mxbai-rerank-base-v2 强大的重排序模型
模型介绍
mxbai-rerank-base-v2 是 Mixedbread 提供的一个强大的重排序模型,旨在提高搜索相关性。该模型支持多语言,特别是在英语和中文方面表现出色。它还支持代码和 SQL 排序,能够处理长达 8k 个标记的上下文,并且在技术内容排序方面表现优异。
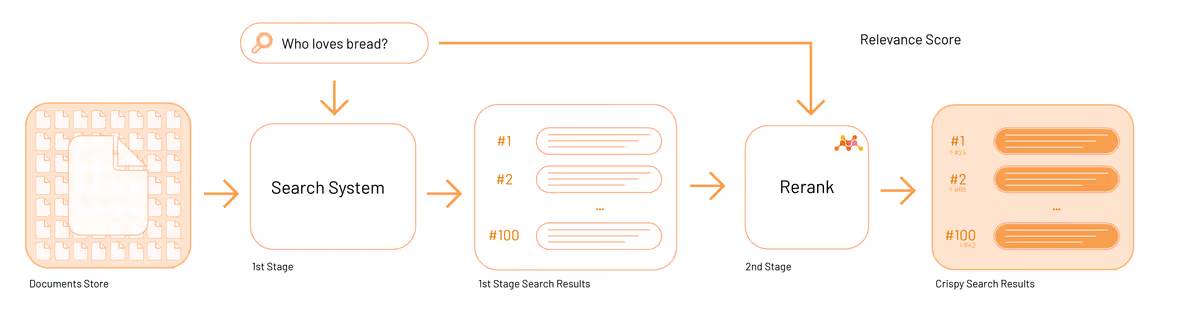
模型类别(20250517)
- mxbai-rerank-base-v2
- mxbai-rerank-large-v2 (🍞)
训练使用了三个步骤进行训练:
- GRPO (引导式配筋提示优化)
- 对比学习
- 偏好学习
主要特点
-
多语言支持:支持 100 多种语言,特别是在英语和中文方面表现出色。
-
长上下文支持:能够处理长达 8k 个标记的上下文,适用于复杂的查询和文档。
-
代码和 SQL 排序:在排序代码片段和技术内容方面表现优异。
-
快速推理:推理速度比同类模型快 8 倍,适合需要快速响应的应用场景。
-
开源和易于集成:基于 Apache 2.0 许可证开源,易于定制和集成到现有的搜索系统中。
benchmark
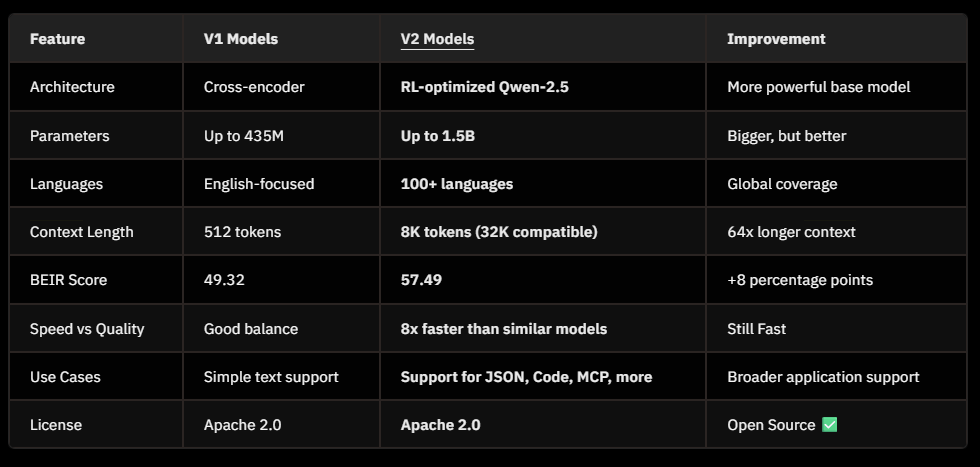
在 A100 GPU (80GB)上测量:
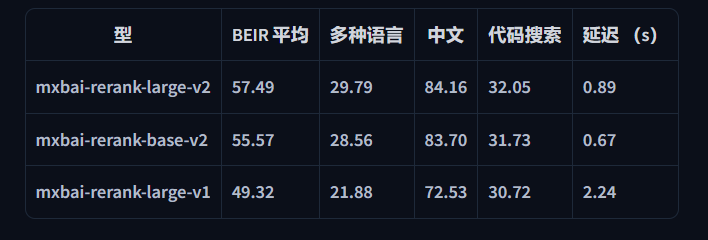
综合评价
1.5B 模型比 bge-reranker-v2-gemma 快 8 倍,同时提供更高的准确性。这种速度优势意味着您可以在不牺牲质量的情况下每秒处理更多查询,使模型成为性能和成本效益都很重要的大批量生产环境的理想选择。
BEIR 是评估英语信息检索模型的行业标准基准。Mixedbread 的 rerank-v2 在 BEIR 排行榜上处于领先地位,其性能优于所有竞争模型,并接近最先进的嵌入模型的有效性,同时使用 BM25 作为第一阶段检索器。
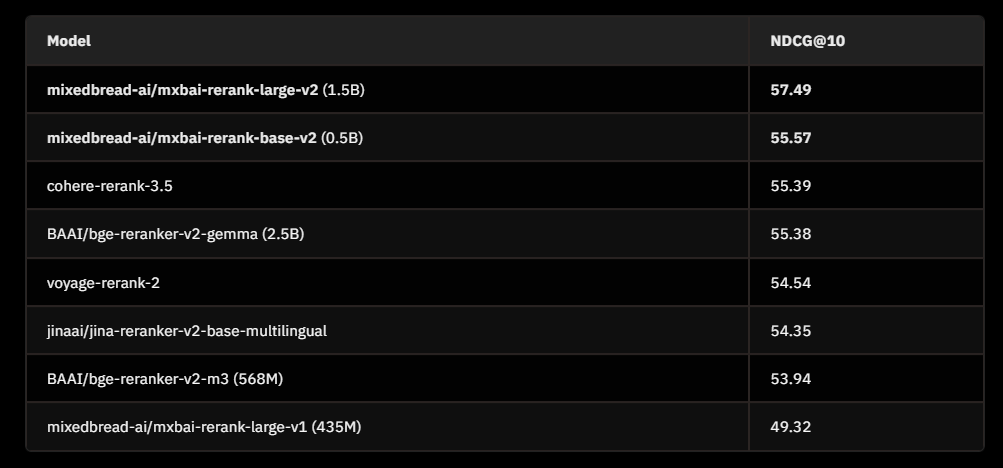
模型通过重新排列候选文档以更好地与用户查询保持一致,显著提高了搜索质量。大型变体(1.5B 参数)的 BEIR 得分为 57.49,是基准中最高的,而我们的基本变体 (0.5B) 也以令人印象深刻的 55.57 分超过了更大的型号。
这代表了对上一代产品的重大改进,与 v1 相比,v2 模型的性能提高了 8 个百分点以上。这些改进使我们的 reranker 对于检索质量至关重要的生产环境非常有价值,而无需大型模型的极端资源需求。组织现在可以有效地部署最先进的搜索功能,确保高准确性和最佳性能。
BEIR Benchmark Performance:
博客地址:https://www.mixedbread.com/blog/mxbai-rerank-v2
huggingface:https://huggingface.co/mixedbread-ai/mxbai-rerank-large-v2
安装
bash
pip install mxbai-rerank推理示例代码
python
from mxbai_rerank import MxbaiRerankV2
# 初始化重排序器
model = MxbaiRerankV2("mixedbread-ai/mxbai-rerank-base-v2")
# 示例查询和文档
query = "《杀死一只知更鸟》的作者是谁?"
documents = [
"《杀死一只知更鸟》是哈珀·李于1960年出版的一部小说。",
"《白鲸记》是赫尔曼·梅尔维尔写的小说。",
"哈珀·李于1926年出生在阿拉巴马州的门罗维尔。"
]
# 获取排序结果
results = model.rank(query=query, documents=documents)
print(results)