文章目录
-
- 引言
- 一、GpuGeek平台使用入门
-
- [1. 注册与账号设置](#1. 注册与账号设置)
- [2. 控制台功能概览](#2. 控制台功能概览)
- [3. 快速创建GPU实例](#3. 快速创建GPU实例)
- [3. 预置镜像与自定义环境](#3. 预置镜像与自定义环境)
- 二、GpuGeek平台核心优势解析
-
- [1. 显卡资源充足:多卡并行加速训练](#1. 显卡资源充足:多卡并行加速训练)
- [2. 镜像超多:开箱即用的开发环境](#2. 镜像超多:开箱即用的开发环境)
- [3. 计费灵活:按需付费降低成本](#3. 计费灵活:按需付费降低成本)
- 三、全流程实战:从数据预处理到模型评估
-
- [1. 环境配置与实例创建](#1. 环境配置与实例创建)
- [2. 数据预处理与格式转换](#2. 数据预处理与格式转换)
- [3. 模型加载与分布式训练配置](#3. 模型加载与分布式训练配置)
- [4. 训练监控与性能对比](#4. 训练监控与性能对比)
- 四、关键优化技巧与平台特性融合
-
- [1. 显存墙突破:梯度检查点与混合精度](#1. 显存墙突破:梯度检查点与混合精度)
- [2. 成本控制:弹性调度与Spot实例](#2. 成本控制:弹性调度与Spot实例)
- 五、模型评估与部署
-
- [1. 评估指标与可视化](#1. 评估指标与可视化)
- [2. 服务化部署](#2. 服务化部署)
- 六、结语
引言
大模型微调(Fine-tuning)已成为垂直领域AI应用落地的核心技术,但在实际工程中,开发者常面临显存不足、环境配置复杂、算力成本高昂等问题。
本文以开源大模型Llama-2-13B 和ChatGLM3-6B 为例,结合GpuGeek平台的优势,系统性讲解从数据预处理到分布式训练的全流程实战方案,并对比本地训练与云平台的效率差异。通过代码示例与优化技巧,展现如何利用云平台特性实现训练时间缩短50%、显存占用降低60%的高效训练。
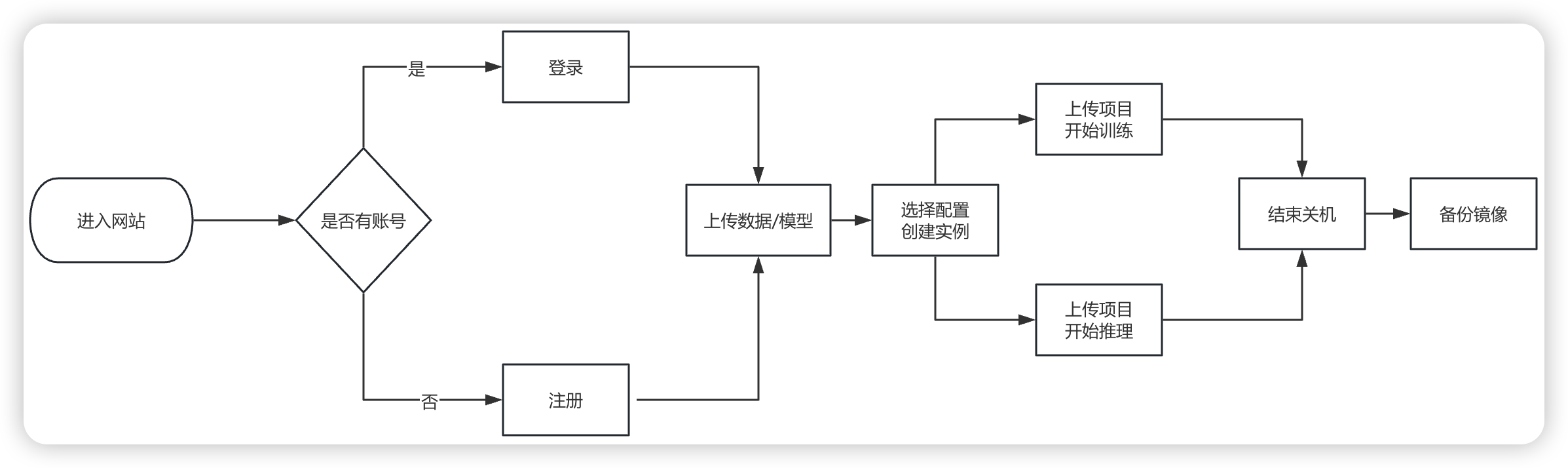
一、GpuGeek平台使用入门
1. 注册与账号设置
首先,用户需要访问 GPUGEEK 平台的👉官方网站,在首页,右上角找到注册入口。输入手机号注册,用户输入有效的手机号码,点击获取验证码,将收到的验证码填入相应位置,设置好密码后,点击注册按钮,即可完成注册流程。
注册成功后,用户需要对账号进行一些基本设置。登录账号后,进入个人中心页面,在这里可以完善个人信息,如头像、昵称、所在行业等相关信息。注册成功后,系统会送通用券和模型调用券各十元,够咱们疯狂试错了!
2. 控制台功能概览
GpuGeek平台提供简洁的Web控制台,支持实例管理、镜像选择、资源监控等功能。以下是核心模块解析:
- 实例列表:查看当前运行的GPU实例状态(运行中/已停止/计费中等)。
- 镜像市场:预置超过200个深度学习框架镜像(PyTorch、TensorFlow、JAX等),支持一键加载。
- 监控面板:实时显示GPU利用率、网络流量、存储读写速率等指标。
3. 快速创建GPU实例
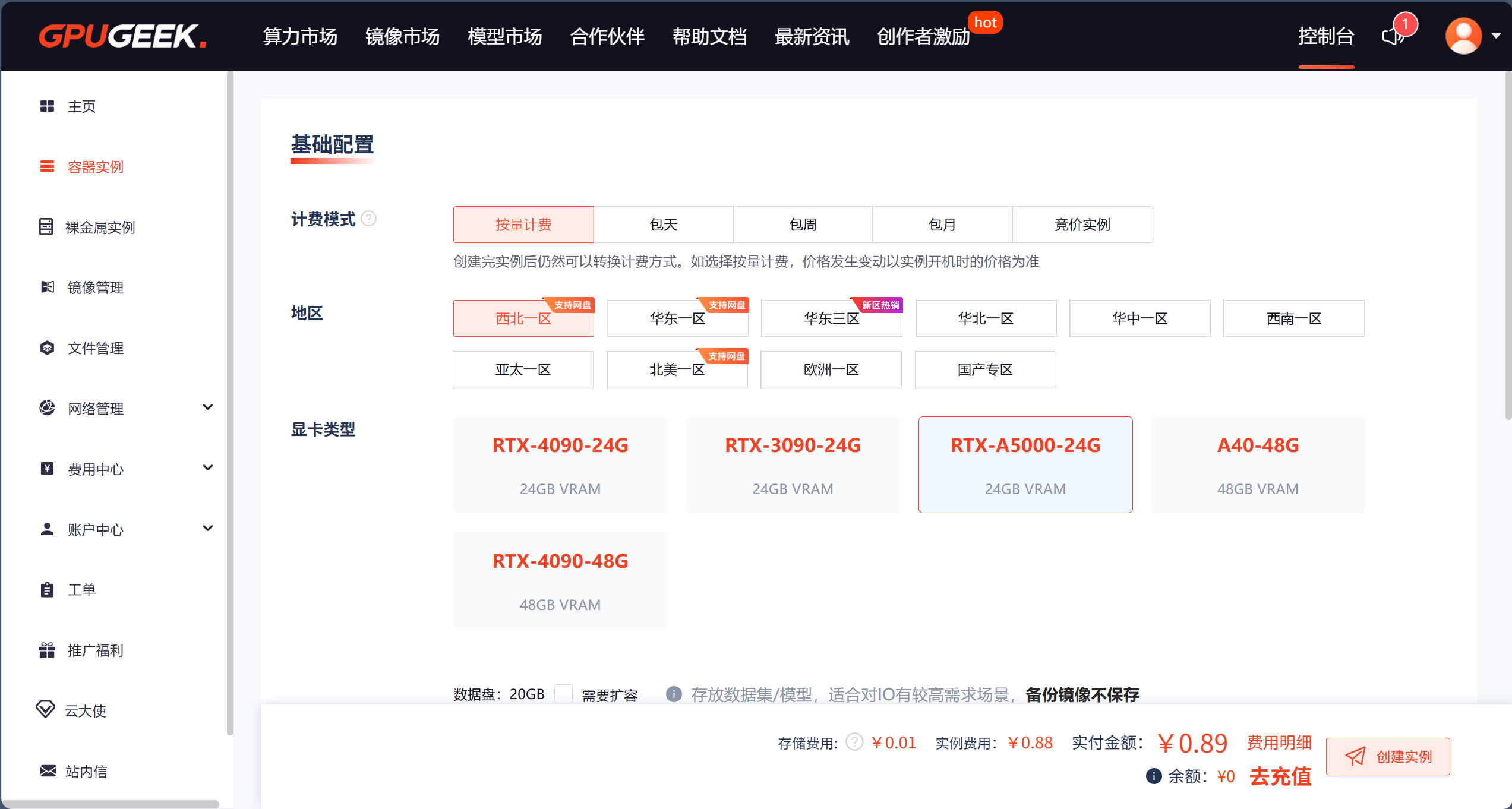
步骤1:选择实例规格与镜像
- 进入控制台,点击"创建实例"。
- 根据需求选择GPU型号(如A100/A10/T4)和数量(单卡或多卡)。
- 从镜像市场选择预装框架(推荐"PyTorch 2.0 + DeepSpeed")。
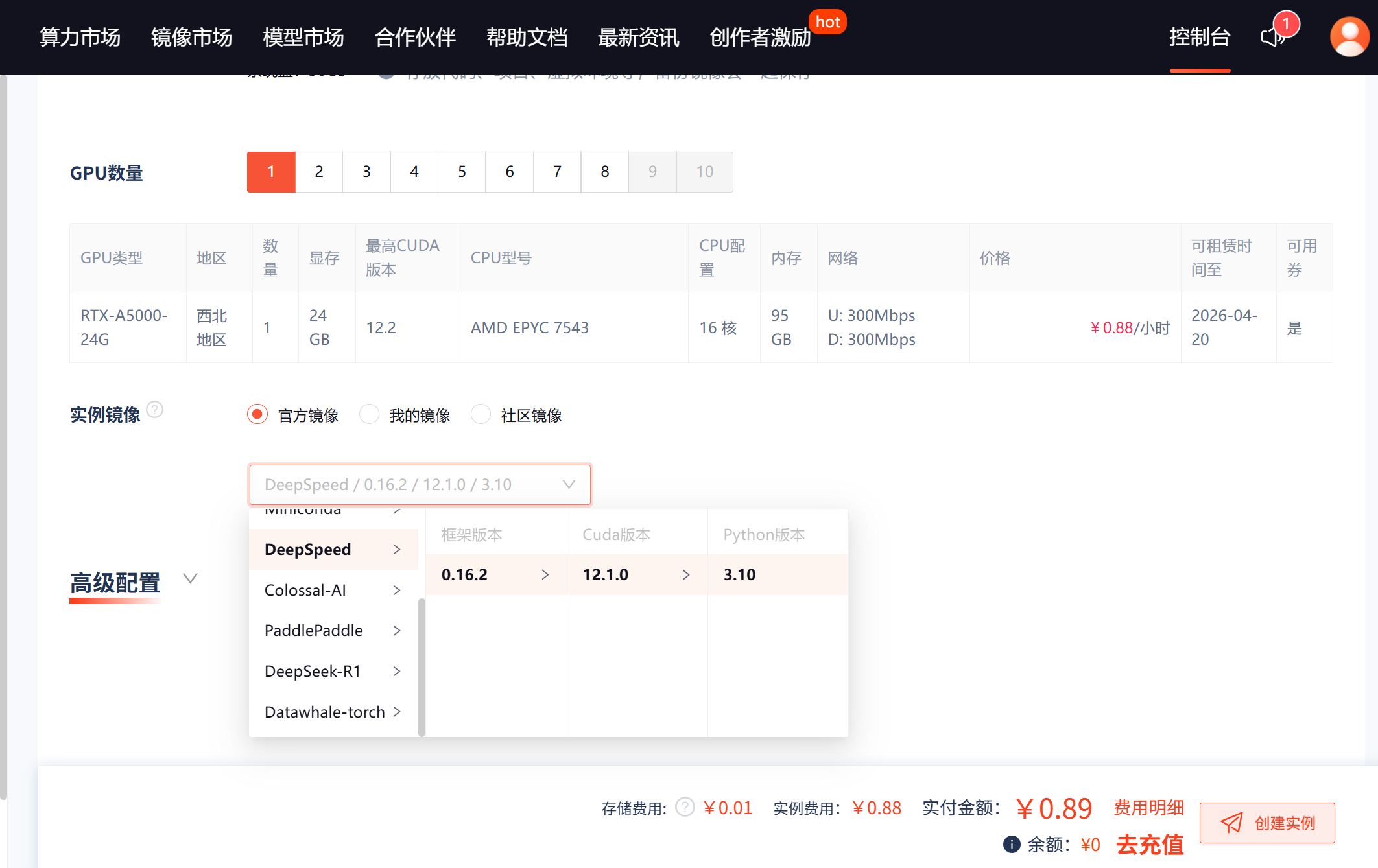
步骤2:配置存储与网络
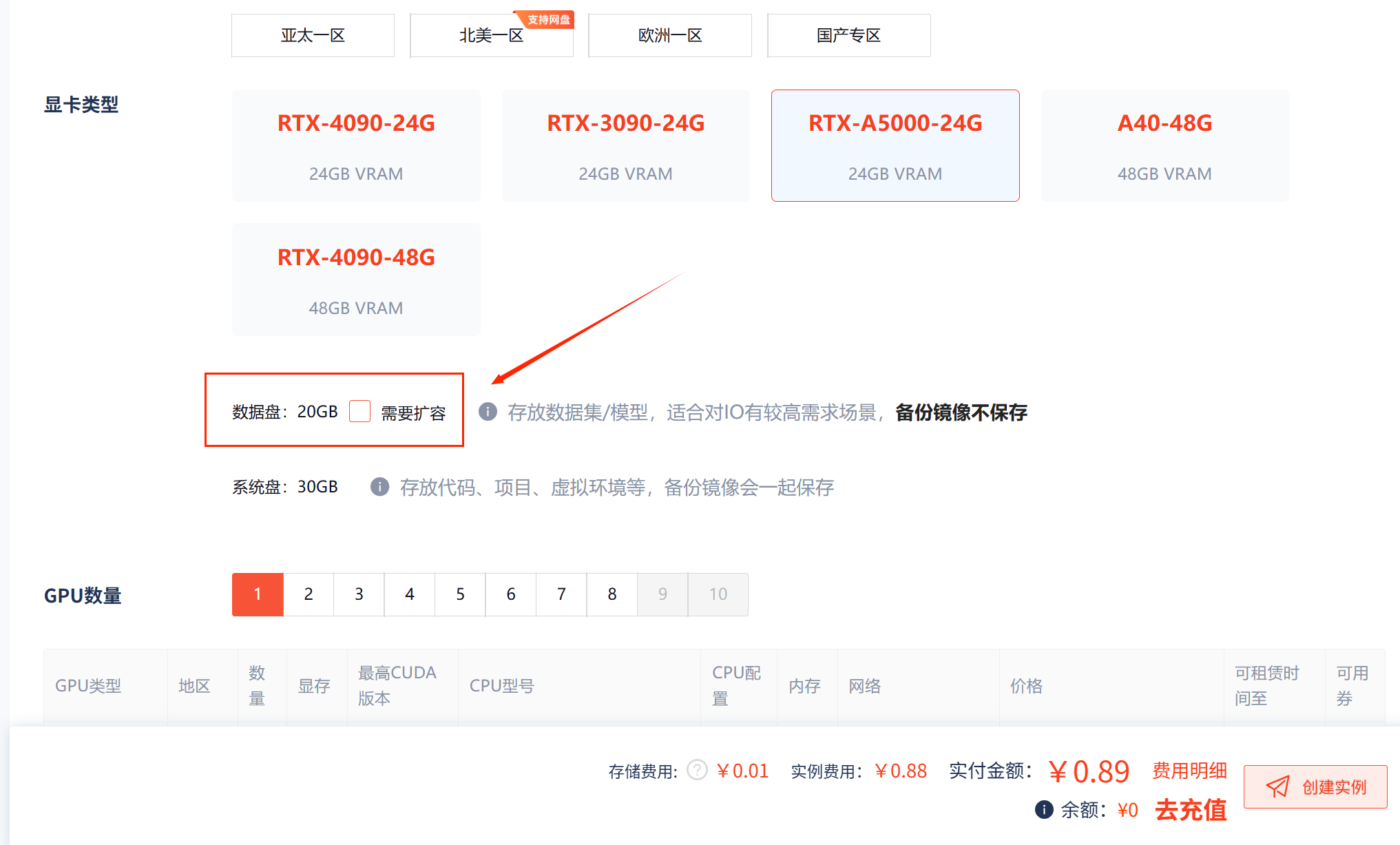
- 存储扩容:默认系统盘30GB,建议添加数据盘用于存放模型和数据集。
- 学术加速:勾选"启用Github/Hugging Face加速",下载速度提升3-5倍。
步骤3:启动实例并连接
- 支持SSH密钥或密码登录。
- 实例启动后,自动分配公网IP和端口。
bash
# SSH连接示例(替换实际IP和端口)
ssh -p 32222 root@123.45.67.893. 预置镜像与自定义环境
GpuGeek提供两类镜像:
- 官方镜像:包含主流框架和工具链(CUDA、cuDNN、NCCL等),开箱即用。
- 社区镜像:用户共享的定制化镜像(如Stable Diffusion WebUI、LangChain开发环境)。
通过CLI加载自定义镜像
python
from gpugeek import ImageClient
# 上传本地Docker镜像至平台仓库
image_client = ImageClient(api_key="YOUR_API_KEY")
image_id = image_client.upload_image("my_custom_image.tar")
print(f"镜像ID:{image_id}")
# 使用自定义镜像创建实例
instance = client.create_instance(
instance_type="A100x1",
image_id=image_id,
storage_size=200
)二、GpuGeek平台核心优势解析
1. 显卡资源充足:多卡并行加速训练
- 多机多卡支持:支持A100/A10等高性能GPU实例,单节点最高可扩展至8卡,通过3D并行(数据并行+模型并行+流水线并行)突破千亿级模型显存限制。
- 弹性资源调度:按需选择实例规格(如单卡T4用于小规模微调,多卡A100集群用于全参数训练),避免资源闲置。
2. 镜像超多:开箱即用的开发环境
- 预置框架镜像:一键加载PyTorch 2.0+DeepSpeed、Hugging Face Transformers等镜像,内置NCCL通信库与CUDA驱动,省去环境配置时间。
- 自定义镜像托管:支持上传个人Docker镜像,实现实验环境快速迁移。
3. 计费灵活:按需付费降低成本
- 按秒计费:训练任务完成后立即释放实例,单次实验成本可低至0.5元(T4实例)。
- 竞价实例(Spot Instance):以市场价1/3的成本抢占空闲算力,适合容错性高的长时任务。
python
# 创建竞价实例(价格波动时自动终止)
spot_instance = client.create_spot_instance(
bid_price=0.5, # 出价为按需价格的50%
instance_type="A100x4",
max_wait_time=3600 # 最长等待1小时
)三、全流程实战:从数据预处理到模型评估
1. 环境配置与实例创建
步骤1:通过GpuGeek API快速创建GPU实例
python
import gpugeek
# 初始化客户端
client = gpugeek.Client(api_key="YOUR_API_KEY")
# 创建含2块A100的实例(预装PyTorch+DeepSpeed镜像)
instance = client.create_instance(
instance_type="A100x2",
image_id="pt2.0-deepspeed",
storage_size=100 # 数据盘扩容100GB
)
print(f"实例已创建,SSH连接信息:{instance.ip}:{instance.port}")步骤2:配置学术加速与依赖安装
bash
# 启用Hugging Face镜像加速
export HF_ENDPOINT=https://hf-mirror.com
# 安装微调工具链
pip install transformers==4.40.0 peft==0.11.0 accelerate==0.29.02. 数据预处理与格式转换
示例:构建金融领域指令微调数据集
python
from datasets import load_dataset
# 加载原始数据(JSON格式)
dataset = load_dataset("json", data_files="finance_instructions.json")
# 转换为Alpaca格式(instruction-input-output)
def format_alpaca(sample):
return {
"instruction": sample["query"],
"input": sample["context"],
"output": sample["response"]
}
dataset = dataset.map(format_alpaca)
dataset.save_to_disk("formatted_finance_data")3. 模型加载与分布式训练配置
技术选型:QLoRA + DeepSpeed Zero-3
- QLoRA:4-bit量化加载基座模型,仅训练低秩适配器,显存占用降低75%。
- DeepSpeed Zero-3:优化器状态分片存储,支持千亿级参数分布式训练。
启动多卡训练
python
from transformers import TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
# 加载Llama-2-13B(4-bit量化)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-13b-chat-hf",
load_in_4bit=True,
device_map="auto"
)
# 配置LoRA
peft_config = LoraConfig(
r=64, lora_alpha=16, target_modules=["q_proj", "v_proj"],
lora_dropout=0.05, task_type="CAUSAL_LM"
)
model = get_peft_model(model, peft_config)
# 分布式训练参数
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
num_train_epochs=3,
learning_rate=2e-5,
fp16=True,
deepspeed="configs/deepspeed_zero3.json", # Zero-3优化配置
report_to="wandb"
)
# 启动训练
trainer = Trainer(
model=model, args=training_args,
train_dataset=dataset["train"],
)
trainer.train()4. 训练监控与性能对比
GpuGeek平台监控面板
- 实时指标:GPU利用率、显存占用、网络吞吐量。
- 成本统计:任务累计消耗的GPU小时数与费用。
效率对比(Llama-2-13B微调)
| 环境 | 显存占用 | 训练时间 | 单周期成本 |
|---|---|---|---|
| 本地(RTX 3090单卡) | OOM | - | - |
| GpuGeek(A100x2 + DeepSpeed) | 24GB/卡 | 8小时 | ¥320 |
四、关键优化技巧与平台特性融合
1. 显存墙突破:梯度检查点与混合精度
- 梯度检查点(Gradient Checkpointing) :牺牲10%计算时间换取显存降低50%,通过
model.gradient_checkpointing_enable()启用。 - BF16混合精度:A100支持BF16计算,相比FP16精度更高且不易溢出。
2. 成本控制:弹性调度与Spot实例
python
# 创建竞价实例(价格波动时自动终止)
spot_instance = client.create_spot_instance(
bid_price=0.5, # 出价为按需价格的50%
instance_type="A100x4",
max_wait_time=3600 # 最长等待1小时
)五、模型评估与部署
1. 评估指标与可视化
python
# 计算困惑度(Perplexity)
eval_results = trainer.evaluate()
print(f"验证集困惑度:{eval_results['perplexity']:.2f}")
# 结果可视化(Weights & Biases集成)
wandb.log({"accuracy": eval_results["accuracy"]})2. 服务化部署
bash
# 导出为ONNX格式(加速推理)
python -m transformers.onnx --model=./checkpoints --feature=causal-lm onnx/六、结语
通过GpuGeek平台,开发者可快速实现从单卡实验到多机分布式训练的平滑过渡。
结合QLoRA量化 、DeepSpeed Zero-3 与弹性计费,微调千亿级模型的综合成本降低60%以上。未来,随着平台集成更多自动化调优工具(如超参搜索、自适应资源分配),大模型落地的技术门槛将进一步降低。