1 概述
Flume是Cloudera开发的一个分布式的、可靠的、高可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化的数据存储系统中。随着互联网的发展,特别是移动互联网的兴起,产生了海量的用户日志信息,为了实时分析和挖掘用户需求,需要使用Flume高效快速采集用户日志,同时对日志进行聚合避免小文件的产生,然后将聚合后的数据通过管道移动到存储系统进行后续的数据分析和挖掘。
2 作用
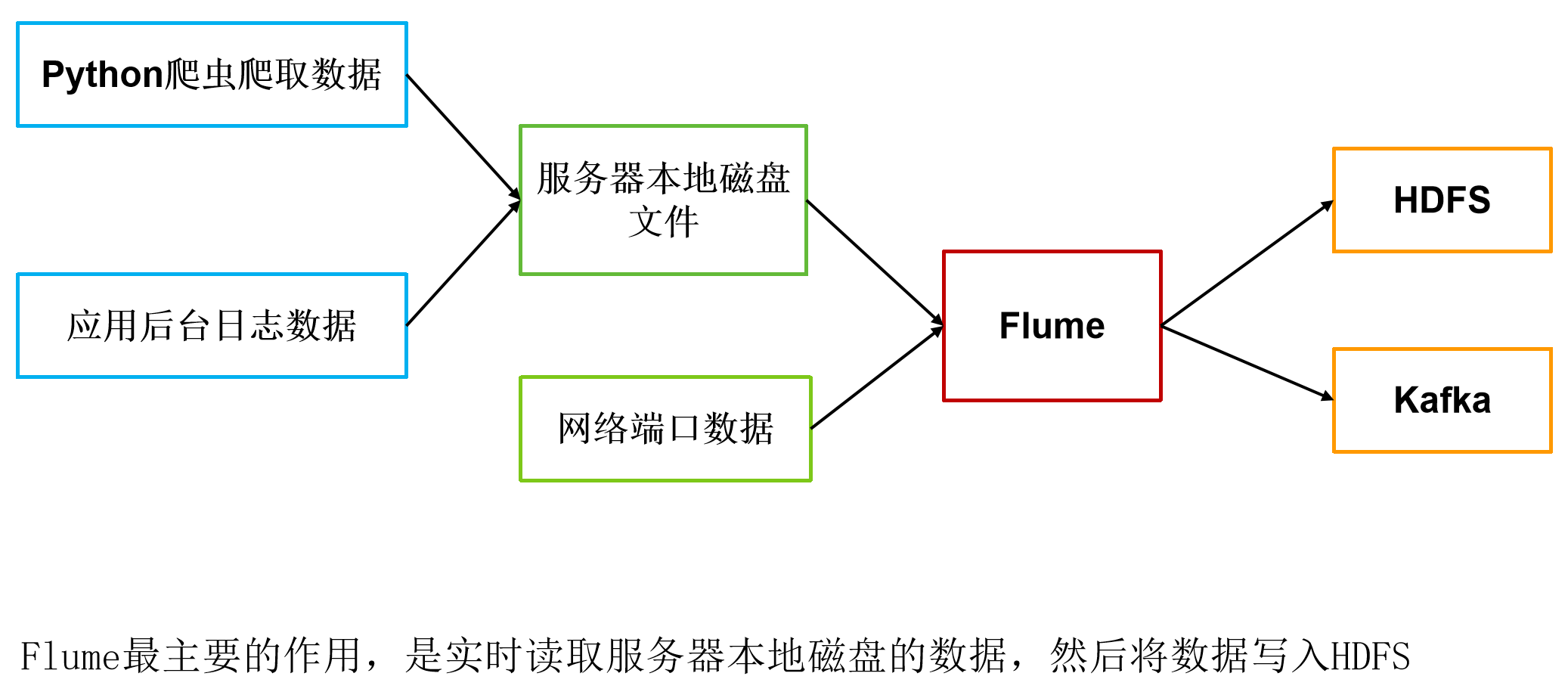
3 架构
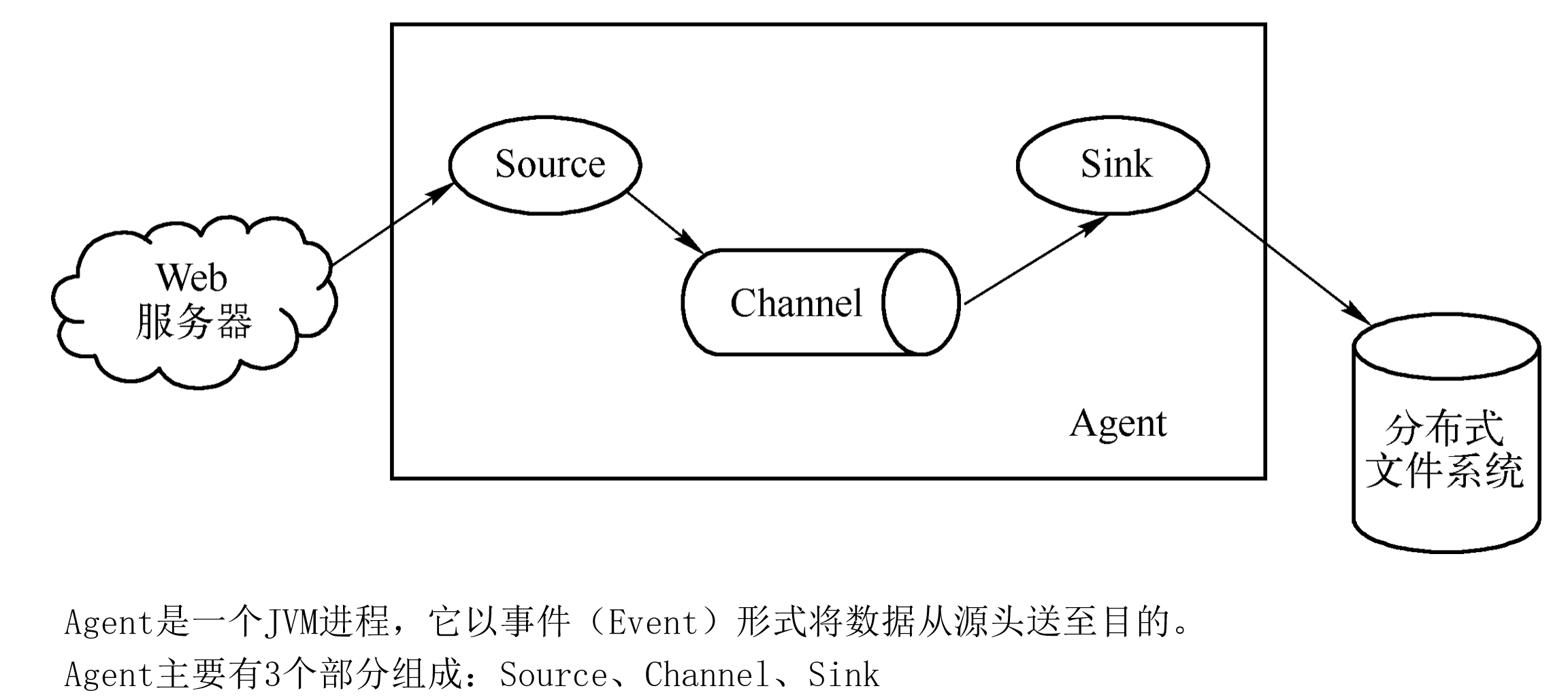
Source
Source负责接收外部源发送过来的数据,指定各种类型的Source以使用各种方式接收数据。

Sink
Sink负责消费Channel中的数据,然后发送给外部数据存储中心。
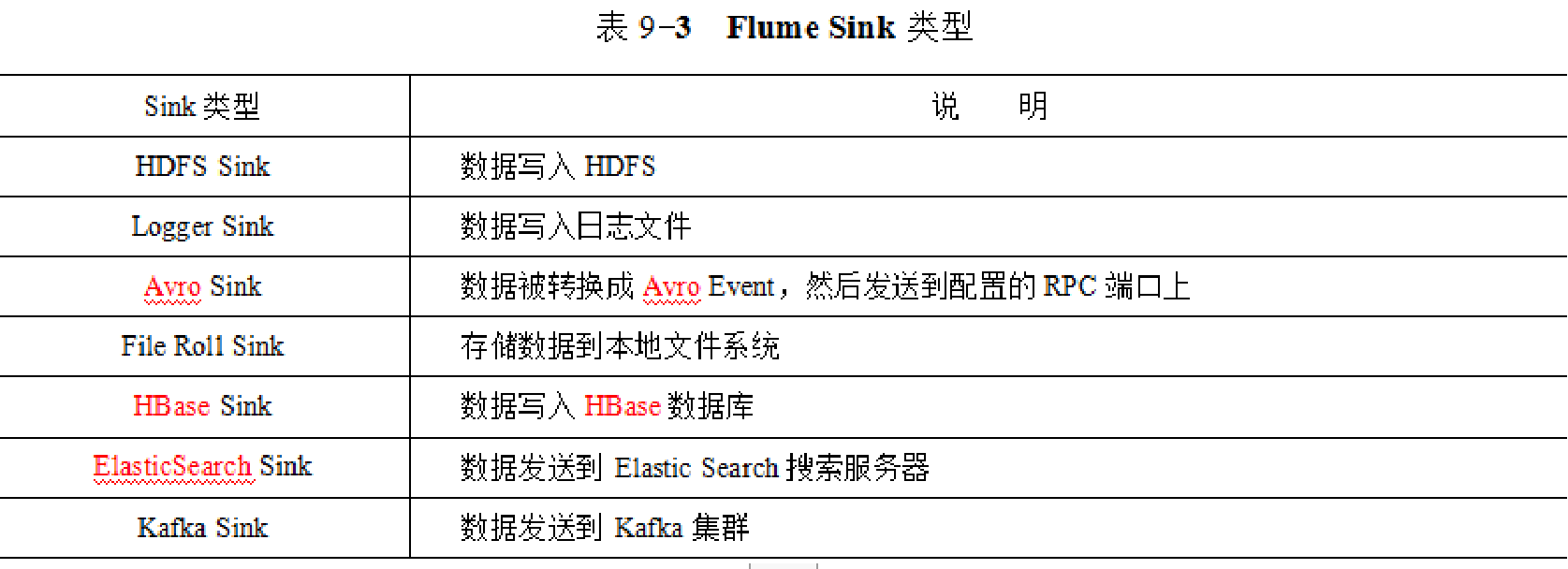
Channel
Channel是位于Source和Sink之间的缓冲区,它的存在使得Source和Sink可以运作在不同的数据处理速率上。
