65536
-
email
```sh
\\w!#$%\&'\*+/=?\^_\`{\|}\~-+(?:\.\\w!#$%\&'\*+/=?\^_\`{\|}\~-+)*@(?:\\w(?:\\w-*\\w)?\.)+\\w(?:\\w-*\\w)?
```
18 defer-文件读取-匿名函数
三种正则表达式:
-
基础正则:(不使用) ==》 +?* 都当成普通字符来处理
-
扩展正则:(我们默认使用这个)==》 +?* 当成特殊字符
-
Perl正则:
-
+?*是特殊字符
-
\d ==》 数字 0-9
-
\w ==> 字符a-zA-Z
-
用法\d{3}\w 可以匹配:212c
四、其他命令
sort(排序)
```sh
-f 忽略字符大小写
-n 按照数值比较
-t 分割字符
-k 指定分割之后比较的字段
-u 只显示一次
-r 反向排序
```
使用:分割之后,截取第三段,以数字的值进行比较,反向打印
```sh
sort passwd -t: -k3 -n -r
```
uniq(删除重复)
uniq.txt
```sh
xiaoliu 99 man 25
xiaowen 98 man 24
xiaoliu 99 man 25
```
去重方式,需要重复的两行挨着才能去重,一般和sort配合使用
```sh
cat uniq.txt | sort | uniq
```
!1585728928962(assets/1585728928962.png)
wc
-l: 统计文件的行数 <==最常用
-c:统计字符
-w:统计单词数量