单就公有云来说,现在云数据面临的挑战有以下 5 个:
-
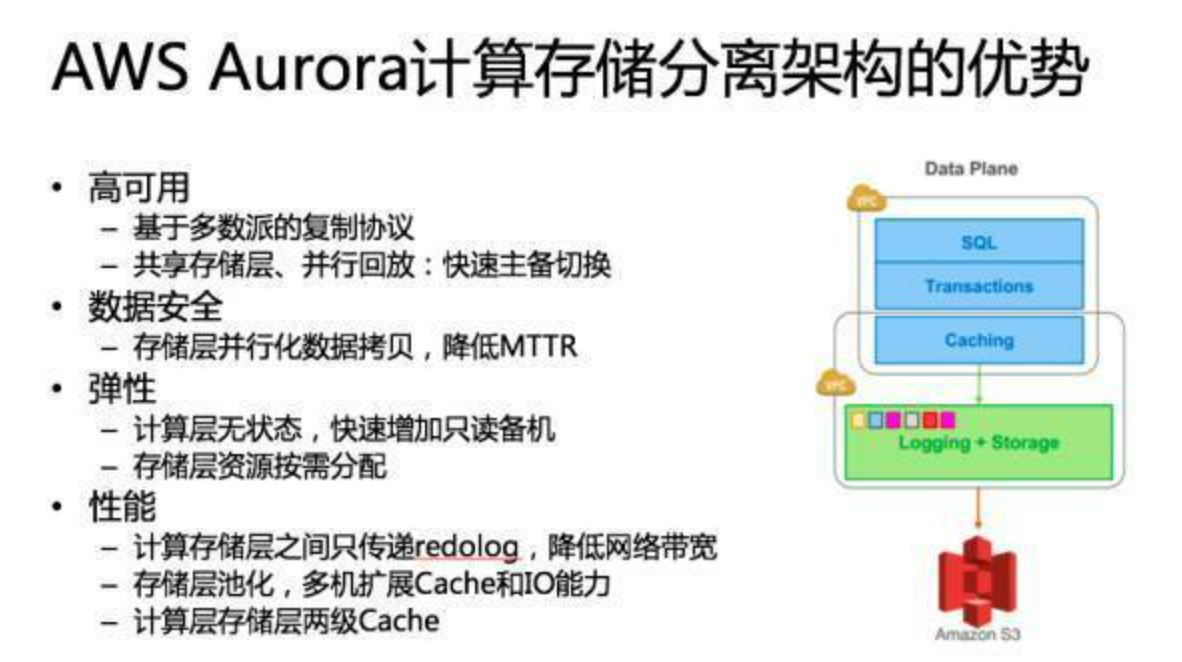
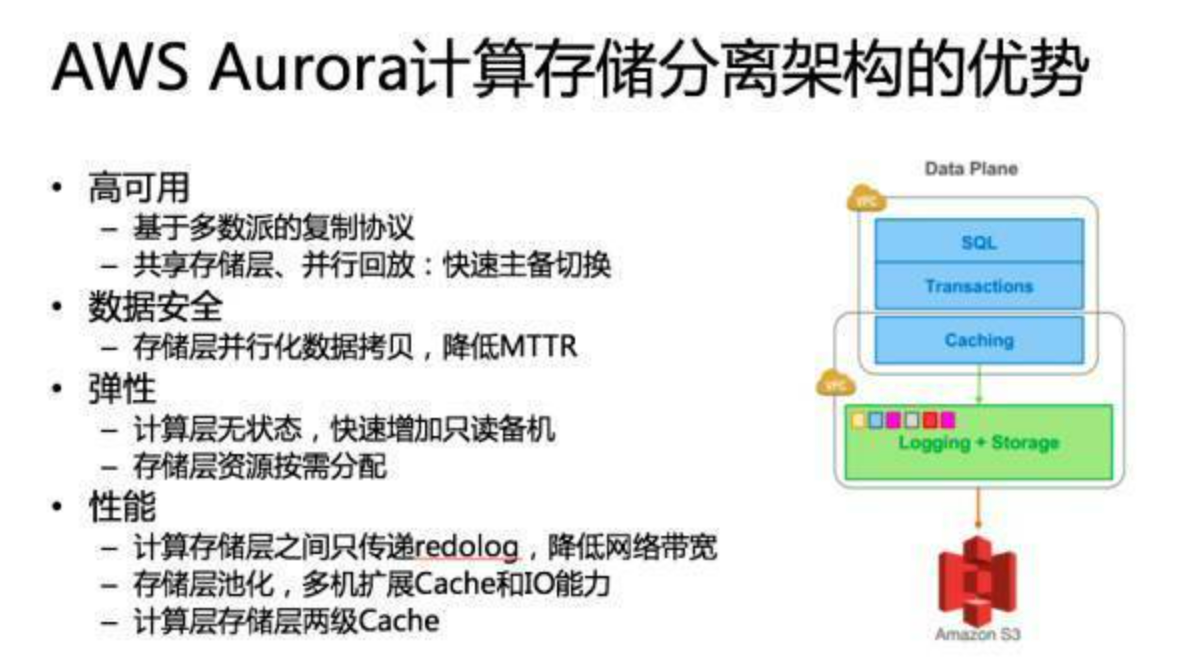
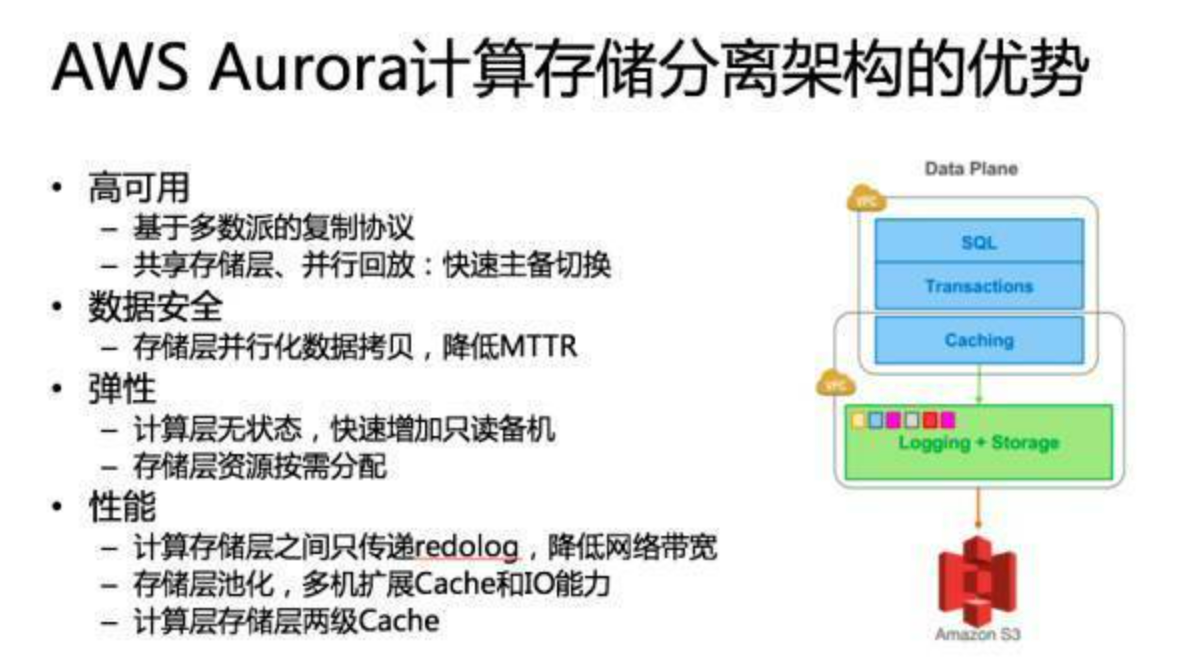
跨 AZ 的可用性与数据安全性。 现在都提多 AZ 部署,亚马逊在全球有 40 多个 AZ, 16 个 Region,基本上每一个 Region 之内的那些关键服务都是跨 3 个 AZ。你要考虑整个 AZ 意外宕机或者计划内维护要怎么处理,数据迁移恢复速度怎么样。以传统的 MySQL 为例,比如说一个机器坏了,可能这个机器上存了几十 T、上百 T 的数据,那么即使在万兆网卡的情况下,也要拷个几分钟或者几十分钟都有可能。那么有没有可能加快这个速度。 还有一个就是服务恢复的速度。可能大家广为诟病就是基于 MySQL Binlog 复制。在主机压力非常大的情况下,是有可能在切换到备机以后,这个备机恢复可能需要几分钟甚至几十分钟。关键因素是回放 Binlog 的效率,MySQL 即使最新版本也只能做到 Group Commit 内的并发回放。这是数据库 RTO 指标,能不能在秒级、分钟级把这个服务恢复起来,这是一个在设计系统的时候要考虑的关键问题。
-
读写分离与弹性扩展。 一般来说我们讲云上数据库基本上都是集中化的,一写多读的,那这里会涉及到读写分离,把主库上一致性要求不高的读流量分给备库,这种情况下读写分离的备库能不能弹性扩展?我们知道 MySQL 可以通过 Binlog 复制来扩展备机,但是扩展的过程中就意味着复制一份完整数据,就像我们刚才提到的数据恢复一样,他要把整个数据全部复制过去然后把 Binlog 接上,这个时间可能你要真做的话几十分钟就过去了。如果说你的业务真撑不住说我赶快要加备机,那这个东西怎么去解决?
-
资源的按需分配。 这点其实云计算上的云数据库一定程度上已经做到了,当然有些可能不一样,比如说有硬件独享的数据库就很难做到按需分配。像阿里可能会把 EBS 接到它的数据库虚拟机上,这样的话其实你接上了弹性化存储以后也基本上做到一个弹性的分配,要 1G 给 1G,再要 1G 再给 1G,不说一开始就把资源分配了,这是云上的一个弹性的东西。
-
高性能。 现在大家都要看跑分,除了跑分,还要看跑实际业务的时候到底行不行,有没有办法去优化。
-
生态兼容性。 比如说为什么 TiDB 一定要做 MySQL 的兼容?我觉得可能也是考虑这一点,现在开源领域最强的生态可能还是 MySQL,开源的数据库如果不做 MySQL 兼容,别人可能不一定会来用。
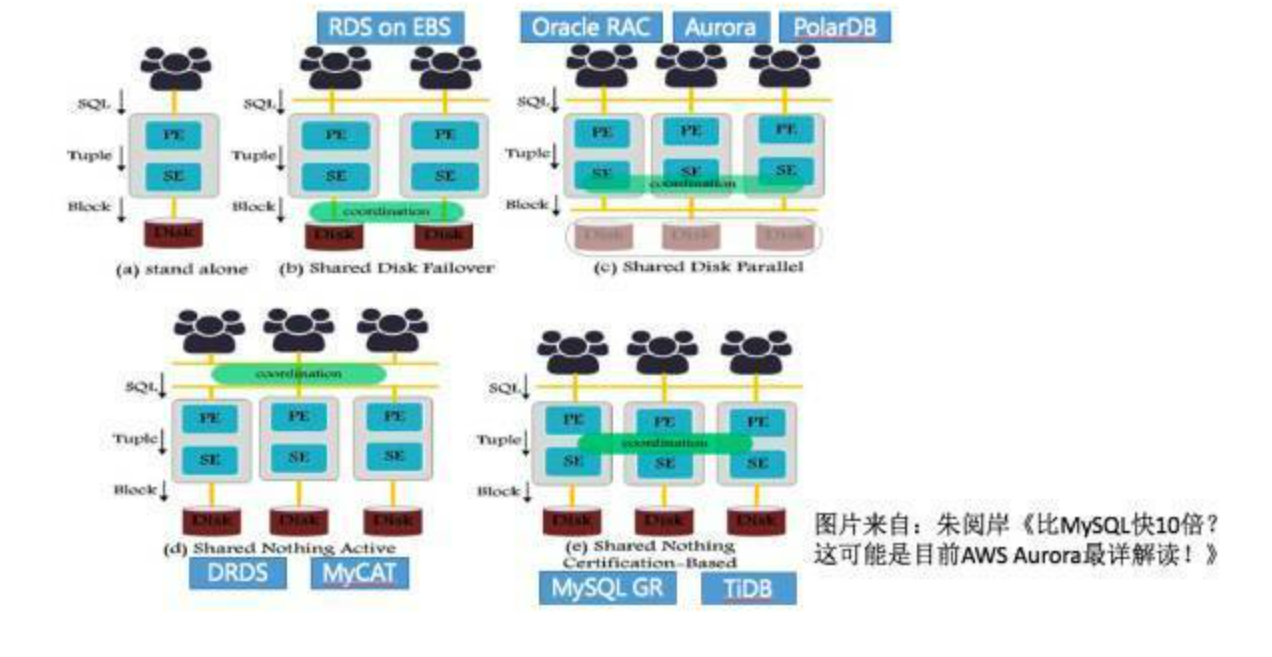
定义数据库服务器集群的架构决策的关键点在于集群共享发生的程度,它定义协调动作发生在什么层以及哪个层( PE 计算层和 SE 存储层 )将被复制或者共享。这不仅确定了系统在可扩展性和灵活性上的权衡,而且关系到每一种架构在现成的数据库服务器上的适用性。
1.单机 2.简单共享存储,多副本一写多读,不需要迁移数据, 备机不能提供服务,灾备恢复EBS 3.统一共享存储, 多个机器之间cahcce一致性,有分布式并行文件系统,可以GFS那样的打散存储,多机器恢复那样的,还是一写多读 4.分库分表,share nothing,分布式中间件SQL比较难做,MVCC啥啊 5.存储分离架构,计算节点快速扩容,SQL引擎层做感知底下share nothing存储
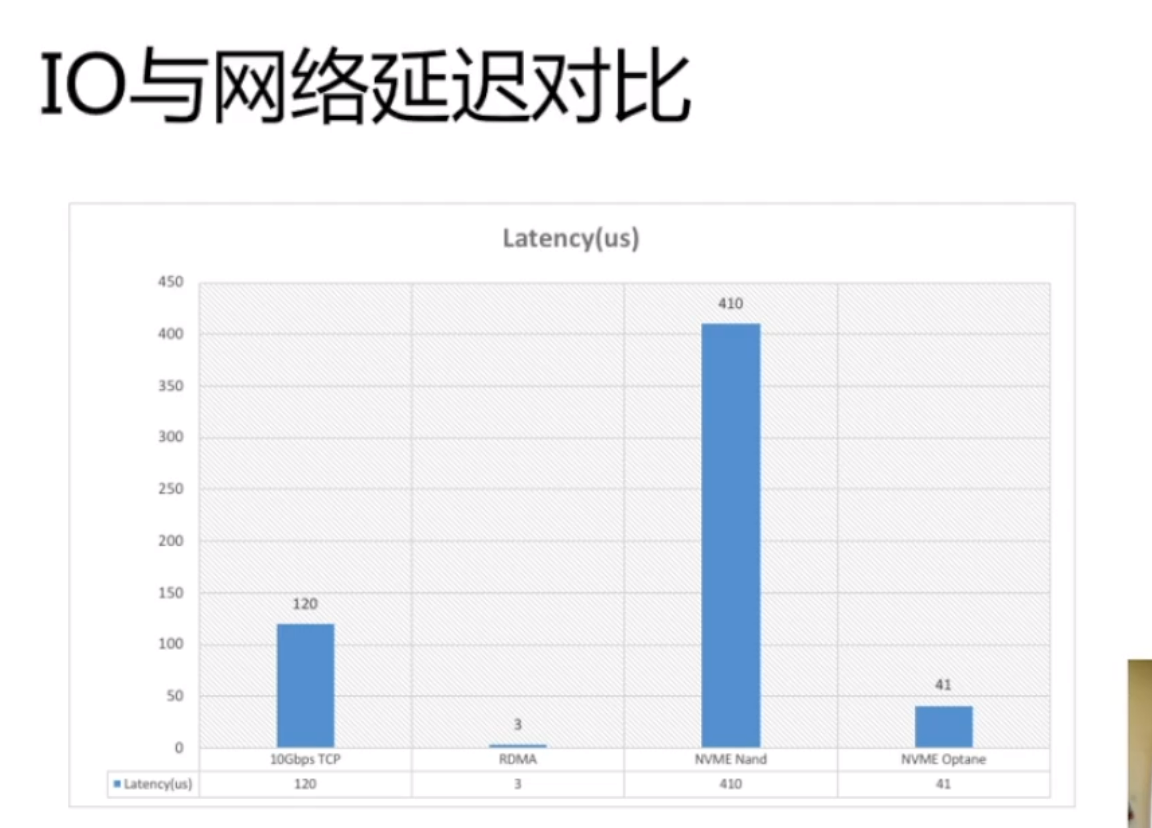
高带宽网络的发展
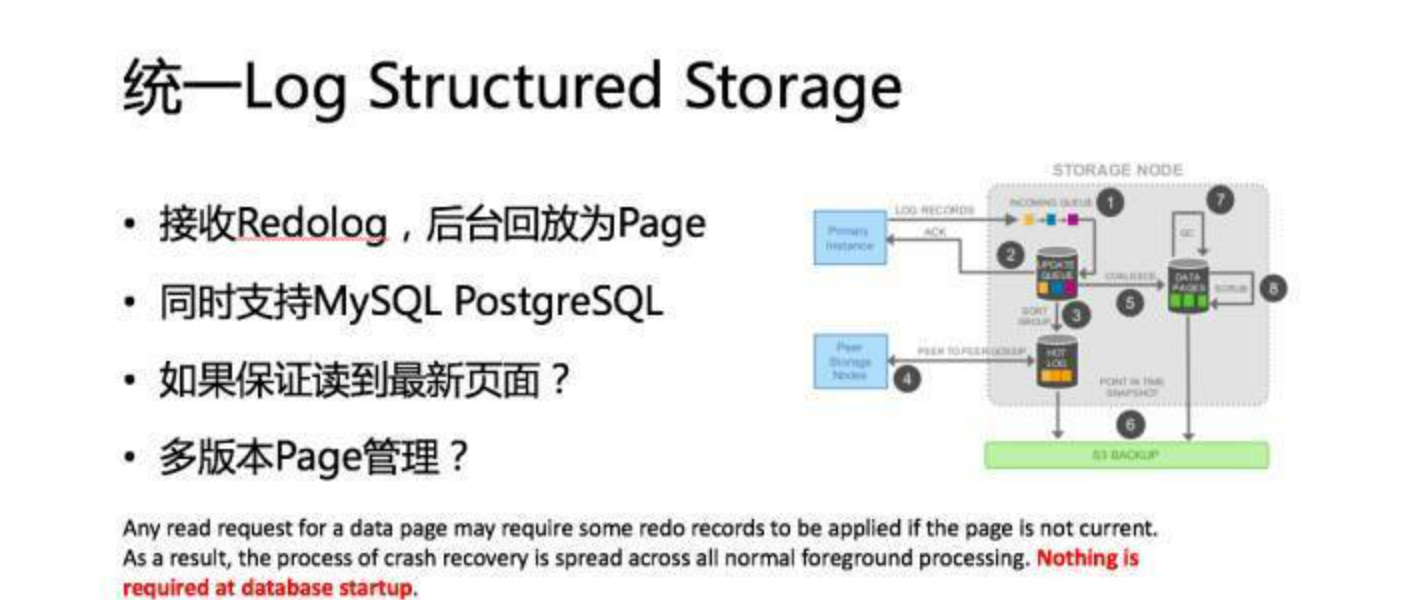


paxos 运行空洞,也容忍网络抖动,不需要依赖前面的顺序日志, ABC AB AC(ACraft要追日志),paxos继续发
Quorum 外部可以选主,简单,存储层可以减少一部分选主开销
NWR写入高可用 1写 N读
备机用多版本MVCC读取事务一致性page版本
TiDB在事务提交生成commitlTS,MySQL ReadView版本是在事务开始时生成Tid,所以需要记录活跃事务
Range在共享存储 cache不重要了,主要还是顺序扫描 主键索引之类的特性,Hash有点预分配的意思,Range分裂比较好点,
Cache协调机制 传递redolog MESI维护,底层是多机大共享打散Cache
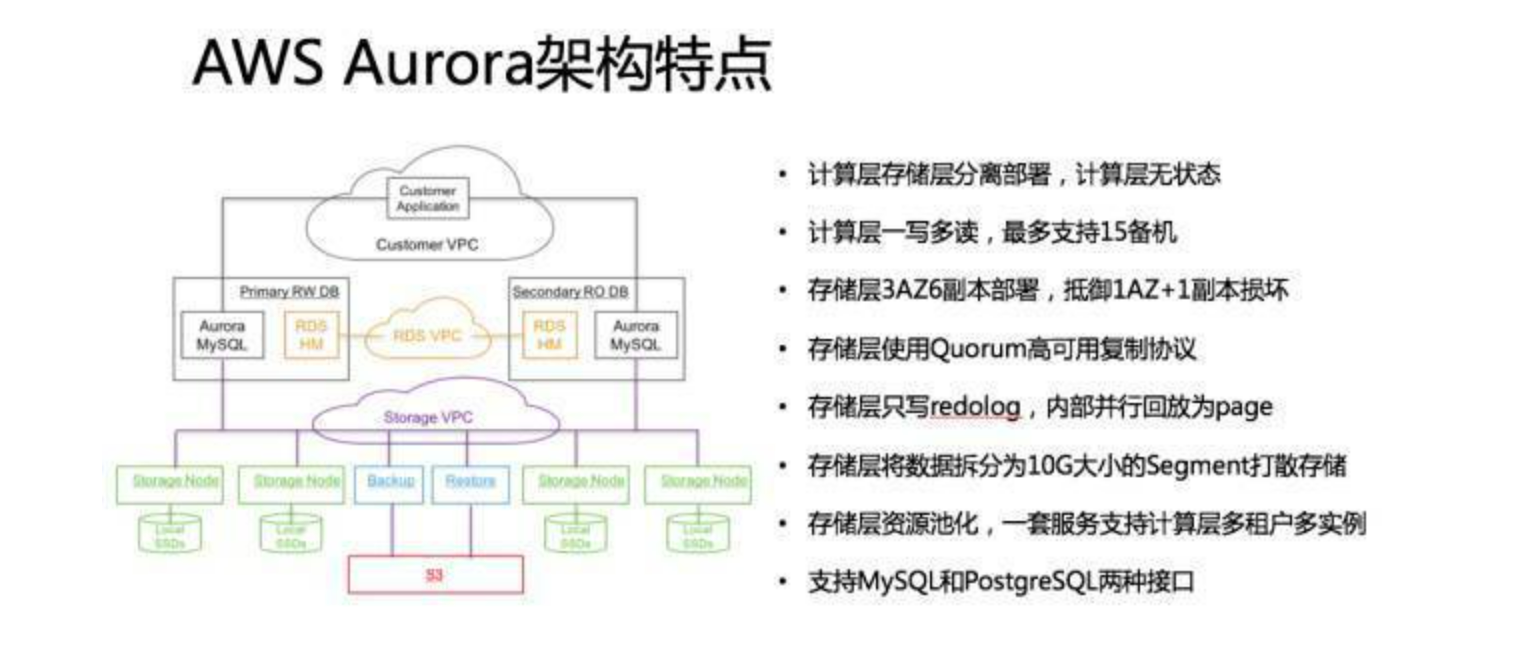
从AWS Aurora架构的设计理念出发,结合计算存储分离范式与分布式系统理论,其核心设计可分解为以下技术要点(引用来源以^编号^格式标注):
一、分布式共识与容错机制
-
Paxos算法的应用
Aurora在存储层采用类Paxos协议实现数据多副本一致性,通过多数派(Quorum)机制 容忍网络抖动与节点宕机24。与Raft协议相比,Paxos允许空洞化的日志提交(即不依赖连续顺序日志),避免因日志追赶导致的性能瓶颈58。例如,当新提案(Proposal)被多数Acceptor接受后,即使中间存在未提交的日志空洞,系统仍可继续处理新请求,仅需异步补全日志。
-
外部选主优化
存储层通过**外部协调服务(如ZooKeeper)**实现轻量级选主逻辑,解耦计算节点与存储节点的选主过程,降低存储层的协调开销6。这种设计允许计算节点聚焦于查询优化,而存储节点专注于数据副本同步。
二、读写可用性与多版本控制
-
NWR模型与读写分离
存储层采用NWR(N-Write-Read)策略,支持1写N读的高可用模式:写入时仅需达成多数派(如W=2)即可返回成功,读取时通过多数派(R=2)获取最新版本46。例如,在3副本集群中,单点写入成功后,其他副本通过异步复制同步数据,避免写入阻塞。
-
MVCC与一致性版本管理
备机通过多版本并发控制(MVCC) 读取事务一致性快照。与TiDB在事务提交时生成
commitTS不同,Aurora采用类似MySQL的活跃事务列表(ReadView)管理机制,但通过存储层维护全局版本号,实现跨节点的版本可见性67。例如,事务启动时获取全局快照版本,读取时仅访问该版本或更早的页面副本。
三、存储引擎与索引优化
-
共享存储下的索引设计
在共享存储架构中,传统Buffer Pool的重要性降低,存储层通过预分配Range分区优化顺序扫描与主键查询6。Range分裂通过写时复制(Copy-on-Write)实现高效元数据变更,而Hash分区因预分配特性可能导致存储碎片,更适合固定负载场景。
-
日志驱动的Cache协调
计算节点通过传递Redo Log而非数据页实现Cache一致性,底层依赖类MESI协议的分布式缓存状态机4。例如,存储层将Redo Log按分片(Shard)打散至多个节点,计算节点通过多数派确认日志持久化后,直接更新本地缓存。
四、对比与扩展
| 特性 | Aurora | 传统主从架构 |
|---|---|---|
| 日志同步 | 多数派异步复制(允许空洞)46 | 全量顺序日志同步(Raft)5 |
| 事务版本管理 | 存储层全局版本号 + MVCC67 | 计算层本地ReadView |
| 缓存一致性 | Redo Log广播 + 分布式状态机4 | 物理页同步 + 锁竞争 |
五、设计启示
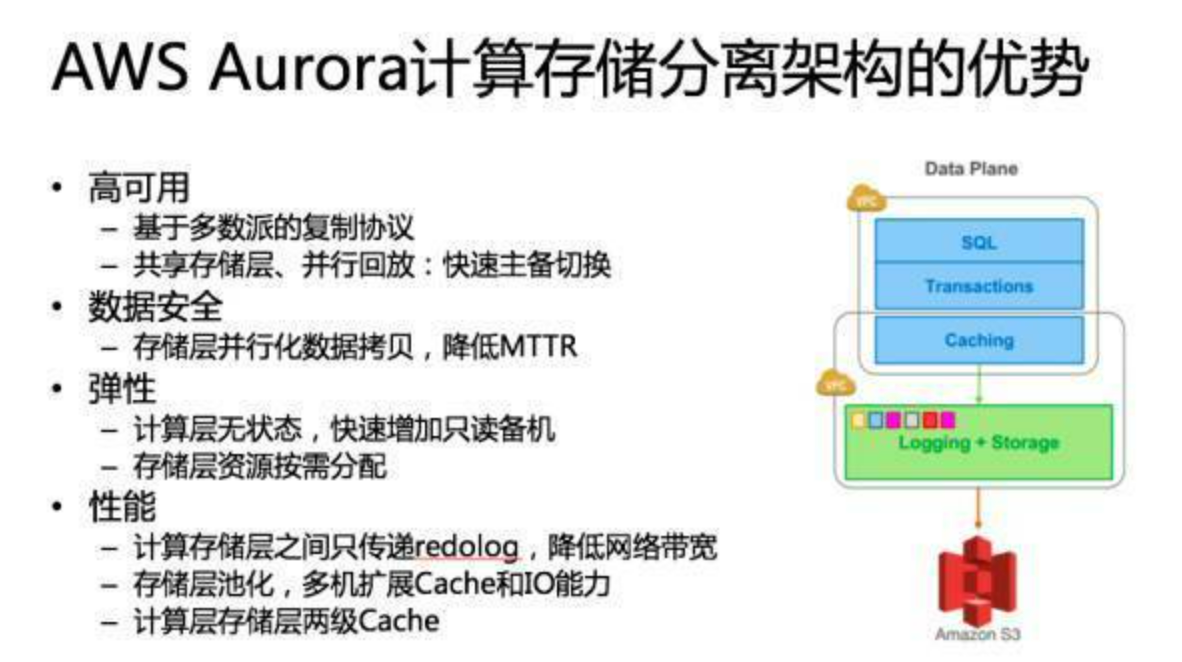
Aurora通过计算与存储职责分离,将分布式共识、多版本控制等复杂性下沉至存储层,使计算层专注于查询优化与事务调度。其核心创新在于:
- 异步多数派写入:牺牲强顺序性换取高吞吐24;
- 日志即数据库:通过Redo Log重构数据页,避免物理页传输7;
- 全局版本时钟:实现跨节点的快照隔离与一致性读68。
这一架构为云原生数据库提供了可扩展、高可用的参考范式,但需权衡跨节点协调延迟与全局锁竞争问题。
Quorum外部选主与Raft/Paxos的对比分析
从分布式一致性协议的设计视角来看,Quorum的轻量化选主机制与Raft、Paxos的核心差异体现在职责边界 与协调开销的权衡上,具体分析如下:
1. Quorum外部选主的特性
-
选主逻辑解耦
Quorum协议的多数派机制仅关注数据副本的读写一致性(如NWR模型),而选主过程可通过外部协调服务(如ZooKeeper或Etcd)独立完成26。例如,存储节点无需维护选举状态机,仅需响应外部服务下发的Leader身份标识,显著降低存储层复杂度。
-
资源开销优化
传统Raft协议中选主与日志复制强耦合,Leader需持续发送心跳维持权威;而Quorum外部选主允许存储层专注于数据同步,仅需在Leader失效时触发外部服务的重新选举,减少网络带宽与CPU占用68。
2. Raft协议的内置选主机制
-
强绑定的Leader角色
Raft要求集群内所有节点参与选主投票,并通过心跳机制维护Leader权威(最小选举超时时间通常为150-300ms)。这一设计虽简化了协议逻辑,但也导致了选主开销与日志复制的耦合性:网络抖动可能频繁触发重新选举,影响写入吞吐58。
-
顺序日志的刚性约束
Raft依赖连续日志索引实现强一致性,选主失败可能导致日志空洞需同步补齐(如新Leader需强制覆盖旧日志),这种设计在存储层需处理日志对齐与状态机恢复的额外开销58。
3. Paxos的选主灵活性
-
Multi-Paxos的实践优化
经典Paxos无明确Leader概念,但Multi-Paxos通过**隐式选主(Leader Proposer)**提升性能:选主过程通过一轮Prepare-Accept交互完成,后续提案由Leader主导,避免多提案竞争带来的活锁问题78。例如,选主成功后Leader可连续提交日志,无需重复协商提案编号。
-
异步多数派的优势
Paxos允许日志空洞提交(异步修复),选主失败时仅需保证新Leader拥有多数派支持的最新日志,无需全局同步历史记录。这种设计更适合跨地域部署场景,存储层可容忍短暂日志不一致48。
对比总结
| 维度 | Quorum + 外部选主 | Raft | Paxos/Multi-Paxos |
|---|---|---|---|
| 选主开销 | 低(独立服务,无状态)26 | 高(心跳维护 + 日志对齐)58 | 中(隐式选举 + 异步修复)78 |
| 日志连续性 | 非强制(允许空洞)4 | 强制(连续索引)5 | 非强制(空洞可异步补齐)78 |
| 适用场景 | 高吞吐写入 + 弱网络容忍68 | 强一致性 + 稳定网络环境5 | 跨地域部署 + 灵活容错48 |
架构选型建议
- 优先Quorum外部选主:若系统需高可用写入且允许短暂不一致(如日志型存储),外部选主可最大化存储层性能26。
- 选择Raft:强一致性事务场景(如金融核心系统)需依赖Raft的顺序日志与内置Leader机制5。
- 倾向Paxos:跨地域多活或大规模集群中,Paxos的异步多数派与灵活选主更适配复杂网络环境