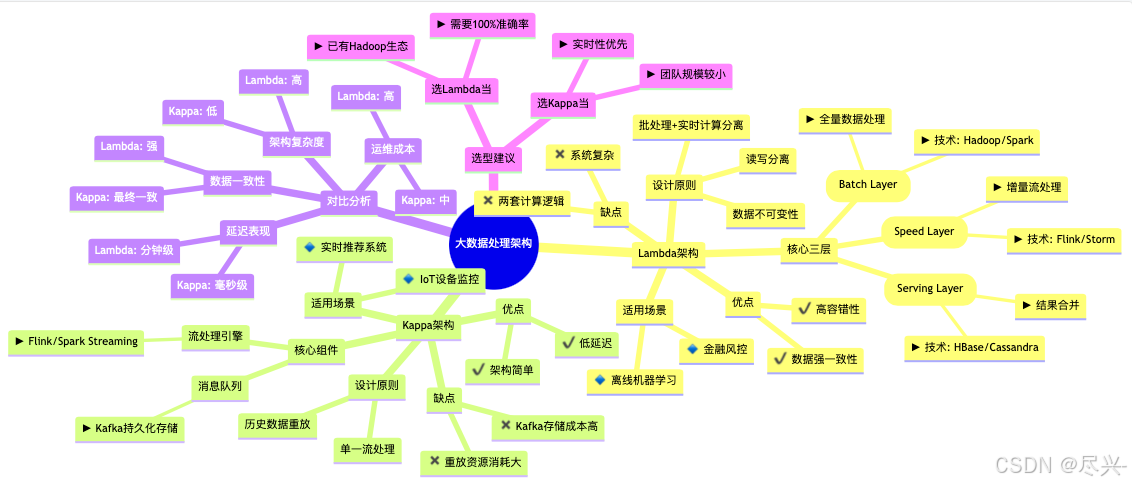
1. Lambda架构
1.1 设计目的
Lambda架构旨在满足大数据系统的关键特性,包括:
- 高容错性(Fault Tolerance)
- 低延迟(Low Latency)
- 可扩展性 (Scalability)
其核心思想是整合离线计算与实时计算,并融合以下原则: - 数据不可变性(Immutable Data)
- 读写分离(Read-Write Separation)
- 复杂性隔离 (Complexity Isolation)
Lambda架构适用于同时处理离线和实时数据 的分布式系统,具备强鲁棒性 ,能提供低延迟查询 和持续数据更新。
1.2 应用场景
- 机器学习(离线训练+实时预测)
- 物联网(IoT)(设备数据实时处理+历史数据分析)
- 流处理(如金融风控、广告点击分析)
1.3 架构分层
Lambda架构可分为三层:批处理层(Batch Layer)、加速层(Speed Layer)、服务层(Serving Layer)。
(1) 批处理层(Batch Layer)
- 功能 :存储主数据集,并预先计算查询函数,生成Batch View(批处理视图)。
- 特点 :
- 处理全量数据,确保高准确性。
- 计算周期较长(如每小时/每天计算一次)。
- 技术实现 :
- 存储:HDFS(Hadoop Distributed File System)
- 计算:MapReduce、Spark
(2) 加速层(Speed Layer)
- 功能 :处理增量数据流 ,生成Real-time View(实时视图)。
- 特点 :
- 低延迟(毫秒级响应)。
- 仅处理最新数据,不保证全局一致性。
- 技术实现 :
- 流计算引擎:Apache Storm、Apache Flink
- 消息队列:Apache Kafka
(3) 服务层(Serving Layer)
- 功能 :合并Batch View 和Real-time View,提供最终查询结果。
- 特点 :
- 支持低延迟查询。
- 存储优化,支持快速检索。
- 技术实现 :
- 数据库:HBase、Cassandra
- 查询引擎:Presto、Hive
1.4 架构图
数据源 批处理层 加速层 Batch View Real-time View 服务层 查询结果
1.5 技术栈示例
| 层 | 技术方案 |
|---|---|
| 批处理层 | Hadoop (HDFS) + Spark |
| 加速层 | Kafka + Flink/Storm |
| 服务层 | HBase/Cassandra + Hive |
1.6 Lambda架构的优缺点
✅ 优点:
- 高容错性:批处理层可重新计算,确保数据一致性。
- 查询灵活:支持全量+增量数据查询。
- 易扩展 :各层可独立扩展(如增加Spark集群规模)。
❌ 缺点: - 编码开销大:需维护两套计算逻辑(批处理+实时)。
- 重新训练成本高:若业务逻辑变更,需重新计算Batch View。
- 运维复杂:需管理多个组件(Hadoop、Kafka、Flink等)。
2. Kappa架构
2.1 设计目的
Kappa架构由Jay Kreps提出,是Lambda架构的简化版本,仅依赖流处理,通过**数据重放(Replay)**实现批处理功能。
2.2 核心思想
- 统一流处理:所有数据通过流计算引擎(如Flink)处理。
- 历史数据重放:需要全量计算时,从消息队列(如Kafka)重新消费数据。
2.3 应用场景
- 实时推荐系统
- 日志分析
- 实时监控(如APM、风控)
2.4 Mermaid架构图
数据源 消息队列 流处理引擎 存储层 查询结果
2.5 技术栈示例
| 组件 | 技术方案 |
|---|---|
| 消息队列 | Apache Kafka |
| 流处理 | Apache Flink / Spark Streaming |
| 存储 | Elasticsearch / Druid |
2.6 Kappa架构的优缺点
✅ 优点:
- 架构简单:仅需维护一套流处理逻辑。
- 低延迟:所有数据实时处理,无需等待批计算。
- 运维成本低 :减少组件依赖(如无需Hadoop)。
❌ 缺点: - 依赖消息队列存储:Kafka需长期保存数据,成本较高。
- 计算资源消耗大:重放历史数据时可能占用大量资源。
- 数据一致性挑战:依赖流处理引擎的准确性。
3. Lambda vs. Kappa 对比
| 对比维度 | Lambda架构 | Kappa架构 |
|---|---|---|
| 架构复杂度 | 高(批处理+实时两套逻辑) | 低(仅流处理) |
| 数据一致性 | 高(批处理层兜底) | 依赖流处理引擎的准确性 |
| 延迟 | 较高(批处理层有延迟) | 低(纯实时处理) |
| 运维成本 | 高(需维护多个系统) | 较低(仅需流处理系统) |
| 适用场景 | 需要高准确性的场景(如金融风控) | 实时性要求高的场景(如推荐系统) |
4. 设计选择建议
4.1 选择Lambda架构的情况
- 数据准确性要求极高(如金融交易审计)。
- 批处理计算复杂(如机器学习模型训练)。
- 已有Hadoop/Spark生态,不希望重构。
4.2 选择Kappa架构的情况
- 实时性要求高(如广告点击分析)。
- 团队希望简化架构(避免维护两套计算逻辑)。
- 数据量适中,Kafka存储成本可接受。
4.3 混合架构(Lambda + Kappa)
部分企业采用混合模式:
- 核心业务用Lambda(确保准确性)。
- 次要业务用Kappa(降低运维成本)。
5. 结论
- Lambda架构 适合强一致性场景,但维护成本高。
- Kappa架构 适合低延迟场景,但对消息队列依赖强。
- 未来趋势:随着Flink等流计算引擎的成熟,Kappa架构的应用范围正在扩大。
6. 「补充」示例大数据处理系统架构
在大数据系统中,完整的数据处理流程通常包含多个层次,每个层次负责不同的功能,并通过特定的技术组件实现。以下是典型的五层大数据架构及其技术组成:
5.数据展示层 4.数据计算层 3.数据存储层 2.数据集成层 1.数据采集层 当日概览 历史回顾 业务看板 Spark Streaming Impala Hive Spark批处理 MapReduce HDFS HBase MemSQL Kafka Zookeeper Sqoop ETL流程 Flume PC/App/TV端 Nginx日志
1. 数据采集层
负责从各种数据源收集原始数据,包括:
- 用户终端:PC端、App端、TV端等产生的用户行为数据
- 日志收集 :Flume(分布式日志采集)、Nginx(Web访问日志)作用:确保数据高效、稳定地进入大数据管道。
2. 数据集成层
负责数据的传输与缓冲,分为实时 和离线两种方式:
- 实时集成 :
- Kafka(高吞吐消息队列,作为实时数据管道)
- Zookeeper(分布式协调服务,管理Kafka集群)
- 离线集成 :
- Sqoop(Hadoop与关系型数据库间的批量数据传输)
- ETL流程 (数据清洗、转换、加载)作用:确保数据可靠地从采集层进入存储或计算层。
3. 数据存储层
存储处理后的数据,支持不同访问模式:
- HDFS(分布式文件系统,存储海量原始数据)
- HBase(分布式NoSQL数据库,支持低延迟随机读写)
- MemSQL (内存优化型数据库,用于高速分析)作用:提供可扩展、高可用的数据存储方案。
4. 数据计算层
执行实时和离线计算任务:
- 实时计算 :
- Spark Streaming(微批处理流计算)
- 离线计算 :
- Spark批处理(内存计算,高效处理大规模数据)
- MapReduce(Hadoop原生批处理框架)
- Hive(数据仓库,支持SQL查询)
- Impala (MPP引擎,交互式SQL查询)作用:提供灵活的计算能力,支持从实时分析到离线报表的各类需求。
5. 数据展示层
将处理结果可视化,供业务使用:
- 当日概览(实时监控仪表盘)
- 历史回顾(趋势分析报表)
- 业务看板 (关键指标可视化)作用:让数据价值直观呈现,辅助决策。
架构特点
- 分层解耦:各层职责清晰,便于扩展和维护。
- 实时+离线双通道:兼顾低延迟和高准确性需求。
- 技术生态丰富 :可灵活选择组件(如Spark/Flink替换MapReduce)。这种架构适用于金融风控、用户行为分析、IoT数据处理等场景,既能满足实时计算需求,又能支持大规模离线分析。