本案例是基于flinksql实现的,将逐步实现从kafka读写数据,聚合查询,关联维表(外部系统)等。
环境准备
首先确保电脑已经安装好zookeeper、kafka、flink。本文flink使用单机模式,zookeeper和kafka也使用单机配置。(环境配置部分可以跳过)
首先启动zookeeper
# 启动zookeeper
bin/zkServer.sh start
# 关闭zookeeper
bin/zkServer.sh stop然后启动kafka
# 启动kafka
bin/kafka-server-start.sh -daemon config/server.properties
# 关闭kafka
bin/kafka-server-stop.sh -daemon config/server.properties启动flink集群,并打开sql客户端
# 启动flink集群
bin/start-cluster.sh
# 启动sql客户端
bin/sql-client.sh embedded -s yarn-session
# 关闭flink集群
bin/stop-cluster.sh案例1:从kafka读取csv格式数据
数据准备
csv格式数据是以','进行分隔。本案例设计一个学生信息表,包含学生id,学生姓名,学生年级字段。
# 示范数据
1,"zhangsan",2021
2,"lisi",2021
3,"wangwu",2024
4,"Bob",2021
5,"Lily",2022kafka 主题相关命令
# 遍历已有topic
bin/kafka-topics.sh --bootstrap-server 192.168.137.201:9092 --list
# 生产者
bin/kafka-console-producer.sh --bootstrap-server node1:9092 --topic test
# 消费者
bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic test --from-beginning创建kafka表
create table kafkatable (
`stu_id` bigint,
`stu_name` string,
`grade` bigint
) with (
'connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = 'node1:9092',
'properties.group.id' = 'testgroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv'
) 本案例读test分区的最新数据,如需修改,参考以下链接:
注意:kafka-flink连接器需要手动上传到flink安装目录下的lib目录下,官网有提供对应jar包。
案例实现
-- 实时查看kafkatable数据
select * from kafkatable;
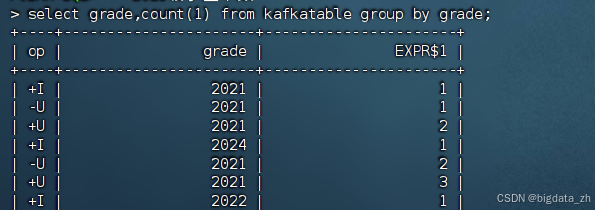
-- 查看不同年级学生数量
select grade,count(1) from kafkatable group by grade;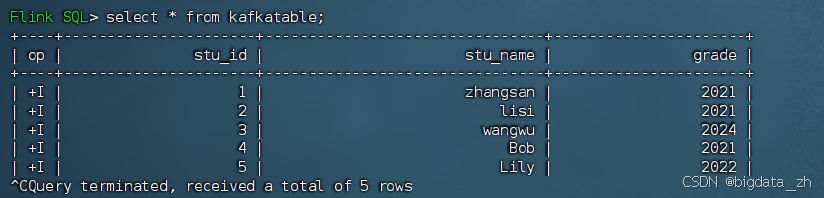
案例2:从kafka读取json格式数据
数据准备
{"stu_id": 1, "stu_name": "zhangsan", "grade": 2021}
{"stu_id": 2, "stu_name": "lisi", "grade": 2021}
{"stu_id": 3, "stu_name": "wangwu", "grade": 2024}
{"stu_id": 4, "stu_name": "Bob", "grade": 2021}
{"stu_id": 5, "stu_name": "Lily", "grade": 2022}创建kafka表
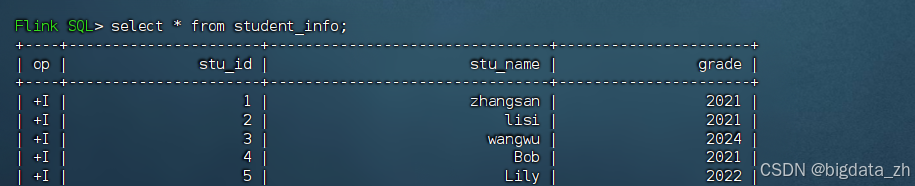
create table student_info (
`stu_id` bigint,
`stu_name` string,
`grade` bigint
) with (
'connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = 'node1:9092',
'properties.group.id' = 'testgroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
); 案例实现
-- 实时遍历
select * from student_info;