目录
[一. JVM](#一. JVM)
[1.1 JVM的组成](#1.1 JVM的组成)
[1.2 运行时数据区域的组成](#1.2 运行时数据区域的组成)
[二. 垃圾回收](#二. 垃圾回收)
[2.1 如何确认垃圾](#2.1 如何确认垃圾)
[1. 引用计数法](#1. 引用计数法)
[2. 根搜索算法](#2. 根搜索算法)
[2.2 垃圾回收基本算法](#2.2 垃圾回收基本算法)
[1. 标记-清除算法(Mark-Sweep)](#1. 标记-清除算法(Mark-Sweep))
[2. 标记-压缩算法(Mark-Compact)](#2. 标记-压缩算法(Mark-Compact))
[3. 复制算法(Copying)](#3. 复制算法(Copying))
[4. 多种算法总结](#4. 多种算法总结)
[2.3 分代堆内存GC策略](#2.3 分代堆内存GC策略)
[2.3.1 堆内存分代](#2.3.1 堆内存分代)
[三. java 内存调整相关参数](#三. java 内存调整相关参数)
[3.1 JVM内存常用相关参数](#3.1 JVM内存常用相关参数)
[3.2 查看JVM内存分配情况](#3.2 查看JVM内存分配情况)
在目前流行的互联网架构中,Tomcat在目前的网络编程中是举足轻重的,由于Tomcat的运行依赖于JVM,从虚拟机的角度把tomcat优化分为JVM优化和Tomcat自身优化。
一. JVM
JVM(Java Virtual Machine,Java虚拟机) 是Java平台的核心组件,它是一个虚拟的计算机,能够执行Java字节码(Bytecode)。
1.1 JVM的组成
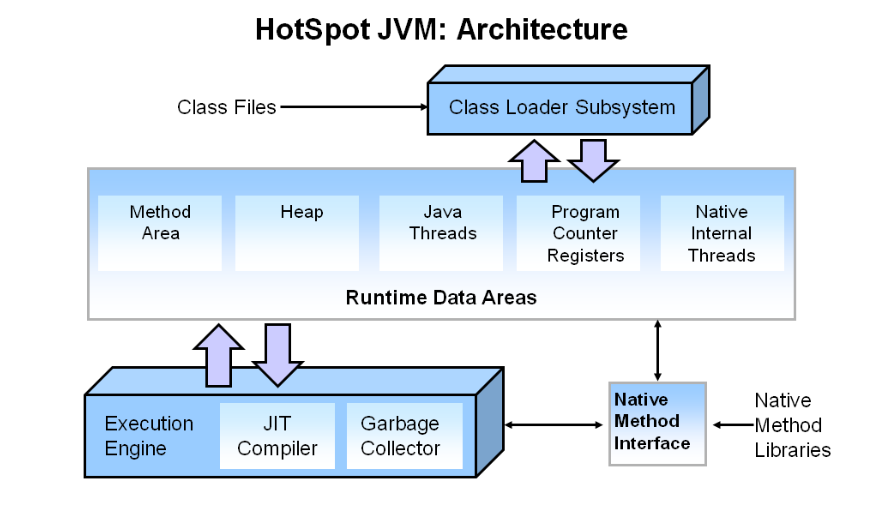
1. 类加载子系统
作用:负责将 .java 编译后的 .class 字节码文件加载到 JVM 内存,并实例化为可执行对象。
核心流程:
-
加载 → 通过类加载器(Bootstrap/Extension/Application)查找并载入
.class文件。 -
链接 → 验证字节码、分配静态变量默认值、解析符号引用。
-
初始化 → 执行静态代码块和变量赋值,完成类准备。
2. 运行时数据区
作用:JVM 内存划分为多个区域,用于存储程序运行时的数据
3. 执行引擎
作用:负责解释或编译执行字节码
4. 本地方法接口
允许Java代码调用本地库
1.2 运行时数据区域的组成
Method Area (线程共享) :是所有线程共享的内存空间,存放已加载的类信息(构造方法,接口定义),常量(final),静态变量(static), 运行时常量池等。
heap (线程共享): 堆在虚拟机启动时创建,存放创建的所有对象信息,是垃圾回收(GC)的主要目标。
虚拟机栈(JVM Stack): 每个线程私有,存储 栈帧(Frame)。
**程序计数器(Program Counter Register):**线程私有,记录当前线程执行的字节码指令地址
本地方法栈(Native Method Stack): 为 JVM 调用 本地方法。
二. 垃圾回收
2.1 如何确认垃圾
1. 引用计数法
引用计数: 每一个堆内对象上都与一个私有引用计数器,记录着被引用的次数,引用计数清零,该对象所占用堆内存就可以被回收。循环引用的对象都无法将引用计数归零,就无法清除。
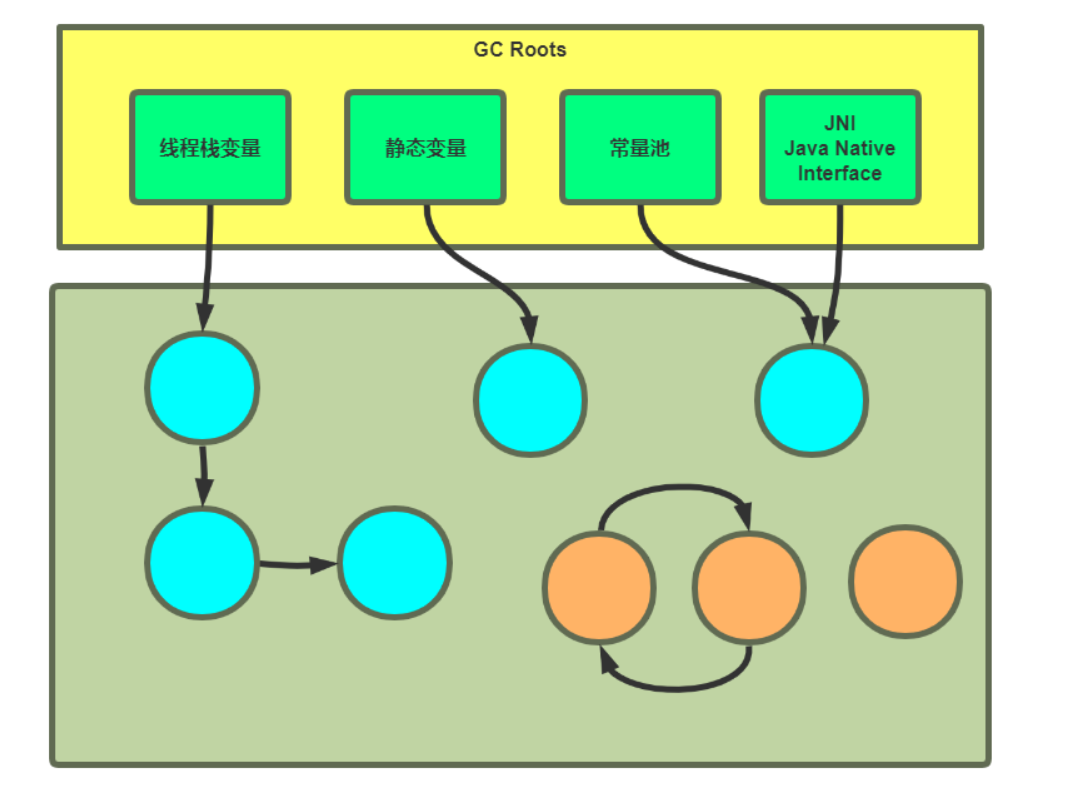
2. 根搜索算法
从 GC Roots(如栈帧、静态变量等)出发,遍历所有可达对象,未被遍历到的对象视为垃圾。
缺点:可能出现两个垃圾相互调用,形成僵尸进程的情况。
2.2 垃圾回收基本算法
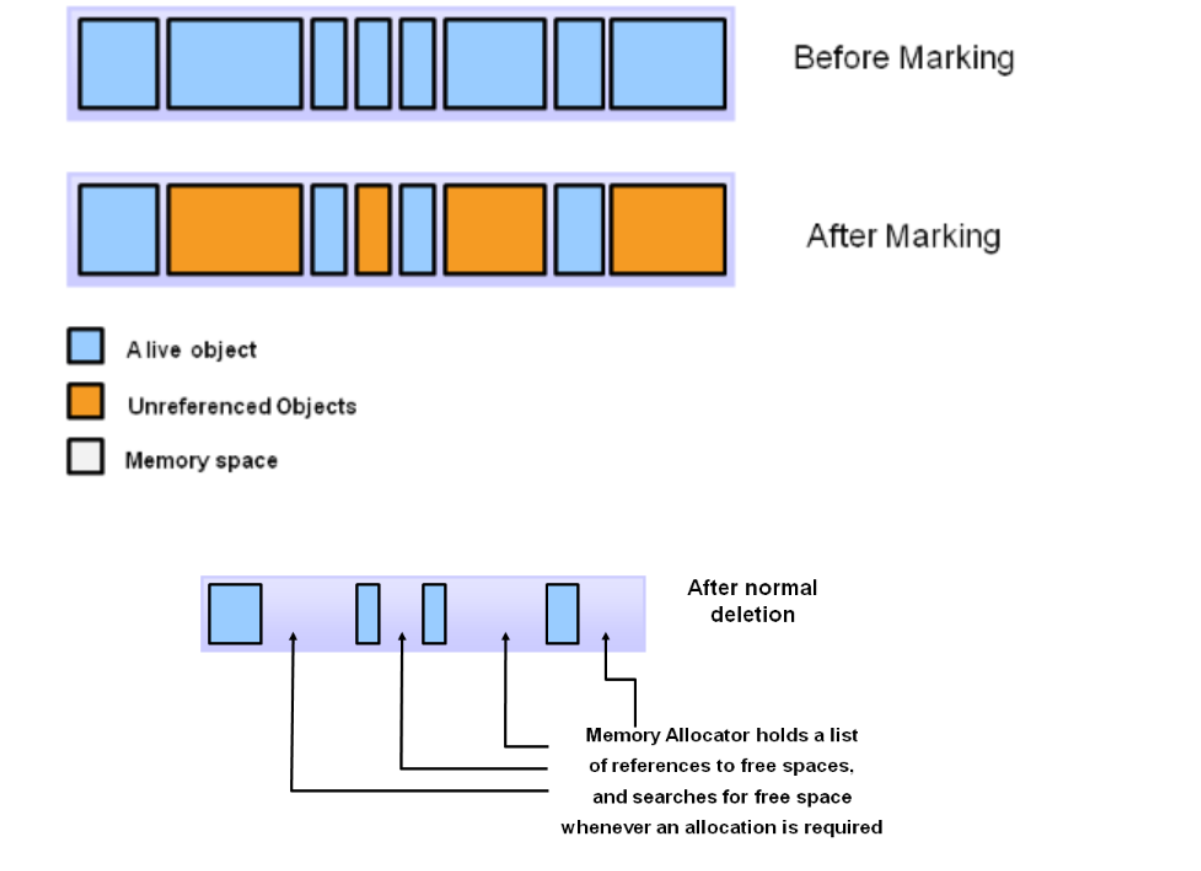
1. 标记-清除算法(Mark-Sweep)
核心原理
-
标记阶段:从 GC Roots 出发,遍历所有可达对象并标记为"存活"。
-
清除阶段:扫描整个堆,回收未被标记的对象内存。
缺点:回收后产生 内存碎片(不连续空闲块)
2. 标记-压缩算法(Mark-Compact)
核心原理
-
标记阶段:与 Mark-Sweep 相同,标记所有存活对象。
-
压缩阶段 :将所有存活对象 向内存一端移动,并更新引用地址。
-
清理边界:直接回收边界外的全部空间。
缺点: 内存整理过程有消耗,效率相对低下
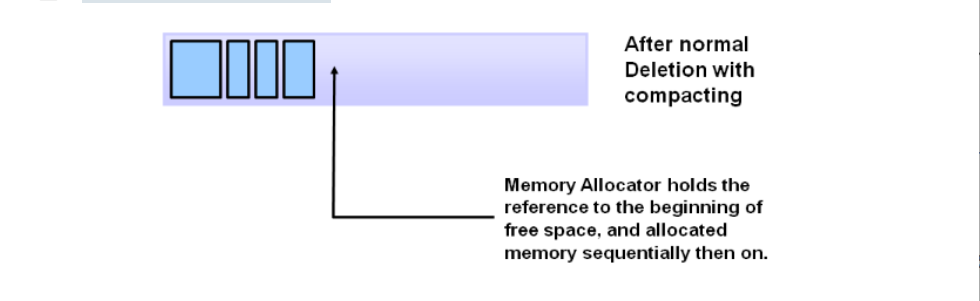
3. 复制算法(Copying)
核心原理
-
内存划分 :将堆分为 两块相同大小的空间(From 和 To)。
-
存活对象复制:
-
从 From 区标记存活对象。
-
将存活对象 复制到 To 区(紧凑排列)。
-
-
角色互换:回收整个 From 区,并交换 From/To 角色。
缺点:比较浪费内存,只能使用原来一半内存
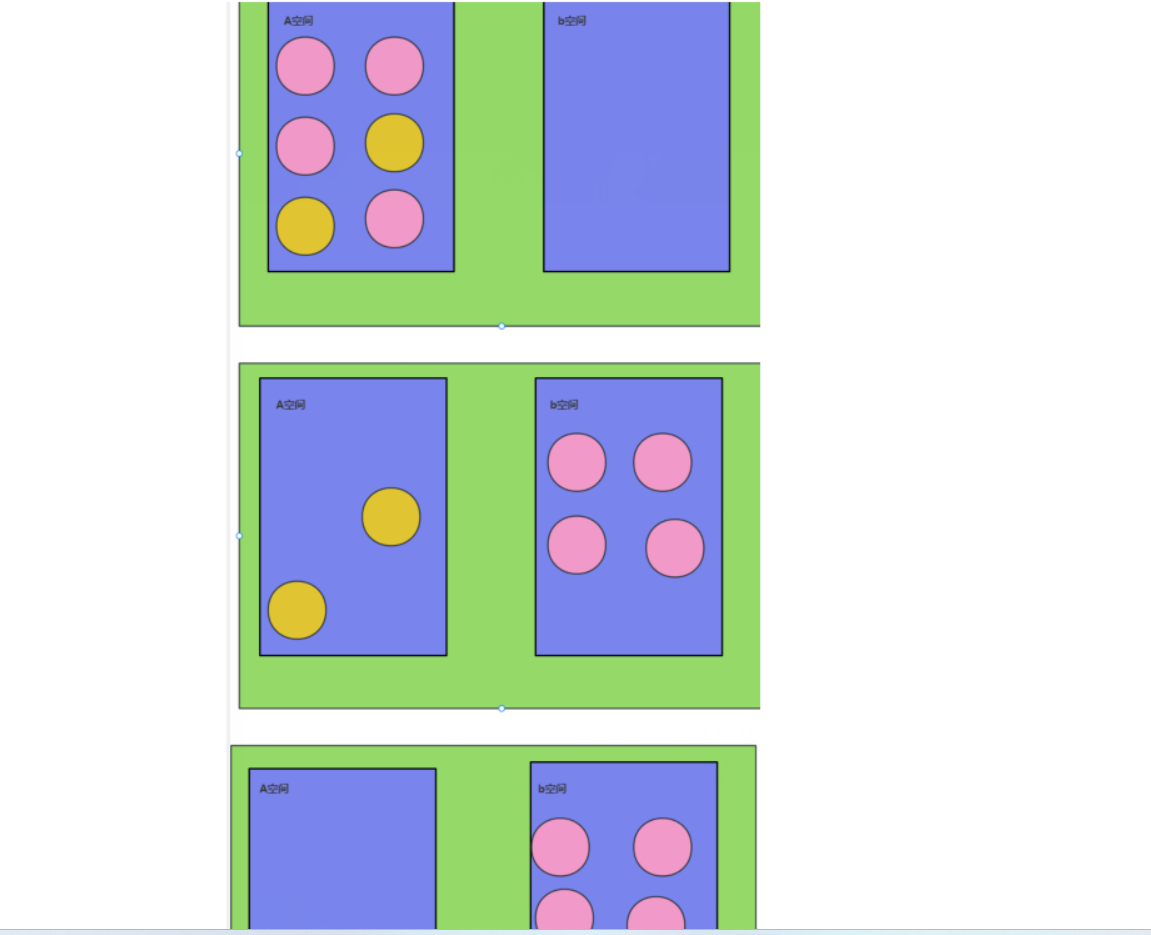
4. 多种算法总结
-
效率: 复制算法>标记清除算法> 标记压缩算法
-
内存整齐度: 复制算法=标记压缩算法> 标记清除算法
-
内存利用率: 标记压缩算法=标记清除算法>复制算
2.3 分代堆内存GC策略
2.3.1 堆内存分代
上述垃圾回收算法都有优缺点,能不能对不同数据进行区分管理,不同分区对数据实施不同回收策略,分而治之。
将heap内存空间分为三个不同类别: 年轻代、老年代、持久代
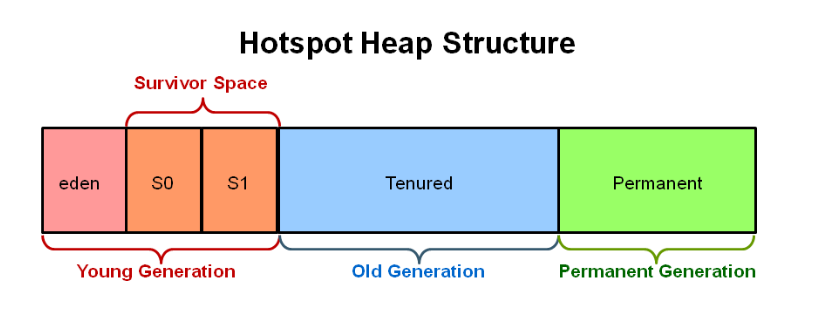
- 年轻代(Young Generation)
概述:年轻代是存放新创建对象的内存区域。大多数对象在创建后很快就会被回收,因此年轻代的设计是为了快速回收这些短生命周期的对象。
- 老年代(Old Generation)
概述:老年代用于存放那些在年轻代中经过多次垃圾回收后仍然存活的对象。这些对象通常具有较长的生命周期。
- 持久代(Permanent Generation)
概述:持久代(在JDK 8及以后被元空间Metaspace取代)用于存储JVM的类元数据、方法区信息、常量池等。持久代不属于堆内存的一部分,而是JVM的另一个内存区域。
三. java 内存调整相关参数
3.1 JVM内存常用相关参数
选项分类
-
-选项名称 此为标准选项,所有HotSpot都支持
-
-X选项名称 为稳定的非标准选项
-
-XX:选项名称 非标准的不稳定选项,下一个版本可能会取消
| 参数 | 说明 | 举例 |
|---|---|---|
| -Xms | 设置应用程序初始使用的堆内存大小(年轻代+老年代) | -Xms2g |
| -Xmx | 设置应用程序能获得的最大堆内存早期JVM不建议超过32G,内存管理效率下降 | -Xms4g |
| -XX:NewSize | 设置初始新生代大小 | -XX:NewSize=128m |
| -XX:MaxNewSize | 设置最大新生代内存空间 | -XX:MaxNewSize=256m |
| -Xmnsize | 同时设置-XX:NewSize 和 -XX:MaxNewSize,代 | -Xmn1g |
| -XX:NewRatio | 以比例方式设置新生代和老年代 | -XX:NewRatio=2 new/old=1/2 |
| -XX:SurvivorRatio | 以比例方式设置eden和survivor(S0或S1) | -XX:SurvivorRatio=6 eden/survivor=6/1 new/survivor=8/1 |
| -Xss | 设置每个线程私有的栈空间大小,依据具体线程 | -Xss256k |
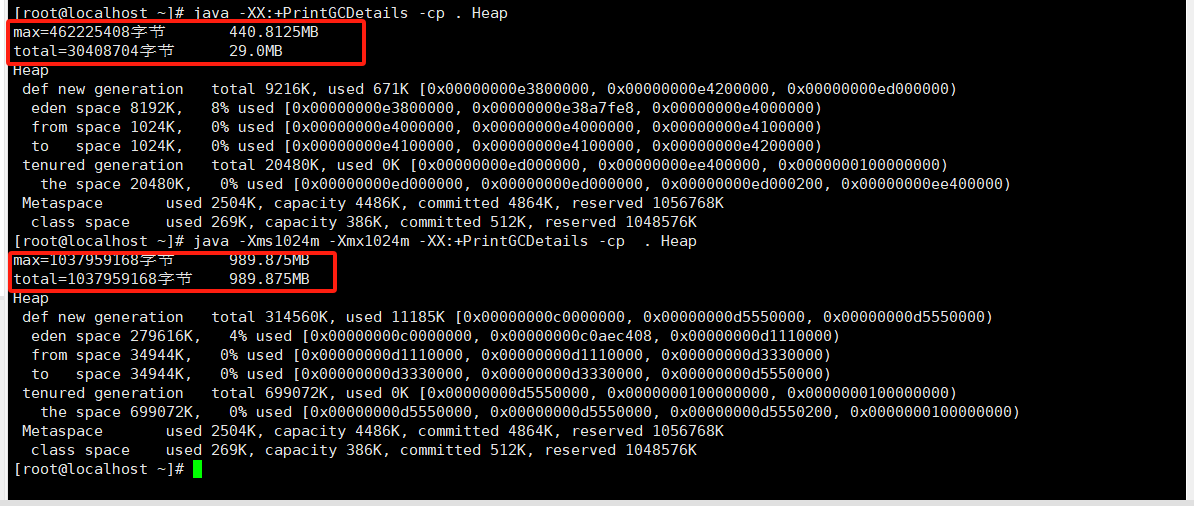
3.2 查看JVM内存分配情况
拖入Head.java
cat Head.java
#查看Head.java内容
public class Heap {
public static void main(String[] args){
//返回虚拟机试图使用的最大内存,字节单位
long max = Runtime.getRuntime().maxMemory();
//返回JVM初始化总内存
long total = Runtime.getRuntime().totalMemory();
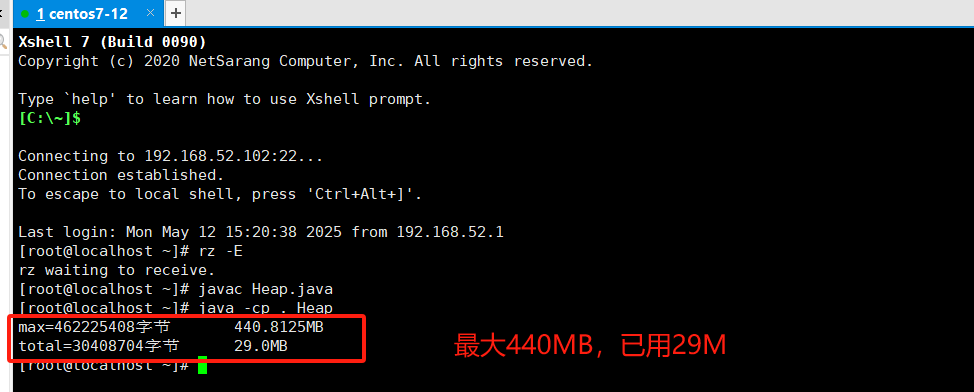
System.out.println("max="+max+"字节\t"+(max/(double)1024/1024)+"MB");
System.out.println("total="+total+"字节\t"+(total/(double)1024/1024)+"MB");
}
}
javac Head.java
#编译Head.java
java -cp . Heap
#运行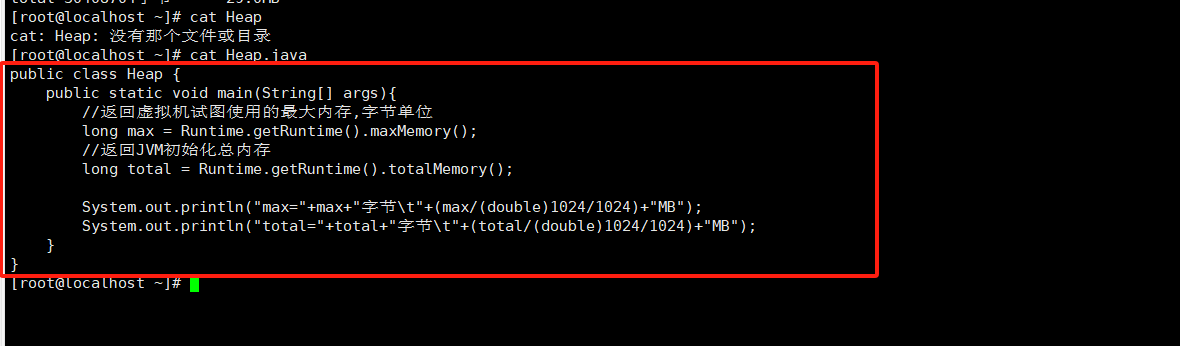
java -XX:+PrintGCDetails -cp . Heap
#内存详细情况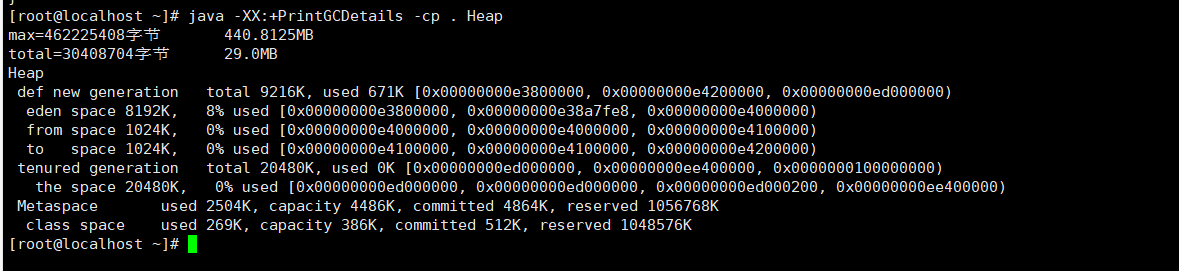
3.2 修改JVM初始堆和最大堆的大小
java -Xms1024m -Xmx1024m -XX:+PrintGCDetails -cp . Heap