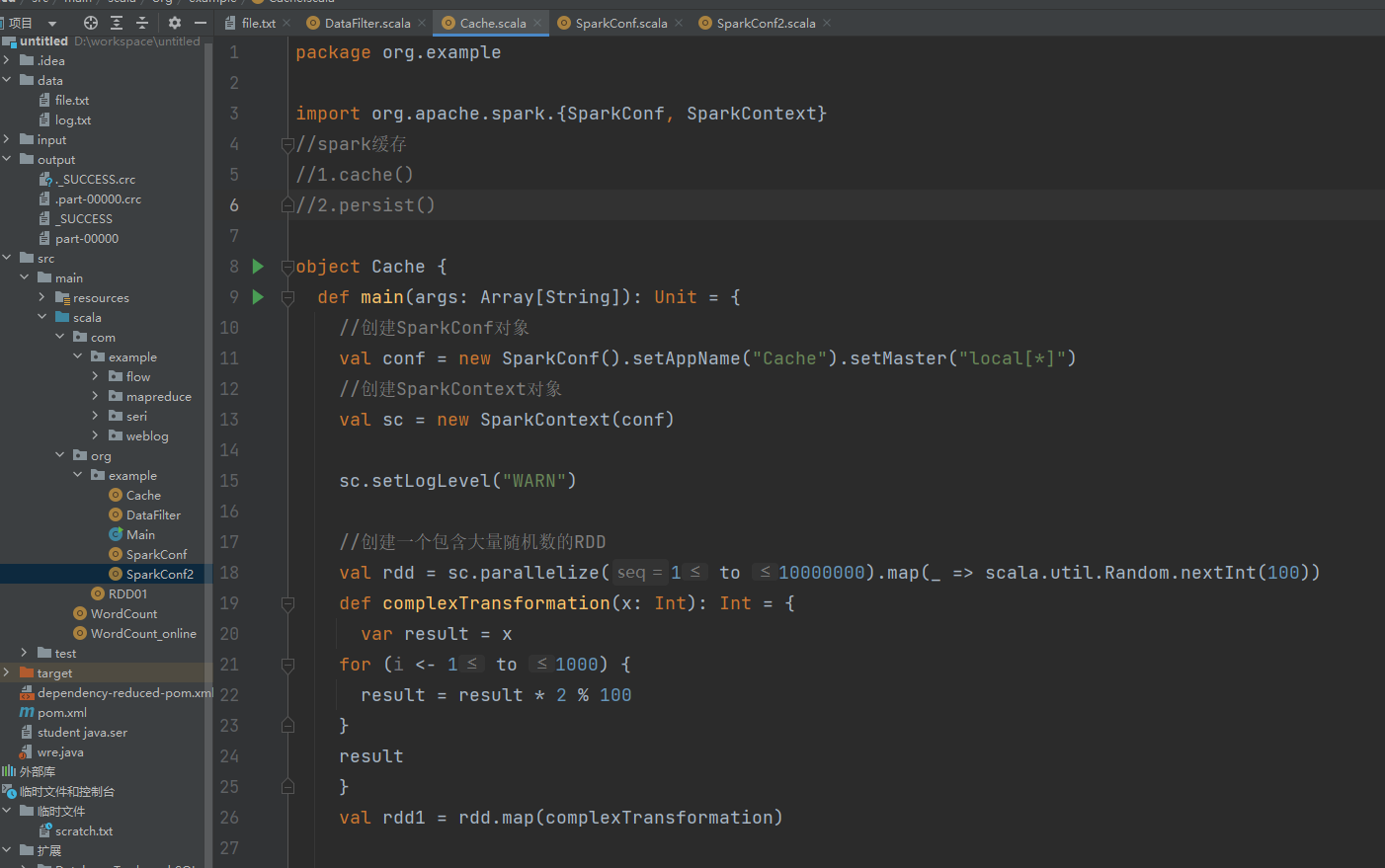
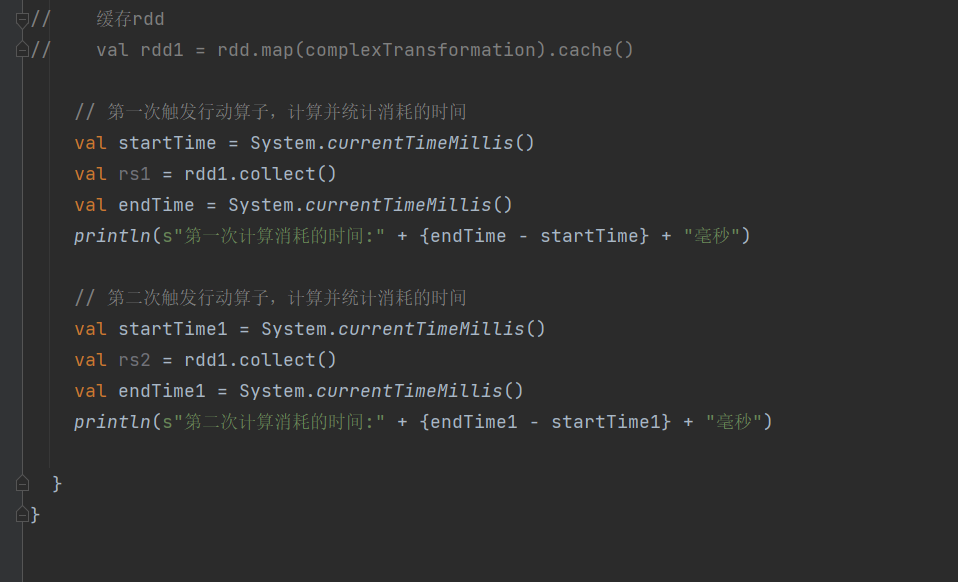
一、RDD持久化
1.什么时候该使用持久化(缓存)
-
RDD cache & persist 缓存
-
RDD CheckPoint 检查点
-
cache & persist & checkpoint 的特点和区别
特点
区别
二、cache & persist 的持久化级别及策略选择
Spark的几种持久化级别:
1.MEMORY_ONLY
2.MEMORY_AND_DISK
3.MEMORY_ONLY_SER
4.MEMORY_AND_DISK_SER
5.DISK_ONLY
6.MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等