
作者主页: 作者主页
本篇博客专栏:Linux
创作时间 :2025年5月11日

1. HTTP 协议介绍
基本介绍:
- http协议全称:超文本传输协议,适用于从万维网服务器传输超文本到本地的传送协议。
- HTTP是一种应用层协议,是基于TCP/IP通信协议进行传输的,其中 HTTP1.0、HTTP1.1、HTTP2.0 均为 TCP 实现,HTTP3.0 基于 UDP 实现。现主流使用 HTTP1.0 和 HTTP3.0
- 协议:为了使数据从发送端传输到接收端,我们必须规定出一套协议,网络通信的双方必须遵守这套协议才可以进行传输,他最终体现为在网络上传输的数据包的形式。
通俗点讲,协议就是要保证网络通信的双方,能够互相对接上号。
注意: 当我们访问一些网页时,是显示通过 HTTPS 来进行通信的,并且当下大多数的网页都是通过 HTTPS 来进行通信的,因为 HTTPS 在 HTTP 的基础上做了一个加密的工作。HTTPS 将在本文末尾具体介绍
2. HTTP 协议的工作过程
当我们在浏览器上输入一个网址的时候,此时浏览器就会给对应的服务器发送一个HTTP请求,对应的服务器收到这个请求之后,经过计算处理,就会返回一个HTTP响应,并且当我们访问一个网站的时候,有可能不止一次的HTTP请求和响应的交互过程。
基础术语:
- 客户端: 主动发起网络请求的一端
- 服务器: 被动接收网络请求的一端
- 请求: 客户端给服务器发送的数据
- 响应: 服务器给客户端返回的数据
HTTP 协议的重要特点: 一发一收,一问一答
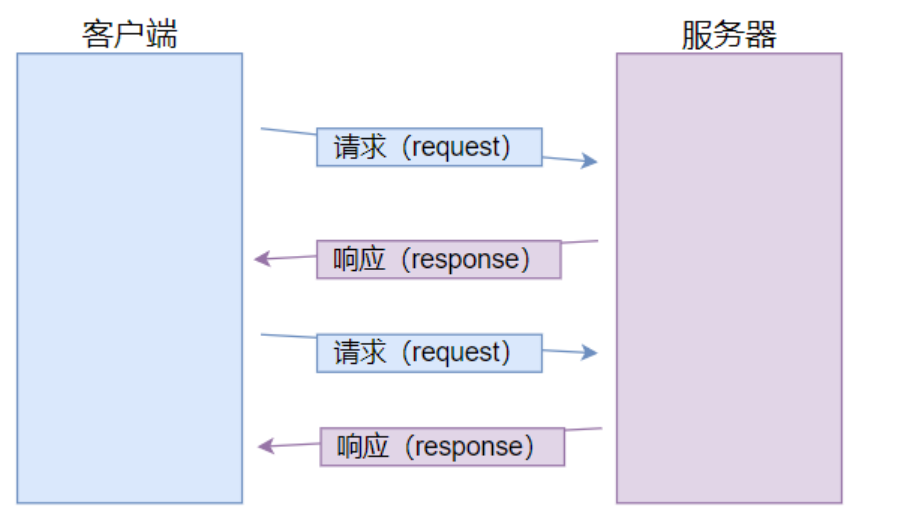
注意: 网络编程中,除了一发一收之外,还有其它的模式
- 多发一收:例如上传大文件
- 一发多收:例如看直播时,搜索一个词条可以得到多个视频源
- 多发多收:例如串流(steam link、moonlight 等等)
3. Fiddler 抓包工具介绍
3.1 抓包工具的使用
当我们访问一个网站时,可能涉及不止一次的 HTTP 请求和响应的交互,为此为了更加清楚的了解我们访问一个网站时 HTTP 请求/协议是怎么交互的,由于 HTTP 是一个文本格式的协议,就可以通过以下两种方式:
- 方式一: 通过 F12 打开浏览器的开发者工具,点击 Network 标签页,然后刷新页面就行。显示的每一条记录都是一次 HTTP 请求/响应
- 方式二(推荐): 抓包工具,这里以 Fiddler 为例,它能够直接读取你电脑上网卡的信息,网卡上有什么数据流动,它都能感知到并且显示出来
当我们选择好我们具体要查看的 HTTP/HTTPS 请求和响应时,右上栏就会显示具体的请求报文内容,右下角就会显示具体的响应报文内容(需要点击 Raw 标签来查看详细的数据格式)
请求和响应的详细数据,可以通过右下角的 view in Notepad 键通过记事本打开
为了方便我们抓取我们自己想查看的抓包结果,可以通过 ctrl + a 全选左侧的抓包结果,ctrl + x 删除选中的所有抓包结果,再进行网页的刷新就行
响应的正文往往是被显示在浏览器上,最常见的响应格式就是 html,很多网站返回的 html 是压缩过的(因为压缩之后,网络传输的数据量就变少了,即节省了网络带宽),所以需要进行解压缩 decode
4. HTTP 协议格式总览
到这里,我们学习 HTTP 协议的方法已经学会了,那就是使用抓包工具来抓取我们想要的 HTTP 请求。接下来我们将介绍 HTTP 协议的格式,它是学习 HTTP 协议的重头戏!
我们将上述得到的搜狗页面的请求为例,整体介绍下 HTTP 协议格式
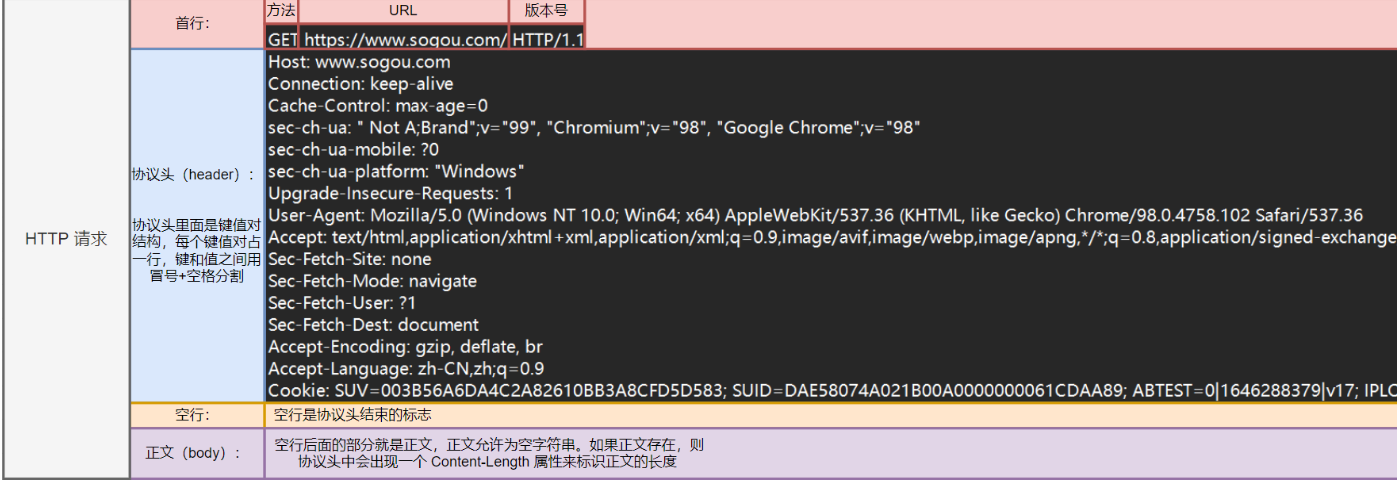
HTTP 请求格式:
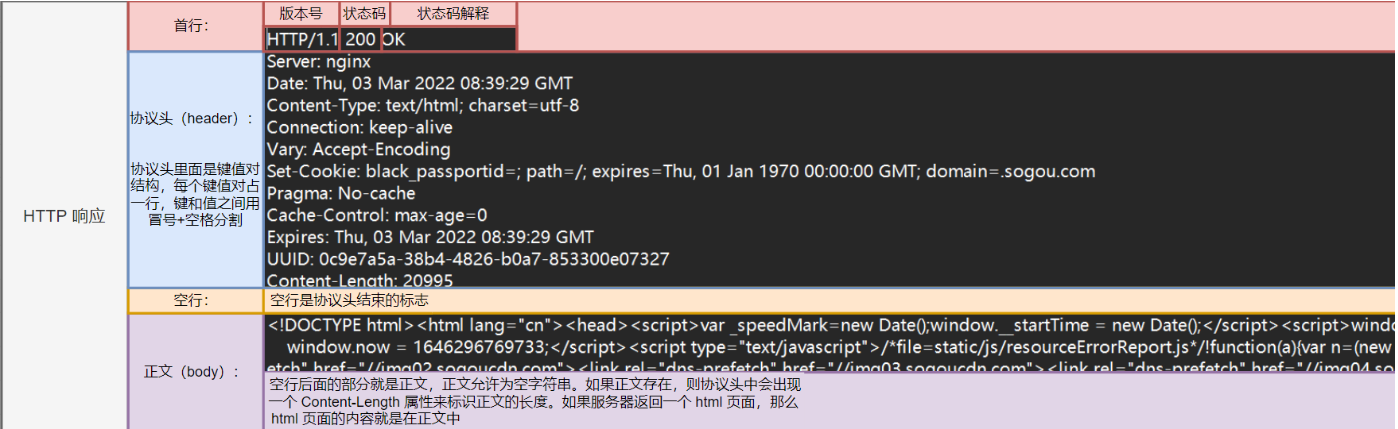
HTTP 响应格式:
注意: 为什么 HTTP 报文中要存在空行呢?
因为HTTP并没有规定报头部分的键值对有多少个,所以使用空格来当作报文的结束标记或者报文和正文之间的分隔符
HTTP在传输层依赖TCP协议,TCP是面向字节流的。如果没有这个空行,机会出现粘包问题
5. HTTP 请求(Request)
5.1 认识 URL
URL基本介绍:
- 平常我们所说的网址,其实就是URL,翻译为:统一资源定位符
- 互联网上的每个文件都有唯一的URL,它包含的信息指出文件的位置,以及浏览器应该怎么处理它
URL基本格式:
URL 的标准格式如下:
协议类型://服务器地址\[:端口号]/资源层级 UNIX 文件路径文件名?查询字符串#片段标识符
URL 的完整格式如下:
协议类型://\[访问资源需要的凭证信息@服务器地址:端口号]/资源层级 UNIX 文件路径文件名?查询字符串#片段标识符
URL 参数介绍

URLencode 介绍
当我们用搜狗搜索蛋糕时,通过抓包,我们会得到下面这个 URL
我们会发现 query string 的有些值是 %E8%9B%8B%E7%B3%95、0%2C0%2C0,通过 urldecode,知道 %E8%9B%8B%E7%B3%95 就是表示蛋糕
需要 urlencode 的原因:
这是因为像 /、?、: 等这样的字符,已经被 url 当做特殊意义理解了,因此这些字符不能随意出现。如果某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义,即 urlencode
一个中文字符由 UTF-8 或者 GBK 这样的编码方式构成,虽然在 URL 中没有特殊含义,但是仍然需要进行转义,否则浏览器可能把 UTF-8/GBK 编码中的某个字节当做 URL 中的特殊符号
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成 %XY 格式。
但是现在网上有很多现成的可以进行转码的工具,因此需要的时候找度娘即可!
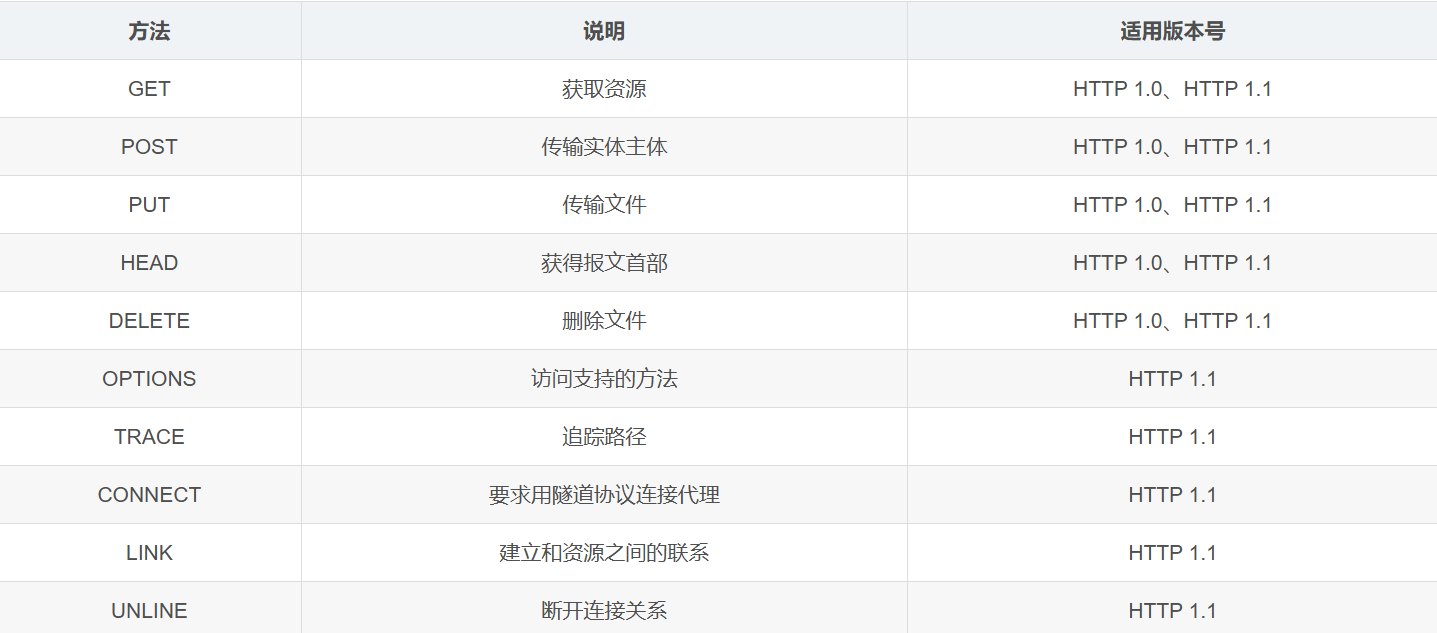
5.2 认识"方法"(method)
HTTP 中的方法,就是 HTTP 请求报文中的首行的第一个部分。
原本 HTTP 的设计者,是希望通过不同的方法,来表达不同的语义。但是至今,其实也没有被实现,以下具体的方法具体起到了什么作用,完全看程序员在代码中是如何实现的。
虽然 HTTP 中的方法很多,但是最常用的就两个 GET 和 POST。以下主要介绍这两个方法
GET方法
基本介绍:
GET是最常用的HTTP方法,作用是用于从服务器上获取某个资源,以下几种方式都会触发GET方法的请求
- 在浏览器中直接输入URL回车或者点击浏览器收藏夹中的链接,此时浏览器就会发送出一个GET请求
- HTML中的img、link、script等标签中的属性中放的URL,浏览器也会构造出HTTP GET请求
- 使用JavaScript中的ajax也可以构造出GET请求
- 各种编程语言只要能够访问网络就可以构造出GET请求
GET 请求的特点:
- 首行里面的第一个部分就是 GET
- URL 里面的 query string 可以为空,也可以不为空
- GET 请求的 header 有若干个键值对结构
- GET 请求的 body 一般是空的
POST 方法
基本介绍:
POST 方法也是一种常见的方法,多用于提交用户输入的数据给服务器(如登录页面)。以下几种方法都会触发 POST 方法的请求
- 通过 HTML 中的 form 标签可以构造 POST 请求
- 使用 JavaScript 的 ajax 可以构造 POST 请求
POST 请求的特点:
- 首行第一个部分就是 POST
- URL 里面的 query string 一般是空的
- POST 请求的 header 里面有若干个键值对
- POST 请求的 body 一般不为空(body 的具体数据格式,由 header 中的 Content-Type 来描述;body 的具体数据长度,由 header 中的 Content-Length 来描述
答题模板:
GET 和 POST 其实没有本质区别,使用 GET 的场景完全可以使用 POST 代替,使用 POST 的场景一样可以使用 GET 代替。但是在具体的使用上,还是存在一些细节的区别
- GET 习惯上会把客户端的数据通过 query string 来传输(body 部分是空的);POST 习惯上会把客户端的数据通过 body 来传输(query string 部分是空的)
- GET 习惯上用于从服务器获取数据;POST 习惯上是客户端给服务器提交数据
- 一般情况,程序员会把 GET 请求的处理,实现成"幂等"的;对于 POST 请求的处理,不要求实现成"幂等"
- GET 请求可以被缓存,可以被浏览器保存到收藏夹中;POST 请求不能被缓存
补充: 幂等是什么?
- 一个 HTTP 方法是幂等的,指的是同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的。换句话说,幂等的方法不应该具有副作用。
比如我们去抢购一件物品,如果我们已经抢到了要进行下单,由于很多人都在抢购,所以下单后,我们发现好像没有什么反应,因此我们又不断的点机下单。如果最终我们只需要付一件产品的钱,就是幂等的,如果要支付N件产品的钱,就不是幂等的
-
在正确的条件下,GET、HEAD、PUT 和 DELETE 等方法是幂等的;POST 方法不是幂等的
-
幂等性只与后端服务器的实际状态有关,而每一次请求接收到的状态码不一定相同
关于 GET 请求的 URL 长度问题的误解
- **网上有一种错误的解释:**GET 请求的长度是存在上限的,这个上限有被说成 1024kb、2048kb 等等,并且 GET 请求存在上限的原因是 URL 的长度存在上限
- RFC 2616 标准正确的解释: HTTP 协议由 RFC 2616 标准定义,该标准中明确说明 "Hypertext Transfer Protocol -- HTTP/1.1," does not specify any requirement for URL length,即没有对 URL 的长度有任何限制
- URL 的长度取决因素: 实际上 URL 的长度取决于浏览器的实现和 HTTP 服务器端的实现。在浏览器端,不同的浏览器最大的长度是不同的,但是现在浏览器支持的长度一般都很长;在服务器端,一般这个长度是可以配置的
关于 POST 比 GET 更安全的误解
- 网上有一种错误的解释: 如果实现登录页面,如果使用 GET 实现登录,GET 习惯上把数据放到 query string 中,此时就能看到浏览器的 URL 中显示当前的用户名和密码了,所以就并不安全;而 POST 习惯上会把数据放到 body 中,因此登录时就不能直接看到用户名和密码,就安全
- 正确的理解: 安全问题取决于是否加密以及加密算法的强度。这和将数据信息放到 query string 或 body 中无关,因为通过抓包,我们就可以得到这两部分的数据
关于 GET 只能传输文本数据的误解
- 网上有一种错误的解释: GET 只能传输文本数据;POST 可以传输文本数据,也可以传输二进制数据
- 正确的理解: GET 也可以传输二进制数据,虽然不能直接在 query string 中传输二进制数据,但是可以针对二进制数据进行 urlencode,转码后就可以放到 url 中;GET 还可以直接将二进制数据放到 body 中
其它方法
- PUT: 与 POST 相似,但是具有幂等特性,一般用于更新
- DELETE: 删除服务器指定资源
- OPTIONS: 返回服务器所支持的请求方法
- HEAD: 与 GET 类似,只不过响应体不返回,只返回响应头
- TRACE: 能显示服务器端收到的请求,测试的时候会用到
- CONNECT: 预留,暂无使用
上述方法的 HTTP 请求可以使用 ajax 或第三方工具来构造,也能使用可以网络编程的语言来构造
5.3 认识请求"报头"(header)
header 的整体格式是键值对结构,每个键值对占一行,键和值之间使用 冒号+空格 进行分割
以下介绍几个常见的报头
HOST:
HOST的值表示服务器主机的地址或者端口号(地址可以是域名,也可以是IP,端口号可以省略或者手动设定)
Content-Length:
Content-Length表示body的长度,长度单位是字节
Content-Type:
Content-Type表示的是body的数据格式,以下介绍三种格式
- application/x-www-form-urlencoded
这是 form 表单提交的数据格式,此时 body 的格式就类似于 query string(是键值对的结构,键值对之间使用
&分割,键与值之间使用=分割
- multipart/form-data
这是 form 表单提交的数据格式(需要在 from 标签上加上
enctyped="multipart/form-data"),通常用于 HTML 提交图片或者文件
- application/json
此时 body 数据为 json 格式,json 格式就是源自 js 的对象的格式。用一个 { } 括住,里面有多个键值对,键值对之间使用逗号分割,键和值之间使用冒号分割
User-Agent(简称 UA)
User-Agent 表示浏览器或者操作系统的属性,形如
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/91.0.4472.77 Safari/537.36
Windows NT 10.0; Win64; x64表示操作系统信息AppleWebKit/537.36 (KHTML, like Gecko)Chrome/91.0.4472.77 Safari/537.36表示浏览器信息
UA 在早年是一个非常有用的字段,网站的开发者可以根据它来检测页面的"兼容性"
Referer
Referer 表示这个页面是从哪个页面跳转过来的,这是一个很有用的字段
假设我用 bing 浏览器搜索蛋糕,会发现有的搜索结果带有广告字眼,这就相当于广告主在 bing 浏览器用来引流的,当该网站的点击次数越多,用户的成交量也就会上升,金主给浏览器的广告费也就增多。为了统计该广告在某一浏览器的点击次数,就可以通过 Referer 字段来查看。
我们可以对该 HTTP 请求进行抓包,其中 Referer 字段的值就是 bing 浏览器,即表面该网页是从 bing 浏览器跳转过来的
注意: 如果直接在浏览器中输入 URL 或直接通过收藏夹访问页面时,是没有 Referer 的
Cookie
什么是cookie?
Cookie是一种为程序员提供在本地具有存储能力的技术
为什么现需要Cookie
如果没有 Cookie,直接将要存储的数据保存在客户端浏览器所在的主机的硬盘上,那么就会出现很大的安全风险,比如当你不小心打开某个不安全的网站,该网站就可以在你的硬盘上写一个病毒程序,那么你的电脑就挂了!因此浏览器为了保证安全性,就禁止网页中的代码访问主机的硬盘(无法在 JS 中读写文件),因此也就失去了持久化存储的能力,故 Cookie 就很重要!
Cookie 里面存的是什么?
Cookie 中存储了一个字符串,是键值对结构的,键值对之间使用 ;分割,键和值之间使用 = 分割
Cookie 来自哪里,如何往 Cookie 中存储数据?
Cookie 这个数据可能是客户端(网页)自行通过 JS 写入的,也可能来自于服务器在 HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据。
6. HTTP 响应(Response)
6.1 认识"状态码"(status code)
状态码表示访问一个页面的结果(如访问成功、失败,还是其它一些情况等等),它是一个3位的整数,从 1xx、2xx、3xx、4xx、5xx,分为五个大类,每个大类的含义都不同。以下介绍一些常见的状态码及它的状态码解释
200 OK
表示访问成功
404 Not Found
表示找不到对应的资源
403 Forbidden
表示访问被拒绝
405 Method Not Allowed
表示访问的服务器不能支持请求中的方法或者不能使用该请求中的方法
500 Internal Server Error
表示服务器出现内部错误
504 Gateway Timeout
表示当前服务器负载比较大,服务器处理单条请求的时耗很长,就会出现超时情况
302 Move temporarily
表示临时重定向
重定向相当于手机呼号的呼叫转移功能,如果我们换了一个手机号,就可以去办理该呼叫转移业务,使朋友拨打你的旧号码时,自动跳转到新号码
6.2 认识响应"报头"(header)
响应报头的基本格式和请求报头的格式基本一致,下面介绍下响应报头的 Content-Type 参数
Content-Type
Content-Type 表示 body 的数据格式,以下介绍三种响应中的数据格式
- text/html
表示body数据的形式是html
- text/css
数据是css
- application/javascript
JavaScript
- application/json
json
最后:
十分感谢你可以耐着性子把它读完和我可以坚持写到这里,送几句话,对你,也对我:
1.一个冷知识:
屏蔽力是一个人最顶级的能力,任何消耗你的人和事,多看一眼都是你的不对。
2.你不用变得很外向,内向挺好的,但需要你发言的时候,一定要勇敢。
正所谓:君子可内敛不可懦弱,面不公可起而论之。
3.成年人的世界,只筛选,不教育。
4.自律不是6点起床,7点准时学习,而是不管别人怎么说怎么看,你也会坚持去做,绝不打乱自己的节奏,是一种自我的恒心。
5.你开始炫耀自己,往往都是灾难的开始,就像老子在《道德经》里写到:光而不耀,静水流深。
最后如果觉得我写的还不错,请不要忘记点赞✌,收藏✌,加关注✌哦(。・ω・。)
愿我们一起加油,奔向更美好的未来,愿我们从懵懵懂懂的一枚菜鸟逐渐成为大佬。加油,为自己点赞!