1、hiveserver2
参与用户模拟功能,因为开启后才能保证各用户之间的权限隔离。
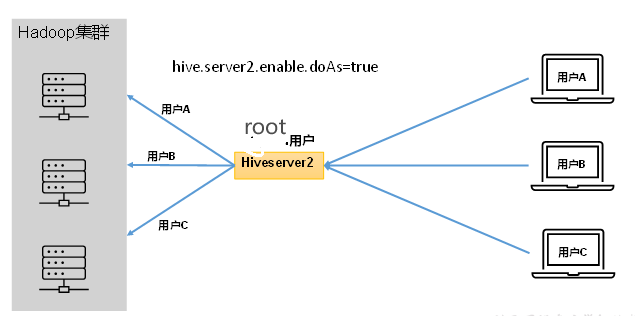
1.1、配置
$HADOOP_HOME/etc/hadoop/core-site.xml
XML
<!--配置所有节点的root用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--配置root用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!--配置root用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>hive-site.xml
XML
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node154</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>1.2、启动
由于启用了hive.metastore.uris参数,所以需要先启用metastore,详情见另一篇博客hive在配置文件中添加了hive.metastore.uris之后进入hive输入命令报错-CSDN博客
bash
nohup hive --service metastore & #启动 metastore (如果没配置就不用手动开启)
hive --service hiveserver22、beeline
替代hive cli的另一种连接hive的方式,命令
bash
bin/beeline -u jdbc:hive2://node154:10000 -n root还可能遇到hdfs进入安全模式,离开安全模式
XML
hadoop dfsadmin -safemode leave