什么是RAG
RAG(检索增强生成)是一种将语言模型与可搜索知识库结合的方法,主要包含以下关键步骤:
-
数据预处理
- 加载:从不同格式(PDF、Markdown等)中提取文本
- 分块:将长文本分割成短序列(通常100-500个标记),作为检索单元
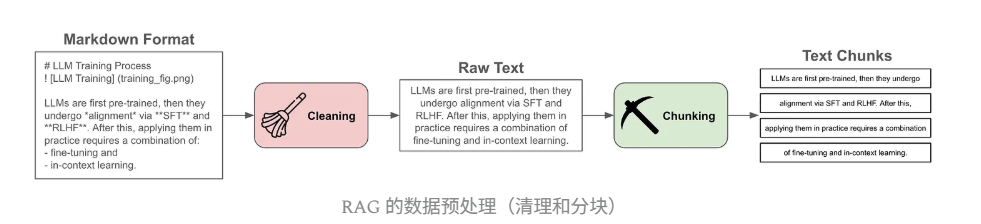
-
检索系统构建
- embedding:使用embedding模型为每个文本块生成向量表示
- 存储:将这些向量索引到向量数据库中
- 可选-重排:结合关键词搜索构建混合搜索系统,并添加重排序步骤
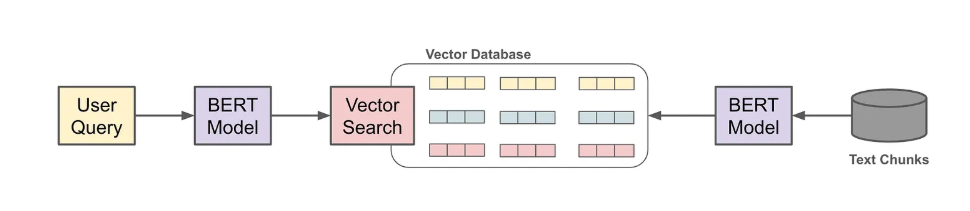
-
查询处理流程
- 接收用户查询并评估其相关性
- 对查询进行嵌入,在向量库中查找相关块
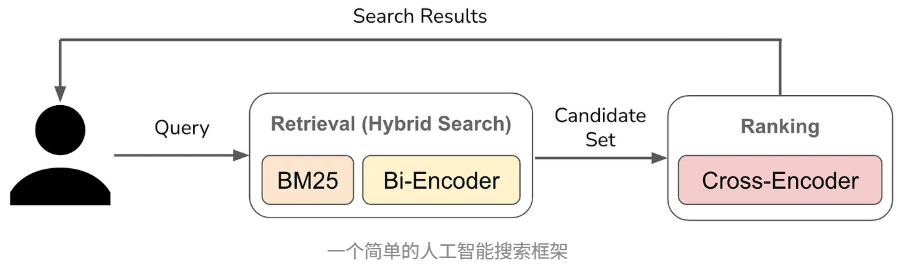
-
生成输出
- 将检索到的相关内容与原始查询一起传递给LLM
- LLM根据这些上下文信息生成更准确、更符合事实的回答
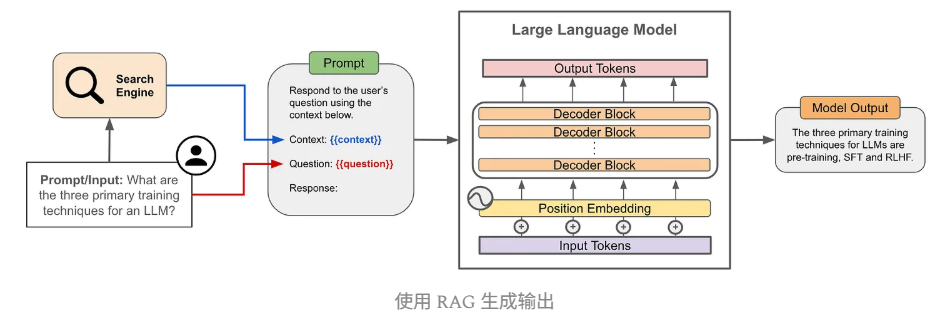
RAG的核心价值在于通过非参数数据源为模型提供正确、具体且最新的信息,从而改进传统LLM的回答质量。
RAG vs 超长上下文
随着模型如Claude、GPT-4和Gemini 1.5等能够处理高达100万tokens甚至200万tokens的输入,业界开始思考一个关键问题:在如此长的上下文支持下,我们未来是否还需要检索增强生成(RAG)技术。
下表将会对比RAG与超长文本优缺点
| 特点 | 超长上下文 | RAG技术 | 实际影响 |
|---|---|---|---|
| 成本 | ⚠️ 高 | ✅ 低 | 200万tokens API调用vs.数千tokens |
| 安全性 | ⚠️ 全部暴露 | ✅ 按需暴露 | 敏感信息保护程度 |
| 检索精度 | ⚠️ 随文档长度降低,AI对更近的文本记忆力更好 | ✅ 相对稳定 | 问答准确率差异 |
| 容量限制 | ⚠️ 有上限(~200万tokens) | ✅ 基本无限 | 可处理知识库规模 |
RAG综合实操
由于本系列已经提到有关RAG的各个细节理论与代码,因此这里有些细节不再重复。
RAG入门篇
环境准备
本机Ollama需要下载了模型ollama run deepseek-r1:7b
python
# 安装必要依赖
pip install langchain langchain-community chromadb beautifulsoup4 sentence-transformers langchain-ollama一个RAG分为一下5个部分
- 加载: 通过
document_loaders完成数据加载 - 分割:
text_splitter将大型文档分割成更小的块,便于索引和模型处理 - 存储: 使用
vectorstores和embeddings模型存储和索引分割的内容 - 检索: 使用
RetrievalQA基于用户输入,使用检索器从存储中检索相关分割 - 生成:
llms使用包含问题和检索数据的提示生成答案
python
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.llms import Ollama
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
loader = WebBaseLoader("https://blog.csdn.net/ngadminq/article/details/147687050")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
chunks = text_splitter.split_documents(documents)
embedding_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh"
)
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embedding_model,
persist_directory="./chroma_db"
)
# 创建检索器
retriever = vectorstore.as_retriever()
template = """
根据以下已知信息,简洁并专业地回答用户问题。
如果无法从中得到答案,请说"我无法从已知信息中找到答案"。
已知信息:
{context}
用户问题:{question}
回答:
"""
prompt = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
#
llm = Ollama(model="deepseek-r1:7b") # 本地部署的模型
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs={"prompt": prompt}
)
question = "图灵的论文叫什么?"
result = qa_chain.invoke({"query": question})
print(result["result"])