引言:多智能体强化学习(MARL)
多智能体强化学习(MARL)将强化学习拓展到多个智能体在共享环境中相互交互的场景。这些智能体可能相互合作、竞争,或者目标混杂。MARL 引入了单智能体设置中不存在的独特挑战。
MARL 中的非平稳性挑战
当多个智能体同时学习时,会出现一个主要的难题。从任何一个单一智能体的视角来看,环境显得非平稳,因为其他智能体的策略在学习过程中不断变化。当其他智能体的行为方式改变时,原本在它们先前行为下表现良好的动作,可能会变得糟糕。这违反了单智能体强化学习算法(如标准的 Q 学习或 DDPG)所依赖的平稳性假设,导致学习过程不稳定。
什么是 MADDPG?
多智能体深度确定性策略梯度(MADDPG)是 DDPG 算法的扩展,旨在解决多智能体场景中的非平稳性问题。它采用了集中式训练与分散式执行的范式。
核心思想:集中式训练,分散式执行
- 分散式执行 :在执行阶段(在环境中行动时),每个智能体 i i i 根据自己的局部 观察 o i o_i oi 使用自己的演员网络 μ i ( o i ; θ i ) \mu_i(o_i; \theta_i) μi(oi;θi) 来选择其动作 a i a_i ai。这一点对于实际部署至关重要,因为在实际中智能体可能无法获取全局信息。
- 集中式训练 :在训练阶段(更新网络时),MADDPG 为每个智能体 i i i 使用一个集中式评论家 Q i Q_i Qi。这个评论家以所有 智能体的联合 观察(或状态) ( x = ( o 1 , . . . , o N ) x = (o_1, ..., o_N) x=(o1,...,oN)) 和联合 动作 ( a = ( a 1 , . . . , a N ) a = (a_1, ..., a_N) a=(a1,...,aN)) 作为输入,来估计动作价值 Q i ( x , a 1 , . . . , a N ; ϕ i ) Q_i(x, a_1, ..., a_N; \phi_i) Qi(x,a1,...,aN;ϕi)。
通过将评论家的条件设定为联合状态和动作,即使其他智能体的策略发生变化,每个智能体的学习目标也变得平稳,因为评论家知道其他智能体在训练过程中实际采取的动作。这使得学习过程得以稳定。
为什么选择 MADDPG?优势所在
- 应对非平稳性:集中式评论家缓解了多智能体学习中的主要挑战。
- 仅使用局部信息进行执行:策略可以在智能体仅具有部分可观察性的场景中部署。
- 对环境结构无假设:与某些 MARL 方法不同,它不需要特定的通信协议或对奖励结构的了解(例如,差异奖励)。
- 适用于合作、竞争或混合设置:该框架是通用的。
MADDPG 的应用领域和方式
MADDPG 已被应用于各种多智能体领域:
- 合作导航:多个智能体协调到达目标位置,同时避免碰撞。
- 捕食者-猎物场景:智能体学习追逐或躲避其他智能体。
- 交通信号控制:协调交通信号灯。
- 多机器人协调:任务分配和路径规划。
当满足以下条件时,它特别适用:
- 智能体具有连续或离散的动作空间(尽管最初是为连续动作空间提出的)。
- 可以进行集中式训练(在学习阶段可以访问联合信息)。
- 需要分散式执行。
- 环境动态复杂,从单个智能体的视角来看可能是非平稳的。
MADDPG 的数学基础
MADDPG 将 DDPG 框架扩展到 N N N 个智能体。设策略为 μ = { μ 1 , . . . , μ N } \boldsymbol{\mu} = \{\mu_1, ..., \mu_N\} μ={μ1,...,μN},参数为 θ = { θ 1 , . . . , θ N } \boldsymbol{\theta} = \{\theta_1, ..., \theta_N\} θ={θ1,...,θN},集中式动作价值函数为 Q i ( x , a 1 , . . . , a N ; ϕ i ) Q_i(x, a_1, ..., a_N; \phi_i) Qi(x,a1,...,aN;ϕi),每个智能体 i i i 的参数为 ϕ i \phi_i ϕi。
集中式动作价值函数(评论家)
每个智能体 i i i 学习自己的评论家 Q i ( x , a 1 , . . . , a N ) Q_i(x, a_1, ..., a_N) Qi(x,a1,...,aN),其中 x = ( o 1 , . . . , o N ) x=(o_1, ..., o_N) x=(o1,...,oN) 表示联合观察(或完整状态,如果可用)。这个函数估计在给定联合上下文和动作的情况下智能体 i的预期回报。
评论家更新
每个智能体 i i i 的评论家 Q i ( x , a 1 , . . . , a N ; ϕ i ) Q_i(x, a_1, ..., a_N; \phi_i) Qi(x,a1,...,aN;ϕi) 通过最小化使用共享回放缓冲区 D \mathcal{D} D 中的样本计算的损失来进行更新。损失通常是均方误差(MSE):
L ( ϕ i ) = E ( x , a , r , x ′ ) ∼ D ( y i − Q i ( x , a 1 , . . . , a N ; ϕ i ) ) 2 L(\phi_i) = \mathbb{E}_{(x, a, r, x') \sim \mathcal{D}} (y_i - Q_i(x, a_1, ..., a_N; \\phi_i))\^2 L(ϕi)=E(x,a,r,x′)∼D(yi−Qi(x,a1,...,aN;ϕi))2
目标值 y i y_i yi 使用目标 网络(用撇号表示)计算:
y i = r i + γ Q i ′ ( x ′ , a 1 ′ , . . . , a N ′ ; ϕ i ′ ) ∣ a j ′ = μ j ′ ( o j ′ ) y_i = r_i + \gamma Q'_i(x', a'_1, ..., a'_N; \phi'i)|{a'_j = \mu'_j(o'_j)} yi=ri+γQi′(x′,a1′,...,aN′;ϕi′)∣aj′=μj′(oj′)
其中 a j ′ = μ j ′ ( o j ′ ; θ j ′ ) a'_j = \mu'_j(o'_j; \theta'_j) aj′=μj′(oj′;θj′) 是每个智能体的目标演员网络根据它们的下一个 局部观察 o j ′ o'_j oj′ 从 x ′ x' x′ 中预测的下一个动作。
演员更新(策略梯度)
每个智能体 i i i 的演员 μ i ( o i ; θ i ) \mu_i(o_i; \theta_i) μi(oi;θi) 使用确定性策略梯度定理进行更新,该定理已适应集中式评论家。演员 i i i 的梯度上升方向为:
∇ θ i J ( θ i ) ≈ E x , a ∼ D ∇ θ i μ i ( o i ; θ i ) ∇ a i Q i ( x , a 1 , . . . , a N ; ϕ i ) ∣ a i = μ i ( o i ) \nabla_{\theta_i} J(\theta_i) \approx \mathbb{E}_{x, a \sim \mathcal{D}} \\nabla_{\\theta_i} \\mu_i(o_i; \\theta_i) \\nabla_{a_i} Q_i(x, a_1, ..., a_N; \\phi_i)\|_{a_i=\\mu_i(o_i)} ∇θiJ(θi)≈Ex,a∼D∇θiμi(oi;θi)∇aiQi(x,a1,...,aN;ϕi)∣ai=μi(oi)
在实际操作中,使用 PyTorch autograd,这通常是通过最小化损失来实现的:
L ( θ i ) = − E o i ∼ D Q i ( x , μ 1 ( o 1 ) , . . . , μ N ( o N ) ; ϕ i ) L(\theta_i) = - \mathbb{E}_{o_i \sim \mathcal{D}} Q_i(x, \\mu_1(o_1), ..., \\mu_N(o_N); \\phi_i) L(θi)=−Eoi∼DQi(x,μ1(o1),...,μN(oN);ϕi)
在为演员 i i i 计算这个损失及其梯度时,将 j ≠ i j \neq i j=i 的 o j o_j oj 和 a j = μ j ( o j ) a_j = \mu_j(o_j) aj=μj(oj) 视为从缓冲区或当前策略中获得的固定输入。
离散动作的适应 :如果使用离散动作,演员通常输出一个概率分布的 logits(例如,Categorical 或 Gumbel-Softmax)。然后可以使用策略梯度方法进行更新,其中优势是从集中式评论家 Q i Q_i Qi 中得出的。为了简化,可以直接使用 Q i ( x , a 1 , . . . , a N ) Q_i(x, a_1, ..., a_N) Qi(x,a1,...,aN) 作为信号(类似于 DDPG 使用 Q 的方式),如果 Q 值较高,则增加采取该动作的概率,尽管也可以使用涉及基线的更复杂的策略梯度估计。
目标网络和软更新
与 DDPG 类似,MADDPG 为所有演员( μ i ′ \mu'_i μi′)和评论家( Q i ′ Q'_i Qi′)使用目标网络,通过软更新进行更新:
θ i ′ ← τ θ i + ( 1 − τ ) θ i ′ \theta'_i \leftarrow \tau \theta_i + (1 - \tau) \theta'_i θi′←τθi+(1−τ)θi′
ϕ i ′ ← τ ϕ i + ( 1 − τ ) ϕ i ′ \phi'_i \leftarrow \tau \phi_i + (1 - \tau) \phi'_i ϕi′←τϕi+(1−τ)ϕi′
探索
探索通常通过在训练过程中为确定性演员输出的动作添加噪声来处理。这通常是为每个智能体独立完成的(例如,独立的 Ornstein-Uhlenbeck 或高斯噪声过程)。
对于我们的离散动作适应,探索可以通过从演员的输出分布中采样或基于演员的首选动作使用 ϵ \epsilon ϵ-贪婪策略来实现。
MADDPG 的逐步解释
- 初始化 :对于每个智能体 i = 1... N i=1...N i=1...N:
- 演员网络 μ i ( θ i ) \mu_i(\theta_i) μi(θi),评论家网络 Q i ( ϕ i ) Q_i(\phi_i) Qi(ϕi)。
- 目标网络 μ i ′ ( θ i ′ ) \mu'_i(\theta'_i) μi′(θi′), Q i ′ ( ϕ i ′ ) Q'_i(\phi'_i) Qi′(ϕi′),并设置 θ i ′ ← θ i , ϕ i ′ ← ϕ i \theta'_i \leftarrow \theta_i, \phi'_i \leftarrow \phi_i θi′←θi,ϕi′←ϕi。
- 探索噪声过程 N i \mathcal{N}_i Ni。
- 初始化 :共享回放缓冲区 D \mathcal{D} D。
- 对于每个训练剧集 :
a. 获取初始联合状态/观察 x = ( o 1 , . . . , o N ) x = (o_1, ..., o_N) x=(o1,...,oN)。重置噪声过程。
b. 对于每个步骤 t t t :
i. 对于每个智能体 i i i,选择动作 a i = μ i ( o i ; θ i ) + N i a_i = \mu_i(o_i; \theta_i) + \mathcal{N}_i ai=μi(oi;θi)+Ni。如有必要,对动作进行裁剪。
ii. 执行联合动作 a = ( a 1 , . . . , a N ) a = (a_1, ..., a_N) a=(a1,...,aN),观察联合奖励 r = ( r 1 , . . . , r N ) r=(r_1, ..., r_N) r=(r1,...,rN) 和下一个联合状态/观察 x ′ = ( o 1 ′ , . . . , o N ′ ) x'=(o'_1, ..., o'_N) x′=(o1′,...,oN′),以及完成标志 d = ( d 1 , . . . , d N ) d=(d_1, ..., d_N) d=(d1,...,dN)。
iii. 将联合 转换 ( x , a , r , x ′ , d ) (x, a, r, x', d) (x,a,r,x′,d) 存储到 D \mathcal{D} D 中。
iv. x ← x ′ x \leftarrow x' x←x′。
v. 更新步骤(如果缓冲区有足够的样本) :- 从 D \mathcal{D} D 中随机抽取一个大小为 B B B 的联合转换迷你批次。
- 对于每个智能体 i = 1... N i=1...N i=1...N:
- 更新评论家 Q i Q_i Qi :使用目标网络 μ j ′ , Q i ′ \mu'_j, Q'_i μj′,Qi′ 计算目标 y i y_i yi。最小化 L ( ϕ i ) L(\phi_i) L(ϕi)。
- 更新演员 μ i \mu_i μi :使用主集中式评论家 Q i Q_i Qi 最小化演员损失 L ( θ i ) L(\theta_i) L(θi)。
- 对于每个智能体 i = 1... N i=1...N i=1...N:
- 更新目标网络 :对 θ i ′ \theta'_i θi′ 和 ϕ i ′ \phi'_i ϕi′ 进行软更新。
vi. 如果任何智能体完成(或全局终止),则退出步骤循环。
- 重复:直到收敛。
MADDPG 的关键组成部分
每个智能体的演员网络
- 每个智能体 i i i 都有一个演员 μ i \mu_i μi,将它的局部观察 o i o_i oi 映射到它的动作 a i a_i ai。
- 使用其关联的集中式评论家的梯度进行训练。
每个智能体的集中式评论家网络
- 每个智能体 i i i 都有一个评论家 Q i Q_i Qi,根据联合 观察和联合 动作 ( x , a 1 , . . . , a N ) (x, a_1, ..., a_N) (x,a1,...,aN) 来估计智能体 i i i 的动作价值。
- 使用目标网络计算的目标值进行训练。
目标网络(演员和评论家)
- 所有演员和评论家网络的慢速更新副本,用于稳定的目標计算。
回放缓冲区(共享)
- 存储联合经验的元组: ( x , a , r , x ′ , d ) (x, a, r, x', d) (x,a,r,x′,d)。
- 启用离线策略学习。
动作选择与探索
- 演员在分散式执行中使用,仅基于局部 o i o_i oi。
- 在训练过程中,为每个智能体独立添加探索噪声(或采样策略)。
集中式训练逻辑
- 更新步骤需要访问所有智能体的网络参数(用于目标和评论家输入)以及共享缓冲区中的数据。
超参数
- 与 DDPG 类似(缓冲区大小、批次大小、学习率、 τ \tau τ、 γ \gamma γ、噪声参数),但可能需要每个智能体单独设置或共享。
实践示例:自定义多智能体网格世界
环境设计理由
我们将创建一个简单的 2 智能体合作导航任务,位于网格上:
- 状态:两个智能体的位置以及它们各自目标的位置。
- 观察(智能体 i i i) :智能体 i i i 的位置,智能体 i i i 的目标位置,其他智能体的位置。
- 动作:每个智能体的离散动作(上、下、左、右)。
- 奖励 :合作型。每步有较小的负奖励。如果两个智能体同时到达它们的目标,则有较大的正奖励。也许可以根据距离减少情况设置一个形状奖励。
- 目标:两个智能体同时到达它们的目标。
这允许我们展示基于联合状态(所有位置)和联合动作的集中式 Q 值估计,而演员则基于局部观察进行操作。我们通过集中式 Q-评论家使用策略梯度来适应 MADDPG,以处理离散动作。
设置环境
导入库。
python
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import random
import math
from collections import namedtuple, deque
from itertools import count
from typing import List, Tuple, Dict, Optional, Callable, Any
import copy
# 导入 PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Categorical # 用于离散演员
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")
# 设置随机种子
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
%matplotlib inline使用设备:cpu创建自定义多智能体环境
一个简单的 2 智能体合作网格导航任务。
python
class MultiAgentGridEnv:
"""
简单的 2 智能体合作网格世界。
智能体必须同时到达各自的目标。
观察包括智能体位置和目标位置。
奖励是共享的。
"""
def __init__(self, size: int = 5, num_agents: int = 2):
self.size: int = size
self.num_agents: int = num_agents
self.action_dim: int = 4 # 上、下、左、右
self.action_map: Dict[int, Tuple[int, int]] = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}
self.actions: List[int] = list(self.action_map.keys())
# 为简单起见,定义固定的起始和目标位置
self.start_positions: List[Tuple[int, int]] = [(0, 0), (size - 1, size - 1)]
self.goal_positions: List[Tuple[int, int]] = [(size - 1, 0), (0, size - 1)]
if num_agents != 2:
raise NotImplementedError("目前仅支持 2 个智能体。")
self.agent_positions: List[Tuple[int, int]] = list(self.start_positions)
# 智能体 i 的观察空间:(self_r, self_c, other_r, other_c, goal_i_r, goal_i_c)
# 在 0 和 1 之间进行归一化
self.observation_dim_per_agent: int = 6
self.max_coord = float(self.size - 1)
def _normalize_pos(self, pos: Tuple[int, int]) -> Tuple[float, float]:
""" 对网格位置进行归一化。 """
r, c = pos
return (r / self.max_coord, c / self.max_coord) if self.max_coord > 0 else (0.0, 0.0)
def _get_observation(self, agent_id: int) -> np.ndarray:
""" 获取特定智能体的归一化局部观察。 """
obs = []
# 自身位置
self_pos_norm = self._normalize_pos(self.agent_positions[agent_id])
obs.extend(self_pos_norm)
# 其他智能体位置
other_id = 1 - agent_id
other_pos_norm = self._normalize_pos(self.agent_positions[other_id])
obs.extend(other_pos_norm)
# 自身目标位置
goal_pos_norm = self._normalize_pos(self.goal_positions[agent_id])
obs.extend(goal_pos_norm)
return np.array(obs, dtype=np.float32)
def get_joint_observation(self) -> List[np.ndarray]:
""" 获取所有智能体的观察列表。 """
return [self._get_observation(i) for i in range(self.num_agents)]
def reset(self) -> List[np.ndarray]:
""" 重置环境,返回初始观察列表。 """
self.agent_positions = list(self.start_positions)
return self.get_joint_observation()
def step(self, actions: List[int]) -> Tuple[List[np.ndarray], List[float], bool]:
"""
执行所有智能体的一步操作。
参数:
- actions (List[int]): 每个智能体的一个动作列表。
返回:
- Tuple[List[np.ndarray], List[float], bool]:
- 每个智能体的下一个观察列表。
- 每个智能体的奖励列表(共享奖励)。
- 全局完成标志。
"""
if len(actions) != self.num_agents:
raise ValueError(f"期望有 {self.num_agents} 个动作,但得到了 {len(actions)} 个")
next_positions: List[Tuple[int, int]] = list(self.agent_positions) # 从当前开始
total_dist_reduction = 0.0
hit_wall_penalty = 0.0
for i in range(self.num_agents):
current_pos = self.agent_positions[i]
if current_pos == self.goal_positions[i]: # 如果智能体已经在目标位置,则不移动
continue
action = actions[i]
dr, dc = self.action_map[action]
next_r, next_c = current_pos[0] + dr, current_pos[1] + dc
# 检查边界并更新位置
if 0 <= next_r < self.size and 0 <= next_c < self.size:
next_positions[i] = (next_r, next_c)
else:
hit_wall_penalty -= 0.5 # 碰到墙壁的惩罚
next_positions[i] = current_pos # 保持原位
# 简单的碰撞处理:如果智能体移动到同一个位置,则反弹
if self.num_agents == 2 and next_positions[0] == next_positions[1]:
next_positions = list(self.agent_positions) # 恢复到先前的位置
hit_wall_penalty -= 0.5 # 视为惩罚(类似于碰到墙壁)
self.agent_positions = next_positions
# 计算奖励和完成标志
done = all(self.agent_positions[i] == self.goal_positions[i] for i in range(self.num_agents))
if done:
reward = 10.0 # 合作成功的大奖励
else:
# 基于距离的奖励(负的到目标的距离总和)
dist_reward = 0.0
for i in range(self.num_agents):
dist = abs(self.agent_positions[i][0] - self.goal_positions[i][0]) + \
abs(self.agent_positions[i][1] - self.goal_positions[i][1])
dist_reward -= dist * 0.1 # 缩放后的负距离
reward = -0.05 + dist_reward + hit_wall_penalty # 每步的小惩罚 + 距离 + 墙壁惩罚
next_observations = self.get_joint_observation()
# 共享奖励
rewards = [reward] * self.num_agents
return next_observations, rewards, done实例化并测试多智能体环境。
python
maddpg_env = MultiAgentGridEnv(size=5, num_agents=2)
initial_obs_list = maddpg_env.reset()
print(f"MADDPG 环境大小:{maddpg_env.size}x{maddpg_env.size}")
print(f"智能体数量:{maddpg_env.num_agents}")
print(f"每个智能体的动作维度:{maddpg_env.action_dim}")
print(f"每个智能体的观察维度:{maddpg_env.observation_dim_per_agent}")
print(f"智能体 0 的初始观察:{initial_obs_list[0]}")
print(f"智能体 1 的初始观察:{initial_obs_list[1]}")
# 示例步骤
actions_example = [1, 2] # 智能体 0 向下,智能体 1 向左
next_obs_list, rewards_list, done_flag = maddpg_env.step(actions_example)
print(f"\n执行动作 {actions_example} 后:")
print(f" 智能体 0 的下一个观察:{next_obs_list[0]}")
print(f" 智能体 1 的下一个观察:{next_obs_list[1]}")
print(f" 共享奖励:{rewards_list[0]}")
print(f" 完成:{done_flag}")MADDPG 环境大小:5x5
智能体数量:2
每个智能体的动作维度:4
每个智能体的观察维度:6
智能体 0 的初始观察:[0. 0. 1. 1. 1. 0.]
智能体 1 的初始观察:[1. 1. 0. 0. 0. 1.]
执行动作 [1, 2] 后:
智能体 0 的下一个观察:[0.25 0. 1. 0.75 1. 0. ]
智能体 1 的下一个观察:[1. 0.75 0.25 0. 0. 1. ]
共享奖励:-0.8500000000000001
完成:False实现 MADDPG 算法
定义演员网络(离散动作)
输出一个分类分布的 logits,用于离散动作。
python
class ActorDiscrete(nn.Module):
""" 离散动作的演员网络,用于 MADDPG。 """
def __init__(self, obs_dim: int, action_dim: int):
super(ActorDiscrete, self).__init__()
self.fc1 = nn.Linear(obs_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, action_dim)
def forward(self, obs: torch.Tensor) -> Categorical:
""" 将观察映射到动作 logits -> 分类分布。 """
x = F.relu(self.fc1(obs))
x = F.relu(self.fc2(x))
action_logits = self.fc3(x)
return Categorical(logits=action_logits)
def select_action(self, obs: torch.Tensor, use_exploration=True) -> Tuple[torch.Tensor, torch.Tensor]:
""" 根据策略选择动作(采样或 argmax)。 """
dist = self.forward(obs)
if use_exploration:
action = dist.sample()
else: # 测试或目标动作预测时使用确定性
action = torch.argmax(dist.probs, dim=-1)
log_prob = dist.log_prob(action)
return action, log_prob定义集中式评论家网络
以联合观察和联合动作为输入。
python
class CentralizedCritic(nn.Module):
""" 集中式评论家网络,用于 MADDPG。 """
def __init__(self, joint_obs_dim: int, joint_action_dim: int):
super(CentralizedCritic, self).__init__()
# 输入大小 = 所有观察的大小 + 所有动作的大小
self.fc1 = nn.Linear(joint_obs_dim + joint_action_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, 1) # 为特定智能体输出单个 Q 值
def forward(self, joint_obs: torch.Tensor, joint_actions: torch.Tensor) -> torch.Tensor:
""" 将联合观察和动作映射到 Q 值。 """
# 确保动作格式正确(例如,离散动作的 one-hot)
# 为了简化,这里我们假设直接传递动作索引(在实际中可能需要进行处理,例如嵌入)
# 假设动作已经正确处理(例如,连续动作或已嵌入)
x = torch.cat([joint_obs, joint_actions], dim=1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
q_value = self.fc3(x)
return q_value定义回放缓冲区
存储联合转换。
python
# 定义 MADDPG 缓冲区的转换结构
# 为了方便批量处理,通常将每个智能体的数据分别存储
Experience = namedtuple('Experience',
('obs_list', 'action_list', 'reward_list',
'next_obs_list', 'done_list'))
# 多智能体回放缓冲区(修改为处理智能体数据列表)
class MultiAgentReplayBuffer:
def __init__(self, capacity: int):
self.memory = deque([], maxlen=capacity)
def push(self, obs_list: List[np.ndarray], action_list: List[int],
reward_list: List[float], next_obs_list: List[np.ndarray],
done: bool) -> None:
""" 保存联合转换。 """
# 将 numpy 数组转换为张量(或直接存储为 numpy)
# 在批量处理之前,存储为 numpy 可能会稍微节省一些内存
obs_t = [torch.from_numpy(o).float() for o in obs_list]
act_t = torch.tensor(action_list, dtype=torch.long) # 存储动作索引
rew_t = torch.tensor(reward_list, dtype=torch.float32)
next_obs_t = [torch.from_numpy(o).float() for o in next_obs_list]
done_t = torch.tensor([float(done)] * len(obs_list), dtype=torch.float32) # 为每个智能体重复完成标志
self.memory.append(Experience(obs_t, act_t, rew_t, next_obs_t, done_t))
def sample(self, batch_size: int) -> Optional[Experience]:
""" 采样一批经验。 """
if len(self.memory) < batch_size:
return None
experiences = random.sample(self.memory, batch_size)
# 批量处理:对每个组件进行堆叠,跨越批次和智能体
# 需要仔细处理结果形状,在更新步骤中使用
obs_batch, act_batch, rew_batch, next_obs_batch, dones_batch = zip(*experiences)
# 示例:堆叠观察 -> (batch_size, num_agents, obs_dim)
obs_batch_stacked = torch.stack([torch.stack(obs) for obs in obs_batch])
act_batch_stacked = torch.stack(act_batch) # (batch_size, num_agents)
rew_batch_stacked = torch.stack(rew_batch) # (batch_size, num_agents)
next_obs_batch_stacked = torch.stack([torch.stack(n_obs) for n_obs in next_obs_batch])
dones_batch_stacked = torch.stack(dones_batch) # (batch_size, num_agents)
# 返回一个包含批量张量的命名元组
return Experience(obs_batch_stacked, act_batch_stacked, rew_batch_stacked,
next_obs_batch_stacked, dones_batch_stacked)
def __len__(self) -> int:
return len(self.memory)软更新函数
标准的软更新。
python
def soft_update(target_net: nn.Module, main_net: nn.Module, tau: float) -> None:
for target_param, main_param in zip(target_net.parameters(), main_net.parameters()):
target_param.data.copy_(tau * main_param.data + (1.0 - tau) * target_param.data)MADDPG 智能体管理器类
一个类,用于管理多个智能体、它们的网络和优化器。
python
class MADDPGAgentManager:
""" 管理多个智能体、它们的网络和更新,用于 MADDPG。 """
def __init__(self, num_agents: int, obs_dim_list: List[int], action_dim: int,
actor_lr: float, critic_lr: float, gamma: float, tau: float,
device: torch.device):
self.num_agents = num_agents
self.obs_dim_list = obs_dim_list
self.action_dim = action_dim
self.gamma = gamma
self.tau = tau
self.device = device
# 计算评论家所需的联合维度
joint_obs_dim = sum(obs_dim_list)
# 对于离散动作,评论家需要适当的表示(例如,one-hot 或索引)
# 如果传递索引,则需要嵌入或小心处理。如果使用 one-hot,则维度为 num_agents * action_dim。
# 假设将动作索引传递给评论家。
joint_action_dim_one_hot = num_agents * action_dim
self.actors: List[ActorDiscrete] = []
self.critics: List[CentralizedCritic] = []
self.target_actors: List[ActorDiscrete] = []
self.target_critics: List[CentralizedCritic] = []
self.actor_optimizers: List[optim.Optimizer] = []
self.critic_optimizers: List[optim.Optimizer] = []
for i in range(num_agents):
# 为智能体 i 创建网络
actor = ActorDiscrete(obs_dim_list[i], action_dim).to(device)
critic = CentralizedCritic(joint_obs_dim, joint_action_dim_one_hot).to(device)
target_actor = ActorDiscrete(obs_dim_list[i], action_dim).to(device)
target_critic = CentralizedCritic(joint_obs_dim, joint_action_dim_one_hot).to(device)
# 初始化目标网络
target_actor.load_state_dict(actor.state_dict())
target_critic.load_state_dict(critic.state_dict())
for p in target_actor.parameters(): p.requires_grad = False
for p in target_critic.parameters(): p.requires_grad = False
# 创建优化器
actor_optimizer = optim.Adam(actor.parameters(), lr=actor_lr)
critic_optimizer = optim.Adam(critic.parameters(), lr=critic_lr)
# 存储智能体组件
self.actors.append(actor)
self.critics.append(critic)
self.target_actors.append(target_actor)
self.target_critics.append(target_critic)
self.actor_optimizers.append(actor_optimizer)
self.critic_optimizers.append(critic_optimizer)
def select_actions(self, obs_list: List[torch.Tensor], use_exploration=True) -> Tuple[List[int], List[torch.Tensor]]:
""" 根据局部观察为所有智能体选择动作。 """
actions = []
log_probs = []
for i in range(self.num_agents):
self.actors[i].eval()
with torch.no_grad():
act, log_prob = self.actors[i].select_action(obs_list[i].to(self.device), use_exploration)
# 如果是单个观察,则转换为标量
if act.dim() == 0:
act = act.item()
self.actors[i].train()
actions.append(act)
log_probs.append(log_prob)
return actions, log_probs
def update(self, batch: Experience, agent_id: int) -> Tuple[float, float]:
""" 为单个智能体 'agent_id' 执行更新。 """
# 解包批量数据
# 形状:obs/next_obs(B, N, O_dim),acts(B, N),rews(B, N),dones(B, N)
obs_batch, act_batch, rew_batch, next_obs_batch, dones_batch = batch
batch_size = obs_batch.shape[0]
# 为集中式评论家准备输入
# 堆叠观察:(B, N, O) -> (B, N*O)
joint_obs = obs_batch.view(batch_size, -1).to(self.device)
joint_next_obs = next_obs_batch.view(batch_size, -1).to(self.device)
# 将动作索引转换为 one-hot 编码,供评论家输入
act_one_hot = F.one_hot(act_batch, num_classes=self.action_dim).float()
joint_actions_one_hot = act_one_hot.view(batch_size, -1).to(self.device)
# 获取当前智能体的奖励和完成标志
rewards_i = rew_batch[:, agent_id].unsqueeze(-1).to(self.device)
dones_i = dones_batch[:, agent_id].unsqueeze(-1).to(self.device)
# --- 评论家更新 ---
with torch.no_grad():
# 从所有目标演员那里获取下一个动作
target_next_actions_list = []
for j in range(self.num_agents):
# 输入:智能体 j 在批量中的下一个观察 (B, O_j)
obs_j_next = next_obs_batch[:, j, :].to(self.device)
# 从目标演员 j 获取确定性动作
action_j_next, _ = self.target_actors[j].select_action(obs_j_next, use_exploration=False)
# 将动作索引转换为 one-hot
action_j_next_one_hot = F.one_hot(action_j_next, num_classes=self.action_dim).float()
target_next_actions_list.append(action_j_next_one_hot)
# 堆叠目标下一个动作:(B, N*A_onehot)
joint_target_next_actions = torch.cat(target_next_actions_list, dim=1).to(self.device)
# 从目标评论家 i 获取目标 Q 值
q_target_next = self.target_critics[agent_id](joint_next_obs, joint_target_next_actions)
# 计算目标 y = r_i + gamma * Q'_i * (1 - d_i)
y = rewards_i + self.gamma * (1.0 - dones_i) * q_target_next
# 获取主评论家 i 的当前 Q 估计值
q_current = self.critics[agent_id](joint_obs, joint_actions_one_hot)
# 计算评论家损失
critic_loss = F.mse_loss(q_current, y)
# 优化评论家 i
self.critic_optimizers[agent_id].zero_grad()
critic_loss.backward()
torch.nn.utils.clip_grad_norm_(self.critics[agent_id].parameters(), 1.0) # 可选的梯度裁剪
self.critic_optimizers[agent_id].step()
# --- 演员更新 ---
# 冻结评论家梯度,用于演员更新
for p in self.critics[agent_id].parameters():
p.requires_grad = False
# 根据批量观察,使用所有智能体的当前演员计算动作
current_actions_list = []
log_probs_i_list = [] # 仅存储智能体 i 的 log_prob
for j in range(self.num_agents):
obs_j = obs_batch[:, j, :].to(self.device)
# 需要动作概率/logits 进行更新 - 使用类似 Gumbel-Softmax 或 REINFORCE 的更新
dist_j = self.actors[j](obs_j) # 获取分类分布
# 如果使用 DDPG 目标:Q(s, mu(s)),我们需要确定性动作
# 适应使用策略梯度:最大化 E[log_pi_i * Q_i_detached]
action_j = dist_j.sample() # 采样动作作为 Q 的输入
if j == agent_id:
log_prob_i = dist_j.log_prob(action_j) # 仅需要更新的智能体的 log_prob
action_j_one_hot = F.one_hot(action_j, num_classes=self.action_dim).float()
current_actions_list.append(action_j_one_hot)
joint_current_actions = torch.cat(current_actions_list, dim=1).to(self.device)
# 计算演员损失:- E[log_pi_i * Q_i_detached]
# Q_i 在所有演员的当前动作下进行评估
q_for_actor_loss = self.critics[agent_id](joint_obs, joint_current_actions)
actor_loss = -(log_prob_i * q_for_actor_loss.detach()).mean() # 剥离 Q 值
# 替代的 DDPG 风格损失(如果演员是确定性的):
# actor_loss = -self.critics[agent_id](joint_obs, joint_current_actions).mean()
# 优化演员 i
self.actor_optimizers[agent_id].zero_grad()
actor_loss.backward()
torch.nn.utils.clip_grad_norm_(self.actors[agent_id].parameters(), 1.0) # 可选的梯度裁剪
self.actor_optimizers[agent_id].step()
# 解冻评论家梯度
for p in self.critics[agent_id].parameters():
p.requires_grad = True
return critic_loss.item(), actor_loss.item()
def update_targets(self) -> None:
""" 为所有目标网络执行软更新。 """
for i in range(self.num_agents):
soft_update(self.target_critics[i], self.critics[i], self.tau)
soft_update(self.target_actors[i], self.actors[i], self.tau)运行 MADDPG 算法
超参数设置
python
# MADDPG 在自定义多智能体网格世界中的超参数
BUFFER_SIZE_MADDPG = int(1e5)
BATCH_SIZE_MADDPG = 256
GAMMA_MADDPG = 0.99
TAU_MADDPG = 1e-3
ACTOR_LR_MADDPG = 1e-4
CRITIC_LR_MADDPG = 1e-3
EPSILON_MADDPG_START = 1.0 # 用于离散动作的 epsilon-greedy 探索
EPSILON_MADDPG_END = 0.05
EPSILON_MADDPG_DECAY = 50000 # 在这么多步中衰减
NUM_EPISODES_MADDPG = 200
MAX_STEPS_PER_EPISODE_MADDPG = 100
UPDATE_EVERY_MADDPG = 4 # 每 N 个环境步执行一次更新
NUM_UPDATES_MADDPG = 1 # 每次更新间隔的更新次数初始化
python
# 初始化环境
env_maddpg = MultiAgentGridEnv(size=5, num_agents=2)
num_agents = env_maddpg.num_agents
obs_dims = [env_maddpg.observation_dim_per_agent] * num_agents
action_dim = env_maddpg.action_dim
# 初始化智能体管理器
maddpg_manager = MADDPGAgentManager(
num_agents=num_agents,
obs_dim_list=obs_dims,
action_dim=action_dim,
actor_lr=ACTOR_LR_MADDPG,
critic_lr=CRITIC_LR_MADDPG,
gamma=GAMMA_MADDPG,
tau=TAU_MADDPG,
device=device
)
# 初始化回放缓冲区
memory_maddpg = MultiAgentReplayBuffer(BUFFER_SIZE_MADDPG)
# 用于绘图的列表
maddpg_episode_rewards = [] # 每个剧集存储总奖励(智能体总和)
maddpg_critic_losses = [[] for _ in range(num_agents)] # 每个智能体的评论家损失列表
maddpg_actor_losses = [[] for _ in range(num_agents)] # 每个智能体的演员损失列表训练循环
python
print("开始 MADDPG 训练...")
total_steps_maddpg = 0
epsilon = EPSILON_MADDPG_START
for i_episode in range(1, NUM_EPISODES_MADDPG + 1):
obs_list_np = env_maddpg.reset()
obs_list = [torch.from_numpy(o).float().to(device) for o in obs_list_np]
episode_reward = 0
ep_critic_losses = [0.0] * num_agents
ep_actor_losses = [0.0] * num_agents
num_updates_ep = 0
for t in range(MAX_STEPS_PER_EPISODE_MADDPG):
# --- 动作选择 ---
# 使用 epsilon-greedy 适应离散动作
if random.random() < epsilon:
actions_list = [random.randrange(action_dim) for _ in range(num_agents)]
else:
# 从演员那里获取动作(use_exploration=False 给出 argmax 用于测试)
actions_list, _ = maddpg_manager.select_actions(obs_list, use_exploration=False)
# --- 环境交互 ---
next_obs_list_np, rewards_list, done = env_maddpg.step(actions_list)
# --- 存储经验(联合) ---
memory_maddpg.push(obs_list_np, actions_list, rewards_list, next_obs_list_np, done)
# 更新状态表示
obs_list_np = next_obs_list_np
obs_list = [torch.from_numpy(o).float().to(device) for o in obs_list_np]
# 累积共享奖励用于记录
episode_reward += rewards_list[0] # 使用智能体 0 的奖励作为共享奖励
total_steps_maddpg += 1
# --- 更新网络 ---
if len(memory_maddpg) > BATCH_SIZE_MADDPG and total_steps_maddpg % UPDATE_EVERY_MADDPG == 0:
for _ in range(NUM_UPDATES_MADDPG):
batch = memory_maddpg.sample(BATCH_SIZE_MADDPG)
if batch:
for agent_id in range(num_agents):
c_loss, a_loss = maddpg_manager.update(batch, agent_id)
ep_critic_losses[agent_id] += c_loss
ep_actor_losses[agent_id] += a_loss
num_updates_ep += 1
# 在更新所有智能体后更新目标网络
maddpg_manager.update_targets()
# 衰减 epsilon
epsilon = max(EPSILON_MADDPG_END, EPSILON_MADDPG_START - total_steps_maddpg / EPSILON_MADDPG_DECAY * (EPSILON_MADDPG_START - EPSILON_MADDPG_END))
if done:
break
# --- 剧集结束 ---
maddpg_episode_rewards.append(episode_reward)
for i in range(num_agents):
maddpg_critic_losses[i].append(ep_critic_losses[i] / num_updates_ep if num_updates_ep > 0 else 0)
maddpg_actor_losses[i].append(ep_actor_losses[i] / num_updates_ep if num_updates_ep > 0 else 0)
# 打印进度
if i_episode % 50 == 0:
avg_reward = np.mean(maddpg_episode_rewards[-50:])
avg_closs = np.mean([np.mean(maddpg_critic_losses[i][-50:]) for i in range(num_agents)])
avg_aloss = np.mean([np.mean(maddpg_actor_losses[i][-50:]) for i in range(num_agents)])
print(f"剧集 {i_episode}/{NUM_EPISODES_MADDPG} | 步数:{total_steps_maddpg} | 平均奖励:{avg_reward:.2f} | 平均 C_Loss:{avg_closs:.4f} | 平均 A_Loss:{avg_aloss:.4f} | Epsilon:{epsilon:.3f}")
print("训练完成 (MADDPG)。")开始 MADDPG 训练...
剧集 50/200 | 步数:4130 | 平均奖励:-65.08 | 平均 C_Loss:0.1754 | 平均 A_Loss:-1.5070 | Epsilon:0.922
剧集 100/200 | 步数:7739 | 平均奖励:-57.36 | 平均 C_Loss:0.0337 | 平均 A_Loss:-2.1525 | Epsilon:0.853
剧集 150/200 | 步数:11024 | 平均奖励:-47.13 | 平均 C_Loss:0.0143 | 平均 A_Loss:-2.8037 | Epsilon:0.791
剧集 200/200 | 步数:14686 | 平均奖励:-54.68 | 平均 C_Loss:0.0153 | 平均 A_Loss:-3.7225 | Epsilon:0.721
训练完成 (MADDPG)。可视化学习过程
绘制每个剧集的聚合奖励和每个智能体的平均损失。
python
# 绘制 MADDPG 的结果
plt.figure(figsize=(18, 4))
# 剧集奖励(共享)
plt.subplot(1, 3, 1)
plt.plot(maddpg_episode_rewards)
plt.title('MADDPG 网格世界:剧集奖励(共享)')
plt.xlabel('剧集')
plt.ylabel('总奖励')
plt.grid(True)
if len(maddpg_episode_rewards) >= 50:
rewards_ma_maddpg = np.convolve(maddpg_episode_rewards, np.ones(50)/50, mode='valid')
plt.plot(np.arange(len(rewards_ma_maddpg)) + 49, rewards_ma_maddpg, label='50-剧集移动平均', color='orange')
plt.legend()
# 平均评论家损失 / 剧集
avg_critic_losses = np.mean(maddpg_critic_losses, axis=0)
plt.subplot(1, 3, 2)
plt.plot(avg_critic_losses)
plt.title('MADDPG 网格世界:平均评论家损失 / 剧集')
plt.xlabel('剧集')
plt.ylabel('平均 MSE 损失')
plt.grid(True)
if len(avg_critic_losses) >= 50:
closs_ma_maddpg = np.convolve(avg_critic_losses, np.ones(50)/50, mode='valid')
plt.plot(np.arange(len(closs_ma_maddpg)) + 49, closs_ma_maddpg, label='50-剧集移动平均', color='orange')
plt.legend()
# 平均演员损失 / 剧集
avg_actor_losses = np.mean(maddpg_actor_losses, axis=0)
plt.subplot(1, 3, 3)
plt.plot(avg_actor_losses)
plt.title('MADDPG 网格世界:平均演员损失 / 剧集')
plt.xlabel('剧集')
plt.ylabel('平均策略梯度损失')
plt.grid(True)
if len(avg_actor_losses) >= 50:
aloss_ma_maddpg = np.convolve(avg_actor_losses, np.ones(50)/50, mode='valid')
plt.plot(np.arange(len(aloss_ma_maddpg)) + 49, aloss_ma_maddpg, label='50-剧集移动平均', color='orange')
plt.legend()
plt.tight_layout()
plt.show()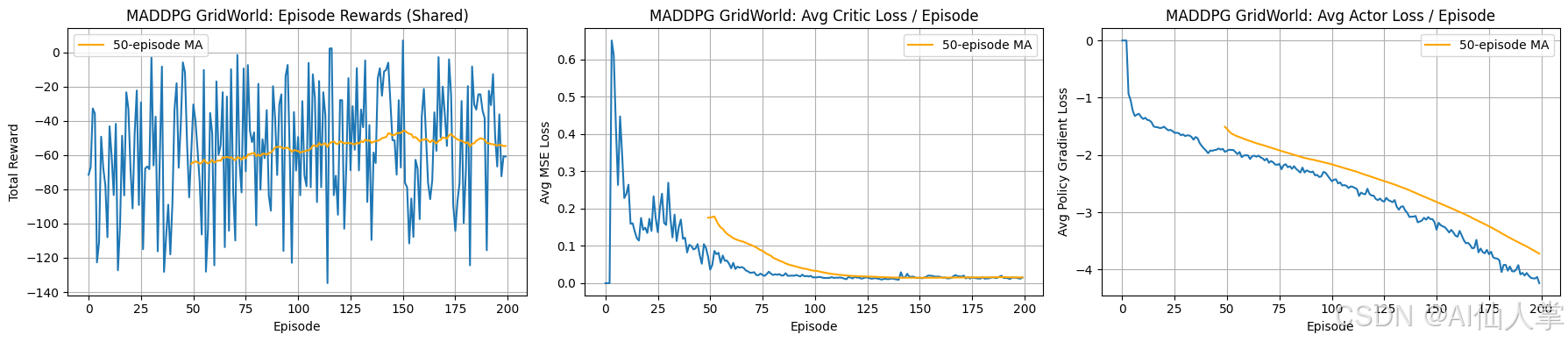
MADDPG 学习曲线分析(网格世界 - 共享奖励):
-
剧集奖励(共享):
- 观察结果: 每个剧集的总共享奖励在整个训练期间(200 个剧集)表现出极大的波动。尽管 50-剧集移动平均值(橙色线)表明有一些学习正在发生,但平均值仍然显著为负(在结束时大约为 -50),并且远未达到任何潜在的最优值(这在目标到达任务中可能是正的)。从一个剧集到下一个剧集,性能的大幅波动没有显示出稳定在高奖励水平的迹象。
- 解释: 这个图表突出了遇到的主要挑战:实现稳定的协作行为。高方差表明分散的演员在一致协调动作以实现共享目标方面存在困难。虽然移动平均值显示一些改善,超出了随机行为,但缺乏收敛到高奖励的收敛表明在这些条件下发现一个稳健的协作联合策略是困难的。学习过程不稳定,这是多智能体交互引入的复杂性的特征。
-
平均评论家损失 / 剧集:
- 观察结果: 与奖励形成鲜明对比的是,集中式评论家的平均均方误差(MSE)损失表现出极佳的收敛特性。在一些初始高尖峰之后(可能是由于随机初始策略和较大的预测误差),损失在大约前 50 个剧集内显著下降,并稳定地收敛到零,其余训练期间保持非常低的水平。
- 解释: 这表明集中式评论家,它观察所有智能体的动作和状态,能够有效地学习预测联合状态-动作对的预期共享回报(Q 值)。损失的快速收敛到低水平表明价值估计组件的 MADDPG 正在正常工作,并能够根据它接收到的数据准确评估智能体集体动作的后果。
-
平均演员损失 / 剧集:
- 观察结果: 平均演员损失,代表策略梯度目标(通常与评论家估计的 Q 值有关,用于演员选择的动作),显示出清晰且一致的下降趋势(变得更负)。这表明,平均而言,演员正在成功地根据评论家提供的梯度信息调整其策略,朝着评论家建议的更高预期回报的方向发展。
- 解释: 这个图表证实了策略更新机制按预期工作。每个分散的演员都使用集中式评论家提供的梯度信息来改进其个人策略。稳步下降表明根据评论家的当前估计一致地改进策略。
总体结论:
MADDPG 的结果呈现出多智能体学习中常见的有趣画面。底层机制------集中式评论家学习价值函数以及分散式演员根据评论家指导更新策略------似乎正常工作,如收敛的损失图表所示。然而,这种内部学习进展并没有转化为稳定、高奖励的团队表现。共享奖励的极端波动表明在协调、信用分配或处理非平稳环境(每个智能体的策略变化影响其他智能体的最优策略)方面存在显著挑战。尽管评论家学会了什么 是好的联合动作,但分散的演员在一致发现和执行这些协调动作方面存在困难,导致在观察到的训练期间内整体结果不稳定。
分析学习到的策略(测试)
使用训练好的演员分散地进行测试。
python
def test_maddpg_agents(manager: MADDPGAgentManager,
env_instance: MultiAgentGridEnv,
num_episodes: int = 5,
seed_offset: int = 5000) -> None:
""" 测试训练好的 MADDPG 智能体分散地行动。 """
print(f"\n--- 测试 MADDPG 智能体 ({num_episodes} 个剧集) ---")
all_episode_rewards = []
for i in range(num_episodes):
obs_list_np = env_instance.reset() # 如果环境支持,使用内部种子
obs_list = [torch.from_numpy(o).float().to(manager.device) for o in obs_list_np]
episode_reward = 0
done = False
t = 0
while not done and t < MAX_STEPS_PER_EPISODE_MADDPG: # 添加测试步数限制
# 分散地获取动作,不添加探索噪声
actions_list, _ = maddpg_manager.select_actions(obs_list, use_exploration=True)
# 执行环境步骤
next_obs_list_np, rewards_list, done = env_instance.step(actions_list)
# 更新观察
obs_list = [torch.from_numpy(o).float().to(manager.device) for o in next_obs_list_np]
episode_reward += rewards_list[0] # 跟踪共享奖励
t += 1
print(f"测试剧集 {i+1}:奖励 = {episode_reward:.2f}, 长度 = {t}")
all_episode_rewards.append(episode_reward)
print(f"--- 测试完成。平均奖励:{np.mean(all_episode_rewards):.2f} ---")
# 运行测试剧集
test_maddpg_agents(maddpg_manager, env_maddpg, num_episodes=5)--- 测试 MADDPG 智能体 (5 个剧集) ---
测试剧集 1:奖励 = -78.40, 长度 = 100
测试剧集 2:奖励 = -119.80, 长度 = 100
测试剧集 3:奖励 = -88.30, 长度 = 100
测试剧集 4:奖励 = -35.60, 长度 = 53
测试剧集 5:奖励 = -80.10, 长度 = 100
--- 测试完成。平均奖励:-80.44 ---MADDPG 的常见挑战和扩展
挑战:集中式评论家的可扩展性
- 问题:集中式评论家的输入维度随着智能体数量线性增长(联合观察 + 联合动作)。对于大量智能体,这可能变得计算上不可行。
- 解决方案 :
- 参数共享:为相似的智能体使用共享网络参数。
- 注意力机制:使用注意力机制让评论家专注于其他智能体的相关信息。
- 近似方法:使用近似集中式评论家的方法,无需完整的联合信息(例如,平均场方法)。
挑战:合作设置中的信用分配
- 问题 :当使用共享团队奖励时,很难让单个智能体的评论家确定该智能体对团队成功的具体贡献(信用分配问题)。
解决方案 :- 反事实基线(COMA):将当前联合 Q 值与仅当前智能体动作变化的基线进行比较。
- 价值分解网络(VDN,QMIX):学习智能体的个体 Q 函数,这些函数组合(例如,求和)形成联合 Q 函数,强制执行对信用分配有用的关联。
挑战:对超参数的敏感性
- 问题 :与 DDPG 一样,MADDPG 对学习率、目标更新、探索噪声、缓冲区大小等超参数敏感。
解决方案:需要仔细调整,通常针对特定的 MARL 问题。
挑战:连续动作空间问题
- 问题 :原始的 MADDPG 继承了 DDPG 在连续动作空间中的潜在不稳定性(例如,Q 值高估)。
解决方案:将 TD3 的想法(例如,双集中式评论家、延迟策略更新、目标动作平滑)纳入 MADDPG 框架(结果是 MATD3)。
扩展:
- MATD3:将 TD3 改进纳入 MADDPG。
- MAPPO:将 PPO 适应于多智能体设置,通常使用集中式价值函数。
- 价值分解方法(VDN,QMIX):专注于具有共享奖励的合作任务。
结论
MADDPG 为将深度演员-评论家方法应用于多智能体环境提供了一个有效的框架。通过利用集中式训练(特别是通过集中式评论家了解联合信息)和分散式执行(演员使用局部观察),它成功地缓解了 MARL 中固有的非平稳性挑战。
其能够处理各种智能体互动(合作、竞争、混合)和动作空间,使得它成为一个多功能的算法。尽管存在挑战,特别是关于扩展到大量智能体以及稳健的信用分配,MADDPG 代表了 MARL 的重要一步,并且是许多后续多智能体算法的基础。