kafka
1、什么是kafka
kafka是一个分布式事件流平台,核心功能有发布/订阅消息系统、实时处理数据流等,Kafka非常适合超大数据量场景。
2、kafka安装
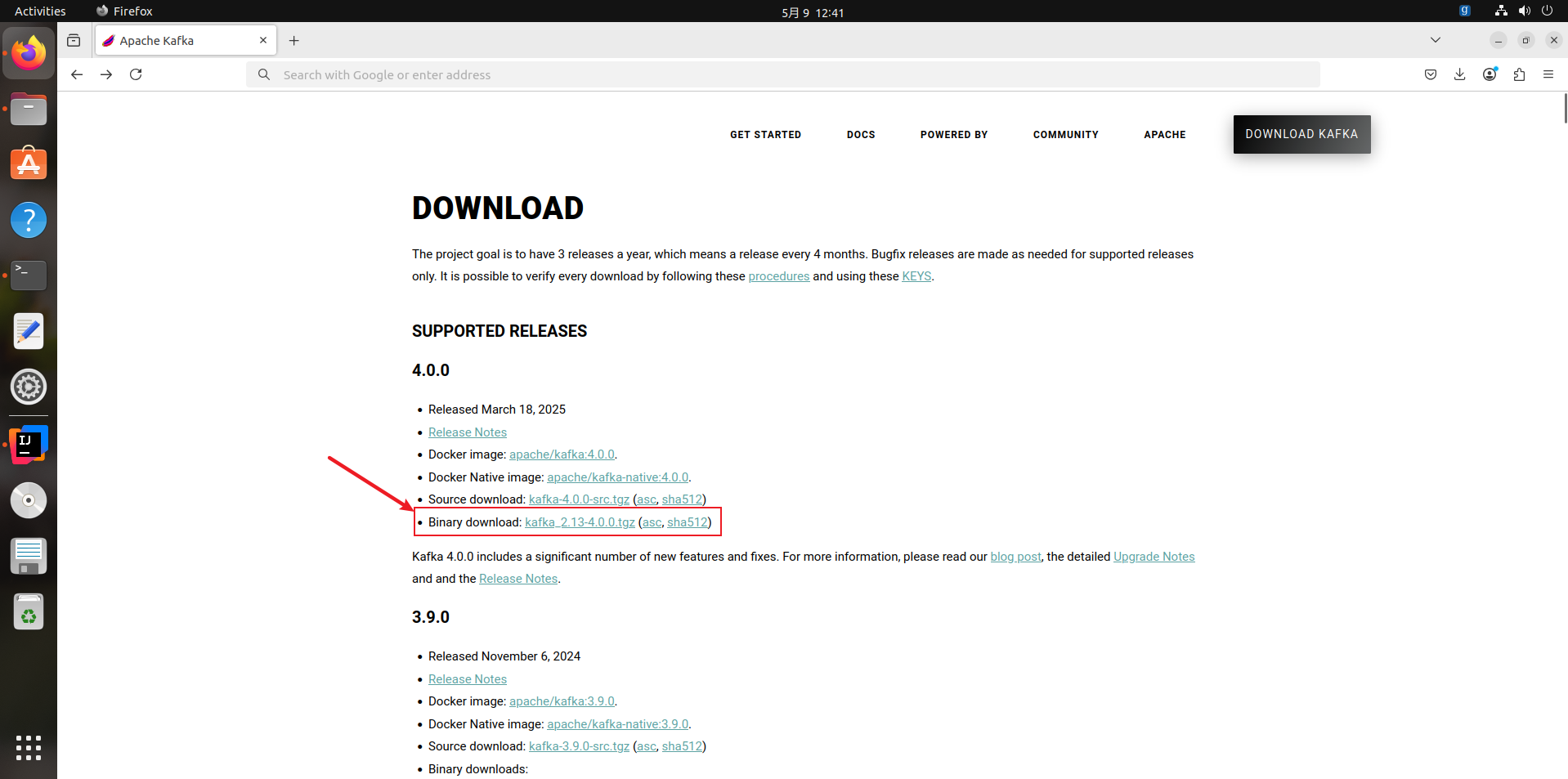
(1)下载
在kafka官网下载二进制压缩包
(2)解压安装
在Linux的终端使用tar -xvf kafka_2.13-4.0.0.tgz -C '解压到指定路径'命令,解压完即完成安装。
(3)启动kafka
kafka是由Scala语言开发的需要预先安装JDK,有两种方式启动kafka,分别是使用Zookeeper,使用KRaft,前期Kafka依赖Zookeeper进行管理维护集群的整体状态和协调各个组件的工作,后期使用KRaft(Kafka Raft)取代了Zookeeper。
- Kafka启动使用Zookeeper
在Kafka的较新版本中已经完全移除了Zookeeper默认使用KRaft,因此可能不存在Zookeeper的启动脚本及jar包,需要我们手动安装Zookeeper。以下是针对旧版本的Kafka启动脚本
1)启动Zookeeper:bin/zookeeper-server-start.sh config/zookeeper.properties &,&用来指定在后台启动。
2)启动Kafka:bin/kafka-server-start.sh config/server.properties &
3)关闭Kafka:bin/kafka-server-stop.sh config/server.properties - 手动安装Zookeeper并启动Kafka
1)下载解压安装
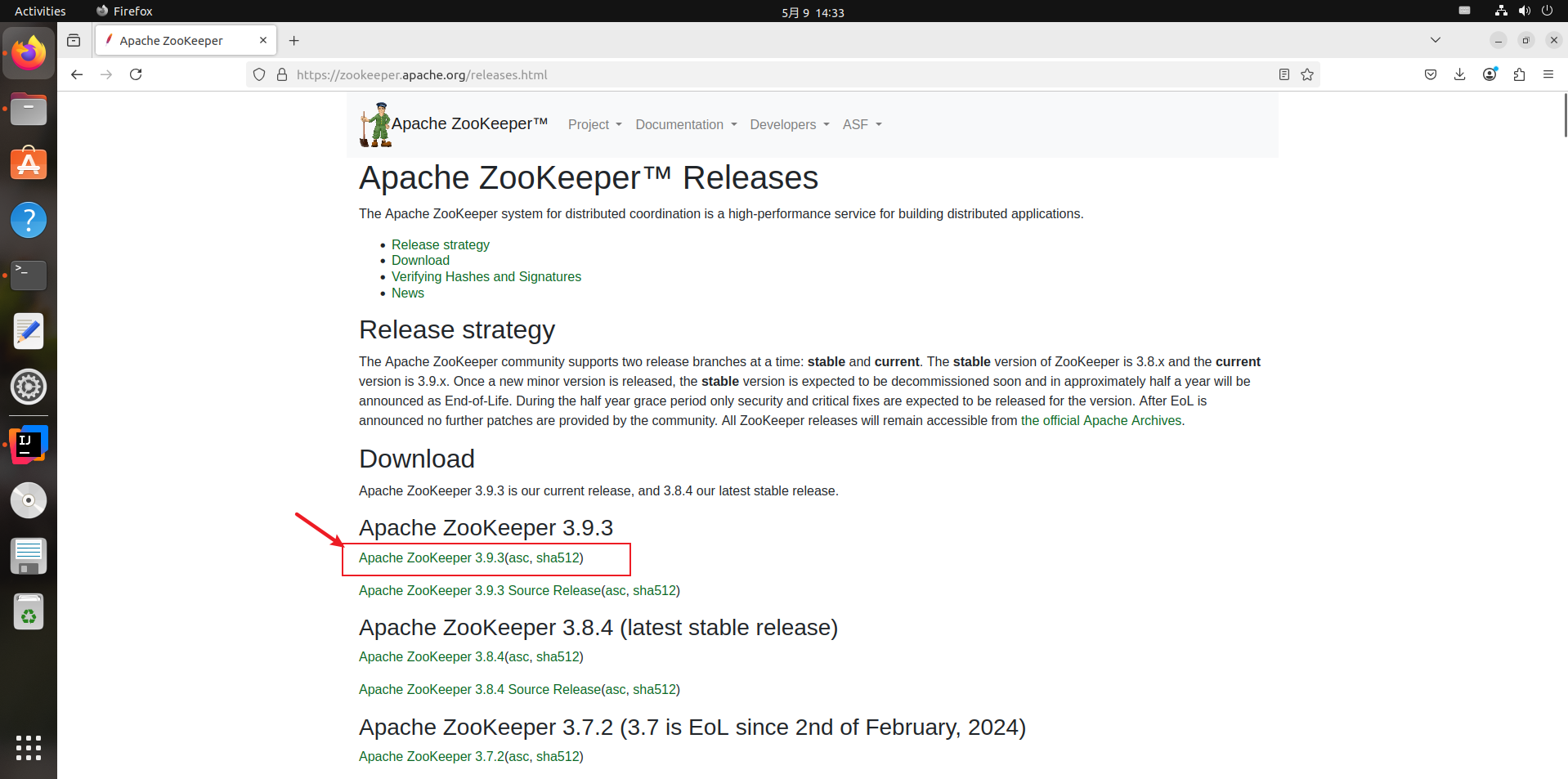
2)在conf目录下配置cp zoo_sample.cfg zoo.cfg,启动zkbin/zkServer.sh start,再启动kafkabin/kafka-server-start.sh -daemon config/server.properties - Kafka启动使用KRaft
bash
# 生成集群ID
KAFKA_CLUSTER_ID=$(bin/kafka-storage.sh random-uuid)
echo $KAFKA_CLUSTER_ID
# 格式化,4.0.0版本没有Zookeeper启动脚本因此只存在一个配置文件在config/server.properties,根据情况自行修改
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
# 启动Kafka,daemon用于指定后台启动
bin/kafka-server-start.sh -daemon config/kraft/server.properties(4)使用docker安装Kafka
- 拉取Kafka镜像,在Kafka的官网文档有提供docker镜像拉取命令

- 使用docker运行Kafka

3、Kafka的简单使用
(1)使命令脚本kafka.topics.sh创建Topic,bin/kafka-topics.sh --create --topic topicName --bootstrap-server localhost:9092
(2)生产者
使用kafka.producer.sh需指定两个必要的参数--topic ,--bootstrap-server,也可通过kafka.producer.sh --help查看更多参数,示例向--topic hello发送消息kafka-console-producer.sh --topic hello --bootstrap-server localhost:9092
(3)消费者
使用kafka-console-consumer.sh脚本,同样需要指定上述两个必须参数./kafka-console-consumer.sh clear --topic hello --bootstrap-server localhost:9092

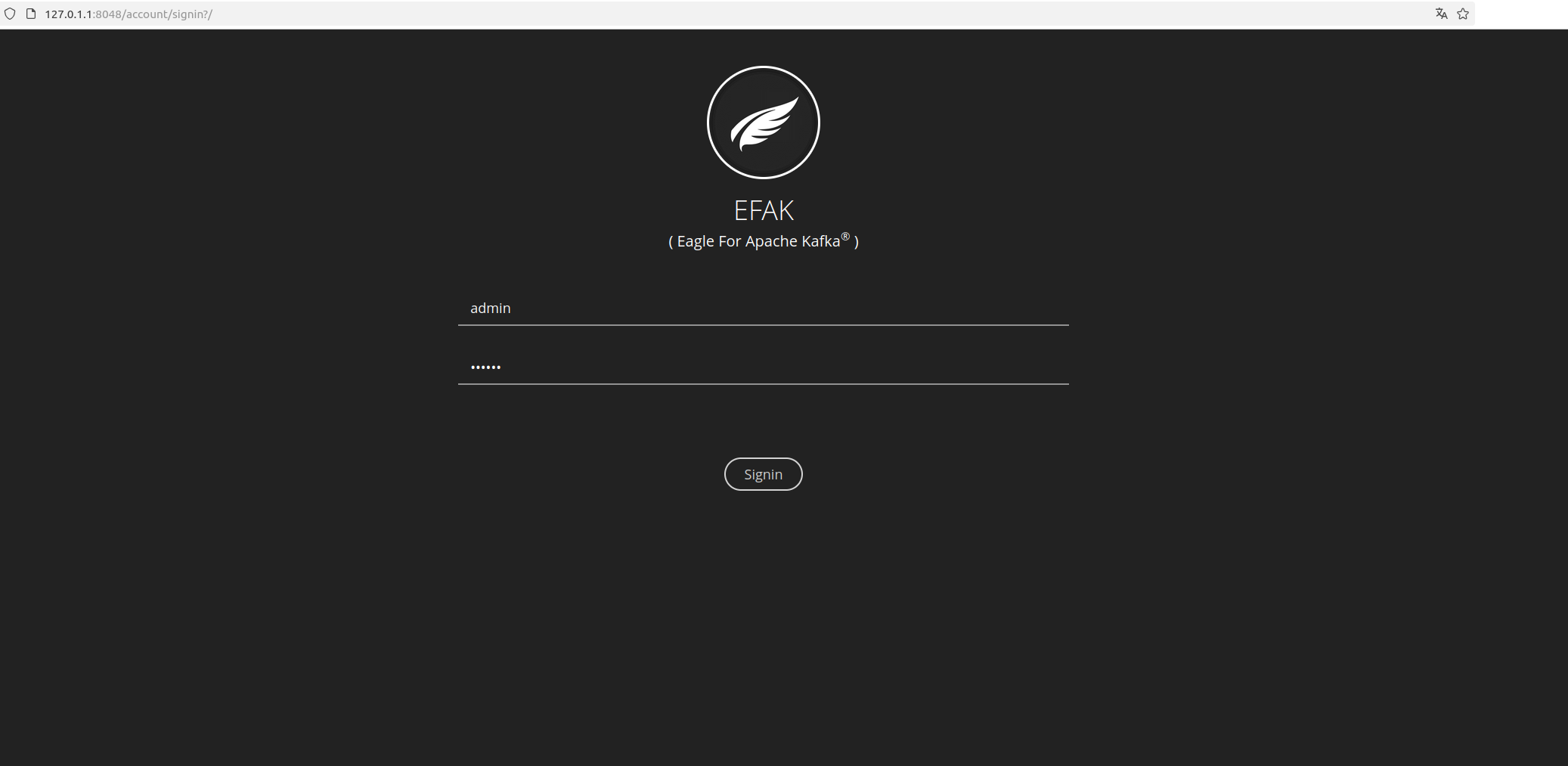
4、kafka图形化工具
-
EFAK,在官网下载解压安装。
-
配置
EFAK依赖MySQL,以Zookeeper方式启动Kafka,需要创建ke数据库。创建完之后修改conf目录下的
system-config.properties配置文件中的Zookeeper配置和MySQL数据库配置。并需要在/etc/profile配置环境变量export KE_HOME=/usr/local/efak-web-3.0.1;export PATH=$PATH:$KE_HOME/bin -
原神启动!!!
执行脚本
bin/ke.sh start
浏览器访问