An Image is Worth 16x16 Words
20年的论文看成10年的哈斯我了



为什么transformer好训练,transformer很好训练吗

为什么 transformer性能不会饱和







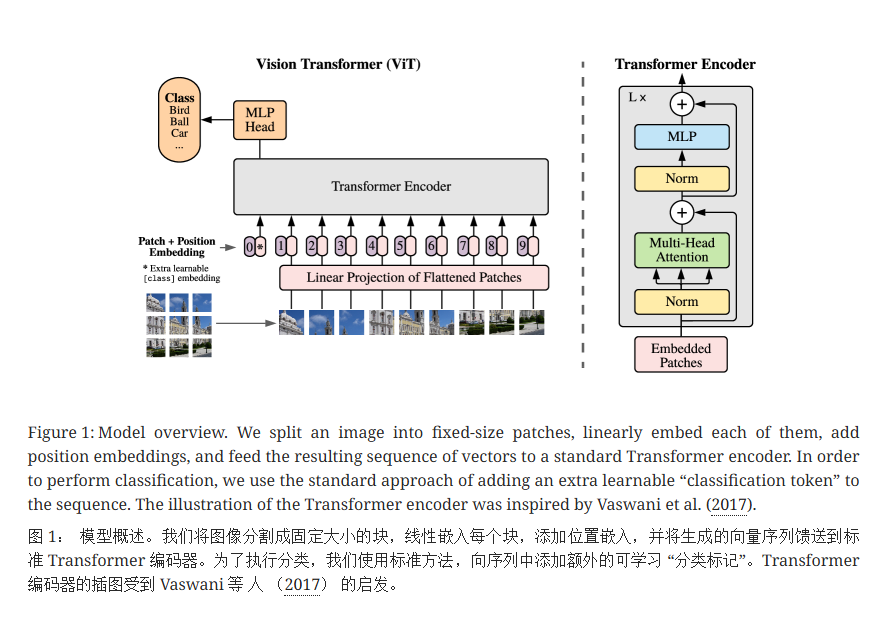


 Vision Transformer是什么,能干嘛
Vision Transformer是什么,能干嘛

比如说我三视图有一个圆柱和一个立方体 Vision Transformer能识别出正方体的长宽高信息和圆柱体的直径和高度信息吗
 他不是有注意力吗,我能不能让他分开的几个区域算作一个东西
他不是有注意力吗,我能不能让他分开的几个区域算作一个东西
