一、我们先来回忆一下在transformer中KV在哪里出现过,都有什么作用?

α的计算过程:
这里引入三个向量:
图中的q为Query,用来匹配key值
图中的k为key,用来被Query匹配
图中的Value,是用来被进行加权平均的
由
这一步我们知道α就是K与Q的匹配程度,匹配程度越高则权重越大。
Wq、Wk、Wv这三个参数矩阵都需要从训练数据中学习


二、为什么要使用KV缓存
使用KV缓存是为减少生成token时候的矩阵运算。
因为在transformer中文本是逐个token生成的,每次新的预测会基于之前生成的所有token的上下文信息,这种对顺序数据的依赖会减慢生成过程,因为每次预测下一个token都需要重新处理序列中所有之前的token。
比说我们要预测第100个token,那么模型必须使用前面99个token的信息,这就需要对这些token做矩阵运算,而这个矩阵运算是非常耗时的。所以KV缓存就是为了减少这种耗时的矩阵运算,在推理过程中会把键和值放在缓存中,这样模型就可以在后续生成token的时候,直接访问缓存,而不需要重新计算。
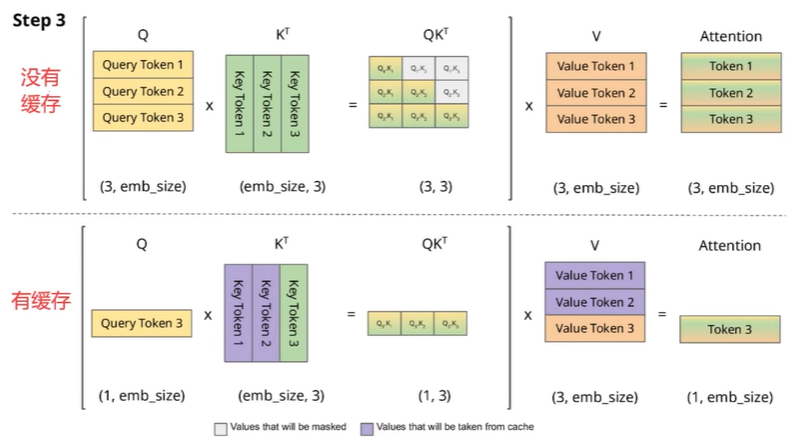
三、KV缓存具体是怎么实现的?
这两张图分别是有缓存和没有缓存的情况
因为是第一个token,所以有没有缓存计算过程没有差别
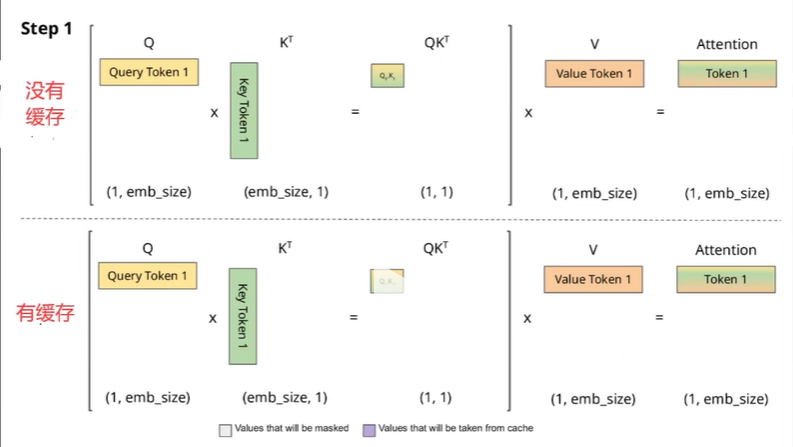
接下来到第二个token时,可以看到紫色标出的就是缓存下来的key和value,在没有缓存的情况下KV都要重新计算。如果做了缓存就只需要把历史的KV拿出来,同时只计算最新的那个token的KV再拼接成一个大矩阵就行了。
对比一下,有缓存的计算量明显减少了一半
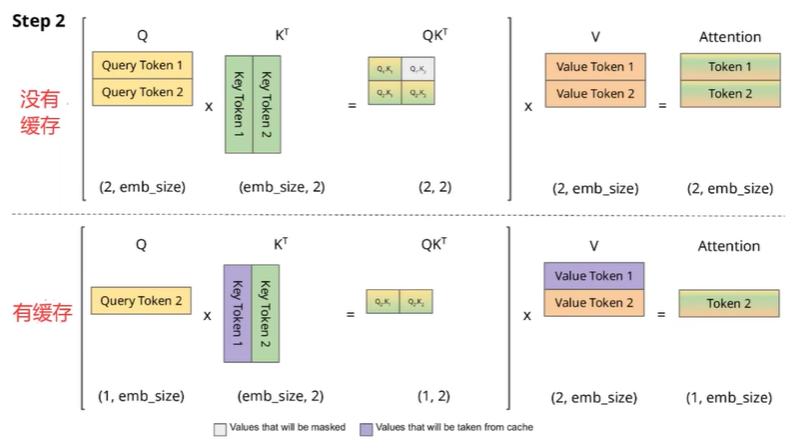
那后面的token一样,每次历史计算过的键和值就不用重新计算了,这样就极大减少了self attention 的计算量,从序列长度的二次方直接变成了线性