贝叶斯优化Transformer融合支持向量机多变量回归预测,附相关性气泡图、散点密度图,Matlab实现
目录
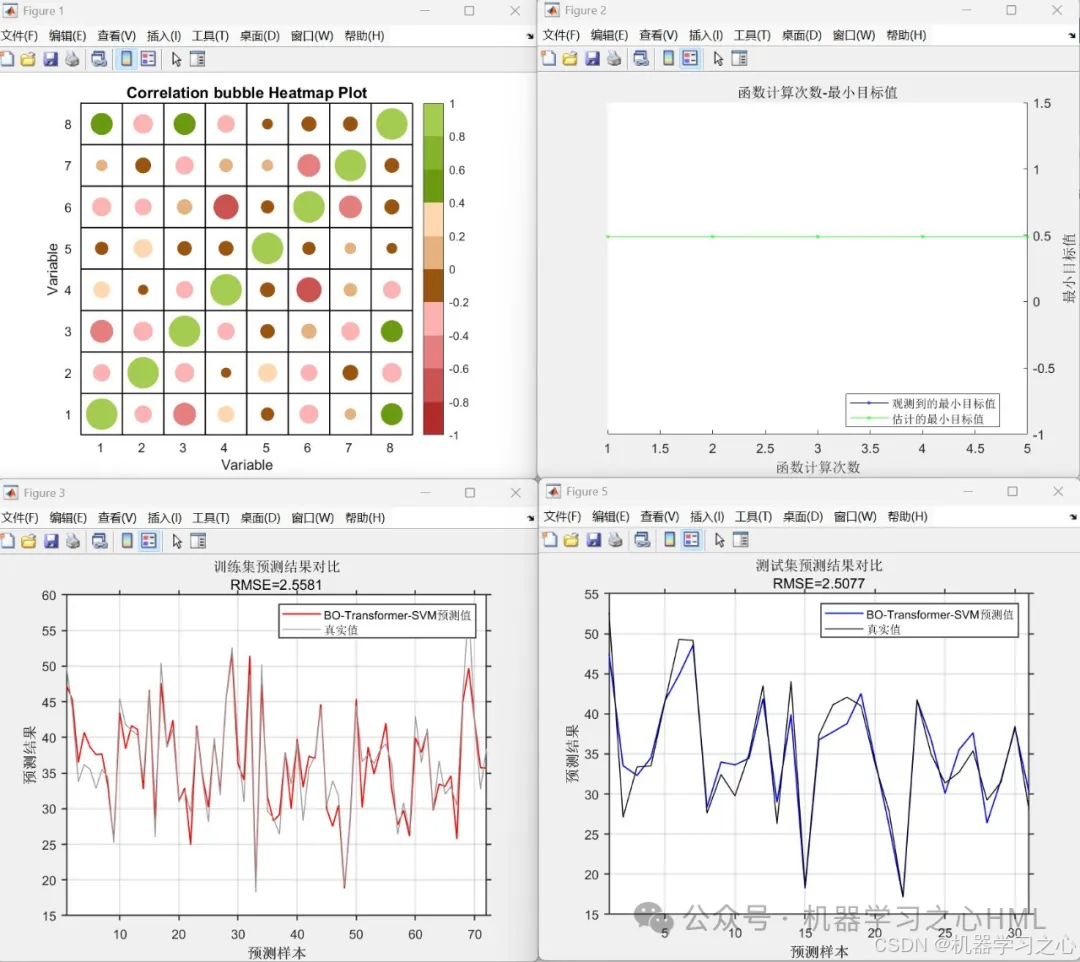
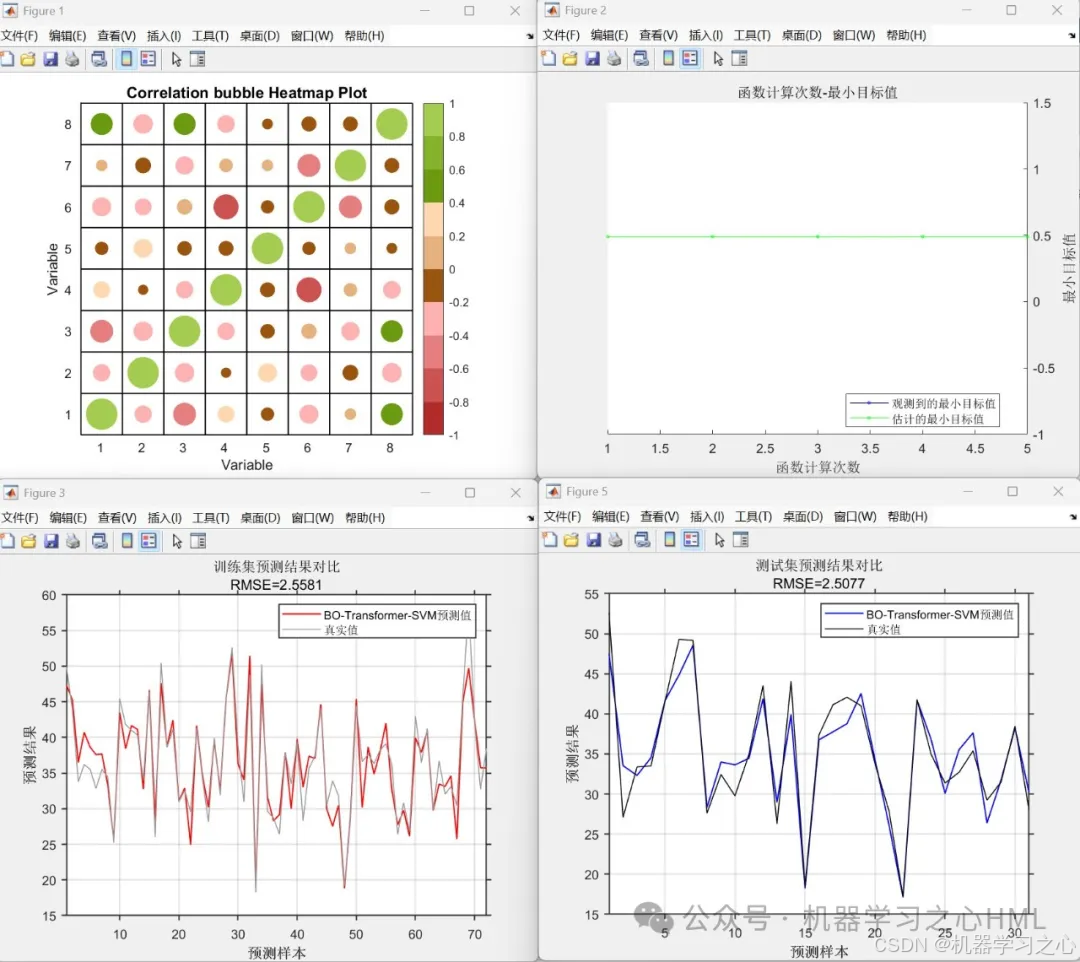
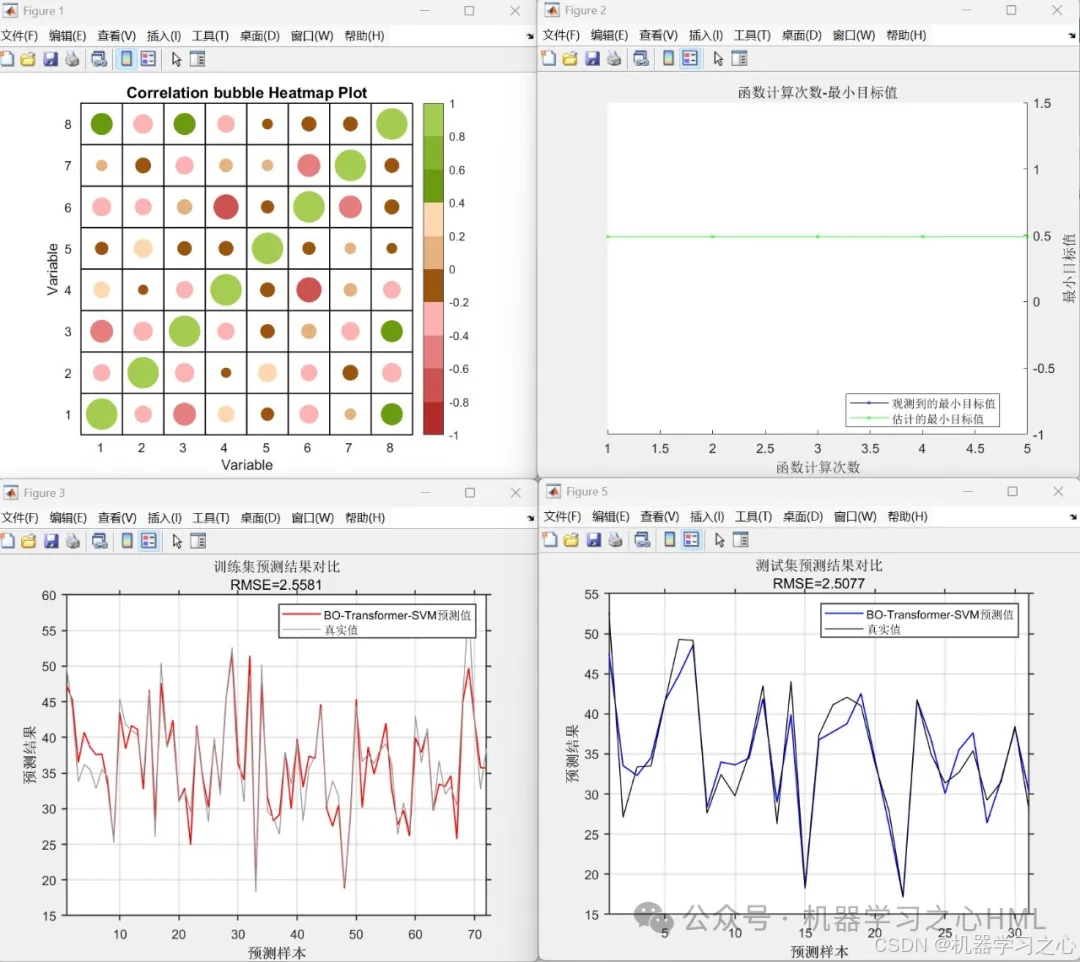
效果一览
基本介绍
1.BO-Transformer+SVM多变量回归预测,Bayes-Transformer+SVM(程序可以作为论文创新支撑,目前尚未发表);
2.Bayes-Transformer提取特征后,输入SVM中,运行环境为Matlab2023b及以上;
3.data为数据集,输入多个变量,输出单个变量,main.m为主程序,运行即可,所有文件放在一个文件夹;
4.命令窗口输出R2、MSE、RMSE、MAE、MAPE、MBE等多指标评价。
代码功能
此代码实现了一个结合Transformer模型和SVM的回归预测框架,具体功能包括:
数据预处理:导入数据,构建输入-输出。
模型构建:使用贝叶斯优化搜索Transformer的超参数(注意力头数、学习率、正则化系数),构建包含位置嵌入和自注意力机制的Transformer模型。
特征提取与预测:利用训练好的Transformer提取序列特征,输入到SVM模型中进行回归预测。
性能评估:计算RMSE、R²、MAE、MAPE、MBE、MSE等指标,并绘制预测结果对比图及误差分析图。
主要原理
数据建模:转换为监督学习问题。
Transformer模型:利用自注意力机制捕捉序列中的长程依赖关系,位置嵌入层编码时间顺序信息。
贝叶斯优化:在超参数空间中搜索最优组合,平衡探索与利用,提高模型性能。
SVM回归:将Transformer提取的高维特征作为输入,利用SVM的非线性拟合能力进行预测。
模型结构
Transformer部分:
输入层:接收序列数据,维度为原始特征数(numChannels)。
位置嵌入层:为输入序列添加位置编码,增强模型对时序的感知。
自注意力层:包含两个多头自注意力层(头数由贝叶斯优化确定),用于捕捉序列内部的依赖关系。
全连接层:将注意力输出映射到目标维度(outputSize=1)。
SVM部分:
使用Transformer中间层的激活值作为特征,通过支持向量回归(SVR)进行最终预测。
算法流程
数据准备:
划分输入-输出序列对,归一化数据。
将训练集和测试集转换为序列输入格式。
超参数优化:
贝叶斯优化搜索numHeads、InitialLearnRate、L2Regularization。
模型训练:
使用优化后的超参数训练Transformer模型。
提取Transformer中间层特征,训练SVM模型。
预测与评估:
对训练集和测试集进行预测,反归一化后计算误差指标。
绘制预测对比图、误差分布图及拟合效果图。
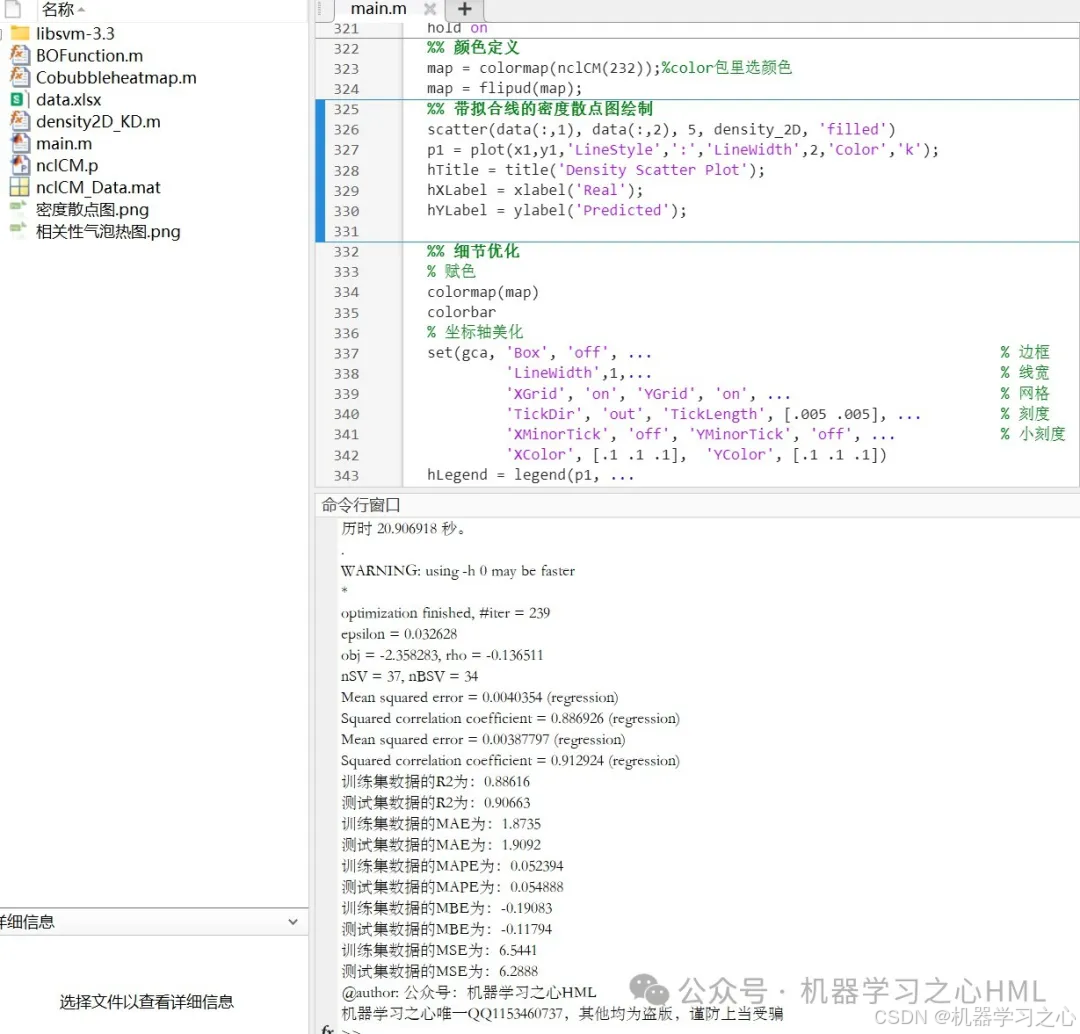
程序设计
完整源码私信回复贝叶斯优化Transformer融合支持向量机多变量回归预测,附相关性气泡图、散点密度图,Matlab实现
clike
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据
result = xlsread('数据集.xlsx');
%% 数据集分析
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征长度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, -1, 1);%将训练集和测试集的数据调整到0到1之间
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, -1, 1);% 对测试集数据做归一化
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
p_train = double(reshape(p_train, f_, 1, 1, M));
p_test = double(reshape(p_test , f_, 1, 1, N));
t_train = double(t_train)';
t_test = double(t_test )';
%% 数据格式转换
for i = 1 : M
Lp_train{i, 1} = p_train(:, :, 1, i);
end
for i = 1 : N
Lp_test{i, 1} = p_test( :, :, 1, i);
end参考资料
1 https://blog.csdn.net/kjm13182345320/article/details/129215161
2 https://blog.csdn.net/kjm13182345320/article/details/128105718