简述
在视频中跟踪一个点(比如一个物体的某个特定位置)听起来简单,但实际上很复杂,尤其是在3D空间中。传统方法通常在2D图像上跟踪像素,但这忽略了物体的3D几何信息和摄像机的运动,导致跟踪不稳定,尤其是在长时间的视频中。TAPIP3D提出了一种新方法,通过结合视频的深度信息(RGB-D视频)和摄像机运动,把2D像素"抬升"到3D空间,形成一个稳定的3D点云,然后在这个3D空间中进行点跟踪。核心思想是把点跟踪问题变成一个迭代优化的过程,确保跟踪的点在3D空间中始终准确且连贯。
论文
TAPIP3D: Tracking Any Point in Persistent 3D Geometry 论文地址在
简述
"对于人类来说,跟踪视频中的每个像素是轻而易举的,但对机器来说仍然具有挑战性。在粒子级别进行细粒度运动估计,为模拟物体、其组件、可变形结构和颗粒材料的时间变化提供了一个统一的接口。由于摄像机运动和动态场景变化导致的遮挡,这项任务具有挑战性。然而,它是计算机视觉中的一个基础问题,在增强现实和机器人技术中有广泛的应用37。例如,点跟踪最近被用作机器人学习策略的子目标表示2, 46,使用深度传感摄像机。
*共同贡献。
早期运动估计方法,如光流,专注于估计相邻帧之间的运动。最近的方法如PIPs 13和CoTracker17, 18通过预测2D点轨迹来解决多帧像素跟踪问题,即使在遮挡的情况下也能追踪点。这些方法的核心是推断查询轨迹点与通过卷积网络计算的2D图像特征的2D相关性图,然后迭代地从这些相关性图中提取局部块,以提供如何改进轨迹的方向性提示,并结合从跨轨迹和轨迹内注意操作中提取的隐含信息。"
论文提到, 在处理复杂变形和大范围相机移动时轨迹追踪,这种困难的一个潜在原因源于在2D图像空间中估计像素运动,而不是在3D中进行估计44。由于物理实体的真实运动发生在3D中,在3D空间中表示和跟踪点可能会比在图像平面上更容易。此外,在3D空间中表示特征相对于2D特征化具有优势。在图像空间中,相机投影将空间上远离的区域拉近,导致误导性的特征相关。相反,3D表示保留真实的空间关系,减少模棱两可性并提高跟踪精度。
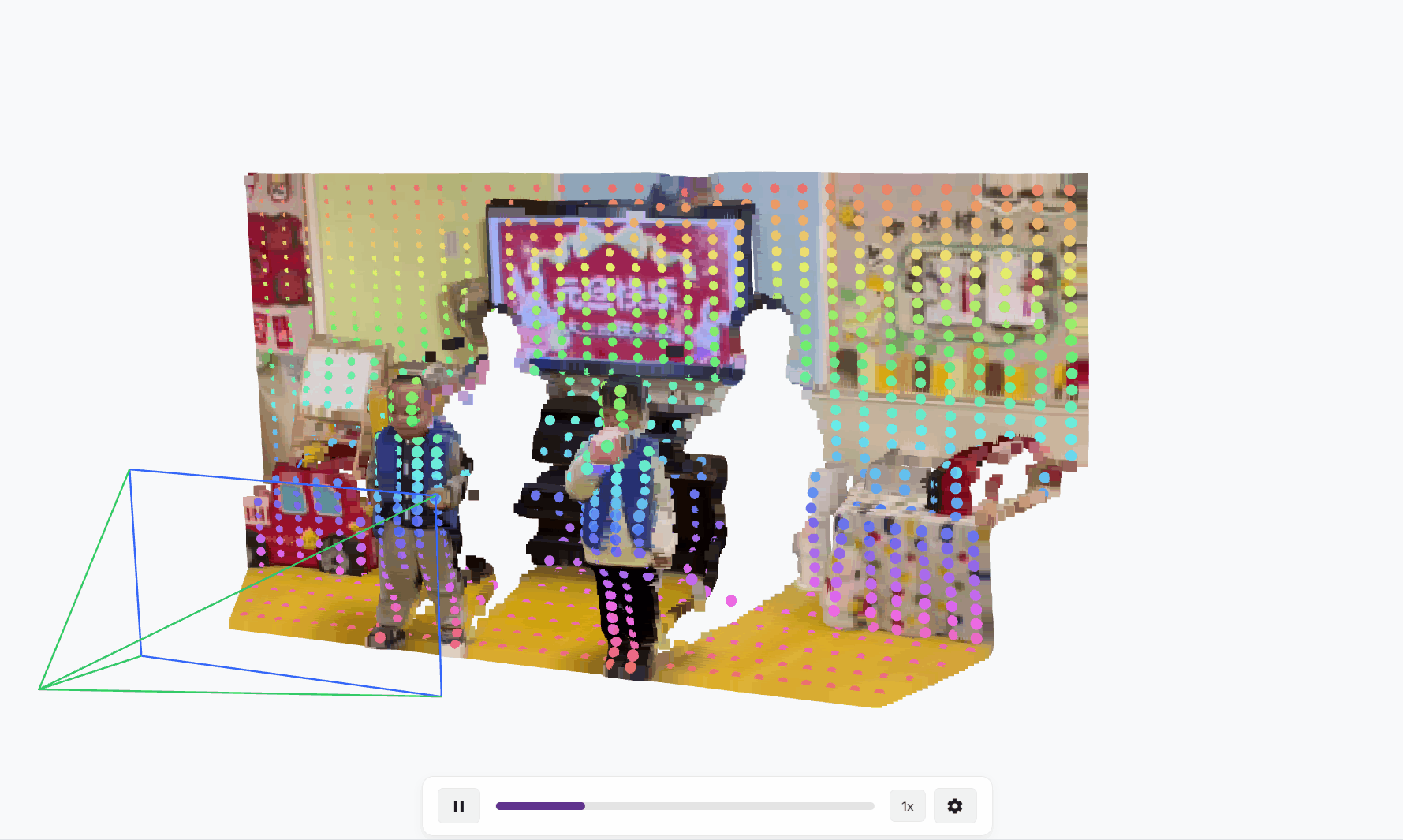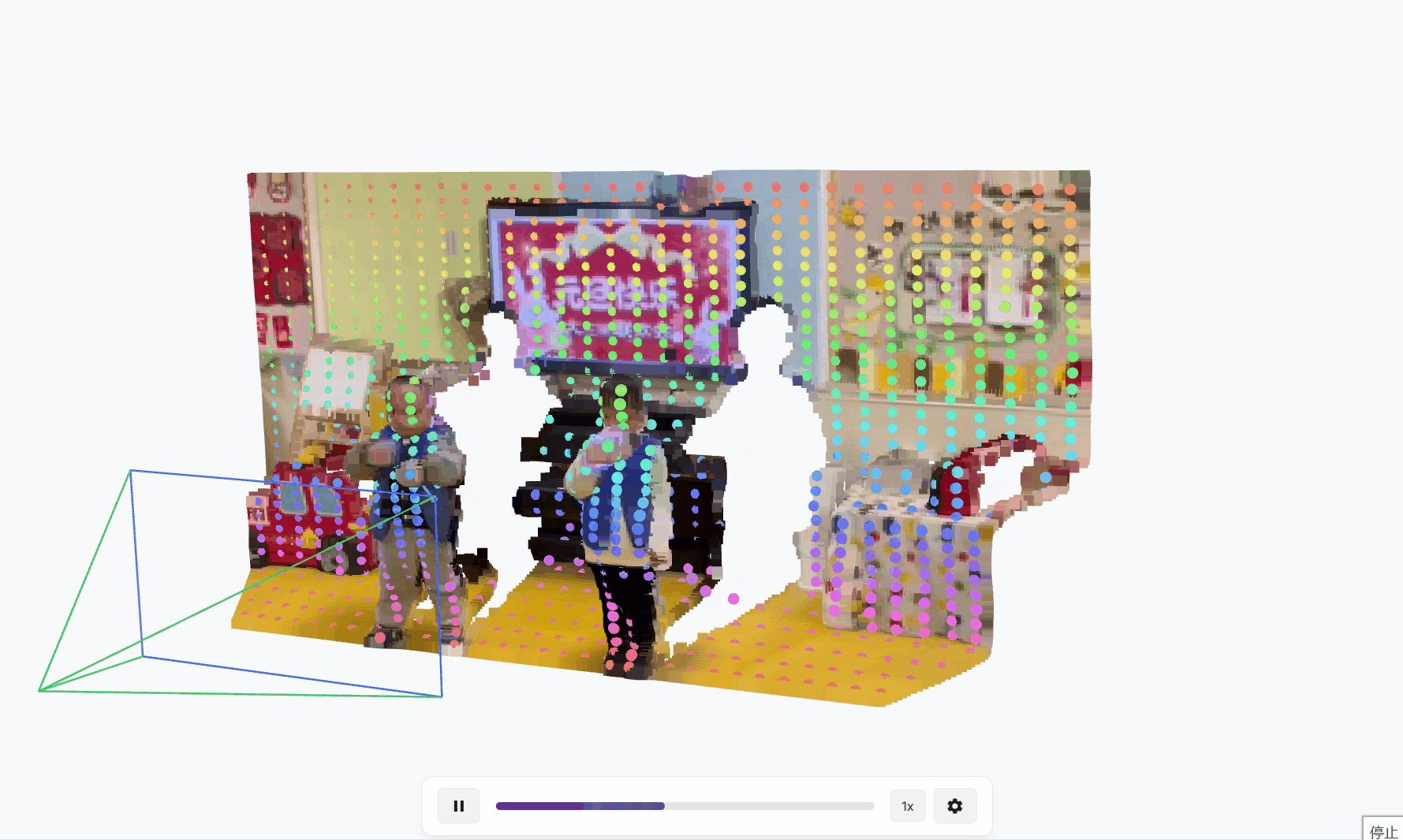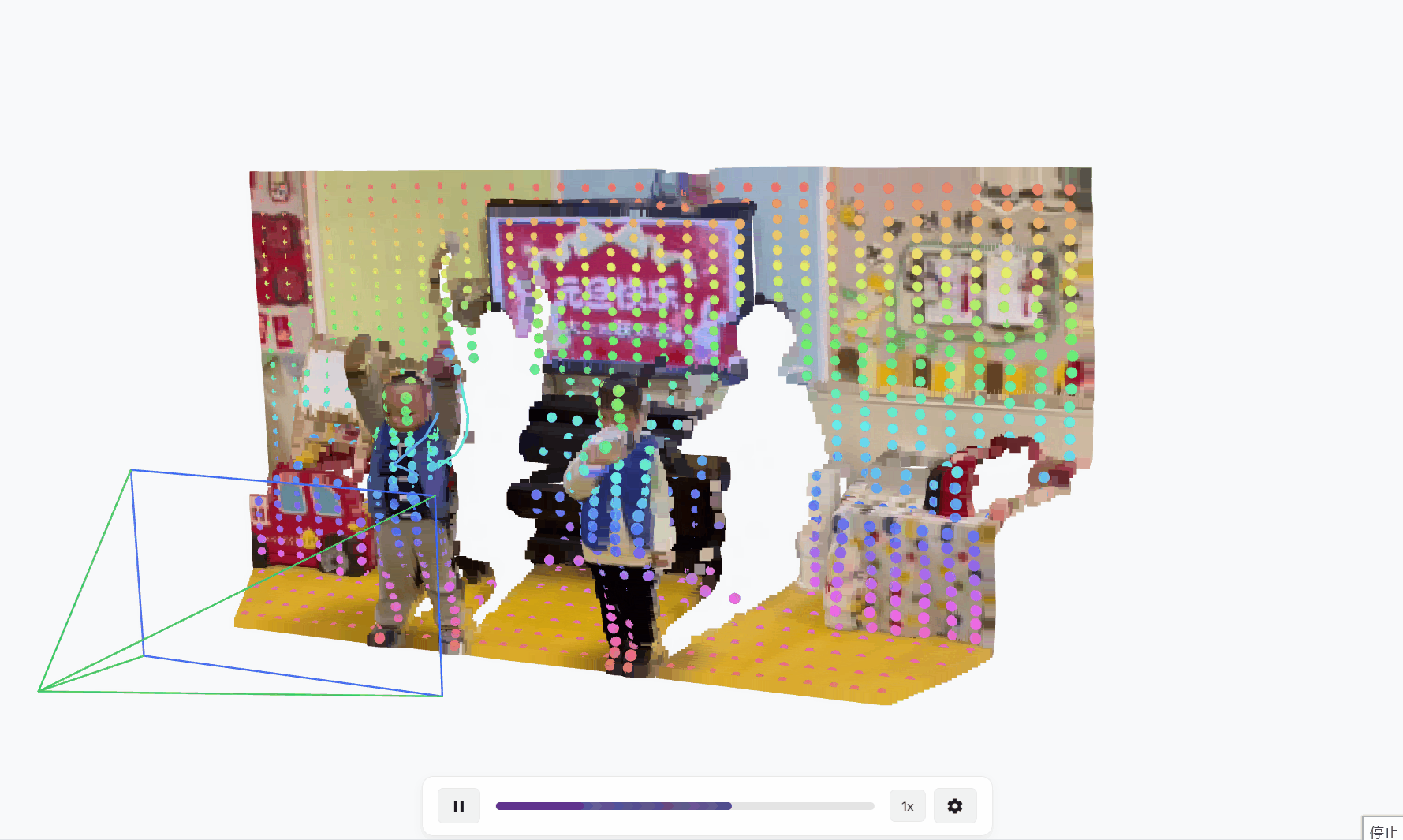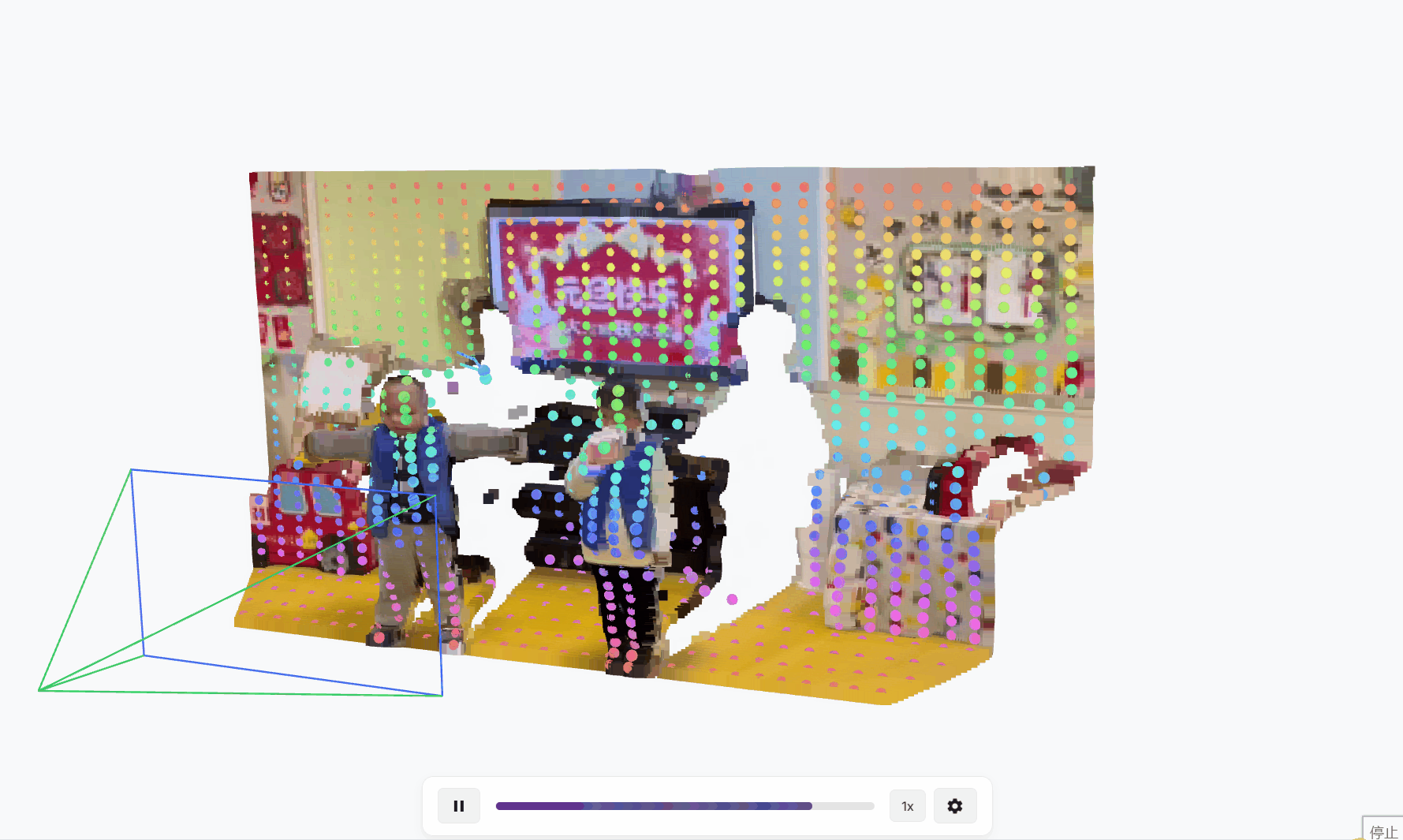
TAPIP3D用于跟踪任意点的持久3D几何体,这是一种3D点跟踪方法,通过空间时间注意力来表示和迭代更新多帧3D像素运动轨迹,RGB-D视频。我们的方法将视频表示为时空3D特征云。云中的每个点代表一个2D特征向量,通过感知或估计的深度提升到相应的3D坐标(X, Y, Z)。在未知的摄像机运动下,我们使用摄像机外参来推断一个世界中心的3D特征图,通过从视频观测中移除摄像机运动,如图1所示。我们的方法在摄像机或世界3D特征空间中进行跟踪,通过直接使用3D注意力来特征化场景坐标。具体来说,它识别每个查询轨迹坐标的局部3D邻域作为查询组,并用一种新的局部对配注意力设计替换传统的2D卷积神经网络。这种机制使得在给定时间步长的查询点组的深层特征表示能够关注未来时间步长的关键点组的特征,即其相邻的3D点。此外,在这些对配注意力中,我们将查询轨迹点与邻近目标点之间的3D相对偏移结合到注意力值中,同时结合外观特征,从而增强空间上下文意识。
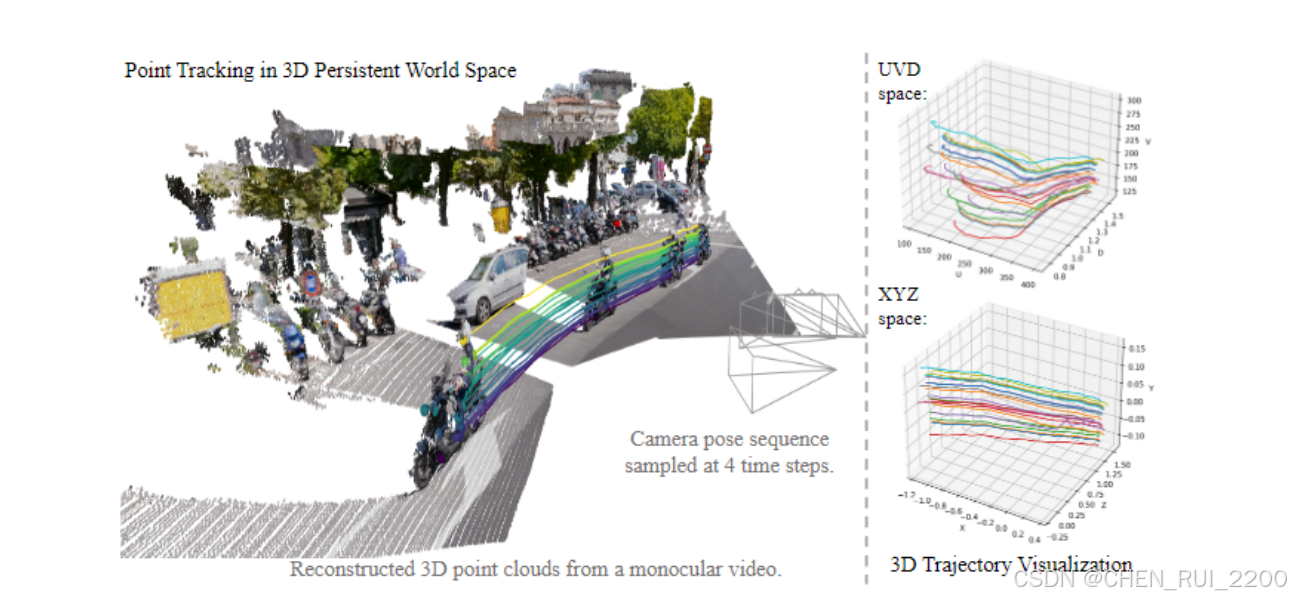
TAPIP3D 在持久的 3D 世界空间中对 3D 特征云进行长期 3D 点跟踪,这超过了先前在相机依赖的 UV 像素 + 深度(UVD)空间中运行的 3D点跟踪方法 28, 44。我们利用来自 MegaSaM 23 的给定/估计的深度图和相机姿态来计算一个相机运动被抵消的 3D 空间。TAPIP3D 设计了一个局部对注意力以进行特征提取和迭代运动估计。在 3D XYZ 世界空间中对采样的动态点的 3D 运动轨迹显著更平滑且更直线,相比于 UVD 空间
从最先进的学习相机和深度估计方法(如MegaSAM 23)估算的3D世界坐标系中进行的点跟踪,其性能优于相机框架中的跟踪,这是现有的3D点跟踪器28, 44所追求的目标。我们对我们的模型的设计选择进行了消除实验,以阐明我们的3D中心特征化、增强和深度估计质量对性能的贡献。总之,论文提出了TAPIP3D,用于从RGB-D和RGB视频中进行3D点跟踪,该方法使用3D特征云来估算3D点轨迹,当有地面真值/传感器深度时,其表现为最先进的性能,并且在估计深度23的情况下具有竞争性能。它可以利用深度和相机姿态估计的最新进展,并提供相机和世界中心的3D轨迹。
相关工作
2D和3D点跟踪近年来在点跟踪方面的进展将任务定义为多帧点轨迹的估计,超越了传统的配对光流估计。受早期粒子视频33工作的启发,PIPs 13引入了一种具有密集成本图的迭代优化方法。最近的工作如SpatialTracker 44通过引入深度信息将点跟踪扩展到3D。SpatialTracker采用三平面表示法4,将每帧来自像素(UV)和深度(D)坐标的3D特征点云投影到三个正交平面上。这种三平面特征化比我们的k-NN注意力更快,但这种加速是以性能下降为代价的。DELTA 28和SceneTracker 38的工作也在UVD坐标系下分别计算外观和深度相关特征,直接扩展了2D方法CoTracker 18。DELTA 28提出了一种粗到细的轨迹估计方法,能够在整个图像平面上估计密集的点轨迹,而不是在一组稀疏位置上。与之前的3D点跟踪器相比,TAPIP3D利用显式的时空3D点特征图视频表示,而不是2.5D的图像空间和深度,进行特征提取和跟踪。通过充分利用场景的底层几何结构,我们的方法实现了更高的点跟踪精度和一致性。此外,作为之前工作的一个重要新特性,它可以在3D世界空间中估计轨迹,通过在提升过程中从场景图像像素中消除推断的相机运动
通过重建的点跟踪3D点轨迹也可以通过测试时优化从单目视频中提取,通过拟合动态光照场(如动态NeRF 31, 39 或高斯分布 7, 27, 34, 40)来适应观察到的视频帧,并通过重投影RGB、深度和运动误差进行监督。这些方法需要针对每个视频进行优化,因此计算成本很高。相反,我们的TAPIP3D是一种基于学习的前向方法用于3D点跟踪。
场景流估计场景流估计将光流扩展到三维,通过考虑点云对并估计它们之间的3D运动11, 12, 14, 25, 29, 32, 36, 43。最近的工作纳入刚体运动先验,显式36或隐式45,或利用扩散模型24。链接3D场景流估计由于设计原因在像素遮挡处终止,类似于链接2D流估计。相反,我们的工作专注于在遮挡下推断多帧点轨迹。基于学习的3D基础模型近期在基于学习的相机运动和深度估计方面的方法,如MoGe 41、DUSt3R 42、MonST3R 47 和MegaSaM 23,专注于从单张图像、图像对或视频中预测密集的3D重建,带来了将视频向4D翻译的愿景更贴近了。MegaSAM 23 通过结合基于学习的初始化和更新与二阶优化,提供了高度准确的相机运动和深度,延伸了DROID-SLAM 35 的早期工作。上述方法中没有一个解决了估计3D点运动的问题,这是我们工作的重点。TAPIP3D 在最近的基于学习的3D相机运动和深度估计方法的进展基础上,探索其在3D点跟踪中的应用,通过将视频提升到3D世界空间,使场景点比在原始的2D图像平面中更容易跟踪。
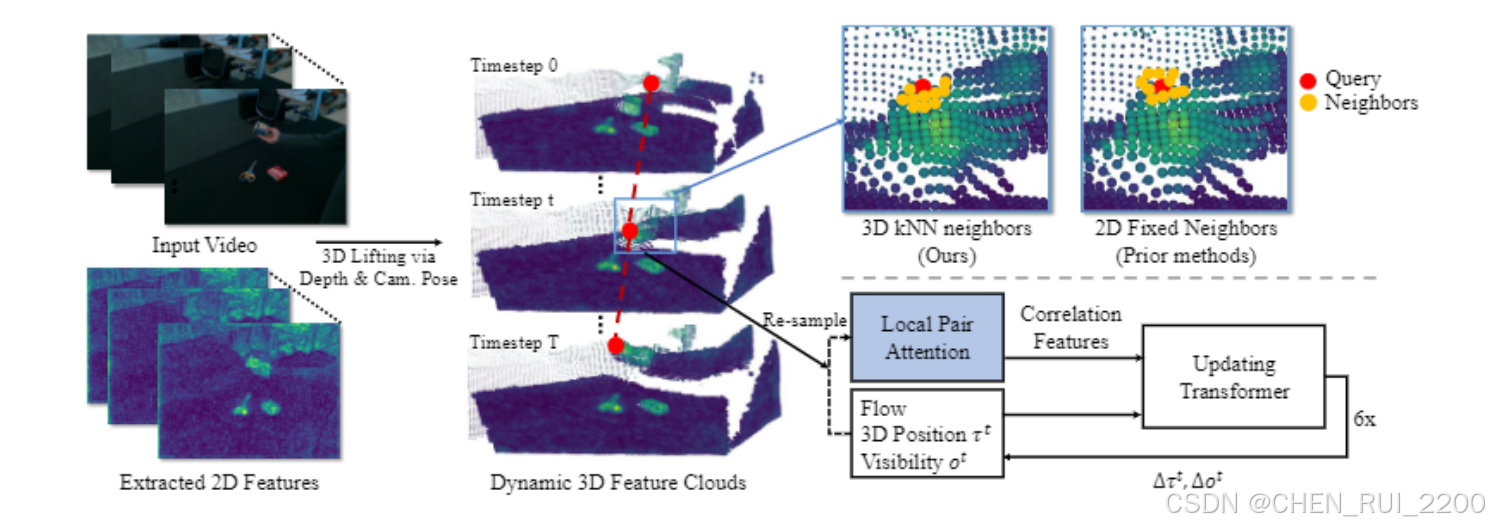
概述。TAPIP3D的架构如图2所示。TAPIP3D可以在相机或世界3D空间中跟踪RGB或RGB-D视频中的任何像素。它是一个3D变换器,通过时空注意力迭代地优化一组3D点轨迹,将其转化为一个4D(3D + 时间)视频点特征图。具体来说,它输入RGB视频V={It∈RH×W×3}Tt=1,一系列深度图D={Dt∈RH×W}Tt=1,相机内参以及一定时间内的焦距f,可选地还有相机姿态序列C={Camt∈R6}Tt=1,相对于第一帧I0的相机姿态。然后,它通过反向相机投影方程将视频像素坐标提升为3D点坐标。输入的深度图可以来源于现成的单目深度估计器41、深度传感器,或者模拟环境提供的GT深度。相机内参和外参可以通过视频3D重建模型23算法估计,或者直接由数据集提供。 给定在各自的帧tq,q=1...Q中指定的一组3D查询点Q={(Xtqq, Ytqq, Ztqq), q=1...Q},我们的模型生成具有遮挡感知的3D点轨迹τ={τq= (Xtq, Ytq, Ztq)Tt=1, q= 1...Q}和相应的可见性轨迹o={(otq)Tt=1, q= 1...Q),这些代表了查询点在时间内的3D位置和可见性。它通过迭代推理实现,在迭代中,模型以轨迹τmq为输入,通过将轨迹与视频输入结合来提取特征,并预测更新后的3D位置和可见性τm+1q,如图2所示。我们将τq用于表示2D和3D轨迹,并且上下文将指示哪一个是暗示的。我们将τtq用于表示轨迹q的像素或点位置。我们将省略表示感兴趣量属于哪个迭代的上标,因为这将在上下文中明确,以减少符号的复杂性。
方法步骤
1. 点跟踪作为迭代轨迹优化
通俗解释:什么是"迭代轨迹优化"?
想象你在玩一个游戏,目标是让一个小球沿着视频中某个物体的表面移动(比如跟踪一辆车的前灯)。你需要预测小球在每一帧视频中的位置,形成一条连续的路径(轨迹)。但视频中有很多干扰:摄像机在动、光线在变、物体可能被遮挡。直接猜小球的位置很容易出错。
TAPIP3D的办法是把这个跟踪问题看成一个"优化问题":我们假设小球的轨迹是一条曲线,然后通过不断调整这条曲线,让它尽可能贴合视频中观察到的信息(比如颜色、深度、位置)。这个调整过程是迭代的,就像你在画画时,先画一个粗糙的草稿,然后一点点修改,直到画得很像为止。
具体步骤:怎么优化轨迹?
论文中,TAPIP3D把点跟踪转化为优化一个3D轨迹的过程,步骤可以拆解为以下几点:
- 把2D视频"抬升"到3D空间 :
- 普通的视频是2D的(只有x、y坐标),但如果有深度信息(RGB-D视频),每个像素不仅有颜色,还有一个z坐标(距离摄像机的深度)。
- TAPIP3D利用深度信息和摄像机的运动(通过SLAM等技术估算),把每个2D像素映射到3D空间,形成一个3D点云。这个点云就像一个稳定的3D世界,摄像机的晃动被"抵消"了。
- 举个例子:假设你在跟踪一辆车的轮胎,轮胎在视频中可能因为摄像机移动而位置变化,但把它映射到3D空间后,轮胎的3D位置是固定的,跟踪就更容易了。
- 初始化一个粗糙的轨迹 :
- 为了开始跟踪,TAPIP3D会先给出一个初始的3D轨迹。比如,你告诉系统要跟踪视频第一帧中轮胎上的一个点,系统会根据深度信息估算这个点在3D空间的位置,然后假设它在后续帧中沿着某条路径移动。
- 这个初始轨迹不一定准确,但它是一个起点。
- 用特征云来优化轨迹 :
- TAPIP3D把视频表示成一个"时空特征云"。每个3D点不仅有位置(x, y, z),还有一个"特征向量"(可以理解为这个点的"指纹",包含颜色、纹理等信息)。
- 优化轨迹的目标是:让轨迹上的每个点都尽量匹配视频中对应帧的特征。比如,轮胎上的点在不同帧中应该有相似的颜色和纹理。
- 具体来说,系统会计算轨迹上每个点的特征与视频中对应位置的特征的差异(用数学上的"损失函数"表示),然后调整轨迹,让这个差异尽量小。
- 迭代调整,直到轨迹最优 :
- 优化不是一步完成的。系统会反复检查轨迹,调整每个点的位置,让整个轨迹更符合视频的观察结果。
- 比如,如果发现轮胎的点在某帧偏离了实际位置,系统会稍微移动这个点,同时考虑它与前后帧的连贯性(轨迹不能跳来跳去)。
- 这个过程就像你在玩拼图,先大致放好拼图块,然后一点点调整,直到每一块都完美契合。
- 多帧联合优化 :
- 为了让轨迹更稳定,TAPIP3D不是只看当前帧,而是同时考虑多帧的信息。比如,它会检查轮胎的点在过去几帧和未来几帧的位置,确保整个轨迹是平滑且合理的。
- 这就像你在看一部电影时,不仅关注当前画面,还会回忆前几秒的剧情,确保故事连贯。
为什么叫"迭代"?
因为优化是一个循环过程:初始化轨迹 → 计算误差 → 调整轨迹 → 再计算误差 → 再调整......直到误差小到可以接受为止。每次循环(迭代)都让轨迹更接近真实情况。
2. 持续的3D几何空间中的跟踪
通俗解释:什么是"持续的3D几何空间"?
"持续的3D几何空间"听起来很复杂,但其实就是指一个稳定的3D世界模型。在这个模型中,物体的3D形状和位置是固定的,不会被摄像机的移动或视角变化干扰。TAPIP3D的目标是在这个稳定的3D空间中,长时间跟踪一个点,即使视频很长、场景很复杂,也能保持准确。
打个比方:假设你在现实世界中跟踪一只飞翔的鸟,鸟的实际位置是固定的3D坐标,但你的摄像机在晃动,拍出来的视频中鸟的位置会不断变化。TAPIP3D的做法是把视频"转换"到一个固定的3D坐标系,就像把鸟的飞行路径画在一张3D地图上,这样不管摄像机怎么动,鸟的轨迹都是清晰的。
具体怎么实现"持续跟踪"?
论文中,TAPIP3D通过以下方式在3D几何空间中实现持续跟踪:
- 构建相机稳定的特征云 :
- 如前面提到的,TAPIP3D把视频中的像素"抬升"到3D空间,形成一个3D点云。这个点云是"相机稳定的",意思是它消除了摄像机运动的影响。
- 比如,视频中一辆车可能因为摄像机旋转而显得在移动,但在这张3D点云中,车的3D位置是固定的,就像你在上帝视角看整个场景。
- Local Pair Attention机制 :
- 3D点云的点分布是不规则的(不像2D图像是整齐的网格),这给跟踪带来挑战。TAPIP3D提出了一种"Local Pair Attention"机制,简单来说,就是让每个点只关注它附近的"邻居点"。
- 想象你在跟踪轮胎上的一个点,这个点会"询问"它周围的点(比如轮胎上其他点)的特征,综合这些信息来判断自己的位置。这种"邻居关系"让跟踪更精准,因为它利用了3D空间的几何信息。
- 举个例子:如果轮胎上的点在某帧被遮挡,但它旁边的点还能看到,系统可以通过邻居的特征推测出这个点的位置。
- 长时间的稳定性 :
- 为了在长视频中保持跟踪的稳定性,TAPIP3D会不断更新3D点云和轨迹。比如,随着视频播放,新的帧会带来新的深度信息,系统会用这些信息更新3D模型,确保点云始终反映最新的场景。
- 同时,迭代优化会考虑整个视频的上下文(多帧信息),避免跟踪在某帧突然"跳跃"。
- 替换传统的2D方法 :
- 传统2D跟踪方法用的是"2D相关邻域"(比如一个像素周围的小方块),但这在3D空间不适用。TAPIP3D用3D的"邻居关系"代替了2D方块,效果更好,因为它能捕捉物体的真实几何形状。
- 比如,跟踪一个球形物体时,2D方法只看到平面上的像素,但TAPIP3D能看到球的3D曲面,跟踪更稳定。
为什么强调"持续"?
因为视频可能是几分钟甚至几小时,场景会不断变化(光线、遮挡、物体移动)。TAPIP3D通过维护一个动态更新的3D几何空间,确保点跟踪不会因为时间长而失效。就像你在导航软件上跟踪一辆车,即使信号偶尔中断,软件也能根据历史数据和地图推测车的当前位置。
总结:这两部分的核心思想
- 点跟踪作为迭代轨迹优化 :
- 把点跟踪变成一个数学优化问题:假设一个3D轨迹,然后通过反复调整,让它尽量贴合视频中的特征(颜色、深度等)。
- 像是在画一条曲线,不断擦掉重画,直到它完美匹配目标。
- 持续的3D几何空间中的跟踪 :
- 把视频"搬"到一个稳定的3D世界,消除了摄像机运动的干扰。
- 用3D点云和"邻居关系"来跟踪点,即使视频很长、场景复杂,也能保持稳定。
跟踪效果评估
TAPIP3D提出了一种在3D空间中跟踪视频中任意点的方法,声称比传统方法更精准、更稳定。但光说自己厉害不行,得用数据和实验证明。所以,论文的评估部分就是用来"晒成绩单"的:通过实验,展示TAPIP3D在不同场景下的表现,比较它和已有方法的优劣。
评估的重点是回答:TAPIP3D跟踪的点是否准确?是否能坚持跟踪不丢失?在复杂场景(比如遮挡、光线变化)下表现如何?
1. 评估的总体思路
通俗来说,评估就像给TAPIP3D做一场"考试"。考试内容是让它跟踪视频中的点,然后检查:
- 准确性:跟踪的点是不是真的在目标位置?
- 鲁棒性:遇到遮挡、摄像机晃动或光线变化,会不会跟丢?
- 持续性:在长视频中,能不能一直跟踪不中断?
为了公平,考试用了一些公开的"考卷"(数据集),这些数据集包含RGB-D视频(有颜色和深度信息)和已知的点轨迹(作为标准答案)。TAPIP3D的成绩会和其他方法(比如传统2D跟踪或基于点云的方法)对比,看谁更优秀。
2. 使用的"考卷"(数据集)
论文通常会用几个标准数据集来测试跟踪效果。这些数据集就像不同的考试科目,模拟了现实中可能遇到的场景,比如室内、室外、动态物体等。以下是可能用到的数据集(具体以论文为准):
- TAP-Vid :
- 这是一个专门用来测试点跟踪的数据集,包含真实和合成的视频。每个视频里有一些标注好的点,告诉你这些点在每帧的正确位置(2D或3D坐标)。
- 比如,一个视频可能拍了一只猫,标注了猫耳朵上的一个点,TAPIP3D的任务是跟踪这个点,看它的预测轨迹和标准答案有多接近。
- Co3D :
- 这个数据集专注于3D场景,包含物体在不同角度的视频和深度信息。适合测试TAPIP3D的3D跟踪能力。
- 想象你在跟踪一个旋转的咖啡杯,Co3D会提供杯子的3D模型和视频,TAPIP3D要证明它能准确跟踪杯子表面的某个点。
- Custom RGB-D Datasets :
- 论文可能还用了一些定制的RGB-D视频数据集,模拟机器人导航或AR场景。这些视频通常有复杂的摄像机运动和遮挡,考验TAPIP3D的鲁棒性。
- 比如,一个视频可能是机器人穿过房间的视角,TAPIP3D要跟踪房间角落的一个点,即使有家具挡住。
3. 怎么评分?(评估指标)
为了给TAPIP3D打分,论文用了几个量化指标,相当于考试的分数。这些指标通俗来说,就是检查跟踪的点和"标准答案"有多接近。以下是常见的指标,解释得尽量直白:
- 位置误差(Position Error) :
- 这是最直接的评分方法:比较TAP 预测的点位置和真实位置的距离差。
- 比如,TAPIP3D预测猫耳朵上的点在3D空间的坐标是(x1, y1, z1),而标准答案是(x2, y2, z2),位置误差就是两点之间的欧几里得距离(就像用尺子量两点多远)。
- 误差越小,说明跟踪越准。
- 跟踪成功率(Tracking Success Rate) :
- 这个指标看TAPIP3D能不能一直跟踪点不丢失。
- 比如,视频有100帧,TAPIP3D在90帧里都正确跟踪了猫耳朵的点(误差在某个范围内),成功率就是90%。
- 如果点被遮挡或光线变化导致跟丢,成功率会下降。
- 遮挡鲁棒性(Occlusion Robustness) :
- 这个指标专门测试TAPIP3D在点被遮挡时的表现。
- 比如,猫耳朵的点被手挡住了几帧,TAPIP3D能不能根据前后帧的信息猜出正确位置?评分会看它在遮挡帧的误差和恢复能力。
- Jaccard Index(或类似指标) :
- 这个指标用来衡量跟踪的"重叠度"。虽然更多用在2D跟踪,但3D也可以类似处理。
- 想象你在跟踪一个点的区域(比如一个小圆),Jaccard Index会检查预测区域和真实区域的重叠比例。重叠越多,分数越高。
这些指标就像考试的评分标准:位置误差看"答得准不准",成功率看"能坚持多久",遮挡鲁棒性看"遇到难题会不会崩"。
4. 和谁比?(对比方法)
为了证明TAPIP3D牛,论文会把它和其他方法放在一起比试。这些"对手"可能是:
- 传统2D点跟踪方法 :
- 比如RAFT或PIPs,这些方法直接在2D视频上跟踪像素,不用3D信息。
- 它们可能在简单场景下还行,但遇到摄像机晃动或遮挡就容易翻车。
- 基于点云的跟踪方法 :
- 比如PointOdyssey,尝试在3D点云上跟踪,但可能没有TAPIP3D的迭代优化或Local Pair Attention机制。
- 这些方法可能在3D空间有优势,但优化不够精细。
- 基线方法(Baseline) :
- 论文可能会自己设计一些简化版的TAPIP3D(比如不迭代优化或不用3D点云),看看完整版比简化版强多少。
- 这就像考试时拿"裸考"和"复习后"的成绩对比。
通过对比,论文会展示TAPIP3D在位置误差、成功率等方面比对手低(误差小)或高(成功率高),证明它的优势。
5. 实验结果:TAPIP3D的表现如何?
虽然我没法直接引用论文的表格或数字(因为没看到具体数据),但评估结果通常会以表格、图表或视频形式展示。以下是典型的结果内容,通俗解释:
- 定量结果(Quantitative Results) :
- 论文会列一个表格,显示TAPIP3D和其他方法在各个数据集上的分数。
- 比如,在TAP-Vid数据集上,TAPIP3D的平均位置误差可能是0.5厘米,而2D方法可能是2厘米,证明TAPIP3D更准。
- 成功率可能显示TAPIP3D在90%的帧里都跟踪正确,而其他方法只有70%。
- 定性结果(Qualitative Results) :
- 论文会放一些视频或图片,展示TAPIP3D的跟踪效果。
- 比如,一个视频可能显示TAPIP3D跟踪一只狗身上的点,即使狗跑来跑去、被遮挡,轨迹依然连贯。而其他方法可能在中途跟丢,轨迹断断续续。
- 这些可视化结果就像"考试答题过程",让人直观感受TAPIP3D的稳定性。
- 复杂场景的表现 :
- 论文会特别强调TAPIP3D在"硬核"场景下的表现,比如:
- 遮挡:点被物体挡住时,TAPIP3D能通过3D邻居关系推测位置。
- 光线变化:光线变暗或变亮,TAPIP3D靠深度信息和特征云保持稳定。
- 长视频:在几分钟的视频中,TAPIP3D的轨迹依然精准,不像2D方法容易漂移。
- 论文会特别强调TAPIP3D在"硬核"场景下的表现,比如:
- 消融实验(Ablation Study) :
- 为了证明TAPIP3D的每个部分都有用,论文会做"拆解实验"。
- 比如,去掉迭代优化,误差变大;不用Local Pair Attention,跟踪成功率下降。这些实验证明TAPIP3D的每个设计(3D点云、迭代优化、邻居机制)都不可或缺。
举个生活化的例子
假设你在看一场足球比赛的视频,想跟踪足球上的一块污点。你用手机拍视频,镜头会晃动,污点在屏幕上的位置会变。传统方法可能直接在2D视频上找污点,但容易因为晃动或遮挡跟丢。TAPIP3D的做法是:
- 3D空间:用深度相机(或算法估算深度)把足球"重建"成一个3D模型,污点在足球表面的3D位置是固定的。
- 初始猜测:先猜污点在3D空间的运动轨迹(比如沿着足球滚动的路径)。
- 优化轨迹:根据视频中污点的颜色和周围纹理,不断调整这条轨迹,确保它在每帧都对得上。
- 邻居帮忙:如果污点被球员挡住,系统会看污点旁边的点(足球表面的其他区域)来推测位置。
- 持续更新:随着比赛进行,系统不断更新3D模型和轨迹,确保污点跟踪不中断。
为什么TAPIP3D厉害?
- 3D更稳定:相比2D方法,3D空间考虑了物体的真实几何和摄像机运动,跟踪更鲁棒。
- 迭代优化:通过反复调整轨迹,适应复杂的视频场景。
- Local Pair Attention:利用3D邻居关系,解决了点云不规则的问题。
- 长时间跟踪:能在长视频中保持准确,适合现实应用(比如机器人导航、AR/VR)。
测试模型效果
编译依赖
环境准备
conda create -n tapip3d python=3.10
conda activate tapip3d
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 "xformers>=0.0.27" --index-url https://download.pytorch.org/whl/cu124
pip install torch-scatter -f https://data.pyg.org/whl/torch-2.4.1+cu124.html
pip install -r requirements.txt编译pointops2
cd third_party/pointops2
LIBRARY_PATH=$CONDA_PREFIX/lib:$LIBRARY_PATH python setup.py install
cd ../..PointOps2 是一个专门为3D点云数据设计的开源库,用于高效处理点云的查询、采样和邻域操作。在TAPIP3D中,PointOps2主要用来支持3D点云的特征提取和Local Pair Attention机制。
通俗解释:
想象你有一堆散乱的3D点(就像一堆漂浮在空中的小星星),你需要快速找到某颗星星的"邻居"并分析它们的特征(比如颜色、位置)。PointOps2就像一个超级高效的"点云管理员",帮你整理这些点,快速计算点之间的关系,比如:
- 邻域查询:找到某个点附近的其他点(支持Local Pair Attention)。
- 点云采样:从一大堆点中挑出代表性的点,减少计算量。
- 特征聚合:把邻居点的特征(比如颜色、纹理)汇总起来,方便后续处理。
在TAPIP3D中的具体用途:
- Local Pair Attention:TAPIP3D提出了一种机制,让每个3D点只关注它附近的"邻居点"来更新特征。PointOps2提供了高效的算法(比如KNN或球查询)来找到这些邻居,并计算它们之间的空间关系。
- 点云处理:TAPIP3D的3D特征云是不规则的(不像2D图像是整齐的网格),PointOps2帮助处理这种不规则数据,确保跟踪算法能快速运行。
- 优化效率:PointOps2用CUDA加速,适合在GPU上处理大规模点云,减少计算时间。
编译megasam
cd third_party/megasam/base
LIBRARY_PATH=$CONDA_PREFIX/lib:$LIBRARY_PATH python setup.py install
cd ../../..MegaSAM 是一个结合了SAM(Segment Anything Model)和DepthAnything 的框架,用于从单目视频(monocular RGB video)中估计深度图 和相机姿态。在TAPIP3D中,MegaSAM主要为单目视频提供深度信息和相机运动信息,以便将2D特征抬升到3D空间。
通俗解释:
假设你在用手机拍一个视频,MegaSAM就像一个"超级助手",能从普通视频中"猜"出每个像素的深度(离你多远)和摄像机的移动轨迹(你怎么晃手机)。这些信息对TAPIP3D很重要,因为它需要把2D视频变成3D点云,而3D点云需要知道每个点的深度和摄像机的位置。
在TAPIP3D中的具体用途:
- 深度估计:对于RGB-D视频,深度信息直接来自传感器;但对于单目RGB视频,MegaSAM用DepthAnything模型生成深度图,模拟RGB-D输入。
- 相机姿态估计:MegaSAM通过分析视频帧之间的差异,估算摄像机在3D空间的运动(位置和旋转)。这让TAPIP3D能构建"相机稳定的"3D特征云,消除摄像机晃动的影响。
- 支持单目视频:TAPIP3D的核心是3D跟踪,但单目视频没有现成的深度信息。MegaSAM填补了这个空白,让TAPIP3D也能处理普通视频。
下载模型
- 下载 TAPIP3D model checkpoint 链接 放在
checkpoints/tapip3d_final.pth - 使用使用 TAPIP3D 在运动视频上, 需要准备下面模型 手动跑 MegaSAM:
- 下载 DepthAnything V1 checkpoint 链接 放置地址
third_party/megasam/Depth-Anything/checkpoints/depth_anything_vitl14.pth - 下载 RAFT checkpoint 链接 放置地址
third_party/megasam/cvd_opt/raft-things.pth
DepthAnything:深度估计的"测距仪"
DepthAnything 是一个基于视觉变换器(Vision Transformer)的深度估计模型,能从单张RGB图像生成高质量的深度图。在TAPIP3D中,DepthAnything通过MegaSAM框架为单目视频提供深度信息。
通俗解释:
DepthAnything就像一个"魔法眼镜",看一张普通照片就能告诉你每个物体离你多远。它通过分析图像中的视觉线索(比如物体大小、遮挡关系)估算深度,生成一张深度图(亮的像素表示近,暗的表示远)。
在TAPIP3D中的具体用途:
- 单目视频的深度输入:TAPIP3D需要深度信息来把2D像素抬升到3D点云。对于RGB-D视频,深度直接可用;但对于单目RGB视频,DepthAnything生成伪深度图,供MegaSAM和TAPIP3D使用。
- 提升通用性:有了DepthAnything,TAPIP3D不仅限于RGB-D传感器,还能处理普通的手机或相机视频,应用场景更广。
- 高质量深度:DepthAnything的深度图精度高,能捕捉细微的几何细节,这对TAPIP3D的3D跟踪很重要。
RAFT:光流估计的"运动侦探"
RAFT(Recurrent All-Pairs Field Transforms)是一个用于光流估计 的深度学习模型,擅长预测视频中像素在连续帧之间的运动(即光流)。在TAPIP3D中,RAFT可能作为基线方法 或辅助特征提取,用于比较或初始化2D跟踪。
通俗解释:
光流就像视频中的"运动轨迹",告诉你每个像素从一帧到下一帧"跑"到哪里去了。RAFT是个"侦探",能分析两帧图像的差异,画出每个像素的移动箭头(比如一个球从左边移到右边)。在TAPIP3D中,RAFT可能用来:
- 提供初始的2D跟踪结果,辅助3D跟踪。
- 作为对比方法,证明TAPIP3D的3D方法比2D光流跟踪更强。
在TAPIP3D中的具体用途:
- 基线对比:论文的实验部分(评估跟踪效果)提到与传统2D跟踪方法(如RAFT)比较。RAFT代表了先进的2D光流跟踪,TAPIP3D通过实验展示自己的3D方法在准确性和鲁棒性上优于RAFT。
- 可能的辅助作用:虽然TAPIP3D主打3D跟踪,但实现中可能用RAFT提取2D光流特征,作为初始化或补充。比如,在单目视频中,RAFT的光流可以帮助MegaSAM估计相机运动,或者为3D点云的特征提供2D运动线索。
- 特征增强:RAFT生成的2D光流可能被融入TAPIP3D的时空特征云,增强对动态场景的理解(比如快速移动的物体)。
使用官方自带的pstudio.mp4 视频测试
python inference.py --input_path demo_inputs/pstudio.mp4 --checkpoint checkpoints/tapip3d_final.pth --resolution_factor 2
结构输出:
09:47:24 INFO Results saved to /opt/chenrui/TAPIP3D/outputs/inference/2025-05-11_09-37-37/pstudio.result.npz
运行可视化
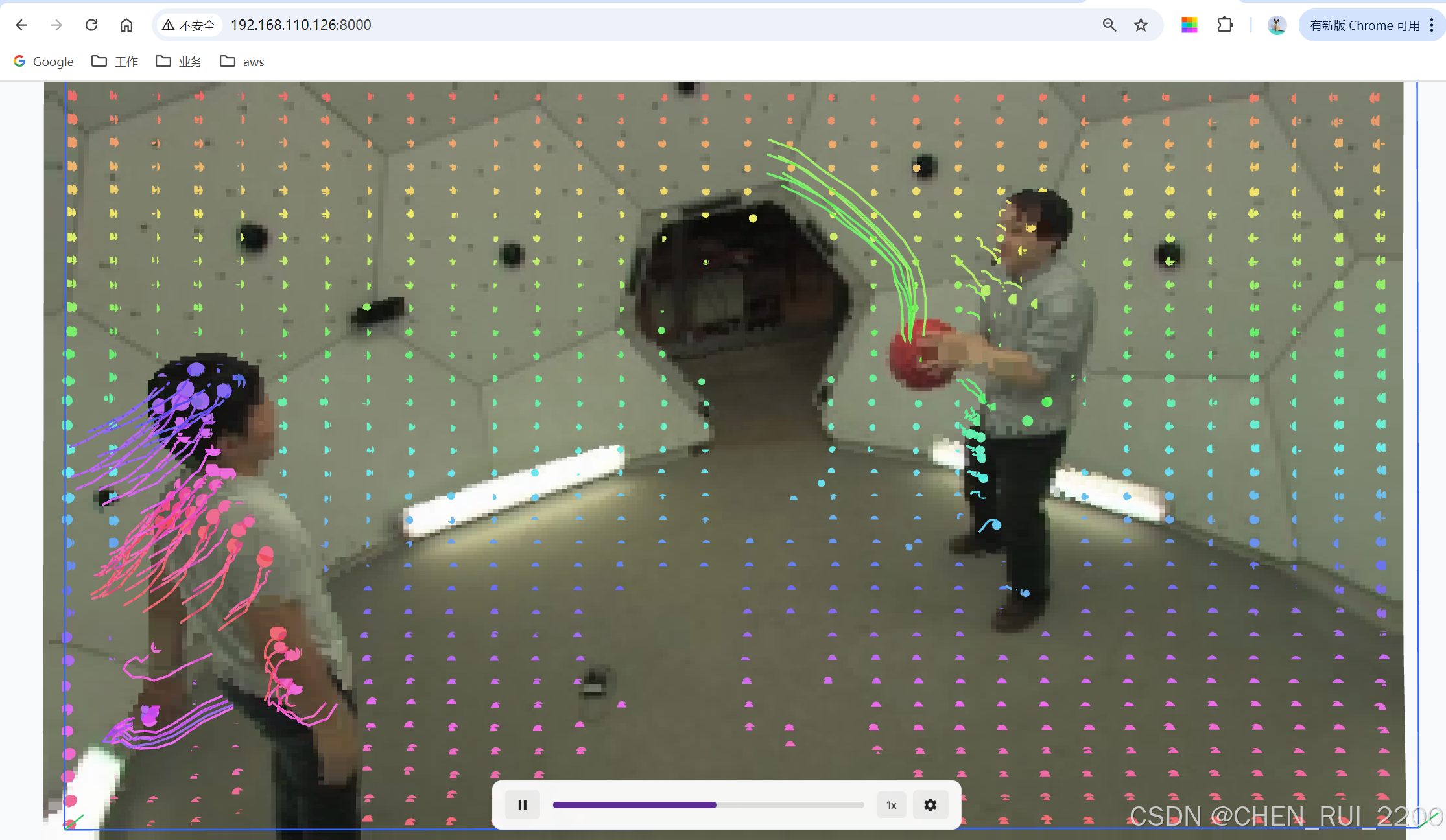
测试其他视频
受限于4090 的显存大小,目前只能处理五秒内的运动视频