0、下载DataX并解压到对应目录
DataX安装包,开箱即用,无需配置。
https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202308/datax.tar.gz
相关参考文档
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
1、Hive分区表DDL样例
注意分隔符号要和后续的DataX配置保持一致,同时在此将贴源层数据类型统一为String。
sql
CREATE TABLE datax.fin_transaction_flow (
transaction_id STRING COMMENT '交易唯一ID(主键)',
account_no STRING COMMENT '账户号(外键 -> account_info.account_no)',
transaction_code STRING COMMENT '交易类型编码(外键 -> transaction_reference.transaction_code)',
amount STRING COMMENT '交易金额(格式:整数部分18位,小数2位)',
currency STRING COMMENT '币种(如CNY/USD)',
counterparty_account STRING COMMENT '对手账户(外键 -> account_info.account_no)',
transaction_time STRING COMMENT '交易时间(格式:yyyy-MM-dd HH:mm:ss)',
status STRING COMMENT '交易状态(成功/失败)',
channel STRING COMMENT '交易渠道(ATM/网银)'
)
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\b'
STORED AS ORC ;2、DataX Json配置样例
创建以下Json文件(mysql-hive.json)并放置到DataX节点合适目录下。
json
{
"job": {
"setting": {
"speed": {
"channel": 4
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "pwd",
"connection": [
{
"querySql": [
"select transaction_id,account_no,transaction_code,amount,currency,counterparty_account,transaction_time,status,channel from fin_transaction_flow where dt='20250416';"
],
"jdbcUrl": [
"jdbc:mysql://chdp01:3306/bg2025"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://chdp01:9000",
"fileType": "orc",
"path": "/user/hive/warehouse/datax.db/fin_transaction_flow/dt=20250416",
"fileName": "xxxx",
"column": [
{
"name": "transaction_id",
"type": "STRING"
},
{
"name": "account_no",
"type": "STRING"
},
{
"name": "transaction_code",
"type": "STRING"
},
{
"name": "amount",
"type": "STRING"
},
{
"name": "currency",
"type": "STRING"
},
{
"name": "counterparty_account",
"type": "STRING"
},
{
"name": "transaction_time",
"type": "STRING"
},
{
"name": "status",
"type": "STRING"
},
{
"name": "channel",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": "\b",
"compress": "NONE"
}
}
}
]
}
}3、手动创建对应分区目录
shell
hadoop fs -mkdir /user/hive/warehouse/datax.db/fin_transaction_flow/dt=202504164、执行DataX
shell
./bin/datax.py ../mysql-hive.json看最终状态显示成功
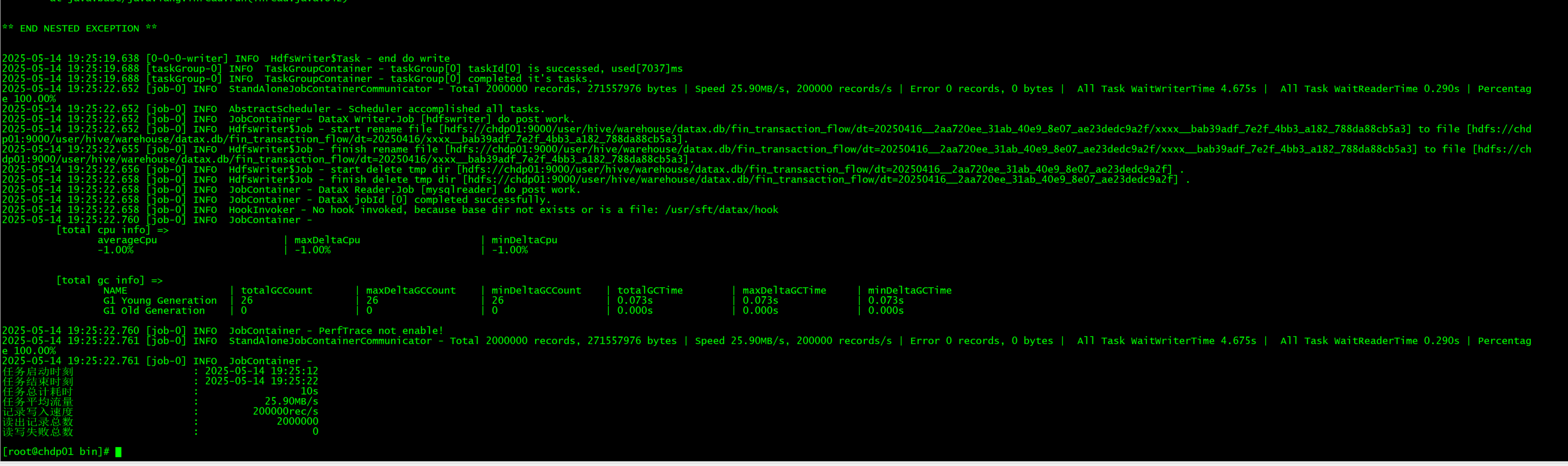
hdfs目标目录里也有了对应文件
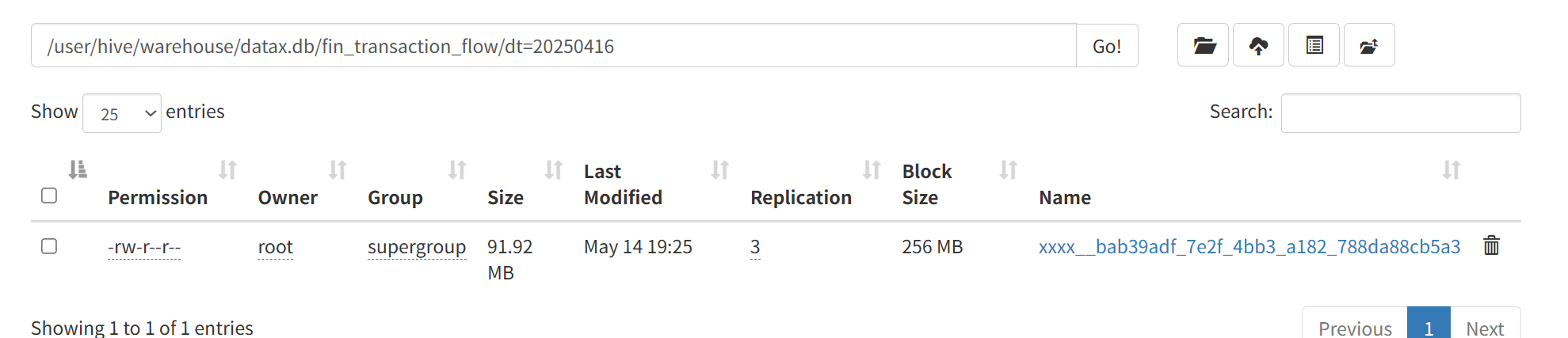
5、添加分区信息
经过上述操作还不能直接从hive表里查询出数据,因为元数据信息尚未构建起来。
ALTER TABLE datax.fin_transaction_flow ADD IF NOT EXISTS PARTITION (dt='20250416');6、验证数据

7、问题:发现count数据为0
sql
select count(*) from datax.fin_transaction_flow;这个是因为hive未及时构建表分析信息导致,手动执行如下表分析sql即可
sql
analyze table datax.fin_transaction_flow compute statistics;