前言
目前 OCR 有比较成熟的方案,想着直接通过 docker 部署一个提供 api 接口服务,查看了一些开源方案,最终发现还是 PaddleOCR 比较好用。
本篇不介绍 PaddleOCR 的详细使用方式,只介绍一下构建镜像的 dockerfile 需要注意的事项。
docker 镜像构建
目录结构
- inference_models (下载好的模型放这里,可以直接在 dockerfile 中下载)
- PaddleOCR (git仓库,可以直接在 dockerfile 中克隆)
- dockerfiledockerfile 内容如下,网络环境需要自己整一下,可直接食用:
bash
# 使用 paddlepaddle/paddle:3.0.0 镜像作为基础镜像
FROM paddlepaddle/paddle:3.0.0
# 设置工作目录
WORKDIR /app
# 安装 paddlehub
RUN pip3 install paddlehub --upgrade
# 安装兼容版本的 protobuf
RUN pip3 install protobuf==3.20.0
# 克隆 PaddleOCR 仓库
RUN git clone https://github.com/PaddlePaddle/PaddleOCR.git
# COPY ./PaddleOCR ./PaddleOCR
WORKDIR /app/PaddleOCR
# 下载并解压 OCR 文本检测、文本识别、文本方向分类模型
RUN mkdir -p inference && \
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar && \
tar -xf ch_PP-OCRv3_det_infer.tar -C inference && \
# 由于 git 仓库中的名称不同,改一下
mv ./inference/ch_PP-OCRv3_det_infer ./inference/PP-OCRv3_mobile_det_infer && \
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar && \
tar -xf ch_PP-OCRv3_rec_infer.tar -C inference && \
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && \
tar -xf ch_ppocr_mobile_v2.0_cls_infer.tar -C inference
# COPY ./inference_models /app/PaddleOCR/inference
# 安装 PaddleOCR 的 Python 依赖
RUN pip3 install -r requirements.txt
# 安装 hub 模块
RUN hub install deploy/hubserving/ocr_system
# 暴露端口
EXPOSE 8866
# 启动服务的命令
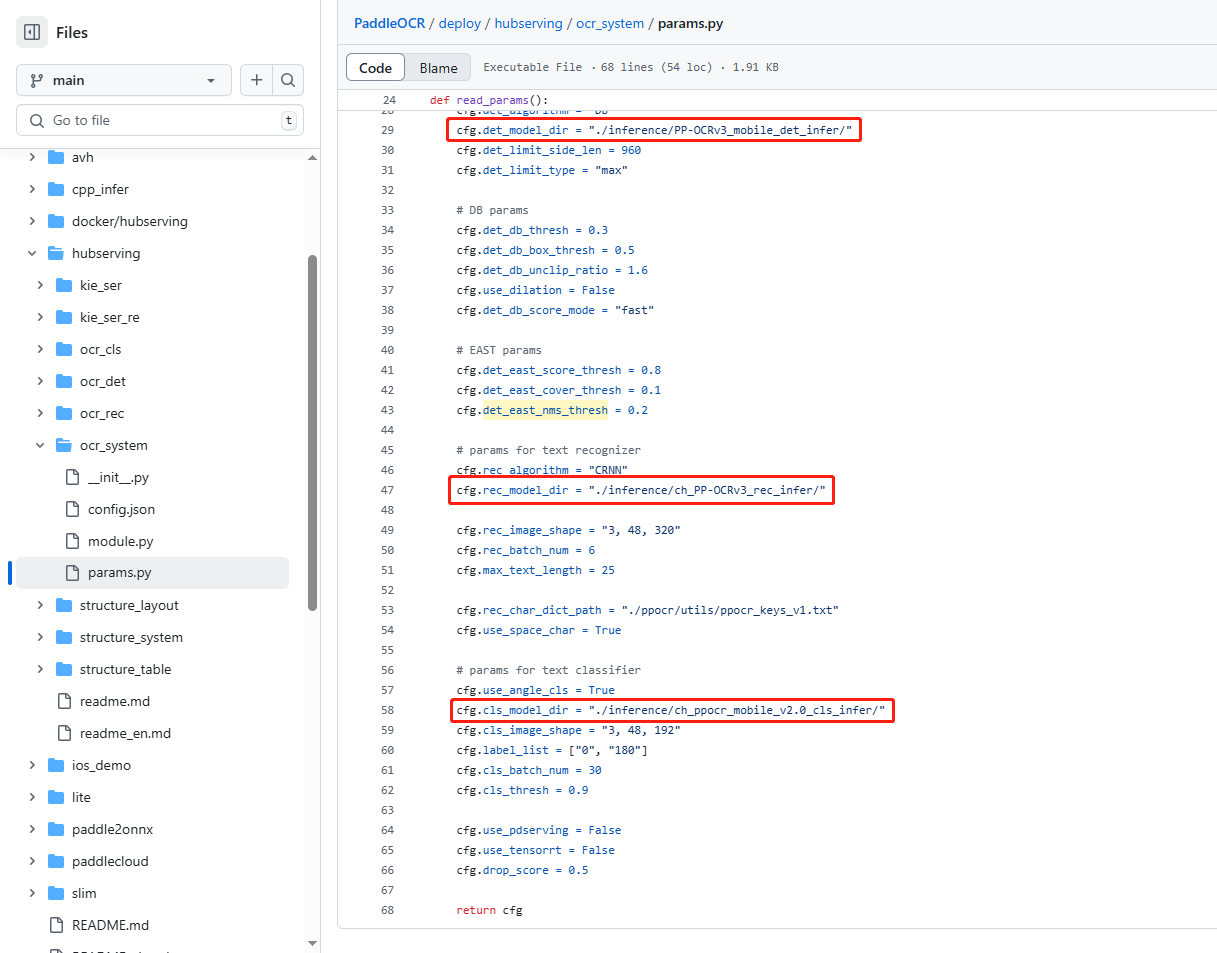
CMD ["hub", "serving", "start", "--modules", "ocr_system", "-p", "8866"]注意:使用 ocr_system 服务,使用的模型是在这里 PaddleOCR/deploy/hubserving/ocr_system/params.py 定义的,如果模型的路径不对,需要手动修改。
-
编译镜像:
docker build -t ocr_test -f dockerfile . -
运行容器:
docker run -d --name paddleocr_hubserving_container -p 8866:8866 ocr_test -
客户端测试:服务启动后,可以通过访问
http://127.0.0.1:8866/predict/ocr_system来测试OCR识别服务。
bash
curl -X POST \
http://127.0.0.1:8866/predict/ocr_system \
-H "Content-Type: application/json" \
-d '{"images": ["/9j/4AAQSkZJRgABAQ..."]}'注意:这里的 images 中放的是图片的 base64 字符串,是不需要带 data:image/jpeg;base64, 这种头的。
总结
本篇介绍了如何使用 docker 快速部署基于 PaddleOCR 的 OCR API 服务,包括构建镜像、运行容器及进行客户端测试的完整步骤。
提供的 dockerfile 可以直接使用,处理了 protobuf 版本错误,以及 params.py 中模型路径匹配。