大数据架构技术上------搭建分布式Hadoop集群
文章目录
- 大数据架构技术上------搭建分布式Hadoop集群
-
- 一、概念补充
- 二、系统搭建与环境准备
- 三、搭建HDFS服务
- 四、搭建YARN服务
- 五、管理HDFS节点
- 六、管理YARN节点
- [七、部署Hadoop NFS Gateway](#七、部署Hadoop NFS Gateway)
-
- [NFS Gateway 简述](#NFS Gateway 简述)
- NFS网关节点准备工作
- 配置代理用户
- 重启Hadoop服务
- NFS网关节点同步文件
- 启动NFS网关服务
- 启动rpcbind映射代理服务
- 启动nfs3服务
- 验证客户端挂载
一、概念补充
部署模式
单机:在一台机器上部署
伪分布式:在一台机器上部署,区分多个角色管理
完全分布式:多台机器节点组成集群,不同角色部署在不同机器上
三大核心组件
HDFS
分布式存储层,数据存储管理
Client:客户端,切分文件,访问HDFS的接口;与NameNode交互,获取文件位置信息;与DataNode交互,读写数据
Block:数据块,默认128M,多副本存储
NameNode:Master节点,元数据管理决定了文件切片存哪,管理HDFS名称空间和数据块映射信息,配置副本策略,处理Client对于元数据操作请求
DataNode:Slave节点,数据存储,定期向NameNode汇报自身所持有的数据块信息
SecondaryNameNode:辅助NameNode,定期合并元数据fsimage和fsedits推送给NameNode分担其工作量,但不具备NameNode的故障转移(非高可用的故障转移)功能
fsimage:元数据镜像文件,存储名称空间和数据库的映射信息元数据信息
edits:元数据操作日志文件,记录数据变更日志,可恢复fsimage
MapReduce(H1老架构)
分布式计算框架层,将计算任务分发到多台机器上执行,将大任务拆成小任务并发执行最后将结果合并,在H1架构中MapReduce既是计算框架又是资源调度器
JobTracker:Master节点唯一,负责资源监控、作业调度和错误处理,拆解任务分派给TaskTracker,即只负责作业的调度而不实际处理具体作业任务
TaskTracker:Slave节点多台,运行MapTask和ReduceTask,负责执行JobTracker分配的任务,定期汇报状态信息给JobTracker
MapTask:解析每条数据记录,传递给用户编写的map()并执行;将输出结果写入本地磁盘,如果为map-only作业直接写入HDFS
ReduceTask:远程从MapTask获取数据,对数据进行排序,将结果按照分组传递给用户编写的reduce函数执行
Yarn(H2老架构)
分布式资源管理层,负责集群资源的管理和作业调度。在H2架构中Yarn核心组件的ResourceManager和NodeManager等价替换了 MapReduce中的JobTracker和TaskTracker
ResourceManager:Master节点唯一,负责处理客户端请求的资源分配和调度,启动/监控ApplicationMaster,监控NodeManager状态
ApplicationMaster:每个作业一个,负责数据切分、为应用程序申请资源、分配内部任务调度、任务监控容错等工作
Container:任务运行环境的抽象,封装了CPU、内存等,启动命令等待任务运行相关的信息资源分配和调度
NodeManager:Slave节点多台,负责单个节点上的资源管理,处理来自ResourceManager和ApplicationMaster的命令
是Yarn的两大核心组件
MapReduce 与 Yarn体系概念重构(H3新核心)
在3.x系列中MapReduce作业的调度已经完全由Yarn的ApplicationMaster接管,Yarn是整个资源管理的核心而MapReduce只是运行在前者之上的计算框架
具体到环境里:在3.x系列集群中具体到作业分配多少内存和CPU、作业并发量、如何公平的分配性能资源、节点宕机时调度中的作业如何处理,但不懂具体的业务,就是yarn需要解决的问题。而MapReduce不再负责资源管理只是纯粹的计算逻辑层
新架构中的Client提交作业后,RM在NM上启动AM,AM向RM注册并申请容器资源,RM分配资源和容器给AM,MRAppMaster将作业切分Map/Reduce在容器内分别运行,NM节点接收AM指令启停容器
二、系统搭建与环境准备
系统规划
| 主机名 | 硬件性能 | 部署角色 | 组件服务 |
|---|---|---|---|
| 192.168.8.20 hadoop-master | 4C8G 20G | Namenode, SecondaryNamenode, ResourceManager | HDFS,Yarn |
| 192.168.8.21 hadoop-node1 | 2C6G 20G | Datanode, NodeManager | HDFS,Yarn |
| 192.168.8.22 hadoop-node2 | 2C6G 20G | Datanode, NodeManager | HDFS,Yarn |
| 192.168.8.23 hadoop-node3 | 2C6G 20G | Datanode, NodeManager | HDFS,Yarn |
| 192.168.8.24 hadoop-node4 | 2C6G 20G | Datanode 与 NodeManager 扩容 | HDFS,Yarn |
| 192.168.8.25 hadoop-nfsgw | 2C6G 20G | NFS3, rpcbind | NFSGateway |
初始化虚拟机环境
创建对应的虚拟机,案例使用Rocky Linux 10镜像资源最简化安装系统,试验机密码默认123456,更改ip地址与系统规划表格内对应
Hadoop 3.x官方支持的 JDK版本为8、11 和 17,案例使用的 Java 21并不在官方明确支持的列表中,在文档前期部署集群时没有兼容性异常问题,但文档后期高可用部分出现master节点通讯异常问题,java版本在高可用案例中降级至17
bash
# 设置ip地址
nmcli connection modify ens160 ipv4.method manual ipv4.addresses 192.168.8.2_/24 ipv4.gateway 192.168.8.254 autoconnect yes
# 重启网卡
nmcli connection up ens160使用setup-dev-env.sh脚本初始化虚机环境
bash
#!/bin/bash
set -e
echo "=== Rocky Linux 10 开发环境配置脚本 ==="
# 0. 系统配置
echo ">>> 系统配置..."
# 卸载防火墙、图形界面,切换字符界面,关闭selinux
systemctl disable firewalld --now
dnf remove -y firewalld
systemctl set-default multi-user.target
systemctl isolate multi-user.target
# 删除 X Window System(通用图形底层)
sudo dnf remove -y xorg-x11-\*
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
# 设置DNS解析
echo "nameserver 223.5.5.5" >> /etc/resolv.conf
echo "nameserver 119.29.29.29" >> /etc/resolv.conf
# 1. 包管理器更新与清理
echo ">>> 更新yum源..."
# 配置阿里云源
sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://dl.rockylinux.org/$contentdir|baseurl=https://mirrors.aliyun.com/rockylinux|g' \
-i.bak \
/etc/yum.repos.d/rocky*.repo
echo ">>> 配置扩展仓库..."
# 安装EPEL并替换为阿里云镜像
dnf install -y epel-release
dnf config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's/$releasever/9/g' /etc/yum.repos.d/docker-ce.repo
# 启用CRB仓库(CodeReady Builder,之前叫PowerTools)
dnf config-manager --set-enabled crb
# 更新系统
dnf update -y
# 删除孤立的依赖包
dnf autoremove -y
# 清理缓存
dnf clean all
# 2. 安装开发工具
echo ">>> 安装开发工具..."
# 开发工具组(包含gcc、g++、make等)
dnf groupinstall -y "Development Tools"
# 安装依赖
dnf install -y dnf-utils device-mapper-persistent-data lvm2
# 安装java环境
dnf install -y java-17-openjdk-devel
# 安装 pip,rocky自带python
dnf install -y python3-pip
# 安装常用工具
dnf install -y createrepo_c vim-enhanced bash-completion wget curl git tree htop ncdu net-tools bind-utils telnet lsof unzip zip sshpass maven
# 安装Docker
dnf install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
dnf install -y docker-ce --allowerasing
# 安装MySQL
dnf install -y mysql8.4-server.x86_64
# 安装 Ansible
pip install ansible
# 清理临时文件
dnf makecache
dnf clean all
# 3. 配置环境变量
echo ">>> 配置环境变量..."
# 设置Docker镜像源
mkdir -p /etc/docker
tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.xuanyuan.me",
"https://docker.m.daocloud.io",
"https://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.baidubce.com",
"https://docker.1ms.run",
"https://registry-1.docker.io"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
# 设置环境变量并重载配置
cat >> ~/.vimrc << 'EOF'
" Tab 设置为 2 个空格
set tabstop=2 " Tab 显示的宽度为 2 个空格
set shiftwidth=2 " 缩进宽度为 2 个空格
set expandtab " 将 Tab 键转换为空格
EOF
sed -i '2i # 历史命令增强\nexport HISTSIZE=10000\nexport HISTFILESIZE=20000\nexport HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S "' ~/.bashrc
echo 'export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))' >> ~/.bashrc
echo 'export PATH=$JAVA_HOME/bin:$PATH' >> ~/.bashrc
source /etc/profile.d/bash_completion.sh
source ~/.bashrc
echo 1 > /proc/sys/net/ipv4/ip_forward
# 4. 设置启动服务与自启
echo ">>> 设置服务自启..."
# 启动MySQL
systemctl enable mysqld --now
# 启动Docker
systemctl enable docker --now
# 验证各组件版本
echo "=== 配置完成!验证各组件版本 ==="
echo "=== Java ===" && java --version
echo "=== Python ===" && python3 --version
echo "=== Pip ===" && pip3 --version
echo "=== Ansible ===" && ansible --version
echo "=== Ansible-doc ===" && ansible-doc -l | wc -l
echo "=== MySQL ===" && mysql --version
echo "=== Docker ===" && docker --version
echo "=== Docker Compose ===" && docker compose version
echo "=== 验证完成正在重启, 15秒后生效 ==="
sleep 15
reboot配置ssh免密
bash
# 生成密钥
ssh-keygen
# 传输密钥
for i in 20 21 22 23
do
sshpass -p "123456" ssh-copy-id -o StrictHostKeyChecking=no root@192.168.8.$i
done搭建ansible节点环境
bash
# 创建ansible目录
mkdir /ansible/{collections,roles,template}
cd /ansible
# ansible.cfg文件配置信息
cat >> ansible.cfg << 'EOF'
[defaults]
inventory = ./inventory
roles = ./roles
collections = ./collections
remote_user = root
host_key_checking = False
[privilege_escalation]
become = True
become_method = sudo
become_user = root
become_ask_pass = False
EOF
# ----------------------------------------------------
# inventory文件配置信息
cat >> inventory << 'EOF'
[master]
master ansible_host=192.168.8.20
[slave]
node1 ansible_host=192.168.8.21
node2 ansible_host=192.168.8.22
node3 ansible_host=192.168.8.23
[cluster:children]
master
slave
EOF
# 测试ansible结果
ansible cluster -m ping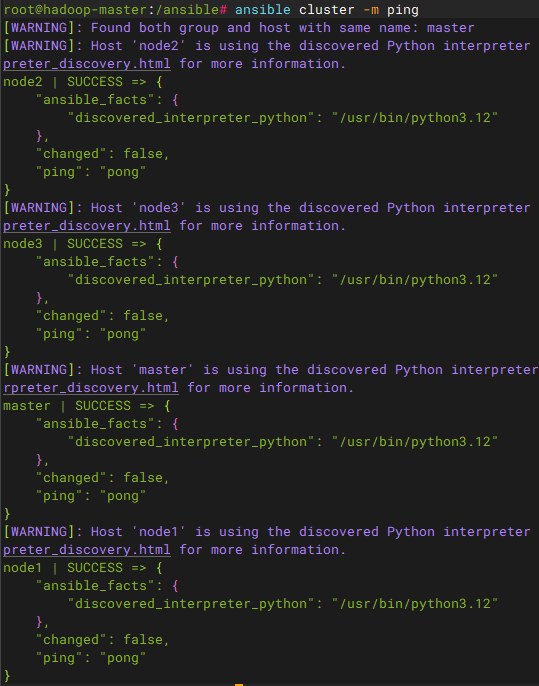
配置hosts解析
编写playbook修改hosts并更新主机名统一管理,使集群中各个节点都能识别对方
Hadoop强依赖于hosts解析
bash
# 进入ansible路径
cd /ansible
# 创建hosts的j2模板
cat >> template/hosts.j2 << 'EOF'
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.8.20 hadoop-master master
192.168.8.21 hadoop-node1 node1
192.168.8.22 hadoop-node2 node2
192.168.8.23 hadoop-node3 node3
EOF
# 编写playbook剧本init_hosts.yml
cat >> init_hosts.yml << 'EOF'
---
- name: set hostname and update hosts
hosts: cluster
become: yes
vars:
hostname_mapping:
master: hadoop-master
node1: hadoop-node1
node2: hadoop-node2
node3: hadoop-node3
tasks:
# 1. set hostname
- name: set hostname
hostname:
name: "{{ hostname_mapping[inventory_hostname] }}"
# replace hosts file
- name: deploy unified hosts file
template:
src: template/hosts.j2
dest: /etc/hosts
backup: yes
owner: root
group: root
mode: '0644'
EOF
# 执行剧本
ansible-playbook init_hosts.yml
# 更改后验证结果
ansible cluster -m shell -a "cat /etc/hosts"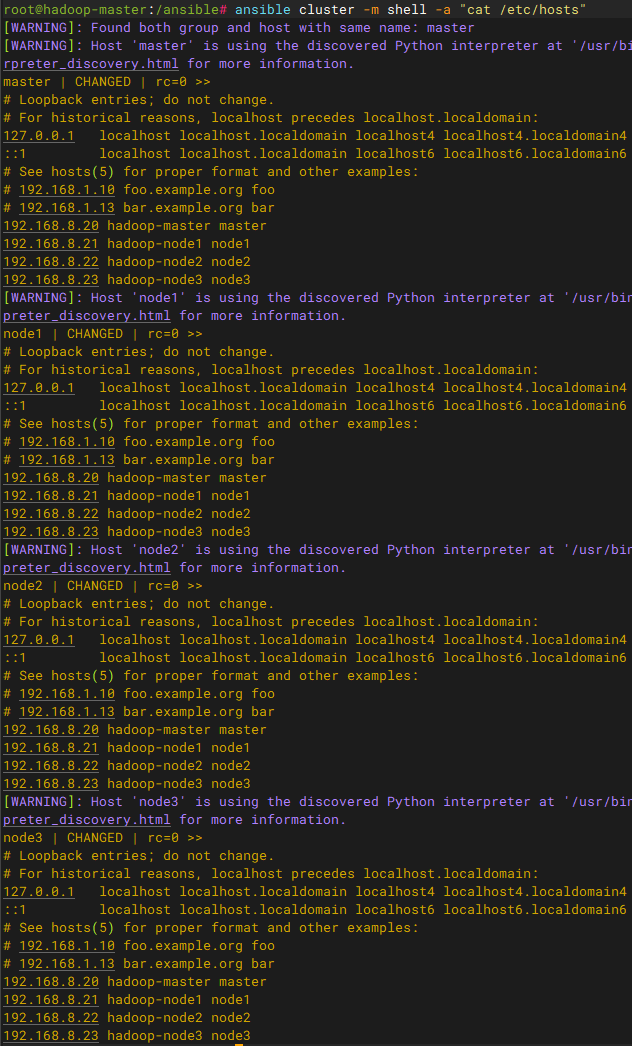
下载hadoop
从官网下载hadoop的tar包拷贝到master节点,并解压到/usr/local/hadoop目录。案例使用3.4.3版本
三、搭建HDFS服务
HDFS配置文件说明
配置文件目录:/usr/local/hadoop/etc/hadoop
环境配置文件:hadoop-env.sh,定义了jvm、etc的环境路径
核心配置文件:core-site.xml,定义了hadoop默认公共属性、数据存储位置
HDFS配置文件:hdfs-site.xml,定义hdfs相关配置
节点配置文件:slaves(workers),是datanode节点的配置文件,所有声明的主机都会运行datanode守护进程
注意:Hadoop 2.x 及更早版本使用 slaves 文件来定义 DataNode 和 NodeManager 所在的主机。但从 Hadoop 3.x 开始,这个文件被重命名为 workers
更改配置模板
hadoop的配置模板遵循xml格式,案例提供必要的参数,从官方文档中根据key查找对应的value,所有配置文档在左侧导航栏中Configuration下
xml
<property>
<name>参数名</name>
<value>值</value>
<description>描述内容</description>
</property>hadoop-env.sh配置
JAVA_HOME:指定虚拟机的java环境路径
HADOOP_CONF_DIR:指定hadoop的配置环境路径
core-site.xml配置
fs.defaultFS:指定namenode的地址,文件系统配置参数
hadoop.tmp.dir:指定hadoop所有数据根目录,默认/var/hadoop,非常重要,单独分区或者单独一块硬盘
hdfs-site.xml配置
dfs.namenode.http-address:声明在哪台机器启动namenode
dfs.namenode.secondary.http-address:声明在哪台机器启动secondarynamenode
dfs.replication:指定每个文件的副本数,默认3
workers(slaves)配置
声明datanode节点,一行一个节点,默认是localhost全部改为node1-3
同步配置文件
master节点的配置文件修改完同步给node1-3,确保集群所有节点配置文件相同
bash
for node in node1 node2 node3
do
rsync -axSH --delete /usr/local/hadoop $node:/usr/local/
done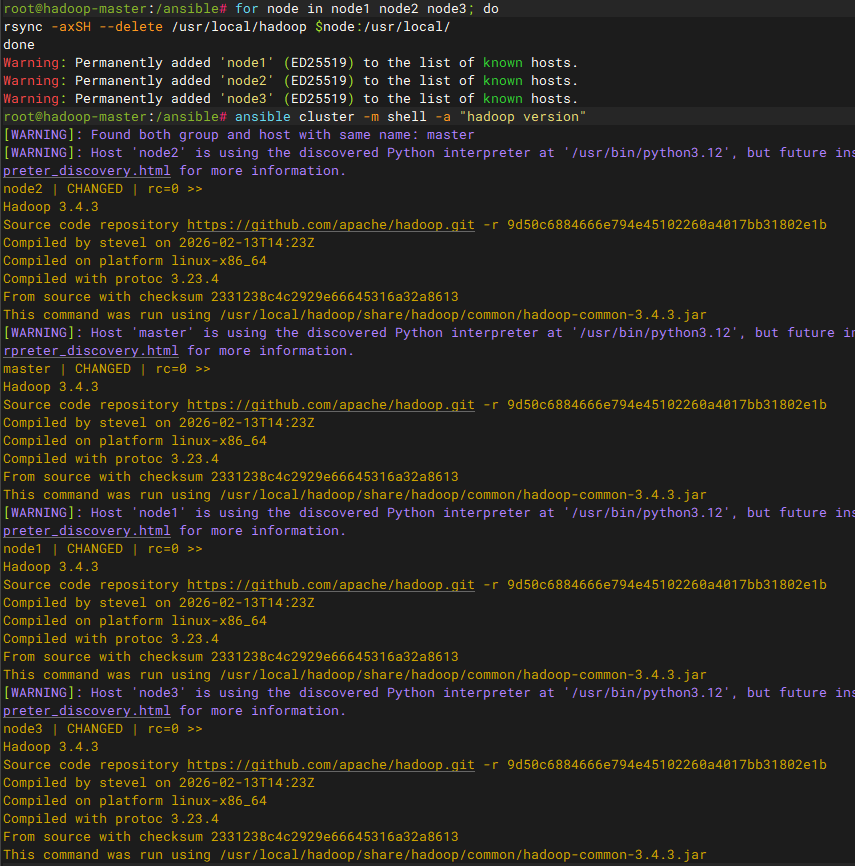
检查slave节点core-site.xml配置文件同步内容
检查slave节点hdfs-site.xml配置文件同步内容
检查slave节点workers配置文件同步内容
启动HDFS服务
初始化HDFS
在namenode中手动创建数据目录:/var/hadoop,datanode节点的数据目录会自动创建
bash
mkdir -p /var/hadoop格式化namenode
bash
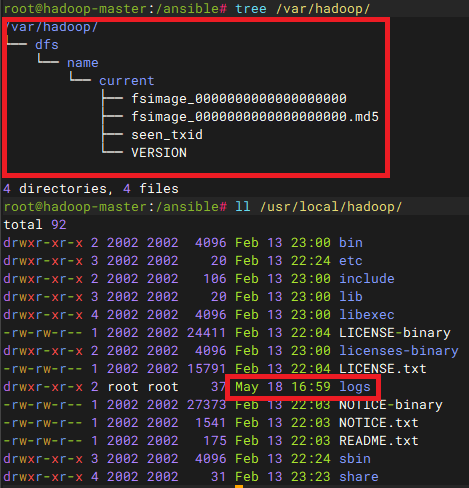
/usr/local/hadoop/bin/hdfs namenode -format在输出的info中看到successfully表示格式化成功,如果有问题紧盯info这一列看红色warn分析具体原因
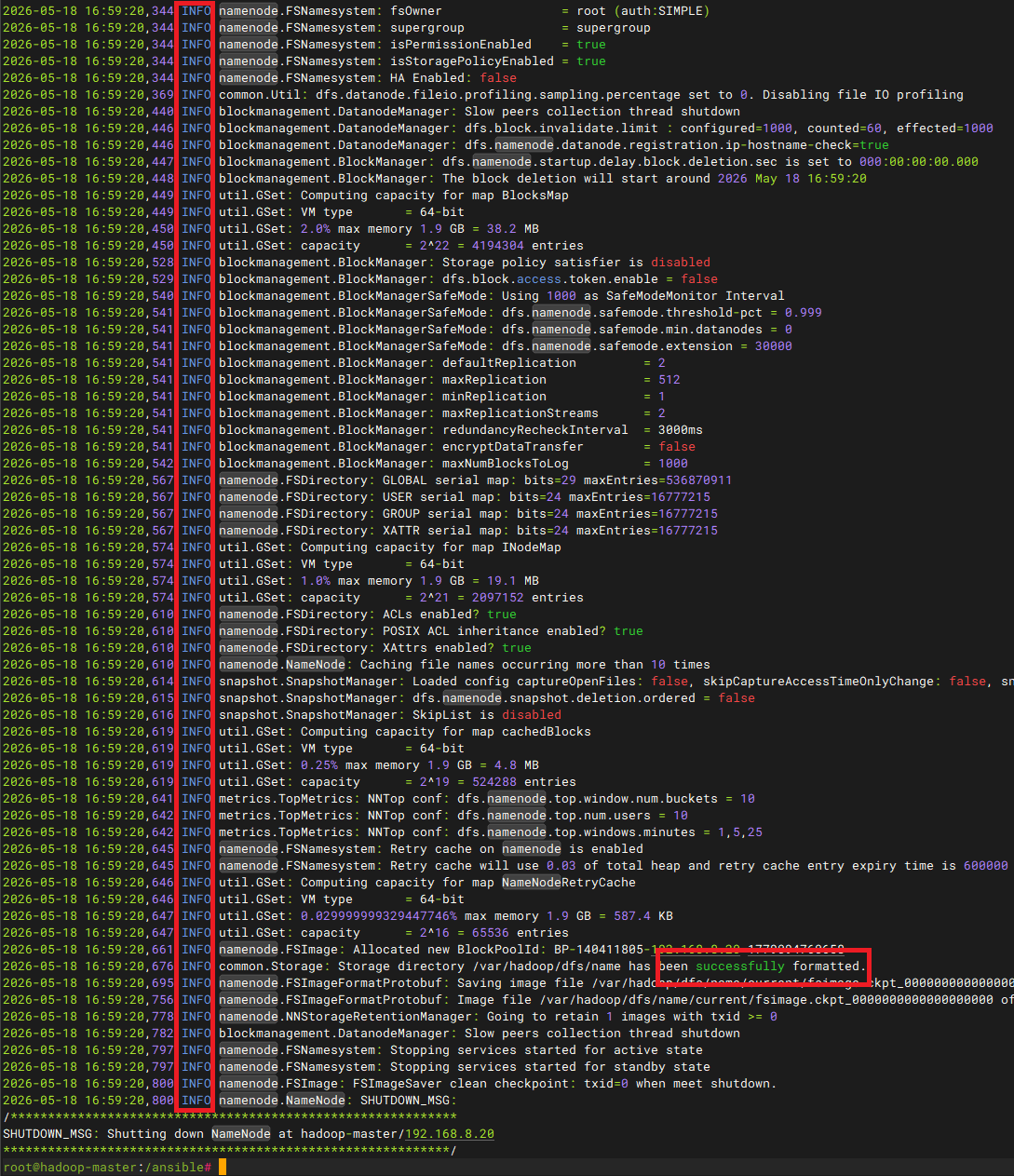
可以看到格式化后不仅多出了logs日志目录,还有集群标识信息、事务记录文件、fsimage文件
启动集群节点
bash
# 在namenode中启动集群
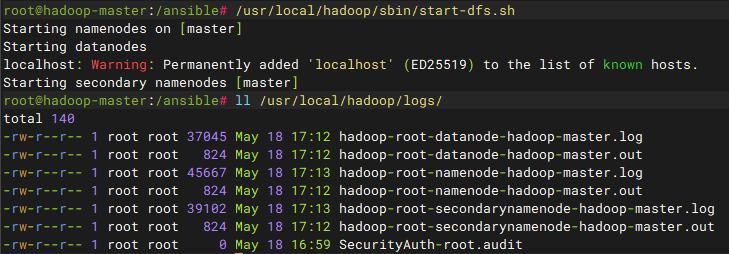
/usr/local/hadoop/sbin/start-dfs.sh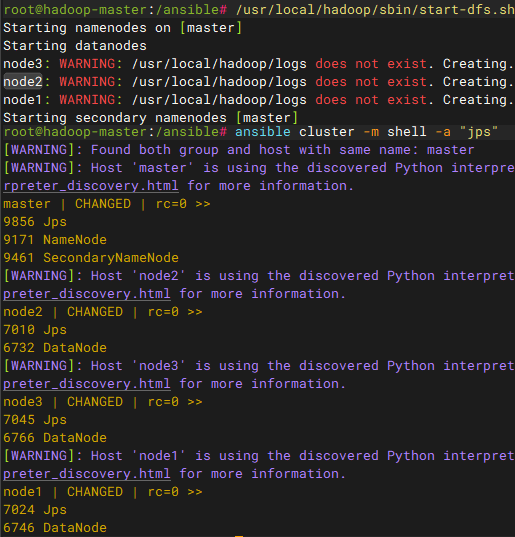
日志说明:名称格式为"服务名-用户名-角色名-主机名.标准输出|系统日志",只存储本机的日志,namenode没有datanode日志,datanode只能去node1-3节点查看
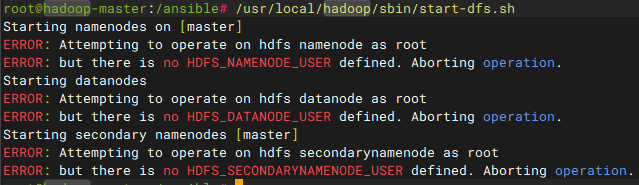
注意:Hadoop 3.x版本出于安全考虑,默认不允许使用root用户来启动集群守护进程
需要在start-dfs.sh和stop-dfs.sh脚本开头添加下列内容
bash# 文件中"#!/usr/bin/env bash"下添加 HDFS_DATANODE_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
验证集群
bash
/usr/local/hadoop/bin/hdfs dfsadmin -report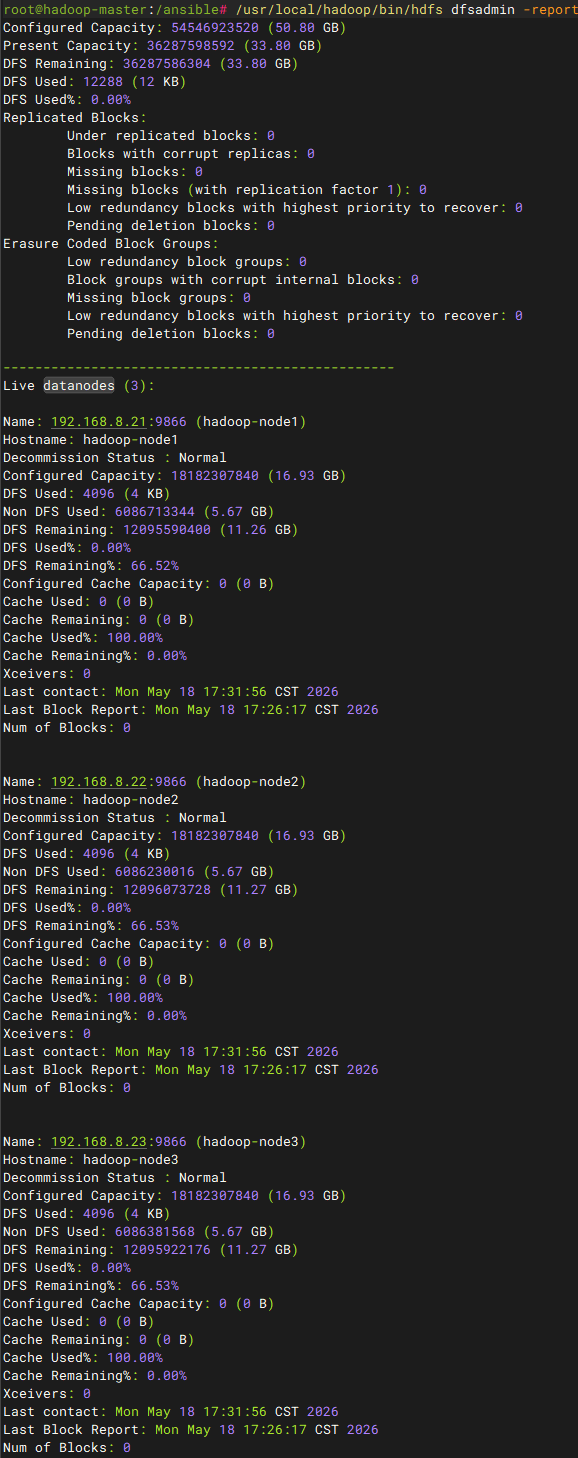
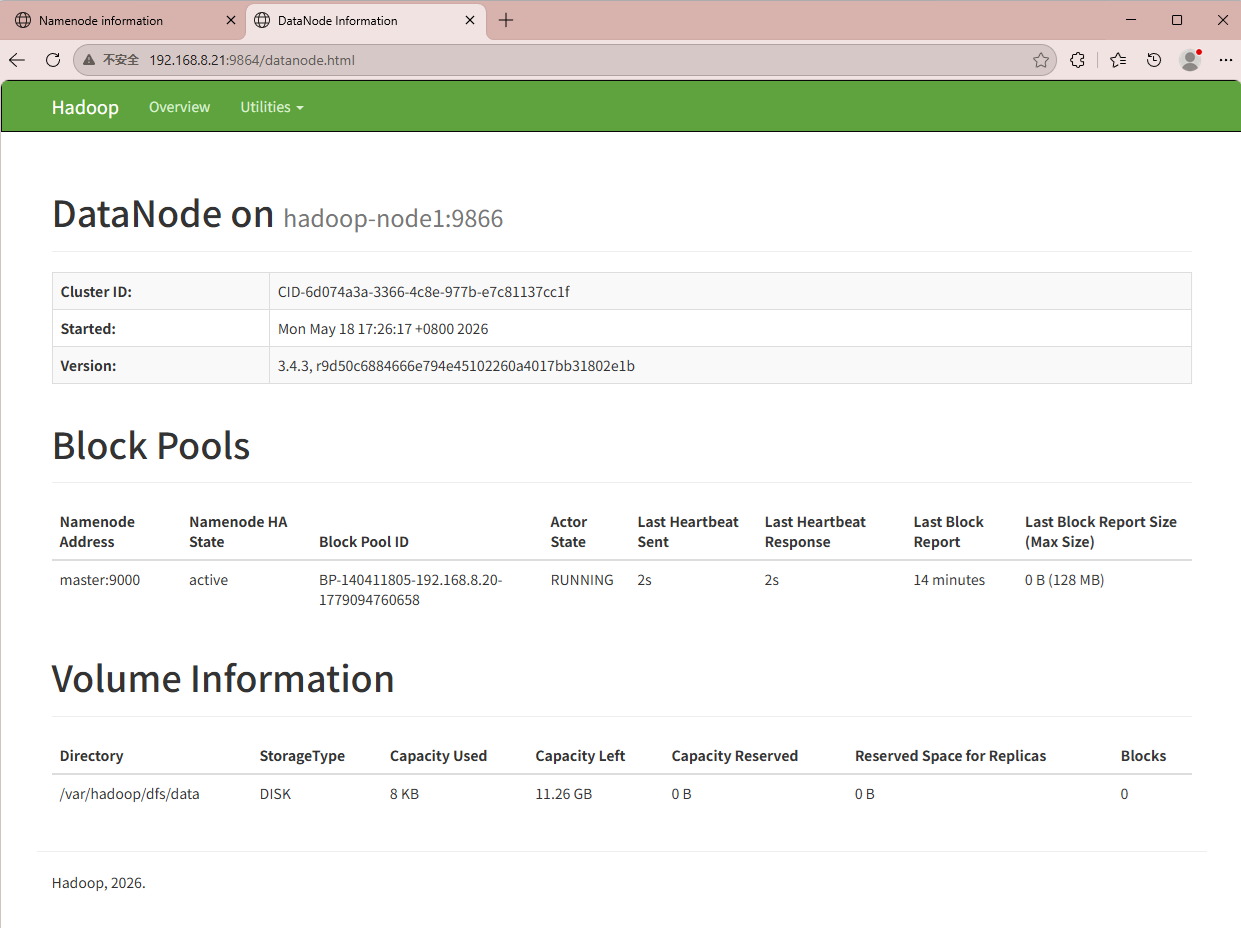
验证web页面DN节点信息
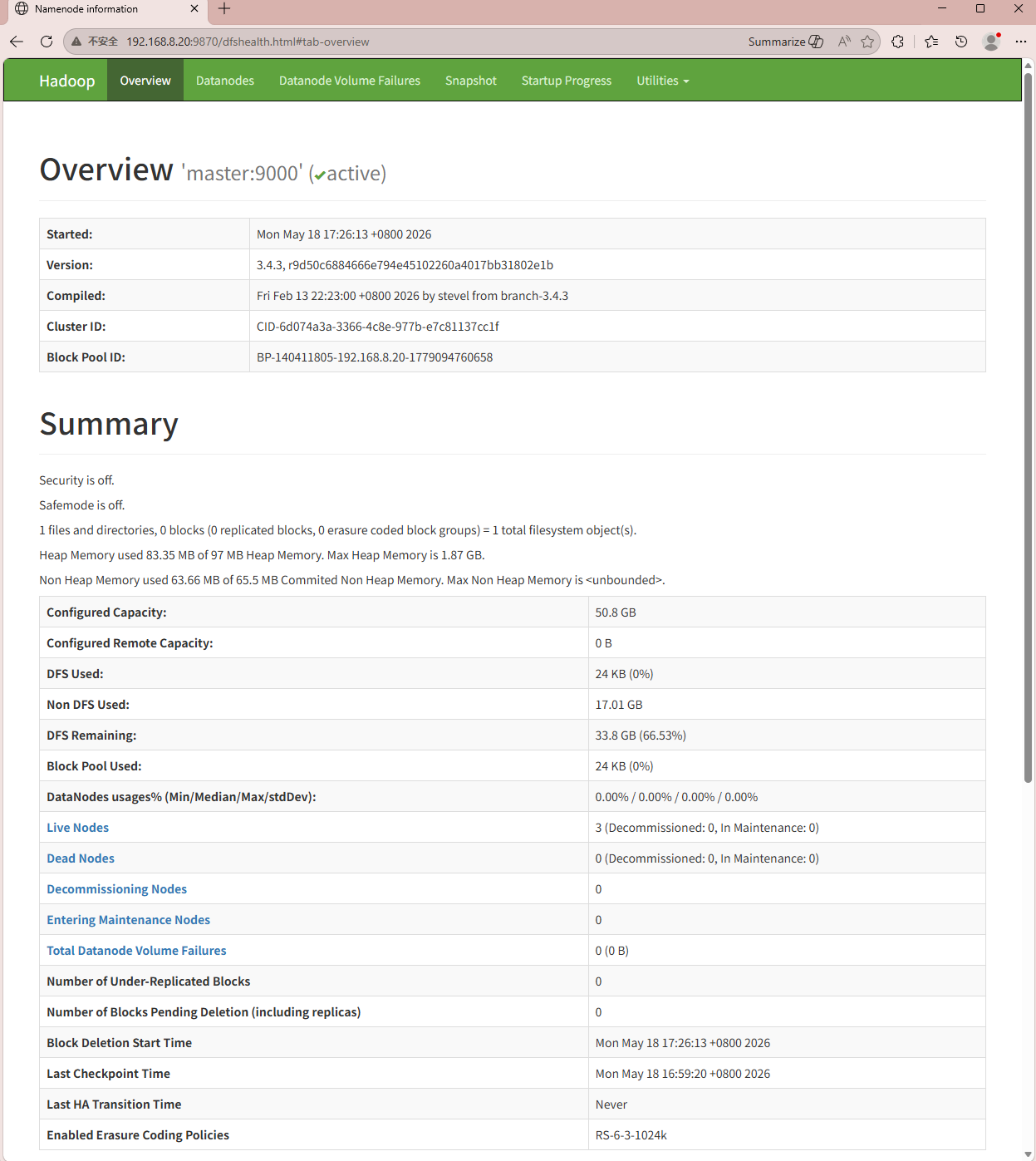
验证web页面NN节点信息
验证web页面SN节点信息
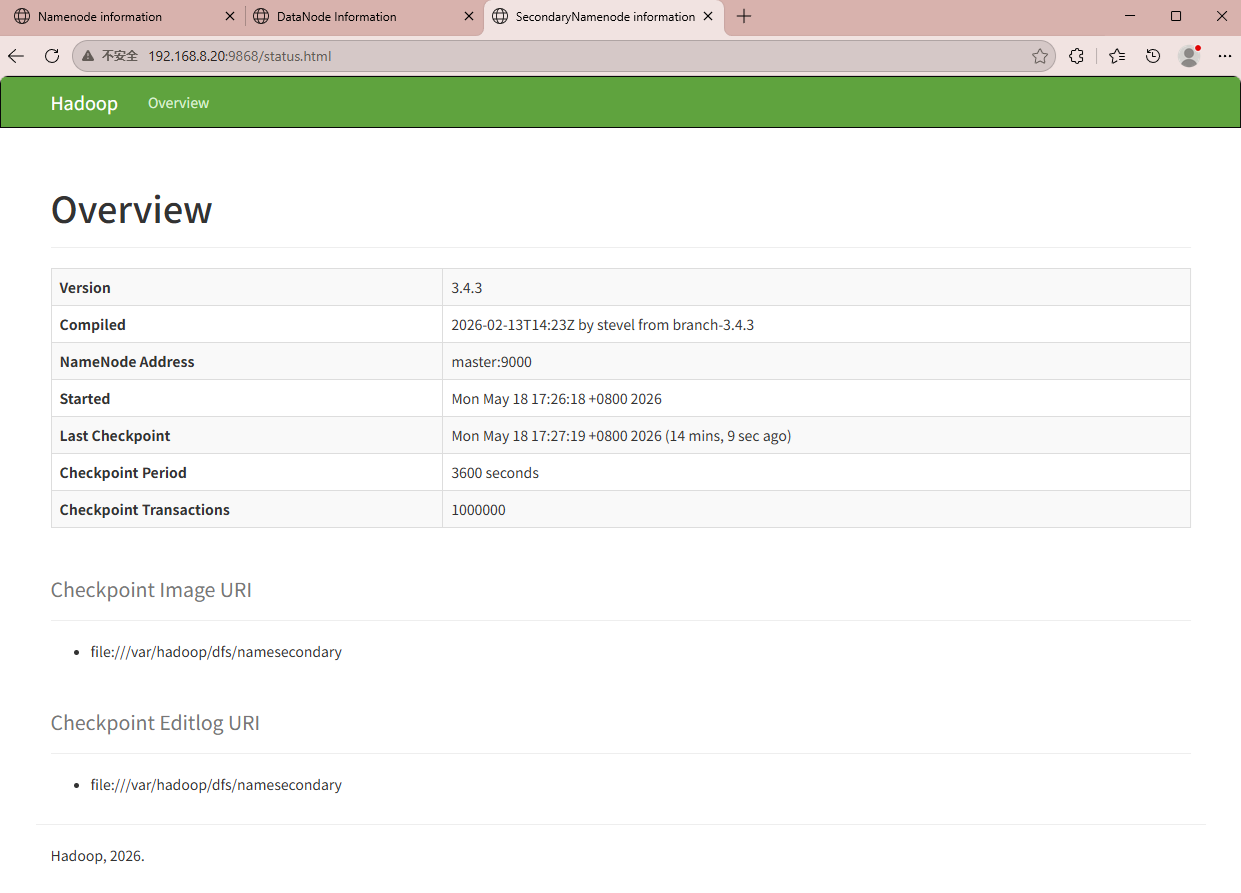
验证HDFS服务工作
bash
# 查看目录
/usr/local/hadoop/bin/hdfs dfs -ls /
# 创建目录
/usr/local/hadoop/bin/hdfs dfs -mkdir -p /file.name
# 创建文件
/usr/local/hadoop/bin/hdfs dfs -touchz /path/.../filename
# 上传文件
/usr/local/hadoop/bin/hdfs dfs -put src_filepath dest_filepath
# 下载文件
/usr/local/hadoop/bin/hdfs dfs -get src_filepath dest_filepath
# 删除文件
/usr/local/hadoop/bin/hdfs dfs -rm /path/.../filename
# 删除目录
/usr/local/hadoop/bin/hdfs dfs -rm -r /path四、搭建YARN服务
datanode作为存储节点,主要消耗磁盘IO存储数据
nodemanager作为计算节点,消耗cpu和内存资源用于计算
所以将datanode和nodemanager放在同一节点上,充分利用硬件资源
YARN配置文件说明
计算框架配置文件:mapred-site.xml配置
YARN配置文件:yarn-site.xml配置
https://hadoop.apache.org/docs/r3.4.3/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
更改MapReduce配置模板
xml
<!-- 与hdfs相同,都使用xml格式 -->
<property>
<name>参数名</name>
<value>值</value>
<description>描述内容</description>
</property>mapred-site.xml配置
mapreduce.framework.name:指定 MapReduce 作业运行框架的核心参数
注意:单机部署所有任务在单个jvm进程顺序执行,不需要通讯与yarn服务,value只配置local;在分布式部署中作业提交给yarn的 ResourceManager,由它统一分配资源、调度任务到各 NodeManager 上并行执行,local无法跨节点资源管理和容错,value需要改为yarn
yarn.app.mapreduce.am.env:启动ApplicationMaster 容器,设置 AM 进程启动时的环境变量
mapreduce.map.env:启动Map Task 容器,设置 Map 任务容器启动时的环境变量
mapreduce.reduce.env:启动Reduce Task 容器,设置 Reduce 任务容器启动时的环境变量
注意:Hadoop 2.x 通常不需要显式设置这三个参数,2.x 和 3.x 在 YARN 容器 classpath 的构建机制上有差异。
这三项的 value 都是 "HADOOP_MAPRED_HOME=/usr/local/hadoop",意思是让 YARN 在启动对应容器时,将 HADOOP_MAPRED_HOME 这个环境变量通过这三个参数注入到YARN容器内部。容器被 NodeManager 拉起后,需要知道 Hadoop 的安装目录进而根据目录找到 MapReduce 的 jar 包,才能把包含 MRAppMaster 类等依赖加入 classpath,对于容器来说只有构建正确的 classpath,才能加载到 MRAppMaster 等类
打个比方:mapreduce.framework.name 相当于告诉快递公司"送到哪个仓库",而 HADOOP_MAPRED_HOME 相当于告诉仓库工人"工具箱在哪里"。只设了前者,任务确实能提交到 YARN,但容器拿到任务后找不到工具(jar 包)
yarn-site.xml配置
yarn.resourcemanager.hostname:指定 ResourceManager 所在节点
yarn.nodemanager.aux-services:配置 NodeManager 上运行的附属服务,用于处理 MapReduce 任务中至关重要的"洗牌"(Shuffle)过程。只运行 MapReduce 需要配置成 mapreduce_shuffle
yarn.nodemanager.resource.memory-mb:节点可用内存
yarn.nodemanager.resource.cpu-vcores:节点可用 CPU 核数
修改完后,将master节点的配置文件同步给node1-3,确保集群所有节点配置文件相同
bash
for node in node1 node2 node3
do
rsync -axSH --delete /usr/local/hadoop/etc/hadoop $node:/usr/local/hadoop/etc/
done启动YARN服务
在namenode节点启动YARN服务
bash
/usr/local/hadoop/sbin/start-yarn.sh注意:YARN服务启动脚本与HDFS相同,3.x 系列的版本出于安全考虑,在启动脚本中没有默认允许 root 用户直接操作
与HDFS一样在start-yarn.sh和stop-yarn.sh中添加以下内容
bashYARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
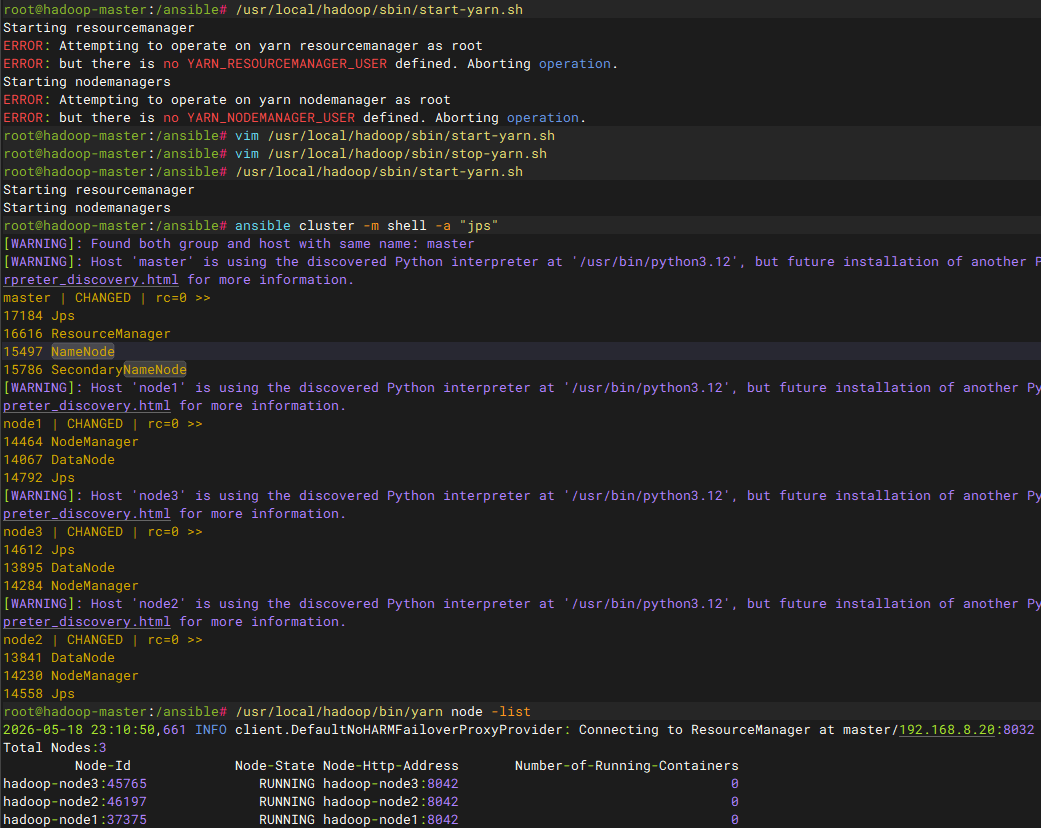
验证YARN服务
查看nodemanager可管理的计算节点
bash
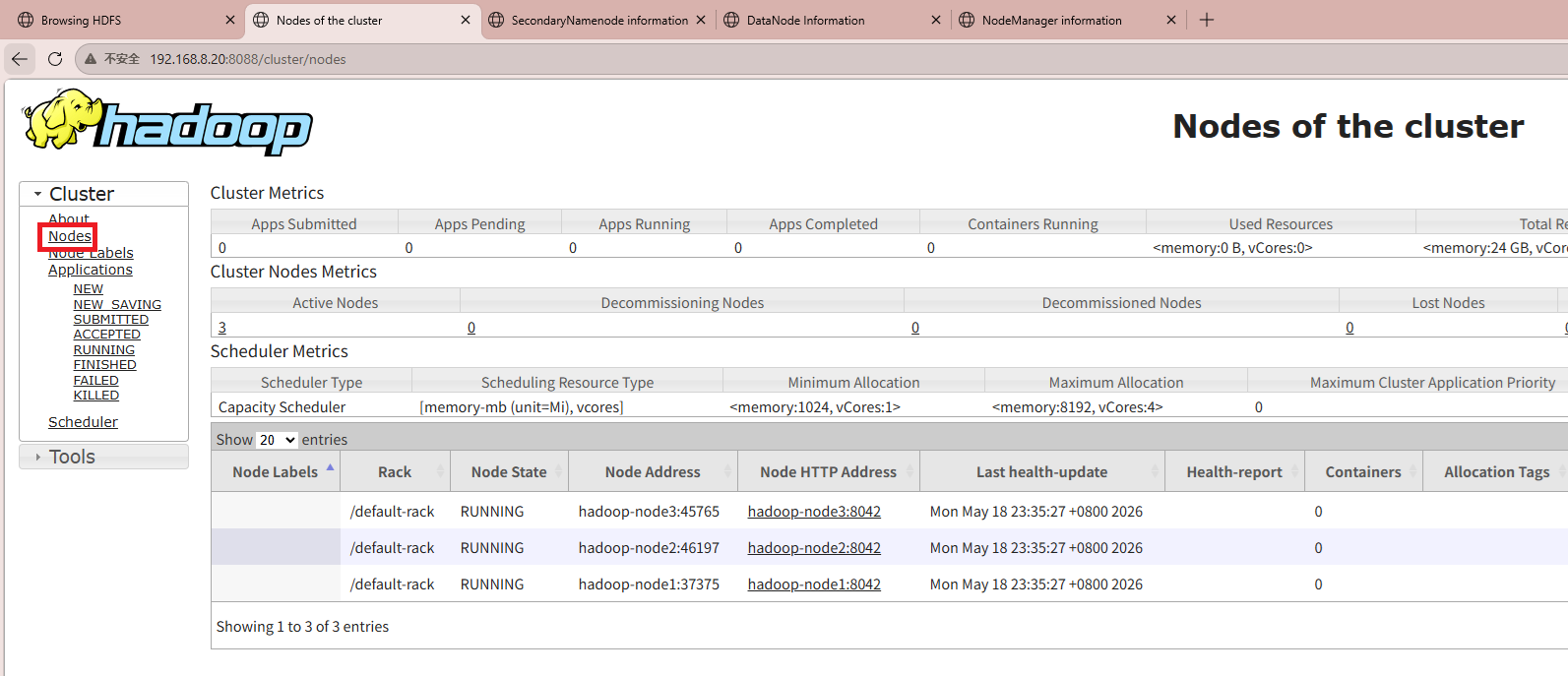
/usr/local/hadoop/bin/yarn node -list在web端查看yarn集群节点信息
五、管理HDFS节点
HDFS节点扩容
新节点环境搭建
创建新的虚拟机node4节点,部署DataNode和NodeManager服务并加入Hadoop集群
bash
## 新环境搭建
# 在新虚拟机设置ip地址
nmcli connection modify ens160 ipv4.method manual ipv4.addresses 192.168.8.24/24 ipv4.gateway 192.168.8.254 autoconnect yes
# 重启网卡
nmcli connection up ens160
# 重新跑一遍环境搭建中的 setup-dev-env.sh 脚本
# 配置ssh免密,在master节点传输密钥
sshpass -p "123456" ssh-copy-id -o StrictHostKeyChecking=no root@192.168.8.24
# 扩充ansible的inventory文件,添加node4便于管理
node4 ansible_host=192.168.8.24
# 更改template/hosts.j2模板,添加node4信息
echo "192.168.8.24 hadoop-node4 node4" >> /ansible/template/hosts.j2
# 更改init_hosts.yml剧本,在vars中新增node4主机名,并运行剧本
node4: hadoop-node4
ansible-playbook init_hosts.yml
# 在namenode节点的workers文件内新增node4节点
ansible cluster -m shell -a "echo 'node4' >> /usr/local/hadoop/etc/hadoop/workers"
# 将namenode的hadoop目录同步给node4新节点
rsync -axSH --delete /usr/local/hadoop node4:/usr/local/
# 清空node4节点Hadoop的log日志
ansible node4 -m shell -a "rm -rf /usr/local/hadoop/logs/*"
## 以上步骤做完后,node4节点就有了跟node1~3一样的环境,同一网段下、相同的hosts、master有当前节点免密权限、被ansible统一管理、同样的hadoop配置启动节点服务
启动node4节点,等待加入集群
bash
ansible node4 -m shell -a "/usr/local/hadoop/sbin/hadoop-daemon.sh start datanode"分配平衡数据
当前所有数据都存储在node1-3节点,扩容新节点后需要将分配平衡数据存储
bash
# 在namenode上设置带宽
/usr/local/hadoop/bin/hdfs dfsadmin -setBalancerBandwidth 500000000
# 分配平衡数据
/usr/local/hadoop/sbin/start-balancer.shHDFS节点下线
迁移数据需要增加配置,告诉hadoop集群删减哪个节点
Hadoop集群的DataNode节点有三种状态
| 正常状态 | 正在迁移 | 迁移完成 |
|---|---|---|
| Normal | Decommissioned in progress | Decommissioned |
注意:在datanode节点删除步骤中,仅当节点状态变成Decommissioned后,才能删除节点
hdfs-site.xml配置
dfs.hosts.exclude:/usr/local/hadoop/etc/hadoop/exclude,在namenode节点指定一个配置文件路径,与hadoop配置文件存放一致
注意:exclude文件用于记录删除节点的名称,与slaves(workers)配置文件内容一样,一行一个节点名称,删除哪个节点就记录哪个节点,并且该文件不同需要同步给各datanode节点
刷新节点
更改完配置后,将删除节点的主机名告诉Hadoop,最后刷新节点开始迁移数据
此时该节点状态由Normal变为Decommissioned in progress,这时不能停止进程,如果停止会导致迁移时数据块的丢失,等待一段时间后但状态变为Decommissioned,说明迁移完成,必要时可以对比一下空间大小,这时才可以停止该节点datanode进程
bash
# 选择下线的主机名称,例如node4
echo "node4" > /usr/local/hadoop/etc/hadoop/exclude
# 刷新节点
/usr/local/hadoop/bin/hdfs dfsadmin -refreshNodes下线节点
在node4节点上停止datanode进程,namenode会等待心跳检测超时后从状态表中删除node4信息
bash
# 等待node4节点的状态变成迁移完成后,删除datanode和nodemanager进程
ansible node4 -m shell -a "/usr/local/hadoop/bin/hdfs --daemon stop datanode"
ansible node4 -m shell -a "/usr/local/hadoop/bin/yarn --daemon stop nodemanager"
# 验证删除结果,查看所有节点的jps
ansible cluster -m shell -a "jps"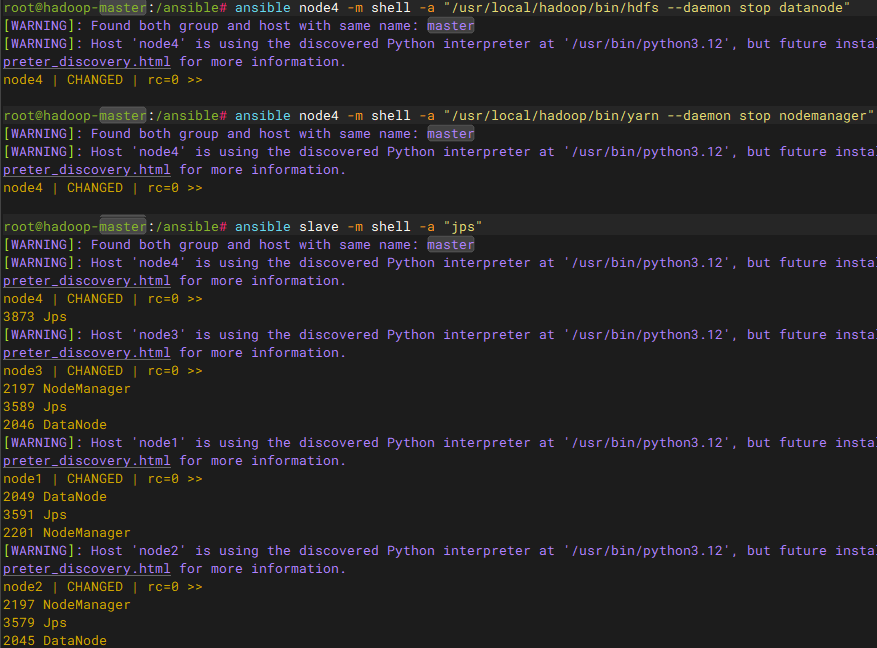
删除exclude文件中记录的node4节点信息
echo "" > /usr/local/hadoop/etc/hadoop/exclude删除所有节点中workers配置内下线的节点主机名
bash
# 更新各节点的workers配置文件
ansible cluster -m lineinfile -a "path=/usr/local/hadoop/etc/hadoop/workers regexp='^node4$' state=absent"
# 验证更改
ansible cluster -m shell -a "cat /usr/local/hadoop/etc/hadoop/workers"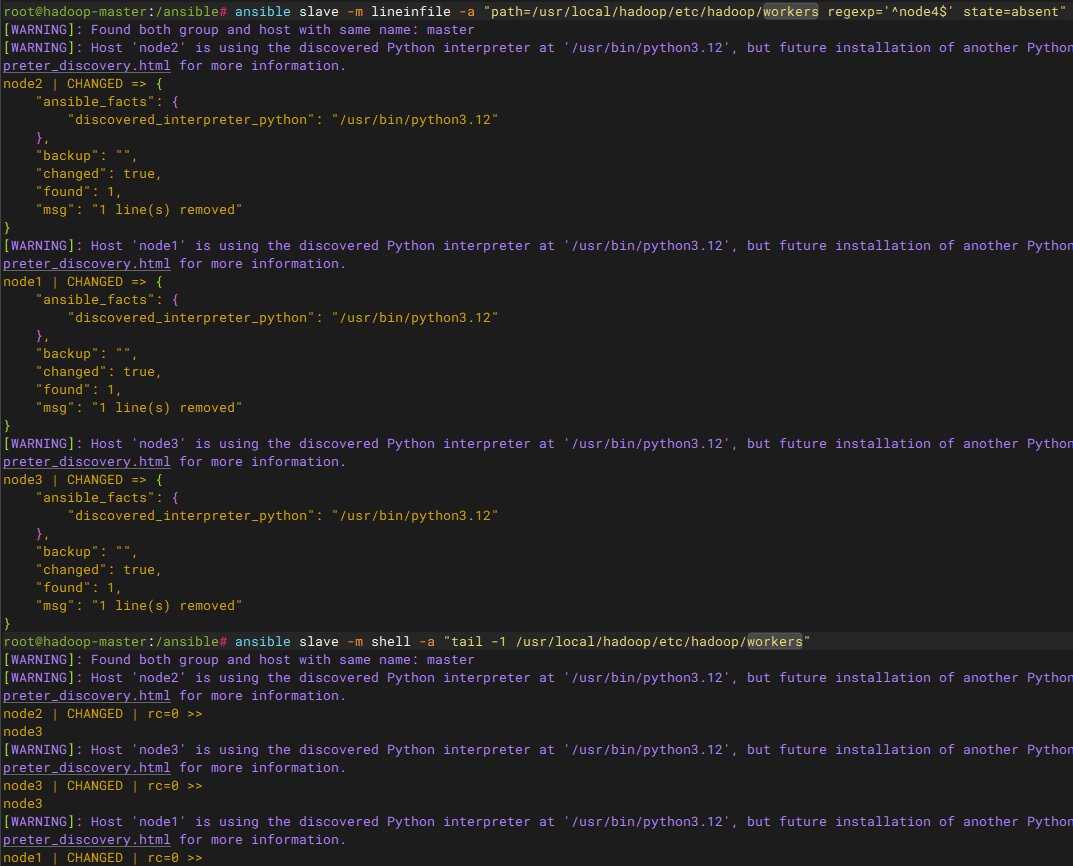
在namenode节点上执行刷新节点命令,刷新exclude文件中的节点信息
bash
# 刷新节点
/usr/local/hadoop/bin/hdfs dfsadmin -refreshNodes
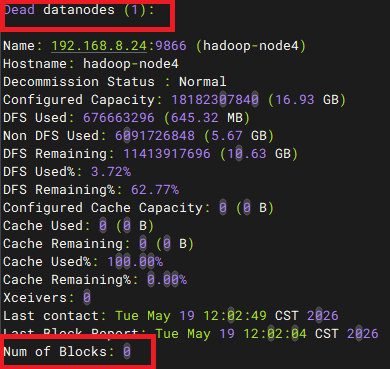
# 查看节点信息,node4已经下线并且存储块为0
/usr/local/hadoop/bin/hdfs dfsadmin -report验证数据
上传数据前记录占用情况,4个node节点总共2516kb忽略不计。上传测试数据大约1011MB
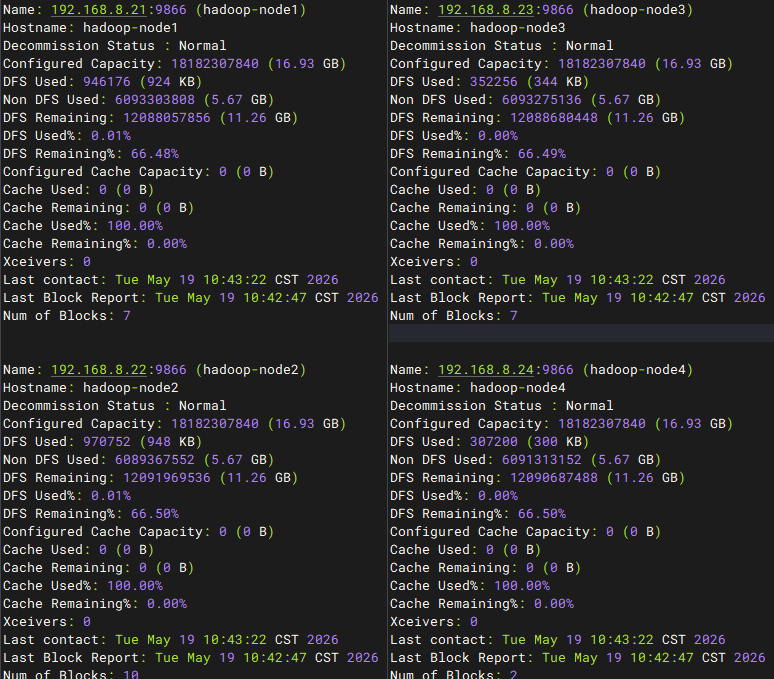
上传数据后记录占用情况,4个node节点总共2038mb(副本数为2)
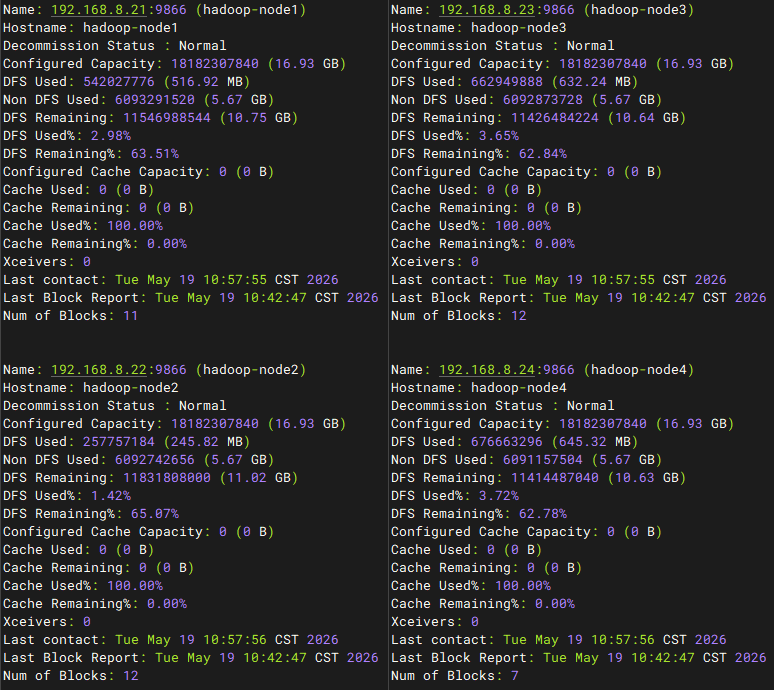
数据迁移后的node1-3节点总共占用2038mb,说明下线node4节点后,node1-3节点的占用与之前4台节点的占用情况一致
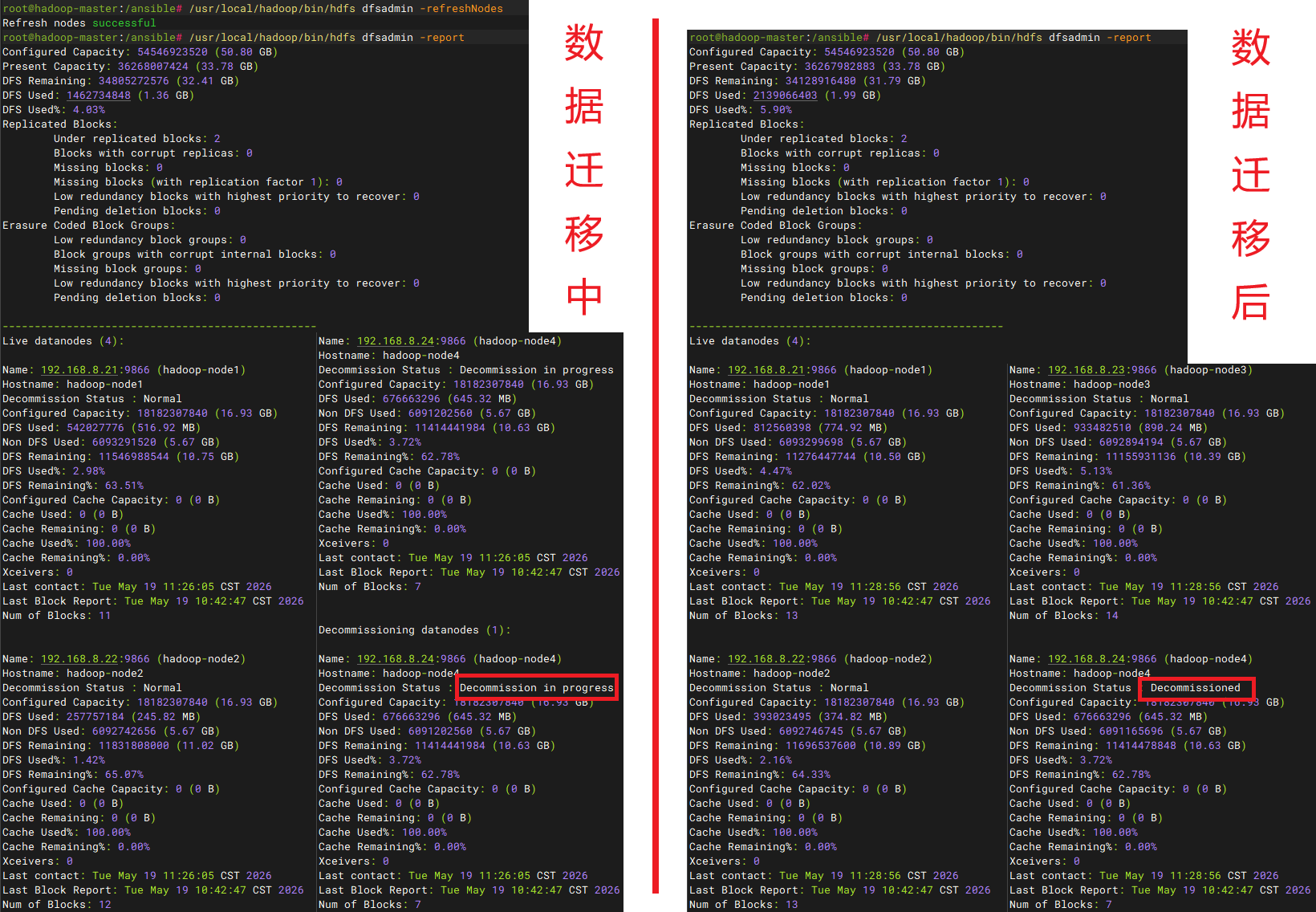
最后再看一遍node4节点下线后的信息,最后的块数量已经是0了,存储数据已经被分别转移到node1-3
六、管理YARN节点
YARN作为计算节点,没有涉及到数据存储,所以不需要像HDFS一样在节点扩缩容时考虑数据问题,得益于此节点管理更简单
YARN节点扩容
新节点环境搭建
bash
## 与HDFS节点扩容一样,如果是新环境可以参照上面重新搞一边,跳过这一步因为案例仍使用之前搭建的node4做测试平台
# 为了防止之前测试结果与某些机制的干扰,先对node4做清理删除日志和临时文件
ansible node4 -m shell -a "rm -rf /usr/local/hadoop/logs/*"
ansible node4 -m shell -a "rm -f /tmp/hadoop-root-nodemanager.pid"
# 重启master节点的ResourceManager服务
/usr/local/hadoop/bin/yarn --daemon stop resourcemanager
/usr/local/hadoop/bin/yarn --daemon start resourcemanager启动节点服务
bash
# ResourceManager管理yarn节点
ansible node4 -m shell -a "/usr/local/hadoop/bin/yarn --daemon start nodemanager"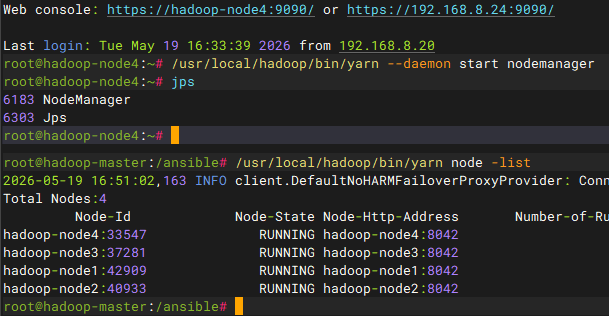
注意:启动节点命令适用于Hadoop 3.x系列,如果是2.x系列启动的命令应该是下面这个
bashansible node4 -m shell -a "/usr/local/hadoop/sbin/yarn-daemon.sh start nodemanager"
验证服务状态
bash
# 查看node4节点的服务
ansible node4 -m shell -a "jps"
# 查看ResourceManager信息
/usr/local/hadoop/bin/yarn node -listYARN节点下线
下线节点
bash
ansible node4 -m shell -a "/usr/local/hadoop/bin/yarn --daemon stop nodemanager"注意:与启动相同如果是2.x系列停止命令应该如下
bashansible node4 -m shell -a "/usr/local/hadoop/sbin/yarn-daemon.sh stop nodemanager"
验证节点信息
bash
ansible node4 -m shell -a "jps"
# yarn有心跳检测机制得等待一段时间,如果着急可以直接重启ResourceManager服务
/usr/local/hadoop/bin/yarn node -list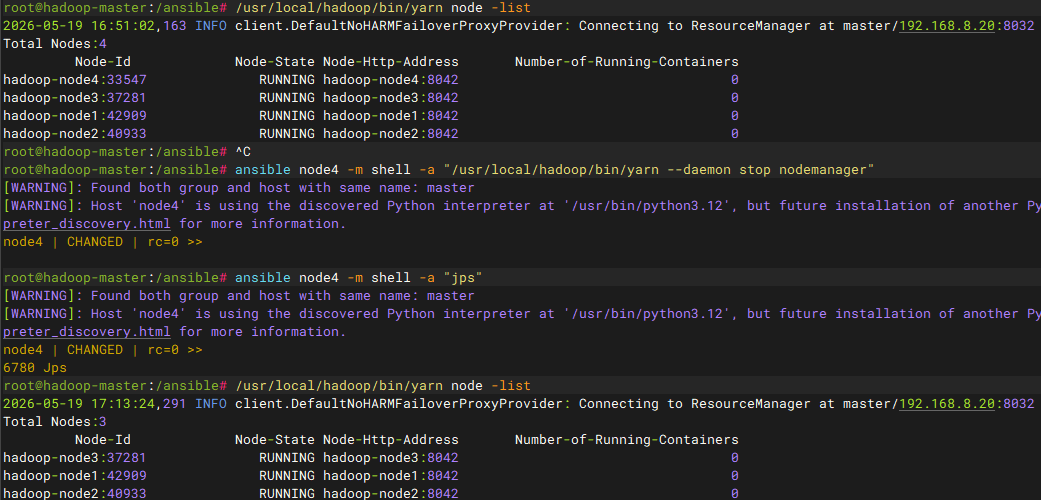
七、部署Hadoop NFS Gateway
NFS Gateway 简述
NFS Gateway 是 Hadoop HDFS 提供的一个基于 NFS(Network File System)协议的网关服务组件,它允许用户通过标准的 NFSv3 协议将 HDFS 文件系统挂载为本地文件系统的一部分,从而实现像操作本地磁盘一样访问 HDFS 中的数据;在如今的26年虽然 3.x 版本中仍得到支持但 JuiceFS 和 Alluxio 在性能、功能和可维护性是更加现代的解决方案
NFS Gateway 作为连接 NFS 客户端与 HDFS 的桥梁,通过 NameNode 获取文件位置信息并访问 DataNode 读写数据,所以NFS网关需要知道 Hadoop 的 NameNode 和 DataNode 地址,为了解决服务器与集群两者不同权限体系之间的映射问题设计了代理用户机制;用户代理的作用在于当挂载HDFS后文件操作请求发送至NFS网关再由预先设置的代理用户向 NameNode 发请求
Hadoop 支持两种身份认证方式:简单认证(Simple)和 Kerberos 认证(Kerberos),两种模式的差异体现在代理用户的身份来源上,在非安全模式下启动nfs网关的操作用户就是代理用户,而官方文档明确要求 NameNode 和 NFSGW 两节点上添加代理用户的UID、GID、用户名必须一致
这是因为 NameNode 存储的元数据中,每个文件的所属用户与组是通过字符串形式记录,而非数字 UID/GID;当 NFS Gateway 使用代理用户访问 HDFS 时,NameNode 会检查该代理用户的身份标识,如果代理用户在 NameNode 上的 UID、GID、用户名与 NFS Gateway 本地的不一致,可能导致权限解析错误或显示异常
NFS网关节点准备工作
新建nfsgw节点,准备环境为新节点配置免密
bash
# nfsgw节点更改ip,并重启网卡
nmcli connection modify ens160 ipv4.method manual ipv4.addresses 192.168.8.25/24 ipv4.gateway 192.168.8.254 autoconnect yes
nmcli connection up ens160
# 在nfsgw节点重新跑一遍环境搭建中的 setup-dev-env.sh 脚本
bash setup-dev-env.sh
# nfsgw节点配置免密
sshpass -p "123456" ssh-copy-id -o StrictHostKeyChecking=no root@192.168.8.25
# 卸载nfs-utils,NFS网关是hadoop的nfs,两者之间端口冲突
dnf -y remove nfs-utils更新inventory配置文件、j2模板、playbook剧本,将nfsgw节点添加进ansible管理
bash
# 更新playbook剧本,在vars下新增:
nfsgw: hadoop-nfsgw
# 更新hosts解析的j2模板
echo "192.168.8.25 hadoop-nfsgw nfsgw" >> /ansible/template/hosts.j2
# 更新inventory配置文件
cat >> inventory << 'EOF'
[master]
master ansible_host=192.168.8.20
[slave]
node1 ansible_host=192.168.8.21
node2 ansible_host=192.168.8.22
node3 ansible_host=192.168.8.23
node4 ansible_host=192.168.8.24
[nfsgw]
nfsgw ansible_host=192.168.8.25
[cluster:children]
master
slave
nfsgw
EOF
# 以上内容更新后运行剧本,验证结果
ansible-playbook init_hosts.yml
# 更改后验证结果
ansible cluster -m shell -a "cat /etc/hosts"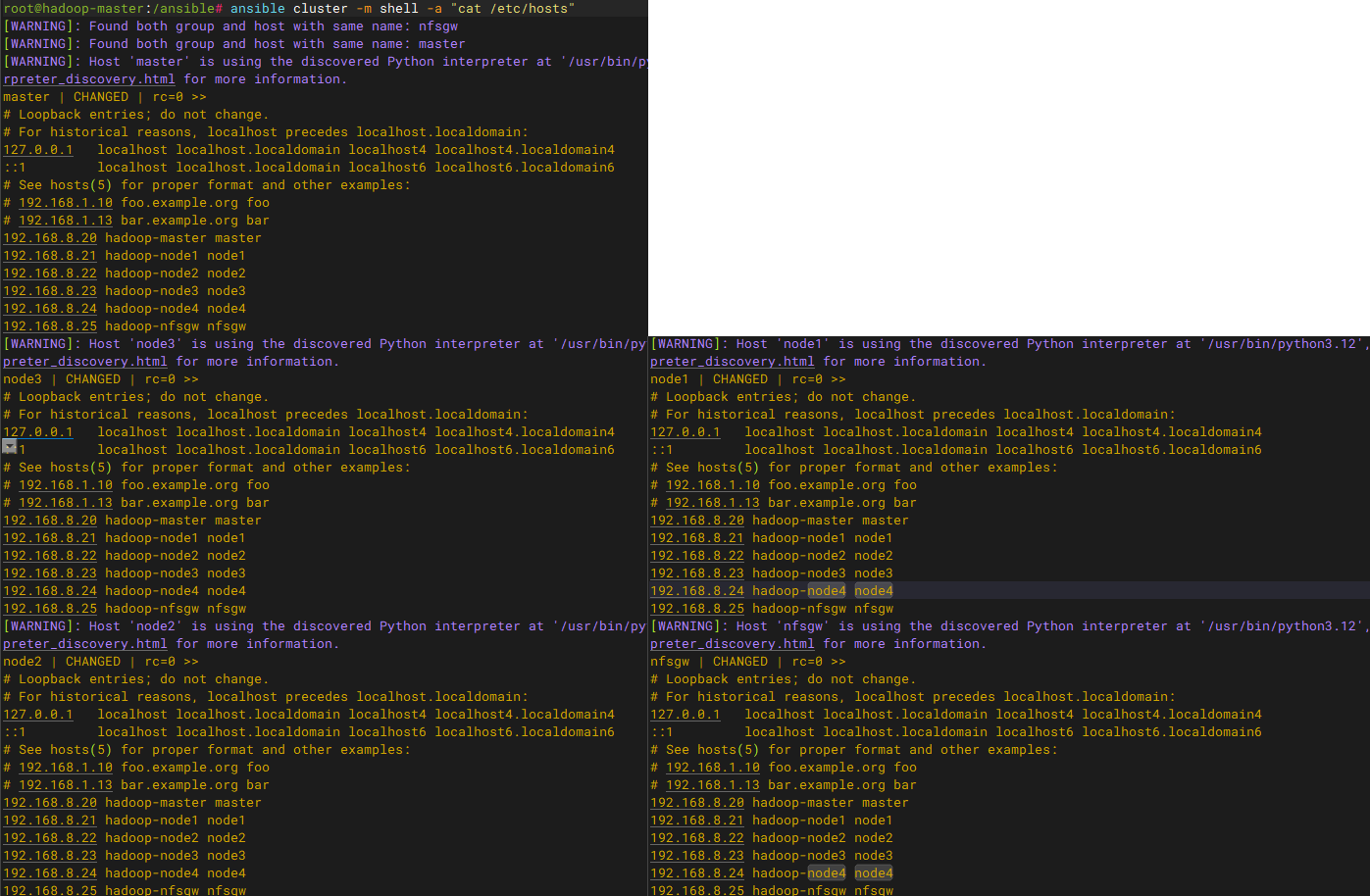
配置代理用户
在 NameNode 节点添加代理用户并授权
bash
# 配置NFS网关的代理用户
ansible 'master:nfsgw' -m shell -a "groupadd -g 800 nfsgwtest"
ansible 'master:nfsgw' -m shell -a "useradd -u 800 -g 800 -r -d /var/hadoop nfsgwtest"
ansible 'master:nfsgw' -m shell -a "cat /etc/passwd | grep nfsgwtest & id nfsgwtest"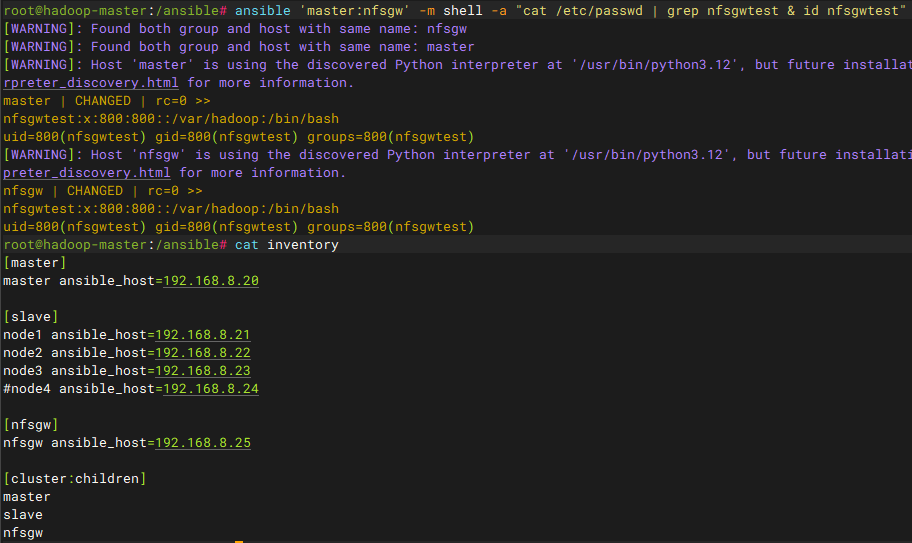
core-site.xml配置
hadoop.proxyuser.nfsgwtest.groups:允许代理用户访问的客户端用户组,多个用户组用逗号分隔,案例权限宽泛直接赋权"*"
hadoop.proxyuser.nfsgwtest.hosts:允许代理用户访问的客户端主机名,多个主机名用逗号分隔,案例权限宽泛直接赋权"*"
bash
# 修改配置文件后与slave节点同步配置文件
ansible cluster -m copy -a "src=/usr/local/hadoop/etc/hadoop/core-site.xml dest=/usr/local/hadoop/etc/hadoop/core-site.xml mode=644"重启Hadoop服务
bash
# 停止服务
/usr/local/hadoop/sbin/stop-all.sh
# 先启动hdfs,在启动yarn
/usr/local/hadoop/sbin/start-dfs.sh
/usr/local/hadoop/sbin/start-yarn.sh
# 验证服务状态
ansible cluster -m shell -a "jps"
/usr/local/hadoop/bin/hdfs dfsadmin -report
/usr/local/hadoop/bin/yarn node -list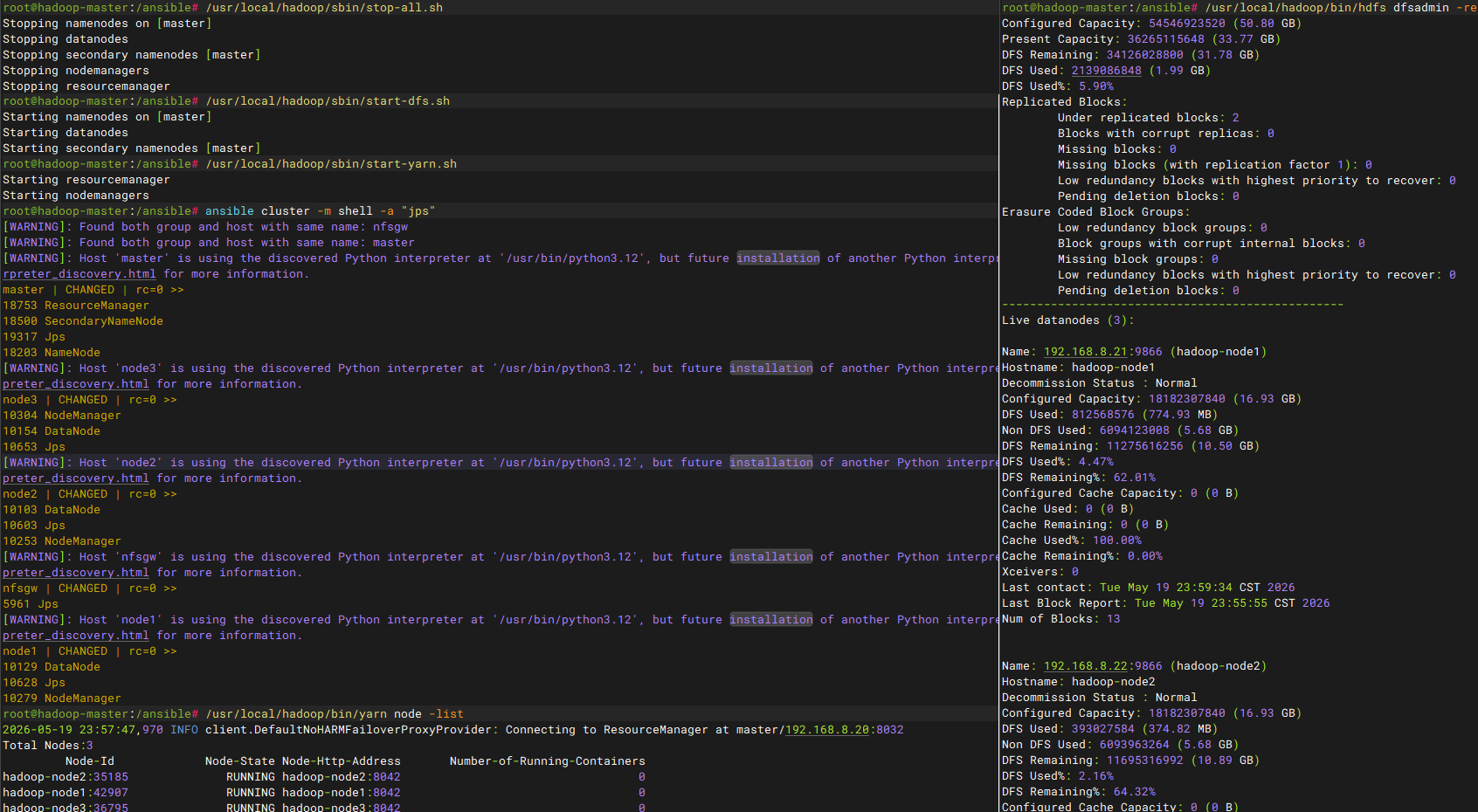
NFS网关节点同步文件
bash
# 将namenode节点的hadoop目录同步给nfsgw节点
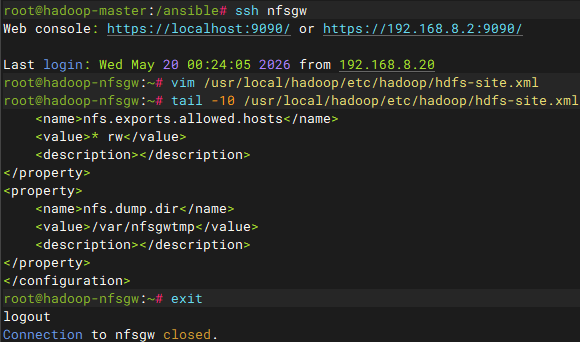
rsync -axSH --delete /usr/local/hadoop nfsgw:/usr/local/同步后的nfsgw节点需要修改配置
hdfs-site.xml配置
nfs.exports.allowed.hosts:访问权限及读写策略,设置为"* rw",其中*代表所有ip,多个ip地址用逗号分隔
nfs.dump.dir:NFS网关的转储目录,用于缓存从集群读取的文件,设置路径为"/var/nfsgwtmp"
启动NFS网关服务
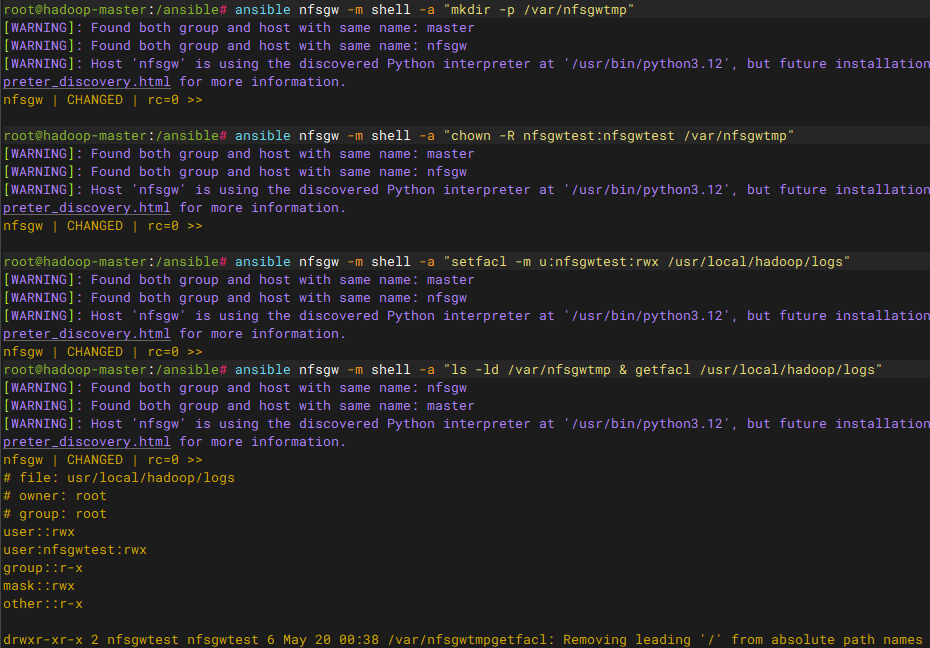
在nfsgw节点中创建转储目录并赋权
bash
# ssh到nfsgw节点操作
mkdir -p /var/nfsgwtmp
chown -R nfsgwtest:nfsgwtest /var/nfsgwtmp
# 添加acl权限
setfacl -m u:nfsgwtest:rwx /var/
setfacl -m u:nfsgwtest:rwx /usr/local/hadoop/logs
# 验证结果
ls -ld /var/nfsgwtmp & getfacl /usr/local/hadoop/logs注意:集群的logs目录日志是自动创建所属为root:root,nfsgwtest用户无权限读取,必须添加acl权限;而var作为转储目录父目录也需要有权限
启动rpcbind映射代理服务
NFS网关工作流程说明:NFS客户端挂载时,先联系 NFS Gateway 节点获取 portmap/rpcbind 记录的 NFS 服务端口,由于 NFS Gateway 内部的 nfsd 和 mountd 已经向 portmap/rpcbind 注册过服务端口,所以portmap/rpcbind 会向客户端返回正确的端口信息,客户端随后建立连接并进行文件操作。若portmap/rpcbind 未运行,客户端将无法获得 NFS 服务的端口信息,挂载操作会失败并报错RPC无法通讯
官方文档中明确指出rpcbind (or portmap), mountd and nfsd三个守护进程共同构成完整的NFS服务能力;NFS网关本身包含了mountd和nfsd两个组件但无法独立工作,而且nfs客户端链接nfs服务中间需要一个中介提供RPC程序号与端口映射关系表,这必须依赖 portmap/rpcbind 来处理客户端的服务发现请求
在红帽6以下 portmap 是默认安装的,而红帽6及以上 portmap 已经被 rpcbind 替代;启动顺序是首先启动 portmap/rpcbind,等待其完全就绪;然后启动 Hadoop 的 nfs3 服务。如果顺序颠倒或 portmap/rpcbind 未运行,NFS Gateway 进程可能会报错或无法正常处理客户端请求
bash
# 在nfsgw节点安装 rpcbind 服务,在启动后验证结果
dnf install -y rpcbind && systemctl enable rpcbind --now
ss -tulpn | grep 111
rpcinfo -p localhost
systemctl status rpcbind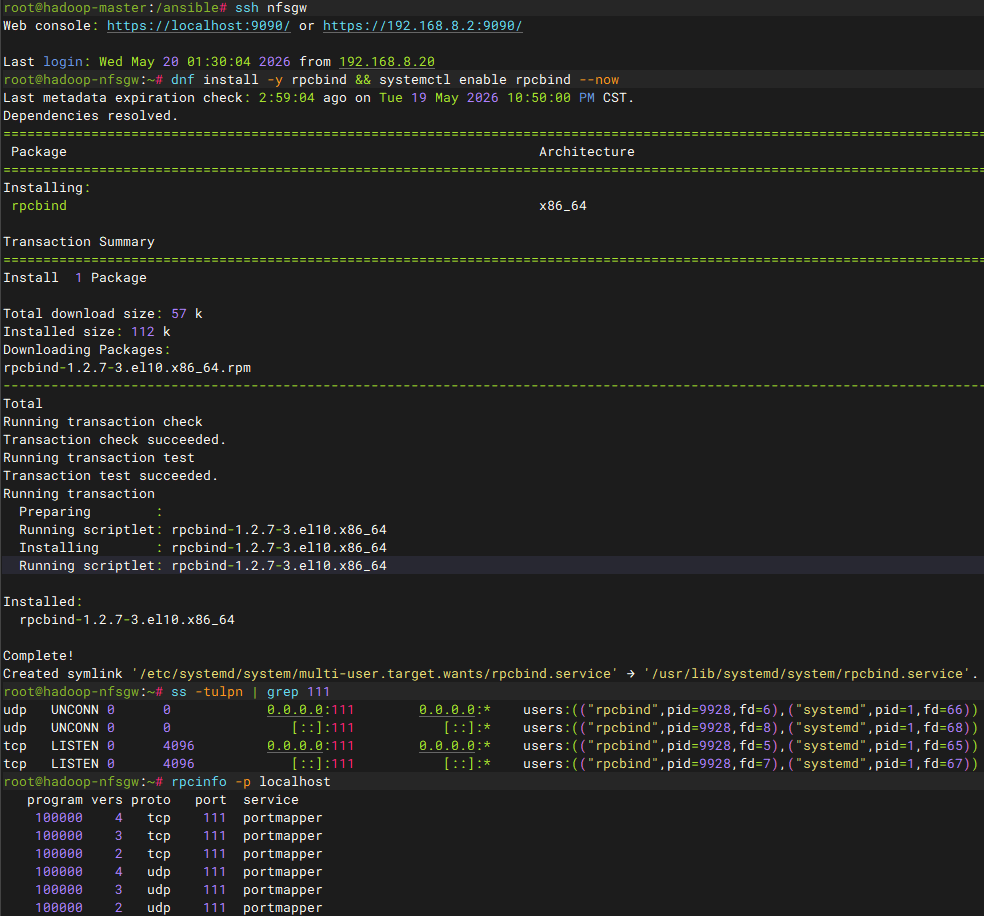
启动nfs3服务
bash
# 在nfsgw节点使用代理用户启动nfs3服务,并验证结果
sudo -u nfsgwtest /usr/local/hadoop/bin/hdfs --daemon start nfs3
jps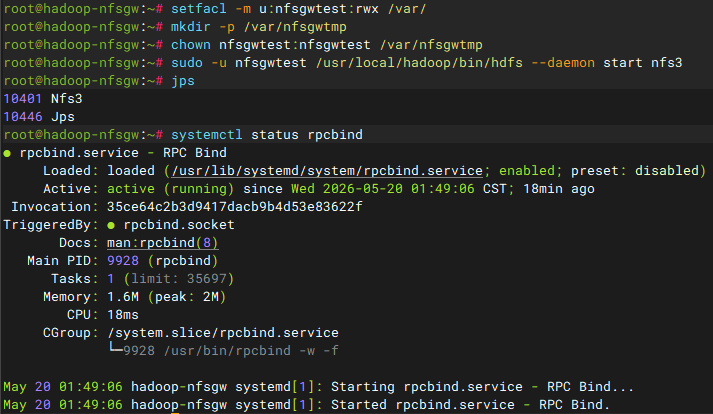
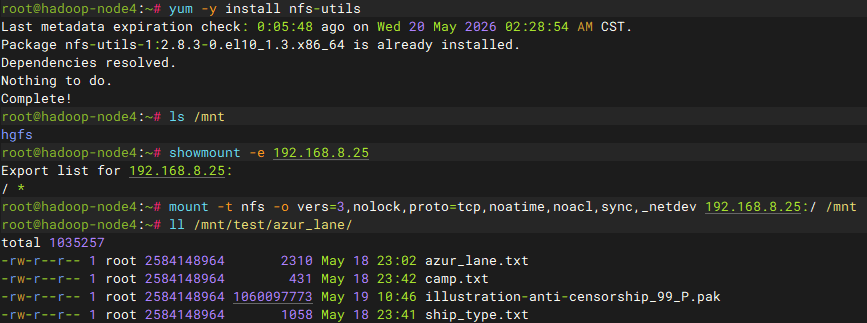
验证客户端挂载
使用现成的node4节点作为nfs客户端挂载HDFS数据,由于之前测试下线节点已经变成裸机不需要其他操作
bash
# 在node4节点安装nfs客户端
dnf install -y nfs-utils
# 挂载nfs
mount -t nfs -o vers=3,nolock,proto=tcp,noatime,noacl,sync,_netdev 192.168.8.25:/ /mnt
## 挂载参数描述:指定 NFSv3 协议,文件使用tcp协议传输,不支持随机写,禁用access time时间更新,禁用acl扩展权限,设置同步写入,等待网络就绪后再挂载,避免开机时网络未启动导致挂载失败注意:虽然红帽6以下使用nfs3版本,红帽6及以上支持nfs4版本,但Hadoop NFS Gateway 只支持 NFSv3 协议不支持 NFSv4