引言
在大型语言模型(LLM)的推理过程中,KV 缓存(Key-Value Cache) 是一项至关重要的优化技术。自回归生成(如逐 token 生成文本)的特性决定了模型需要反复利用历史token的注意力计算结果,而 KV 缓存通过存储这些中间值(即键值对 K/V),避免了重复计算,大幅提升了推理效率。然而,随着上下文长度的增加,KV 缓存占用的内存也迅速膨胀(例如 7B 模型处理 10k token 输入时需约 5GB 内存),成为制约长文本生成的瓶颈。
为了解决这一问题,KV 缓存量化技术应运而生。通过将缓存的数值从高精度(如FP16)压缩为低精度(如 INT4或 INT2),在几乎不影响生成质量的前提下,内存需求可降低 2.5 倍以上。本文将深入解析 KV 缓存的工作原理、量化技术的实现细节。
KV caching 详解
-
KV cache 流程展示
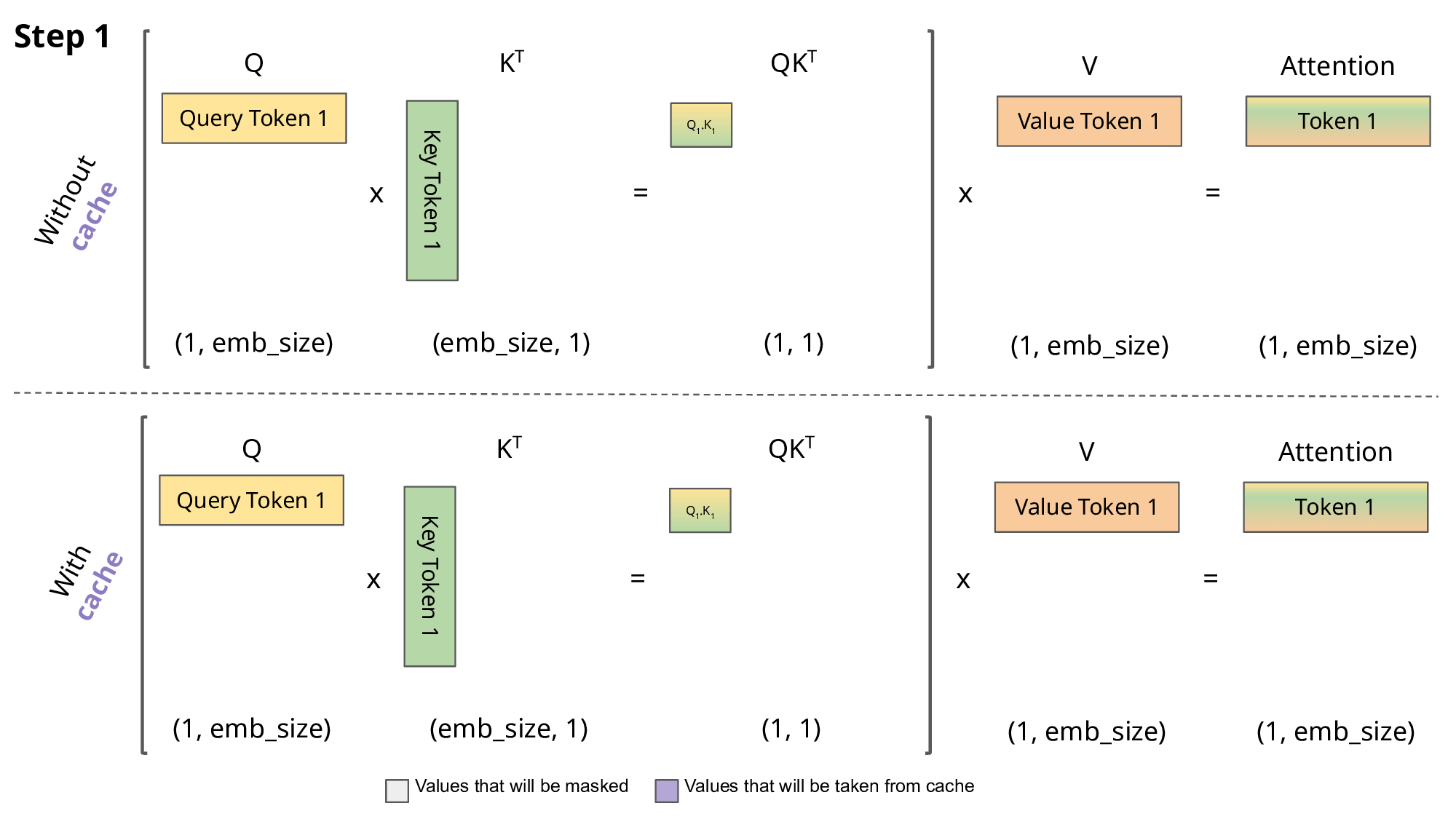
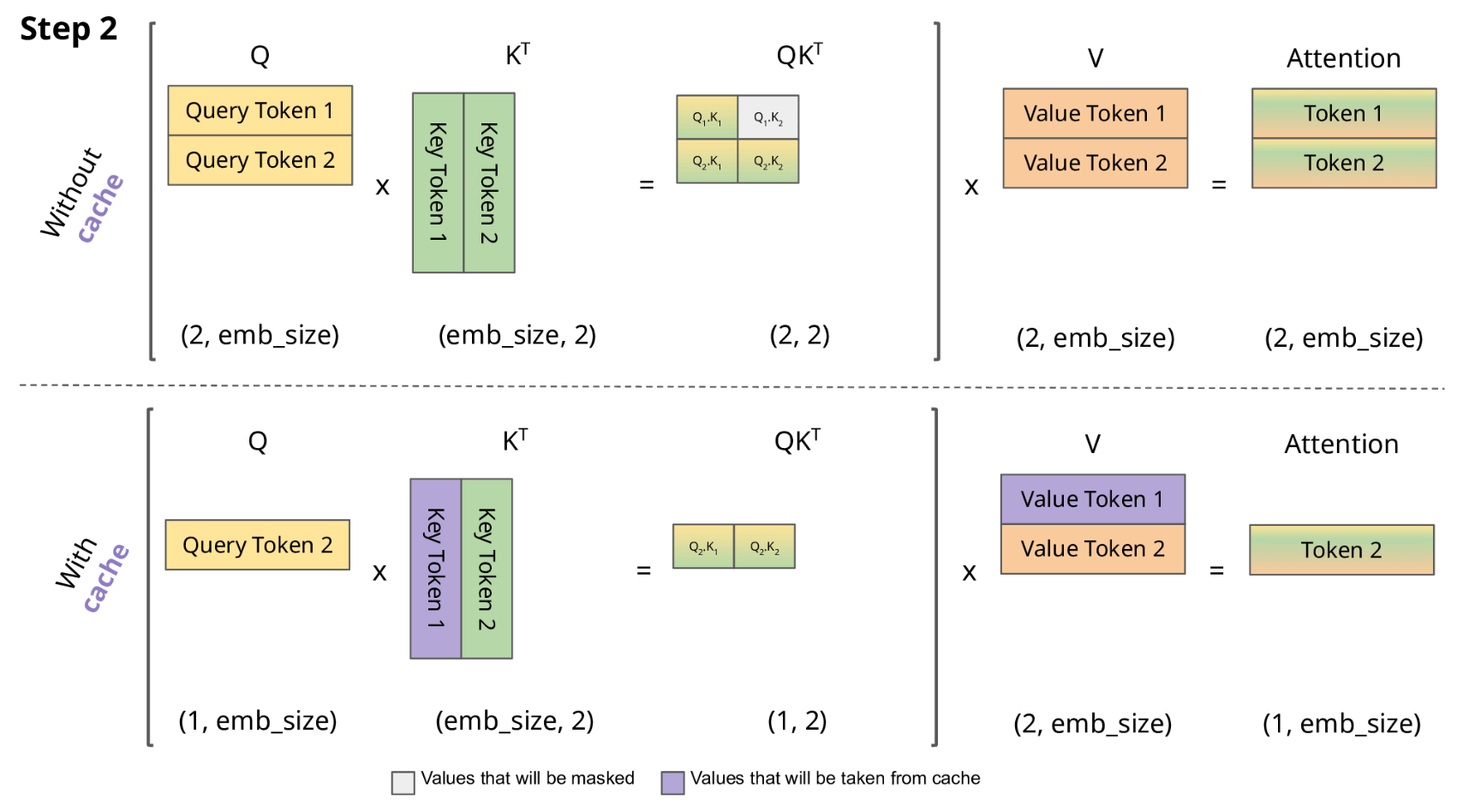
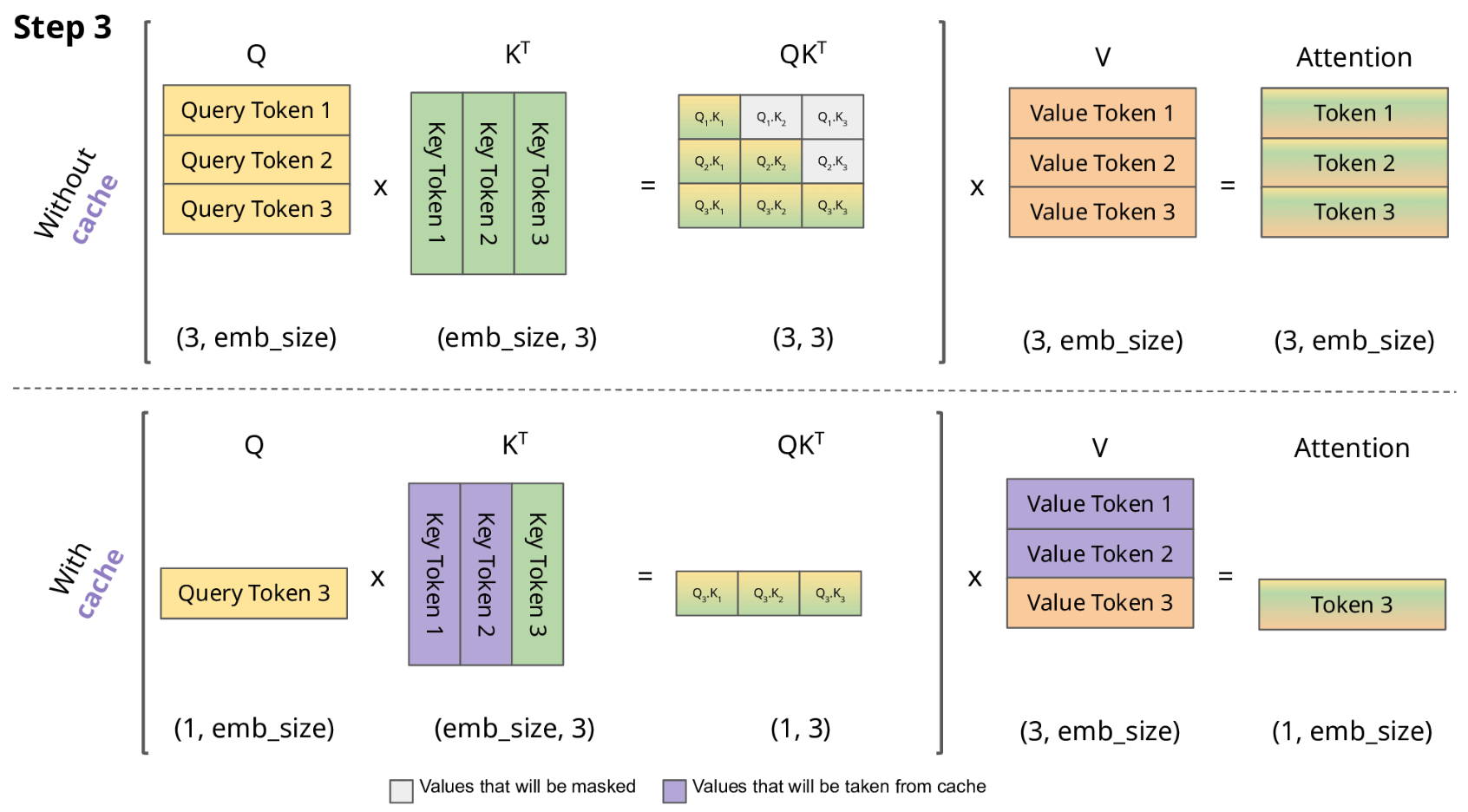
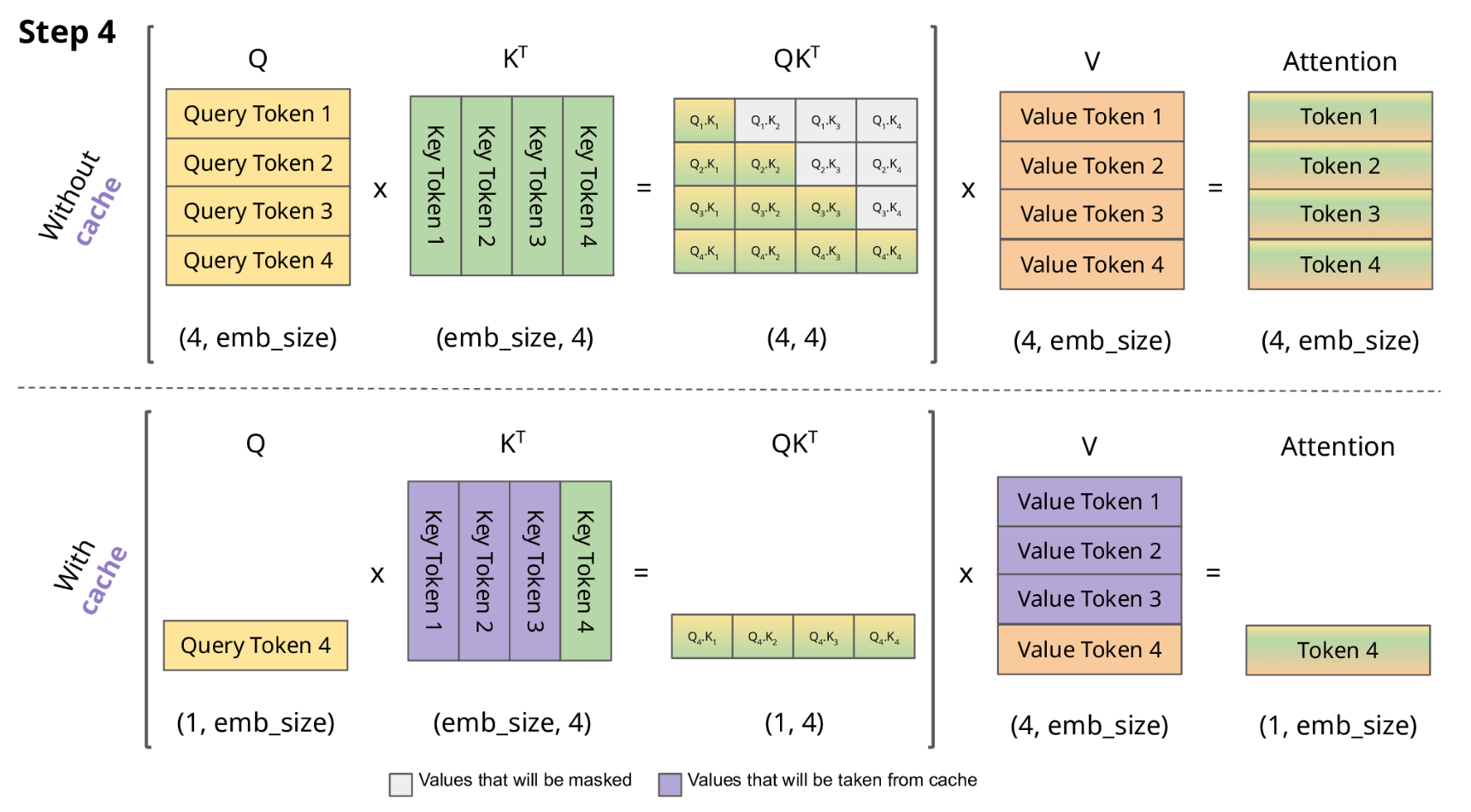
-
LLM 推理的过程是一个自回归的过程,每次生成一个 token 的时候需要结合前面所有的 token 做 attention 操作。也就是说前 i 次的token会作为第 i+1 次的预测数据送入模型,才能得到第 i+1 次的推理 token
-
由于解码器是因果的(即,一个 token 的注意力仅取决于其前面的 token),因此在每个生成步骤中,我们都在重新计算相同的先前 token 的注意力,而实际上我们只是想计算新 token 的注意力。
-
KV Cache 核心节约的时间有三大块:1)前面 n-1 次的 Q 的计算,当然这块对于一次一个 token 的输出本来也没有用;2)同理还有 Attention 计算时对角矩阵变为最后一行,和 1)是同理的,这样 mask 矩阵也就没有什么用了;3)前面 n-1 次的 K 和 V 的计算,也就是上图紫色部分,这部分是实打实被 Cache 过不需要再重新计算的部分。
-
使用 Transformer 🤗 来比较有和没有 KV 缓存的 GPT-2 生成速度
python
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)
for use_cache in (True, False):
times = []
for _ in range(10): # measuring 10 generations
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)
times.append(time.time() - start)
print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")在 Google Colab 笔记本上,使用 Tesla T4 GPU,生成 1000 个新 token 的报告平均时间和标准差如下:
使用 KV 缓存:11.885 ± 0.272 秒
没有 KV 缓存:56.197 ± 1.855 秒
KV cache 量化
-
机器学习中常用的数据类型( float32、float16、bfloat16、int8)以及基本的量化原理介绍:link
-
模型量化简介:
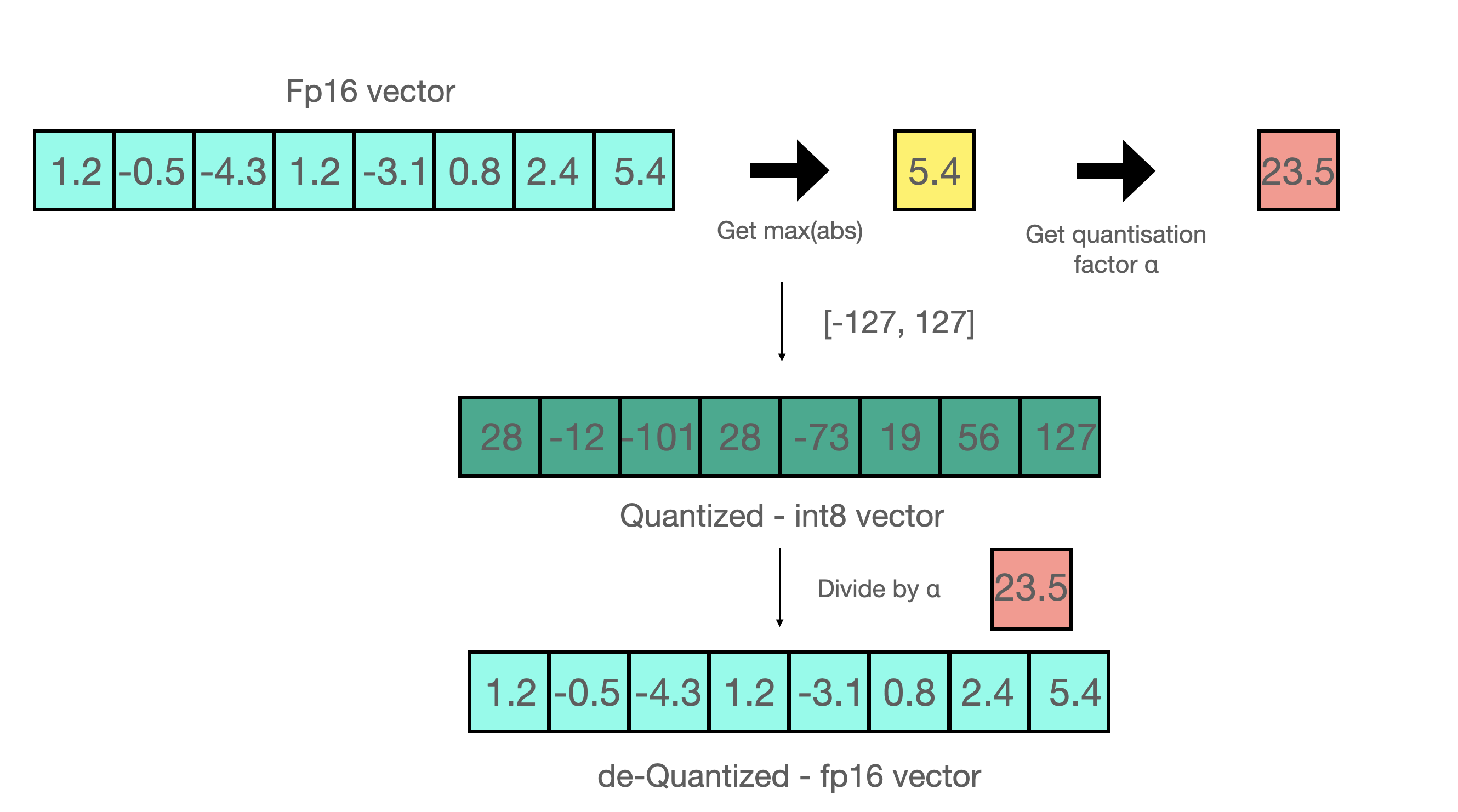
- 假设你要用 absmax 对向量 1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4 进行量化。首先需要计算该向量元素的最大绝对值
- Int8 的范围为 -127, 127,因此我们将 127 除以 5.4,得到缩放因子 23.5。
- 最后,将原始向量乘以缩放因子得到最终的量化向量 28, -12, -101, 28, -73, 19, 56, 127。
- 要恢复原向量,可以将 int8 量化值除以缩放因子,但由于上面的过程是"四舍五入"的,我们将丢失一些精度。
-
为什么需要 kv cache 量化?
- 估算一下,当用 7B Llama-2 模型处理 10000 个词元的输入时,我们需要多少内存来存储 KV 缓存。存储一个词元的 KV 缓存所需的内存大致为
2 * 2 * 层数 * 键值抽头数 * 每抽头的维度,其中第一个 2 表示键和值,第二个 2 是我们需要的字节数 (假设模型加载精度为 float16 )。因此,如果上下文长度为 10000 词元,仅键值缓存所需的内存我们就要:
2 * 2 * 32 * 32 * 128 * 10000 ≈ 5GB
该内存需求几乎是半精度模型参数所需内存的三分之一。 - 因此,通过将 KV 缓存压缩为更紧凑的形式,我们可以节省大量内存并在消费级 GPU 上运行更长上下文的文本生成
- 估算一下,当用 7B Llama-2 模型处理 10000 个词元的输入时,我们需要多少内存来存储 KV 缓存。存储一个词元的 KV 缓存所需的内存大致为
-
KV cache 量化方式
- 给定形状为 batch size, num of head, num of tokens, head dim 的键或值,我们将其分组为 num of groups, group size 并按组进行仿射量化,如下所示:
X_Q = round(X / S) - Z
这里:
X_Q是量化后张量
S是比例,计算公式为(maxX - minX) / (max_val_for_precision - min_val_for_precision)
Z是零点,计算公式为round(-minX / S)
- 给定形状为 batch size, num of head, num of tokens, head dim 的键或值,我们将其分组为 num of groups, group size 并按组进行仿射量化,如下所示:
-
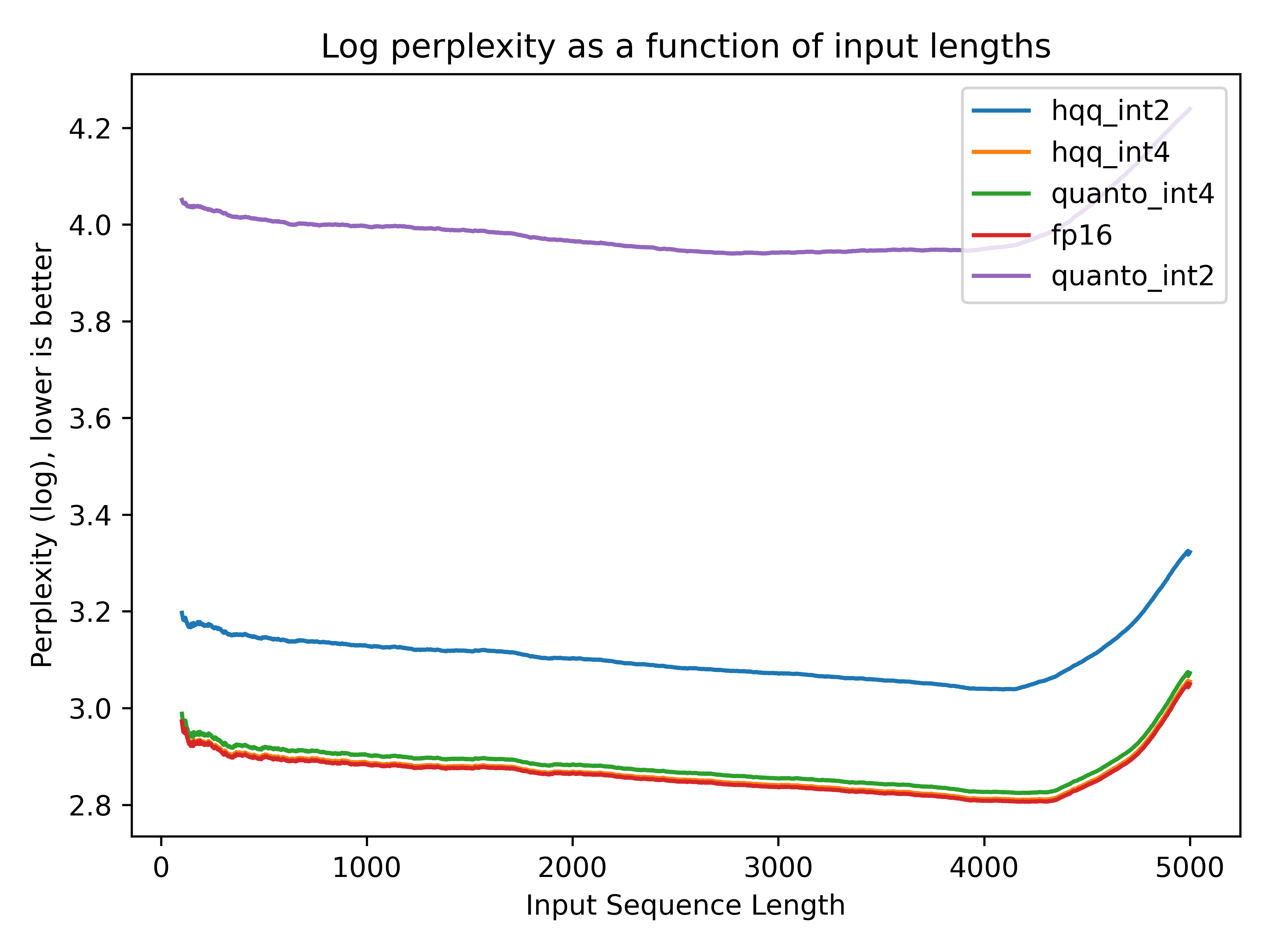
实验效果:两个后端的 int4 缓存的生成质量与原始 fp16 几乎相同,而使用 int2 时出现了质量下降
-
transformers 中使用量化 kv cache 的方式
python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, device_map="cuda:0")
inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="quantized", cache_config={"backend": "quanto", "nbits": 4})
print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
# I like rock music because it's loud and energetic. It's a great way to express myself and rel
out = model.generate(**inputs, do_sample=False, max_new_tokens=20)
print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
# I like rock music because it's loud and energetic. I like to listen to it when I'm feeling