这是一个基于用户点击信息进行会话时长分析的案例,常见于互联网 App 使用分析。
问题描述
用户的访问记录存储在 user_access 表中,包含用户编号(user_id)以及访问时间(access_time)等信息。以下是一个示例数据:
sql
-- 创建示例表
CREATE TABLE user_access(user_id bigint, access_time timestamp);
-- 生成示例数据
INSERT INTO user_access VALUES
(1, '2025-04-30 07:00:00'),
(2, '2025-04-30 07:05:00'),
(2, '2025-04-30 07:10:00'),
(1, '2025-04-30 07:15:00'),
(1, '2025-04-30 07:20:00'),
(1, '2025-04-30 08:00:00'),
(3, '2025-04-30 08:00:00'),
(1, '2025-04-30 08:10:00');对于同一个用户,如果前后两次操作时间间隔超过 30 分钟,则认为它们属于不同的会话。要求分析每个用户每次会话的开始时间和结束时间,输出结果如下:
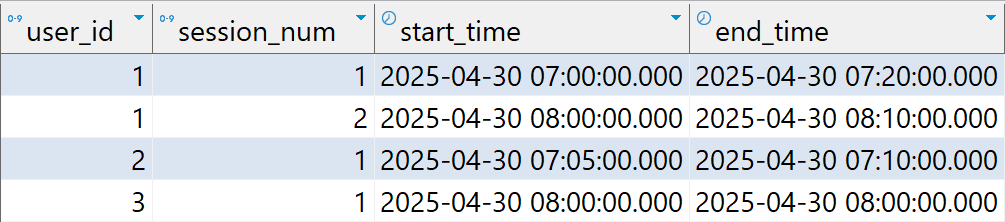
以用户 1 为例,他有两次会话,第一次会话从 7 点开始到 7 点 20 分结束(持续 20 分钟),第二次会话从 8 点开始到 8 点 10 分结束(持续 10 分钟)。
问题解析
基于上面的描述,我们首先需要分析用户每次点击的时间和上一次时间是否间隔超过 30 分钟,超过了表示新会话开始,否则仍然属于上一次会话。为此,我们需要使用一个窗口函数 lag,它可以返回上一条数据的信息:
sql
SELECT user_id, access_time,
lag(access_time) OVER (PARTITION BY user_id ORDER BY access_time) AS pre_access_time, -- 上次点击时间
CASE
WHEN access_time - INTERVAL '30' MINUTE <= lag(access_time) OVER (PARTITION BY user_id ORDER BY access_time) THEN 0
ELSE 1
END AS new_session -- 基于每次点击和上次点击时间间隔判断是否新的会话
FROM user_access;
user_id|access_time |pre_access_time |new_session|
-------+-----------------------+-----------------------+-----------+
1|2025-04-30 07:00:00.000| | 1|
1|2025-04-30 07:15:00.000|2025-04-30 07:00:00.000| 0|
1|2025-04-30 07:20:00.000|2025-04-30 07:15:00.000| 0|
1|2025-04-30 08:00:00.000|2025-04-30 07:20:00.000| 1|
1|2025-04-30 08:10:00.000|2025-04-30 08:00:00.000| 0|
2|2025-04-30 07:05:00.000| | 1|
2|2025-04-30 07:10:00.000|2025-04-30 07:05:00.000| 0|
3|2025-04-30 08:00:00.000| | 1|其中,lag 函数分析了每个用户(PARTITION BY user_id)每次点击对应的上一次点击时间(ORDER BY access_time);CASE 表达式基于时间间隔判断是否新的会话开始。
考虑到一个用户可能存在多次会话,我们需要把它们进行编号。基于上面的查询结果,每次新会话开始对应的 new_session 字段都等于 1,其他都等于 0,可以基于这个字段求和生成会话编号:
sql
WITH user_access_session_flag AS (
SELECT user_id, access_time,
CASE
WHEN access_time - INTERVAL '30' MINUTE <= lag(access_time) OVER (PARTITION BY user_id ORDER BY access_time) THEN 0
ELSE 1
END AS new_session -- 基于每次点击和上次点击时间间隔判断是否新的会话
FROM user_access
)
SELECT user_id, access_time,
sum(new_session) OVER (PARTITION BY user_id ORDER BY access_time) AS session_num -- 基于new_session标识生成每次会话的编号
FROM user_access_session_flag;
user_id|access_time |session_num|
-------+-----------------------+-----------+
1|2025-04-30 07:00:00.000| 1|
1|2025-04-30 07:15:00.000| 1|
1|2025-04-30 07:20:00.000| 1|
1|2025-04-30 08:00:00.000| 2|
1|2025-04-30 08:10:00.000| 2|
2|2025-04-30 07:05:00.000| 1|
2|2025-04-30 07:10:00.000| 1|
3|2025-04-30 08:00:00.000| 1|其中,WITH 用于定义通用表表达式,我们可以简单把它理解为一个临时表(user_access_session_flag)。在这里主要是将查询语句模块化,便于我们阅读,否则要使用子查询。
此时,我们已经可以比较清晰地看到每个用户的每次会话信息了。为了生成最终的效果,得到每次会话的开始时间和结束时间,可以基于用户和会话编号再执行一次分组操作:
sql
WITH user_access_session_flag AS (
SELECT user_id, access_time,
CASE
WHEN access_time - INTERVAL '30' MINUTE <= lag(access_time) OVER (PARTITION BY user_id ORDER BY access_time) THEN 0
ELSE 1
END AS new_session -- 基于每次点击和上次点击时间间隔判断是否新的会话
FROM user_access
),
user_sessions AS (
SELECT user_id, access_time,
sum(new_session) OVER (PARTITION BY user_id ORDER BY access_time) AS session_num -- 基于new_session标识生成每次会话的编号
FROM user_access_session_flag
)
SELECT user_id, session_num, min(access_time) AS start_time, max(access_time) AS end_time
FROM user_sessions
GROUP BY user_id, session_num
ORDER BY user_id, session_num; -- 分组获取每个用户每次会话的会话开始时间和结束时间
user_id|session_num|start_time |end_time |
-------+-----------+-----------------------+-----------------------+
1| 1|2025-04-30 07:00:00.000|2025-04-30 07:20:00.000|
1| 2|2025-04-30 08:00:00.000|2025-04-30 08:10:00.000|
2| 1|2025-04-30 07:05:00.000|2025-04-30 07:10:00.000|
3| 1|2025-04-30 08:00:00.000|2025-04-30 08:00:00.000|在以上查询中,我们基于原始数据定义了临时表 user_access_session_flag,然后又基于它定义了临时表 user_sessions,接着基于这个临时表进行分组分析,得到最终结果。
通过这个案例也可以看出,通用表表达式(WITH)编写的代码非常符号我们的阅读理解习惯,推荐大家使用。