文章目录
Ubuntu 安装
一、配置电脑
1、进入VMware
2、选择配置类型

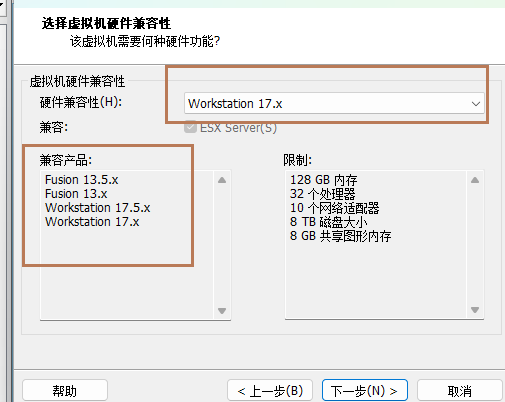
3、选择硬件兼容性版本
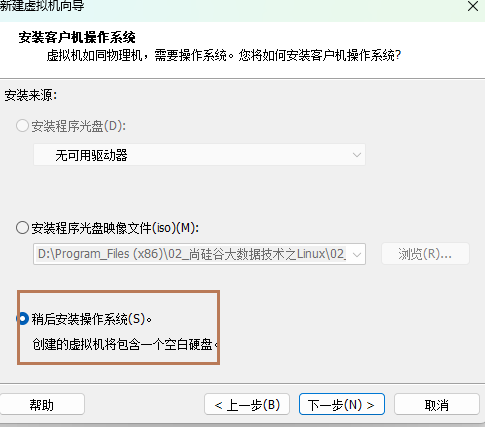
4、当前虚拟机的操作系统
选择"稍后安装操作系统"(修改)
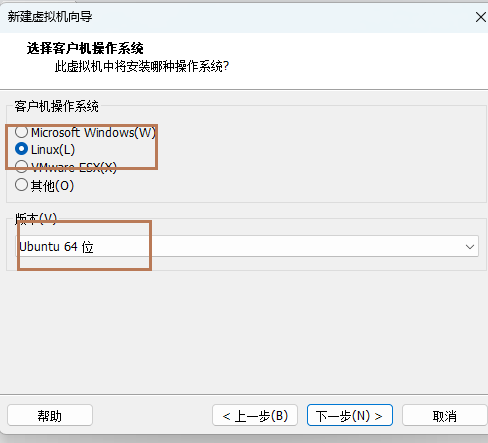
5、选择虚拟机将来需要安装的系统
选中"Linux"和选择"Ubuntu64位"(修改)
6、配置电脑
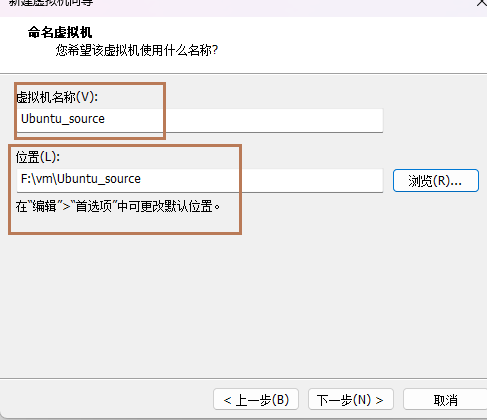 7、选择CPU的个数
7、选择CPU的个数
一般选择1个处理器和4个内核;配置高的,可以选择2个处理器和4个内核。(修改)
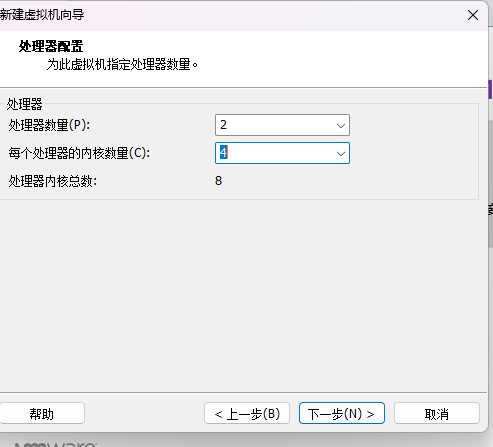
8、设置虚拟机的内存
内存4-8G,如果电脑配置高可以酌情增加。(修改)
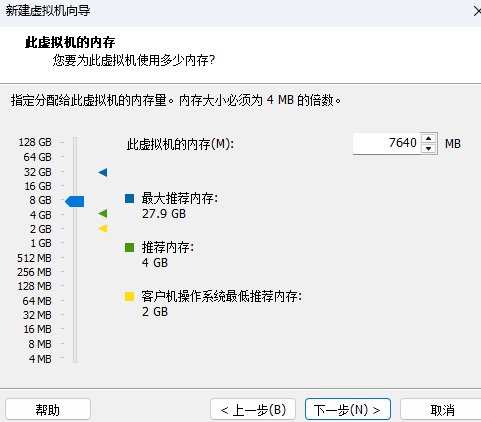
9、选择虚拟机上网方式
选择NAT的方式(默认)
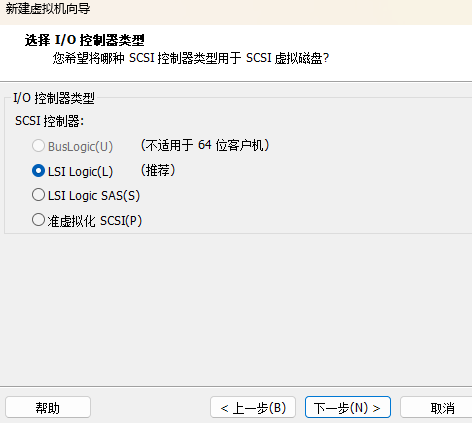
10、选择对应的文件系统的IO方式
选择"LSI Logic"(默认)
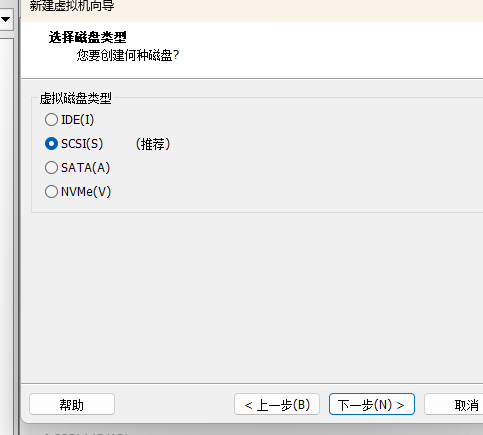
选择"SCSI(S)"(默认)
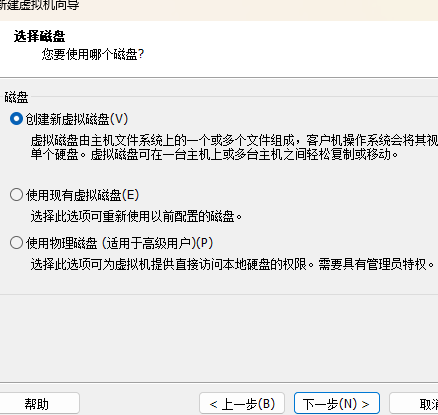
选择"创建新虚拟磁盘"(默认)
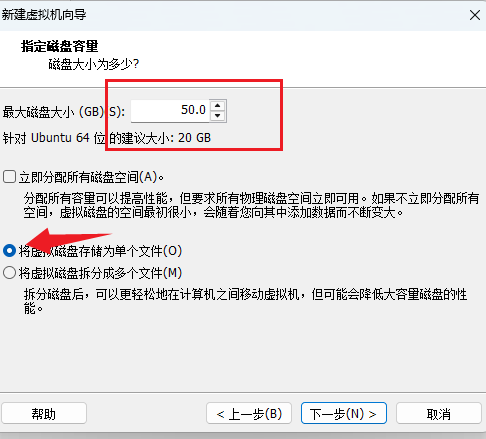
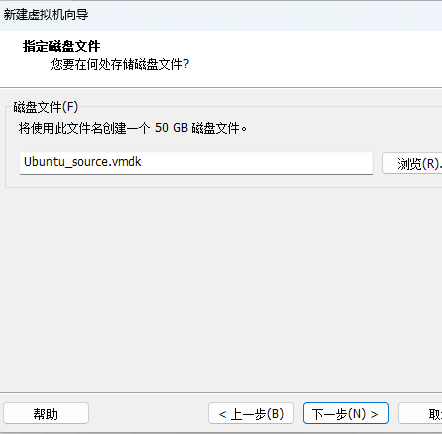
11、选择虚拟机的磁盘大小和文件个数
指定最大磁盘大小为:50G (修改)
选择虚拟硬盘文件个数为:1 (修改)
默认直接下一步
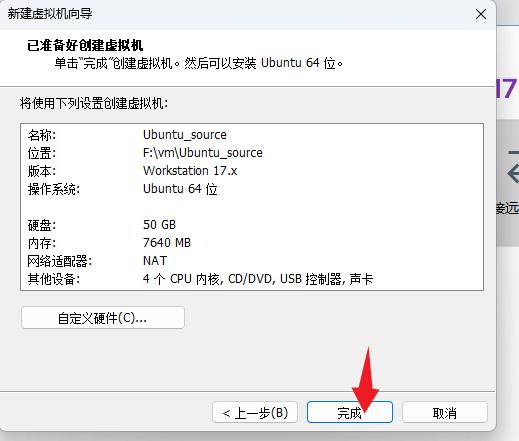
 最后完成
最后完成
二、安装系统
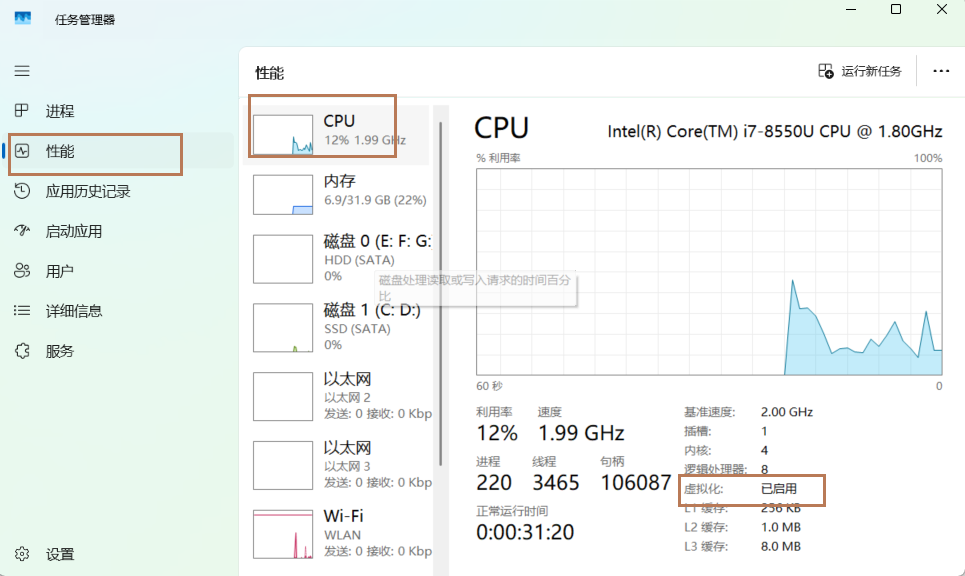
注:在安装系统之前需要检查自己虚拟机的bios的虚拟化是否打开(大部分的电脑都是打开的,大家可以先尝试直接安装,如果出现错误再去调试,没有出错就不用管了)。
以下是查看虚拟机bios是否开启的方式。
window10/9
1、双击打开
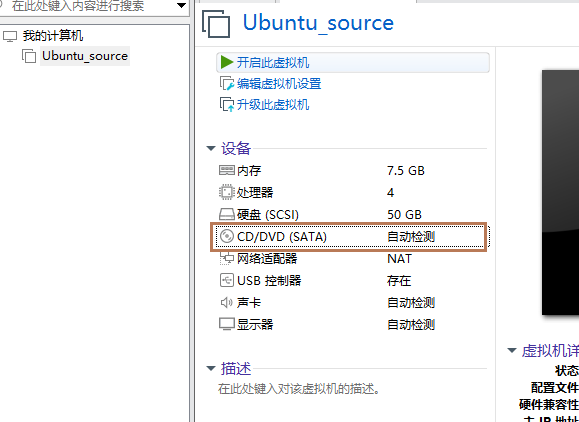
2、cd/dvd的方式安装系统
镜像下载网站:https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/22.04.4/
选择下载好的镜像
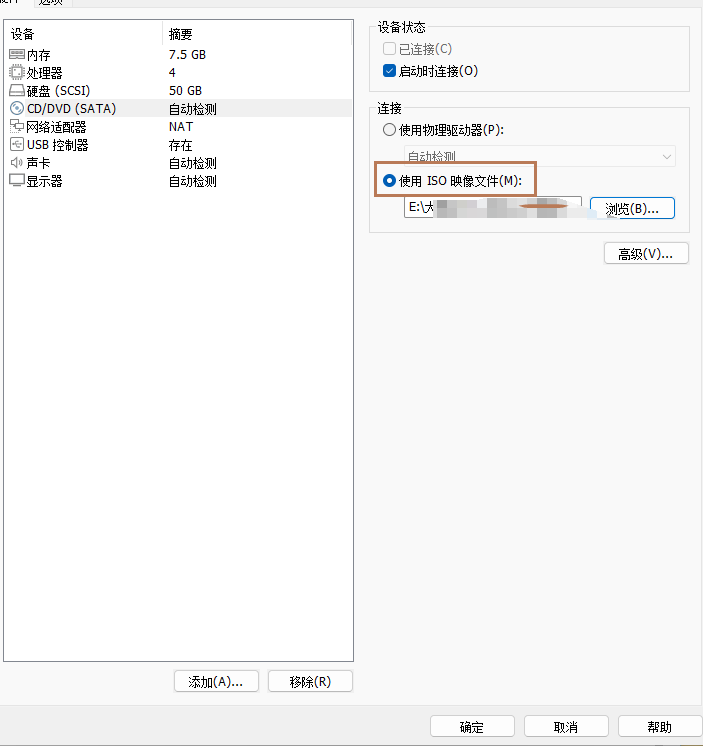
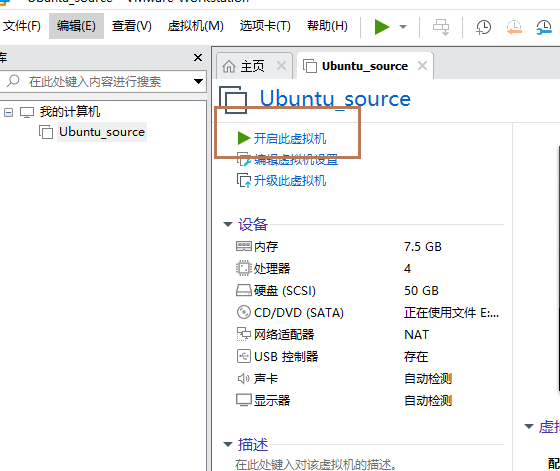
3、开启虚拟机
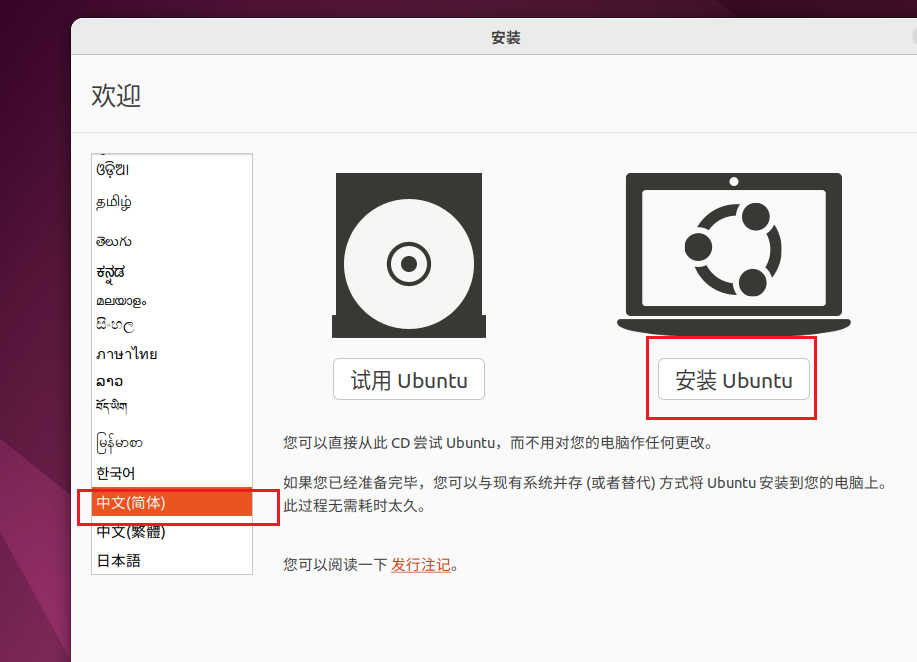
1)出现如下界面,选择中文安装
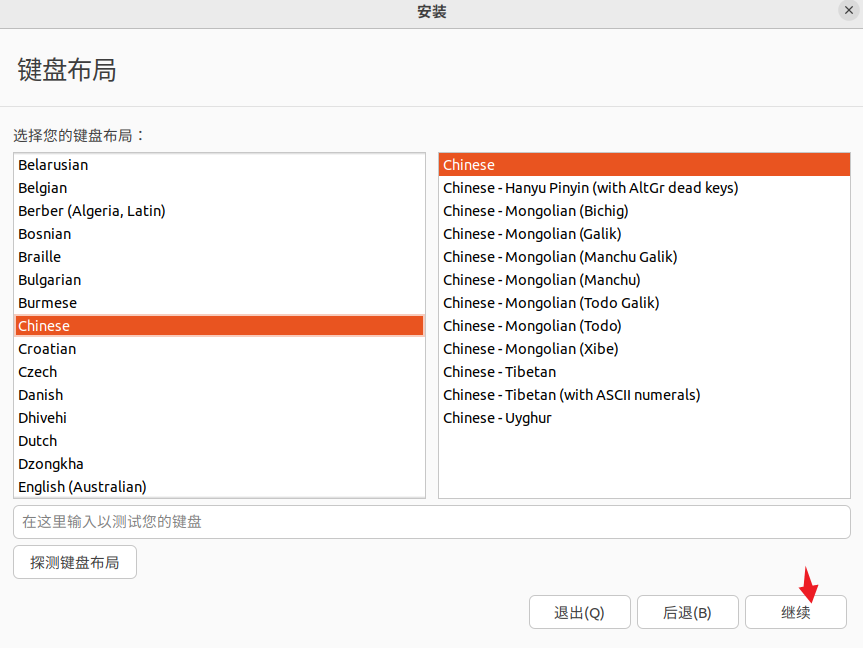
2)选择中文键盘
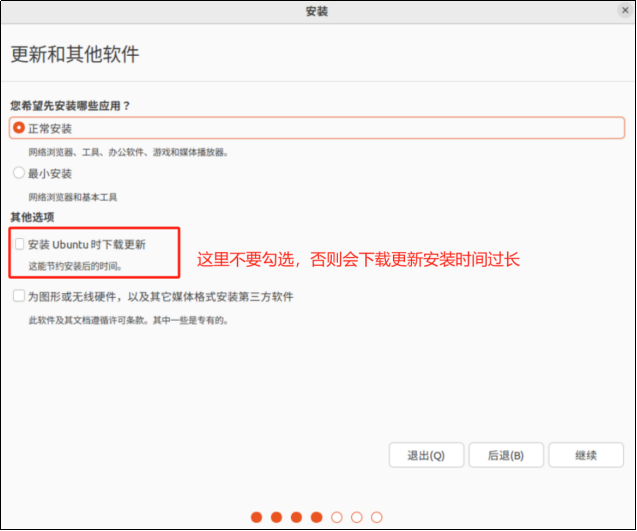
直接安装
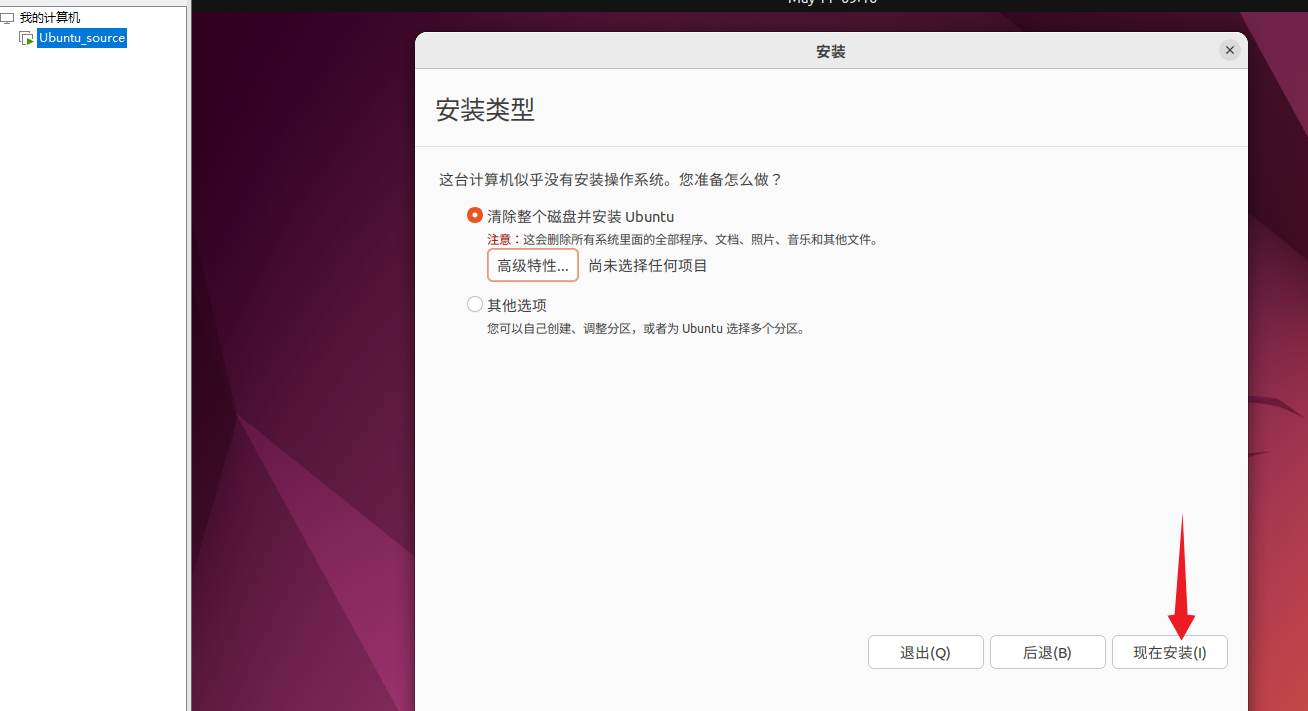
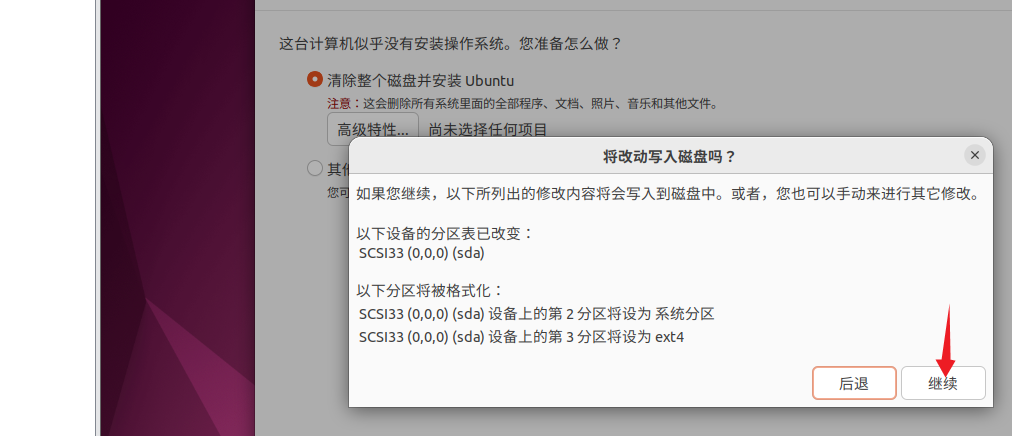
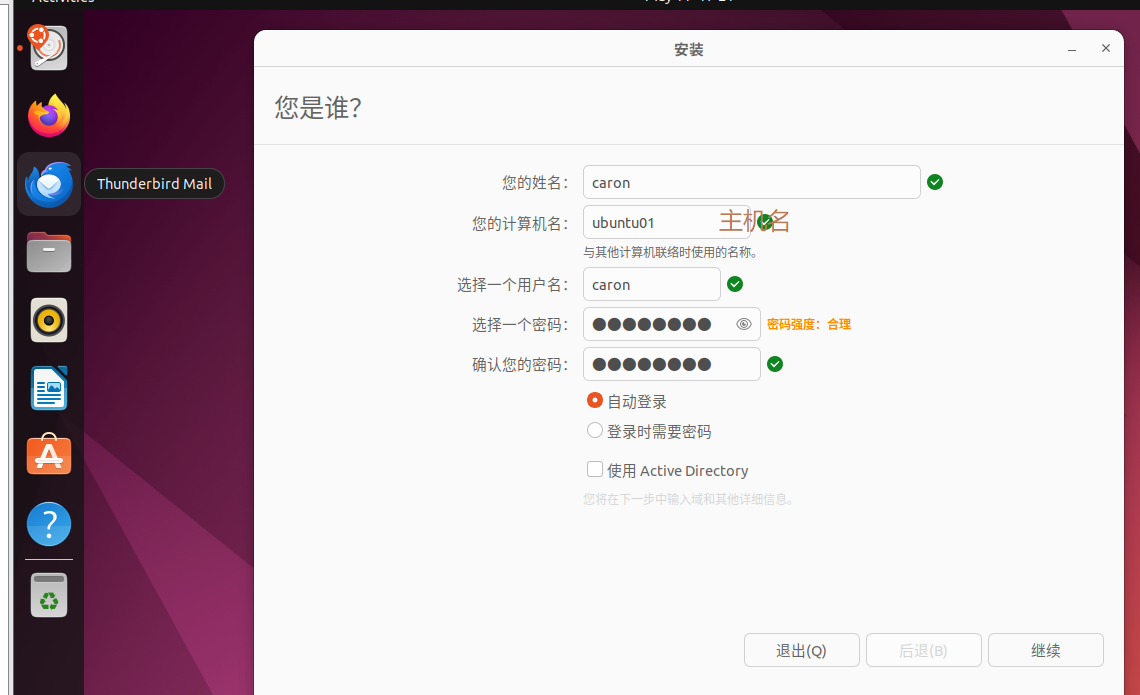
3)等待安装结束,重启虚拟机