大家好,这里是失踪人口bang__bang_,从今天开始持续更新PostgreSQL内幕相关内容,让我们一起了解学习吧✊!


目录
[1️⃣ DB集群、数据库、表](#1️⃣ DB集群、数据库、表)
[🍙 数据库集群的逻辑结构](#🍙 数据库集群的逻辑结构)
[🍙 数据库集群的物理结构](#🍙 数据库集群的物理结构)
[🍥 数据库集群布局](#🍥 数据库集群布局)
[🍥 数据库布局](#🍥 数据库布局)
[🍥 表和索引相关联文件的布局](#🍥 表和索引相关联文件的布局)
[🍥 表空间布局](#🍥 表空间布局)
[🍙 堆表文件的结构布局](#🍙 堆表文件的结构布局)
[🍙 元组读写方法](#🍙 元组读写方法)
[🍥 写入元组](#🍥 写入元组)
[🍥 读取元组](#🍥 读取元组)
[2️⃣ 进程架构和内存架构](#2️⃣ 进程架构和内存架构)
[🍙 进程架构](#🍙 进程架构)
[🍙 内存架构](#🍙 内存架构)
1️⃣ DB集群、数据库、表
🍙 数据库集群的逻辑结构
 集群逻辑图
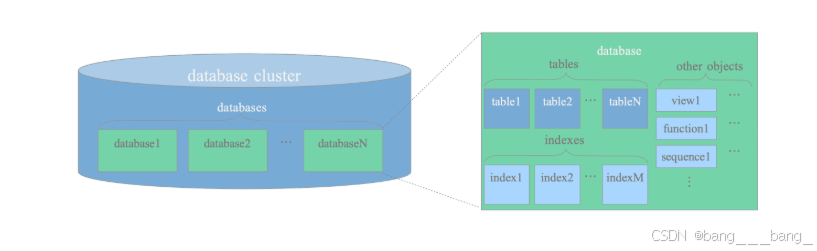
集群逻辑图
数据库是数据库对象的集合,数据库对象可以是数据库本身、表、索引、试图等。
数据库集群是PostgreSQL数据库服务器在单个主机上运行并管理单个数据库集群。
PostgreSQL中的所有数据库对象都由Oid(unsigned int)4字节的无符号整数标识。
exp:
数据库的Oid存储在pg_database;堆表的Oid存储在pg_class中。
sql
select datname,oid from pg_database where datname="simpledb";
select relname,oid from from pg_class where relname="simpletbl";🍙 数据库集群的物理结构
 物理结构图
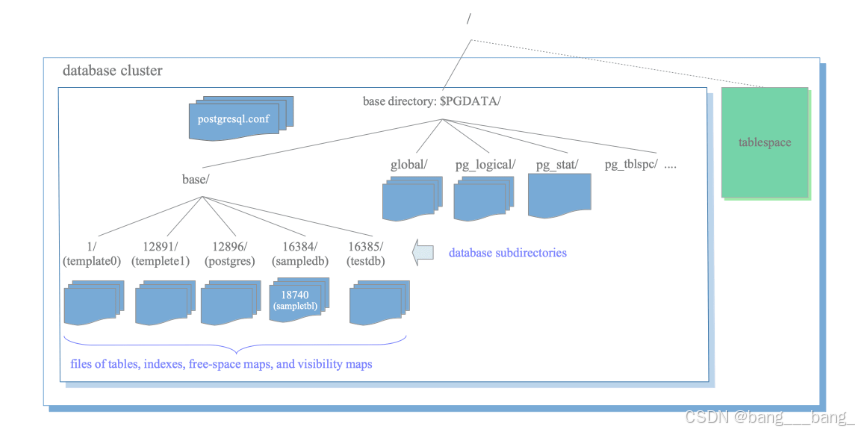
物理结构图
数据库集群其实是一个base directory 目录,在初始化程序时创建基目录,其路径由系统变量PGDATA设置。
一切皆文件 ,在postgresql中,数据库是存储在base目录下的子目录文件,表和索引则是对应数据库目录下的文件。特殊的表空间也是一个目录,包含基本目录之外的数据,在根目录下**/tablespace**。
🍥 数据库集群布局
基目录下文件的布局:
| files | description |
|---|---|
| PG_VERSION | 包含 PostgreSQL 主版本号的文件。 |
| current_logfiles | 记录日志记录收集器当前写入的日志文件的文件。 |
| pg_hba.conf | 用于控制 PostgreSQL 的客户端身份验证的文件。 |
| pg_ident.conf | 用于控制 PostgreSQL 的用户名映射的文件。 |
| postgresql.conf | 用于设置配置参数的文件。 |
| postgresql.auto.conf | 用于存储在 ALTER SYSTEM 中设置的配置参数的文件。(版本 9.4 或更高版本) |
| postmaster.opts | 一个文件,记录上次启动服务器时使用的命令行选项。 |
基目录下子目录的布局:
| subdirectories | description |
|---|---|
| base/ | 包含每个数据库的子目录的子目录。 |
| global/ | 包含集群范围的表(如 pg_database 和 pg_control)的子目录。 |
| pg_commit_ts/ | 包含事务提交时间戳数据的子目录。(版本 9.5 或更高版本) |
| pg_clog/ (versions 9.6 or earlier) | 包含事务提交状态数据的子目录。在版本 10 中,它已重命名为 pg_xact。 |
| pg_dynshmem/ | 包含动态共享内存子系统使用的文件的子目录。(版本 9.4 或更高版本) |
| pg_logical/ | 包含用于逻辑解码的状态数据的子目录。(版本 9.4 或更高版本) |
| pg_multixact/ | 包含多事务状态数据的子目录。(用于共享行锁) |
| pg_notify/ | 包含 LISTEN/NOTIFY 状态数据的子目录。 |
| pg_repslot/ | 包含复制槽数据的子目录。(版本 9.4 或更高版本) |
| pg_serial/ | 子目录,其中包含有关已提交的可序列化事务的信息。(版本 9.1 或更高版本) |
| pg_snapshots/ | 包含导出快照的子目录。 PostgreSQL 的函数pg_export_snapshot在此子目录中创建快照信息文件。 (版本 9.2 或更高版本) |
| pg_stat/ | 包含 statistics 子系统的永久文件的子目录。 |
| pg_stat_tmp/ | 包含 statistics 子系统的临时文件的子目录。 |
| pg_subtrans/ | 包含子事务状态数据的子目录。 |
| pg_tblspc/ | 包含指向表空间的符号链接的子目录。 |
| pg_twophase/ | 包含准备好的事务的状态文件的子目录。 |
| pg_wal/ (versions 10 or later) | 包含 WAL(预写日志记录)段文件的子目录。它是从版本 10 中的 pg_xlog 重命名而来的。 |
| pg_xact/ (versions 10 or later) | 包含事务提交状态数据的子目录。它是从版本 10 中的 pg_clog 重命名而来的。 |
| pg_xlog/ (versions 9.6 or earlier) | 包含 WAL(预写日志记录)段文件的子目录。在版本 10 中,它已重命名为 pg_wal。 |
在版本 10 中,子目录 pg_xlog 和 pg_clog 分别重命名为 pg_wal 和 pg_xact。
🍥 数据库布局
物理存储上数据库目录的name和Oid相同,数据库路径如base/oid。
🍥 表和索引相关联文件的布局
每个大小小于1GB的表或索引会存储在其数据库目录下的单个文件中。表和索引由单个Oid在内部管理,他们的数据内容由变量relfilenode进行管理,Oid和relfilenode并不总是相同。
1.一般情况下,Oid和relfilenode对应相同,此时数据文件路径则为数据库目录下的relfilenode,如base/oid/relfilenode。
2.当使用TRUNCATE、REINDEX、CLUSTER等来更改表和索引的 relfilenode 值后会删除旧的数据文件,生成新的数据文件,此时Oid和relfilenode就不相同了。
内置函数pg_relation_filepath()可以返回具有指定oid或名称关系的文件路径。
如果当表或索引的数据大小大于1GB,则会创建一个以relfilenode.1为名的新文件,依次类推。
表文件会有两个后缀"_fsm"和"_vm"的文件分别是free space map和visibility map,表示空闲空间映射和可用空间映射,fsm和vm在内部可以称为每个关系的分叉,数据文件的分叉编号为0,fsm的分叉编号为1,vm的分叉编号为2。
🍥 表空间布局
 表空间布局
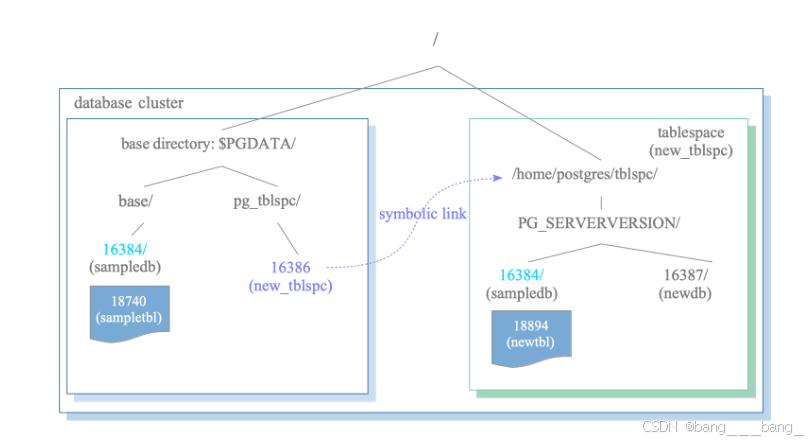
表空间布局
使用CREATE TABLESPACE语句在指定目录下创建表空间,则会在该指定目录下创建一个特定于版本的子目录。 子目录命名规则为PG_目录名_版本号
sql
CREATE TABLESPACE tablespace_name
[ OWNER { new_owner | CURRENT_ROLE | CURRENT_USER | SESSION_USER } ]
LOCATION 'directory'
[ WITH ( tablespace_option = value [, ... ] ) ]1.表空间由pg_tblspc子目录进行符号链接寻址,链接名称则为生成的tablespace的Oid值。
2.如果要在特定版本的表空间中创建一个数据库,则会在tablespace中生成一个子目录,目录名为数据库Oid。
3.如果要对基目录中的数据库创建一个新表,则首先会在特定版本的表空间中生成一个数据库目录,其目录名为基目录的Oid值,再在其下生成一个表文件。
🍙 堆表文件的结构布局
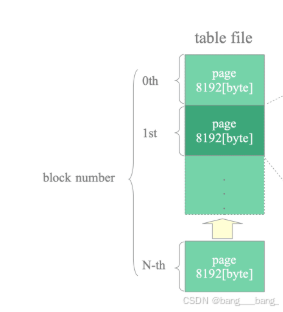
在PostgreSQL中数据文件是由一个个大小为8kb的页面(也称作块)组成的,当文件大小不够使用时,PostgreSQL会在文件末尾添加新的空页,页面号由0开始编号。
 堆表文件结构
堆表文件结构
每个页面的内部结构如下:
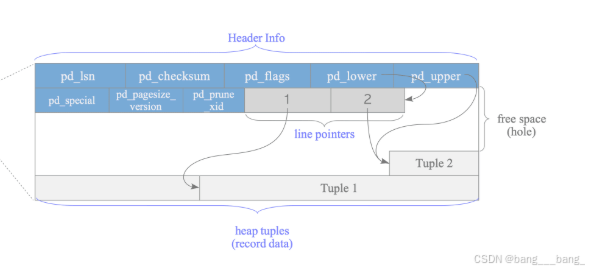 页面内部结构
页面内部结构
关键结构:
-
heap tuples(堆元组):tuple(堆元组)是自页面底部进行堆放的。
-
line pointers(行指针数组): line pointer是4字节长度的行指针,其中包含指向tuple的指针,行指针形成一个简单的数组,行指针按顺序编号,称为偏移量编号,当一个新的tuple被添加到页面时自然而然的推送一个新的行指针到数组上指向新的tuple。
-
**Header Info(标头数据):**页面开头分配长度为24字节。pd_lower和pd_upper所指向的中间空白区域称为free space.
字段 描述 pd_lsn 8字节,用于wal机制,LSN:此页的最后一次更改的 WAL 记录的最后一个字节之后的下一个字节 pd_checksum 2字节,用于校验和 pd_flags 2字节,标志位 pd_lower 2字节,指向行指针末尾,描述空闲空间的开头 pd_upper 2字节,指向最新堆元组开头,描述空闲空间的末尾 pd_special 2字节,表示索引,在表空间中指向页面末尾,在索引空间中指向特殊空间开头 pd_pagesize_version 2字节,页面大小和布局版本号信息 pd_prune_xid 4字节,页面上最旧的未修剪 XMAX,如果没有则为零
使用TID (元组标识符)标识表中的元组,TID是由一对值构成**(页面号,指向目标元组的行指针偏移量)。**
此外,大小大于约 2 KB(约为 8 KB 的 1/4)的堆元组使用称为 TOAST(超大属性存储技术)的方法进行存储和管理。
🍙 元组读写方法
🍥 写入元组
 写入元组示意图
写入元组示意图
阶段1:页面只有元组tupe1,pd_lower指向行指针末尾即line pointer1,line pointer1指向对应堆元组tuple1,pd_upper指向最新堆元组开头tuple1。
阶段2: 向页面写入新的元组tuple2,对应推送一个新的line pointer2到数组,其指向tuple2,pd_lower更新指向最新行指针末尾,pd_upper更新指向最新tuple2的开头,对应的其他字段也进行更新。
🍥 读取元组
顺序扫描:顺序扫描是按序遍历页面的行指针数组即遍历对应的堆元组。
B树索引扫描:B树索引扫描是使用了一个索引文件,索引文件中有索引元组,基本构成为(索引键,指向目标堆元组的TID),TID上述介绍为(页面号,行指针偏移量),通过扫描索引文件中的索引元组获取到对应目标索引键拿到TID,通过TID拿到数据。
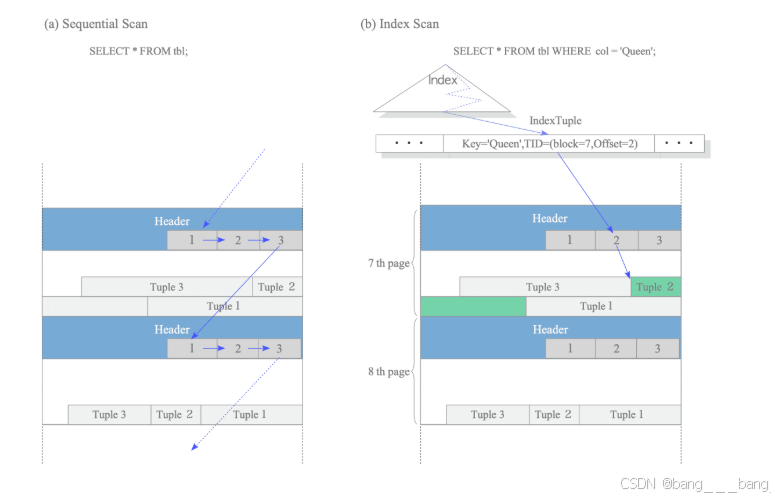 读取元组示意图
读取元组示意图
2️⃣ 进程架构和内存架构
🍙 进程架构
PostgreSQL是一个多进程架构,具有一个所有进程的父进程Postgres进程、2个后端进程接受客户端的请求,7个后台进程作不同的功能、1个复制关联进程,v9.3后支持后台工作进程,他们构成了PostgreSQL的服务器。
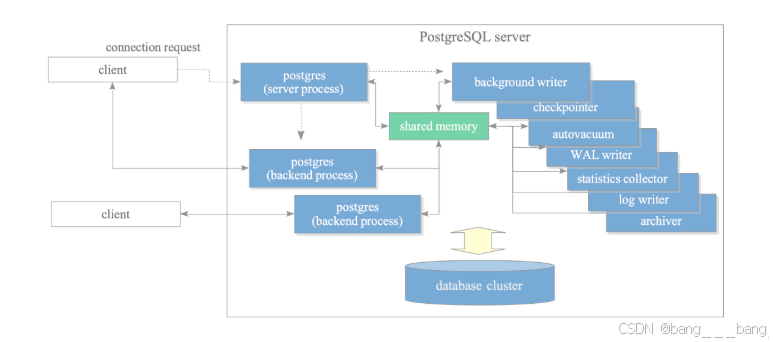 进程架构图
进程架构图
postgres服务器进程是PostgreSQL服务器中所有进程的父进程,在启动pg_ctl程序时带上start选项,postgres服务器进程,他会创建一个共享内存、各种后台进程、根据需要启动复制关联进程,接收到客户端请求时创建一个后端进程。
PostgreSQL本机没有连接池功能,面对postgres服务器进程被大量请求,开销会很大,通常使用中间件来解决。
🍙 内存架构
PostgreSQL的内存架构分为两种:
-
本地内存区域:每个后端进程backend process本地分配使用。
-
共享内存区域:PostgreSQL服务器所有进程一起使用。
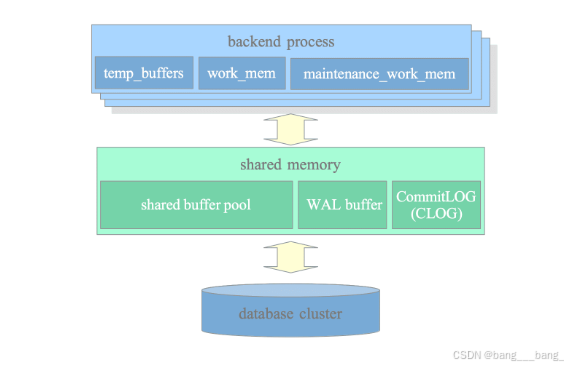 内存架构图
内存架构图
| 本地内存区域 | 作用 |
|---|---|
| temp_buffers | 执行器用来存储临时表 |
| work_mem | 使用order by/distinct操作对元组进行排序后使用hash-join或者merge-join连接表 |
| maintenance_work_mem | 某些类型的维护操作使用区域 |
| 共享内存区域 | 作用 |
|---|---|
| shared buffer pool | 将表和索引中的页面从持久存储加载到该区域并直接操作 |
| WAL buffer | WAL数据写入持久存储之前的缓冲区 |
| CommitLog | 提交日志保留并发控制的所有事务的状态 |
结语:本文开始剖析PostgreSQL的内幕,本篇主要介绍PostgreSQL中的集群、数据库、表是什么即他们的逻辑结构和实际的物理结构。同时介绍了堆表文件写入读取元组的方法,并简单讲解PostgreSQL的进程架构和内存架构。
参考文章:https://www.interdb.jp/pg/index.html
