写在前面
使用搜索引擎是我们经常做的事情,搜索引擎的实现原理。
什么是搜索引擎
搜索引擎是一种在线搜索工具,当用户在搜索框输入关键词时,搜索引擎就会将与该关键词相关的内容展示给用户。比较大型的搜索引擎有谷歌,百度,必应。
像我们嵌入在app里面的搜索,也是搜索引擎。只不过上面的搜索引擎是 搜全网 ,把全网的网站放到自己的数据库中,app里面的搜索一般只是站内信息的搜索。
搜索引擎的原理
相对成熟的搜索引擎工作原理可以分为爬虫、索引、排名三个步骤:
- 爬虫(Crawler):这是一种自动化程序,爬虫可以搜索网页并将找到的网页保存到搜索引擎的数据库中,以便进行索引。
- 索引(Indexing):索引是搜索引擎给每个网页分配一个关键字,以便搜索引擎能够快速地找到对应的网页。
- 排名(Ranking):排序是搜索引擎根据搜索结果进行打分排序,根据相关性的高低进行排名,以便用户能够找到最相关的网页。当然,一些搜索引擎偶尔也会在排名中穿插广告。
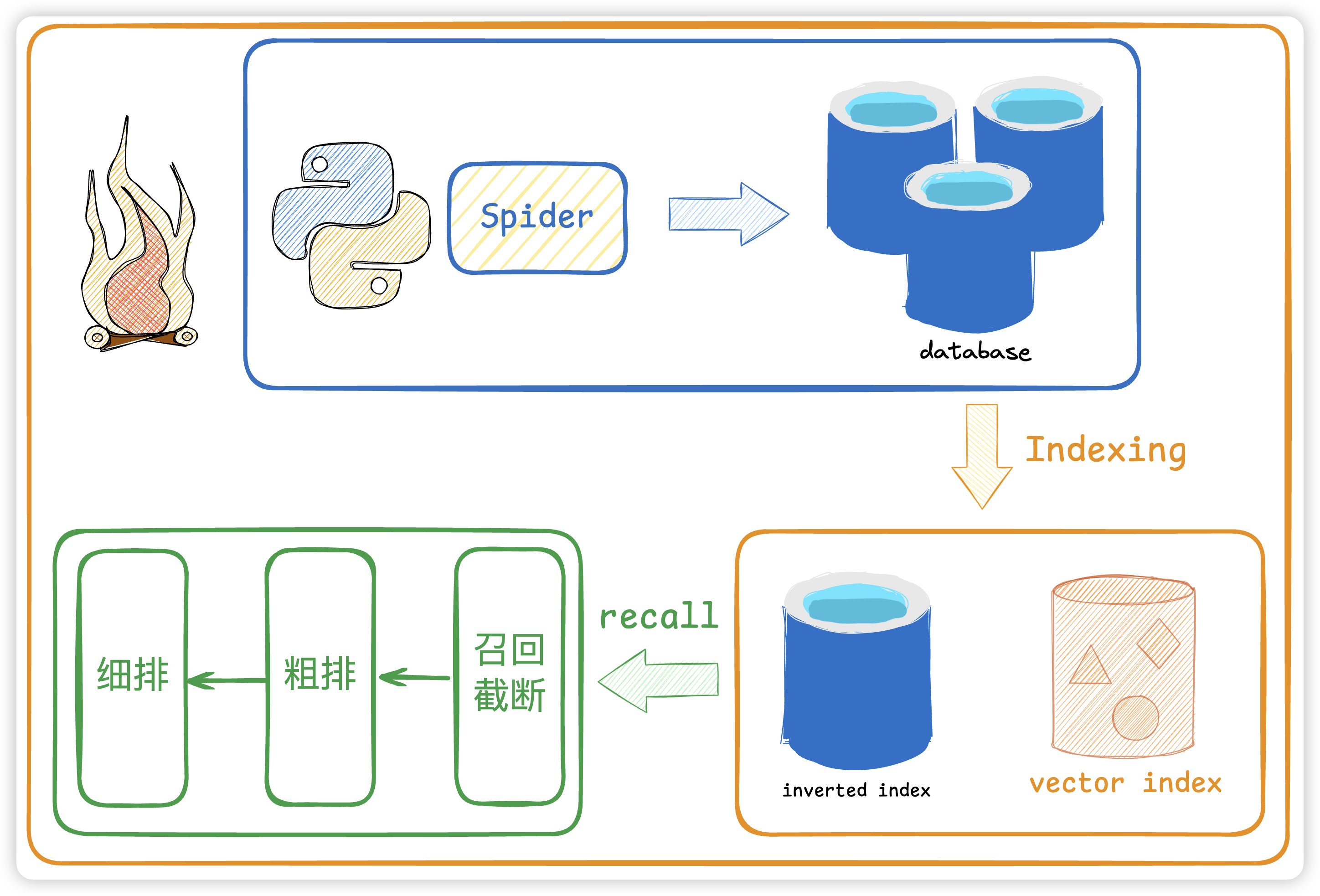
那么我们一点点来讲讲搜索引擎的这三个步骤。
爬虫
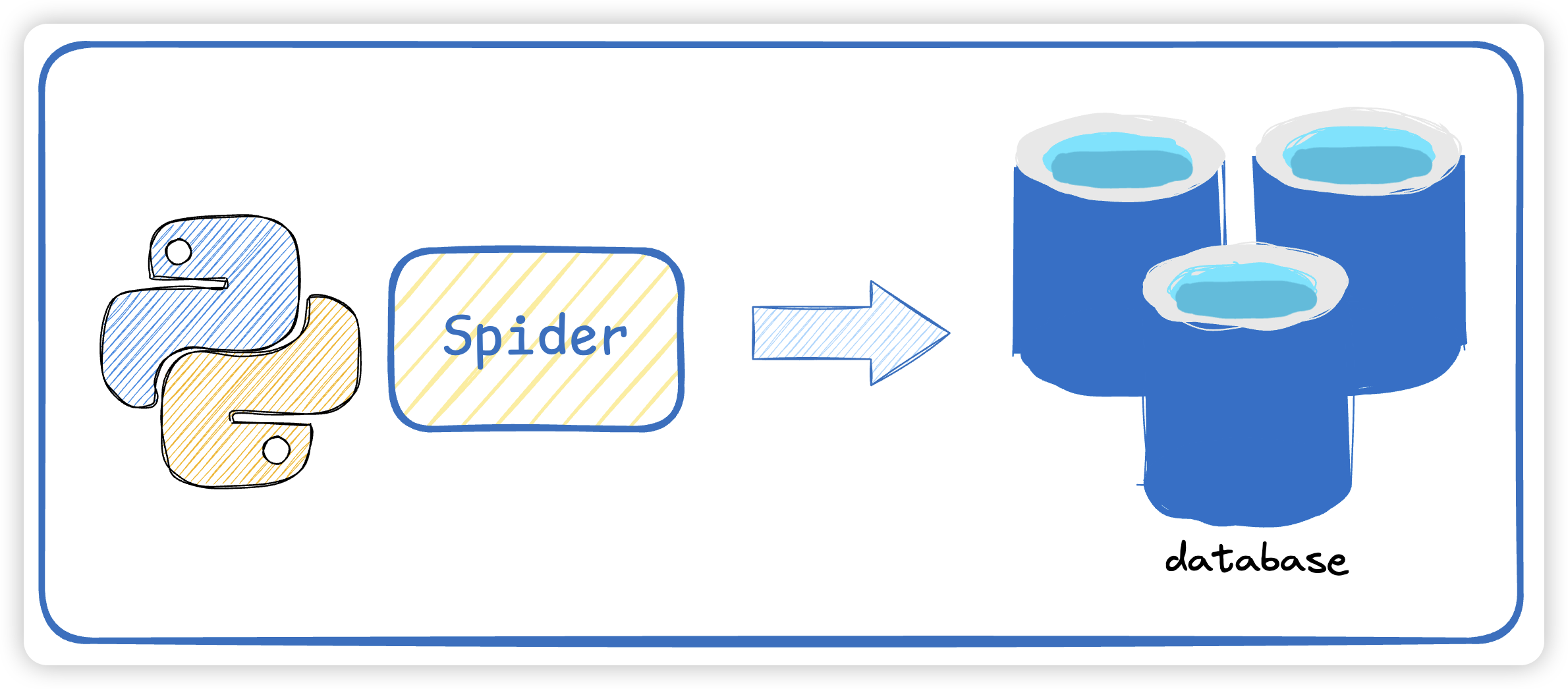
搜索引擎会派出一个抓取网页的代码程序用来发现新网页,通常被称为爬虫。这是一种自动抓取网络信息的程序,通过模拟人类访问网站的行为,自动访问网站,抓取网站上的信息,将抓取到的信息保存到数据库中。
首先,爬虫会从一个或多个指定的网址开始,然后根据程序设定的规则,从网页中抓取所需要的信息,并将抓取的信息保存到自己的数据库中。抓取的过程中,爬虫会不断地从网页中提取出新的网址,然后继续抓取,这一过程会一直持续下去,直到爬虫抓取到所有符合要求的信息为止。
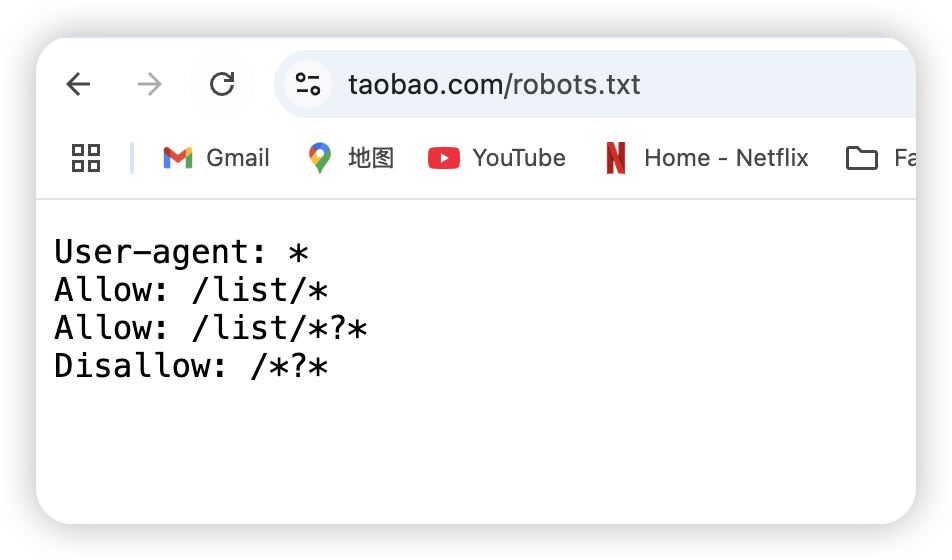
而爬虫会根据项目的robots.txt文件的内容来选择是否爬取该网站的信息。比如这个就是 B站 的 robots.txt。
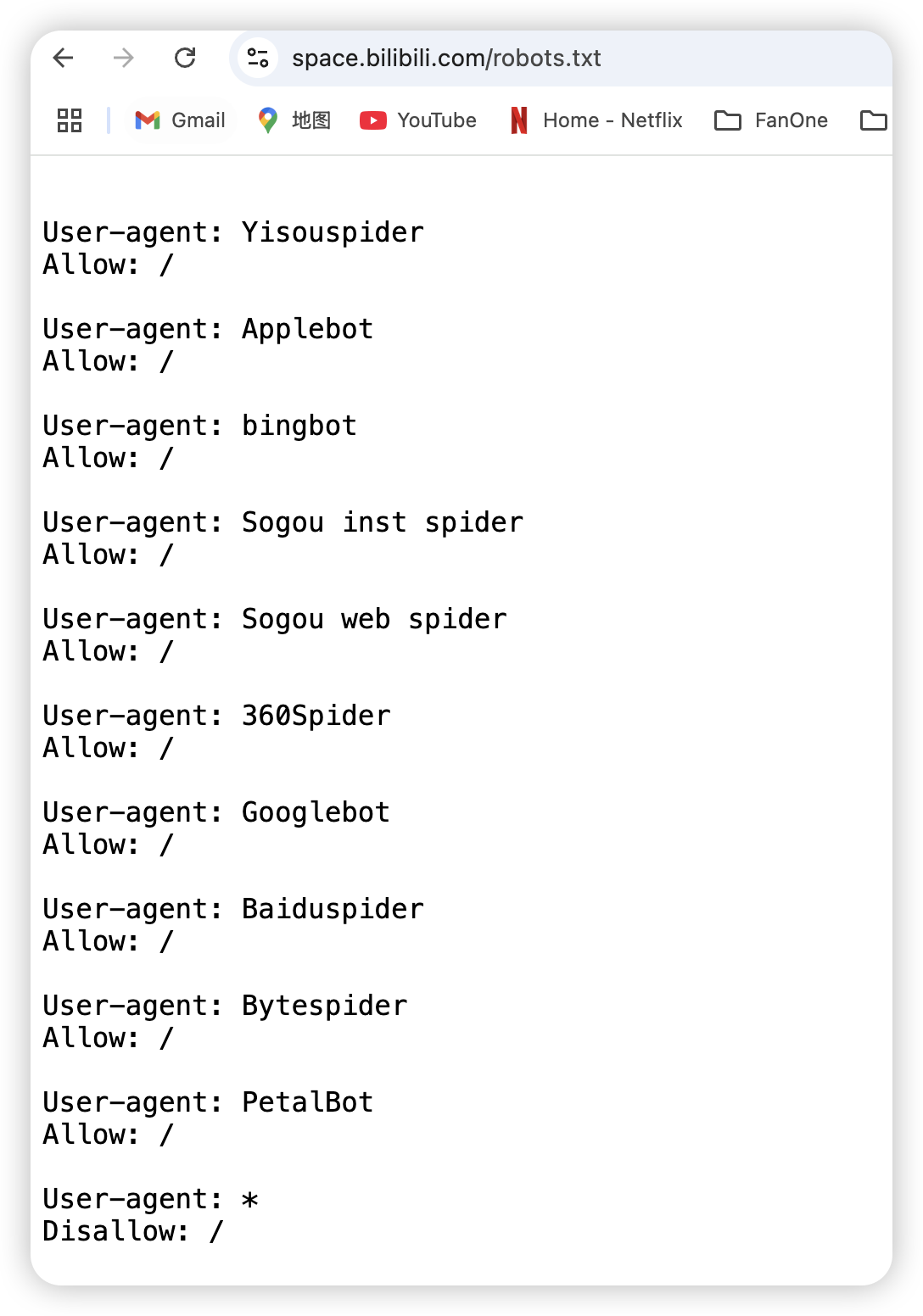
我们可以看到,b站的robots.txt 和其他网站的robots.txt 都是类似的,都希望自己的页面被各个搜索引擎的爬虫收录。一般的网站都希望被搜索引擎的爬虫访问,这样网站的流量入口就多了一个。
当然也有一些网站不希望自己被搜索引擎爬取,比如淘宝,这样大家只能在淘宝的网站搜索商品,而不能在其他入口搜索淘宝的商品。
看到这里,你可能会疑惑,搜索引擎不是全网搜索吗? 难道有些网站,还会出现在百度能搜出来,在其他搜索引擎就搜不出来情况?
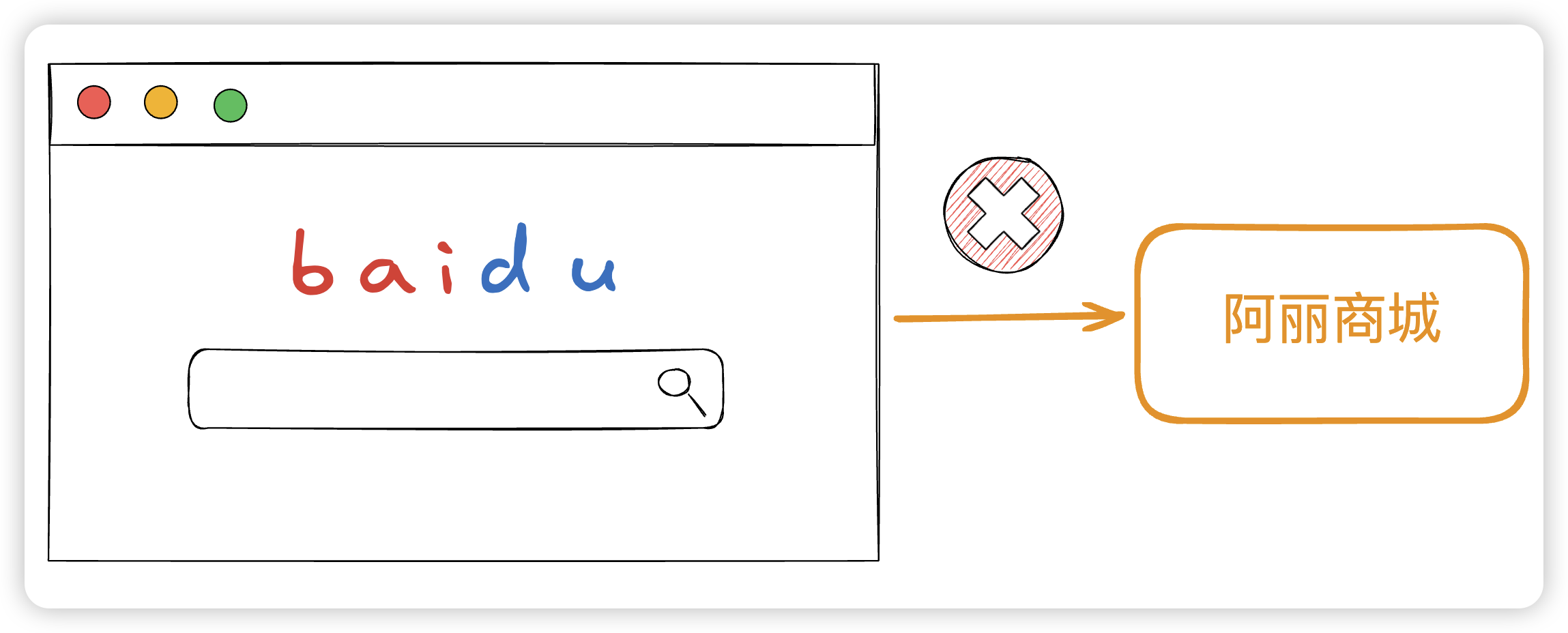
其实我们所谓的搜索引擎全网搜,这个全网是一个 伪全网 。我们进入百度的搜索引擎页面,其实我们进入了是百度这个网站,只是这个网站的爬虫收录了很多其他的网站,让你以为你是在全网
举个例子,我新上线了一个网站,就叫 "阿丽商城" ,我不想让我的网页被百度收录,那我就可以在 robots.txt 设置不让百度的爬虫爬去收录。这样当你百度 "阿丽商城" 的时候,在百度的网站上就没有任何 "阿丽商城" 的信息了。
索引
我们了解完爬虫之后,我们来讲讲索引。2025年全球的域名数量已经突破 3.68亿, 每个网站又有数不胜数的子页面,网页内容等等,再加上这个信息爆炸的时代,搜索引擎的数据库中已经收录了数以万亿级的网站信息,这时候,为了快速找到对应的网址,我们就要对这些网站信息建立索引。
索引一般分成正排索引和倒排索引:
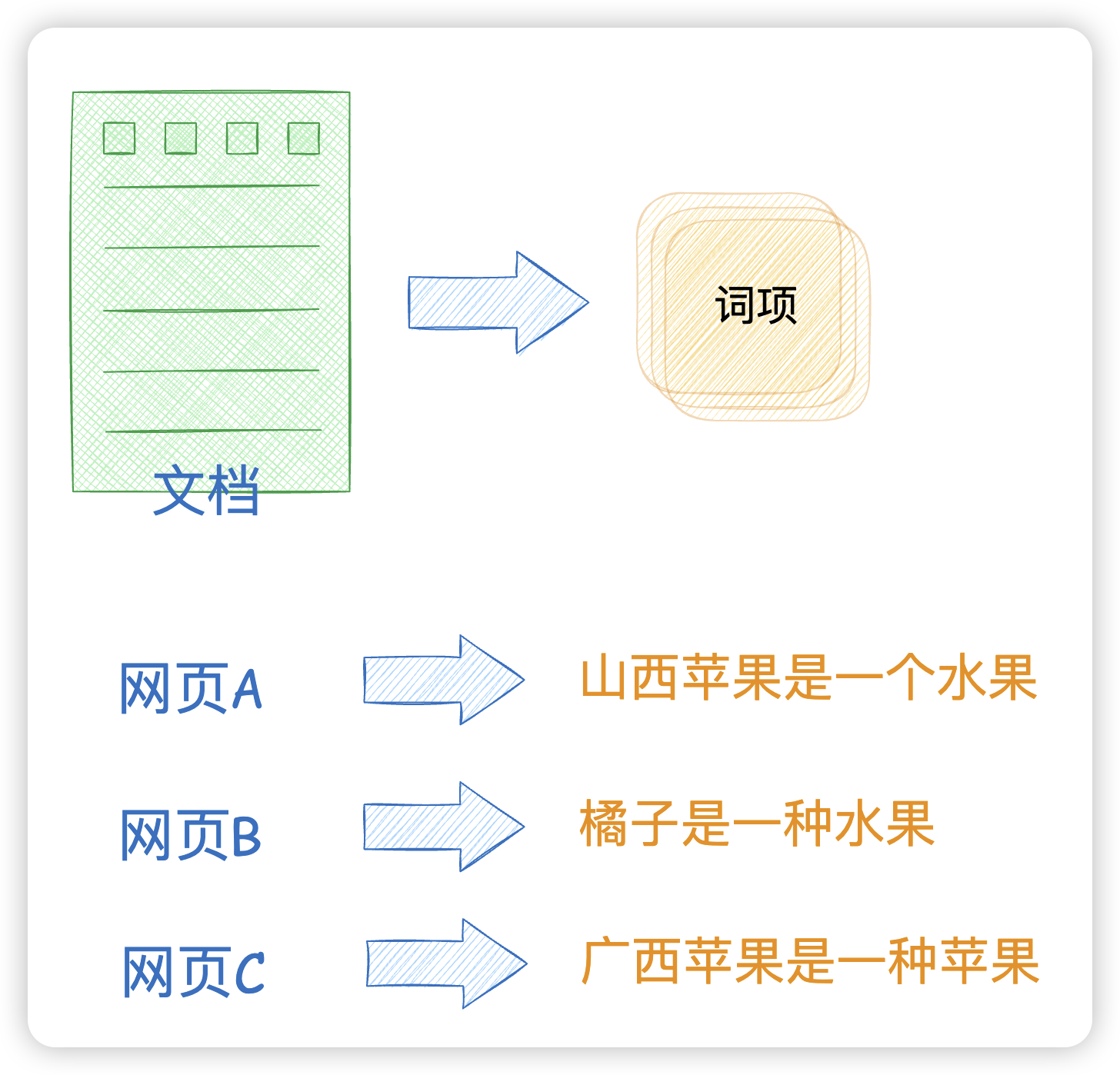
正排索引是一种"文档→词项"的索引结构,它按照文档的顺序存储每个文档中包含的词项。
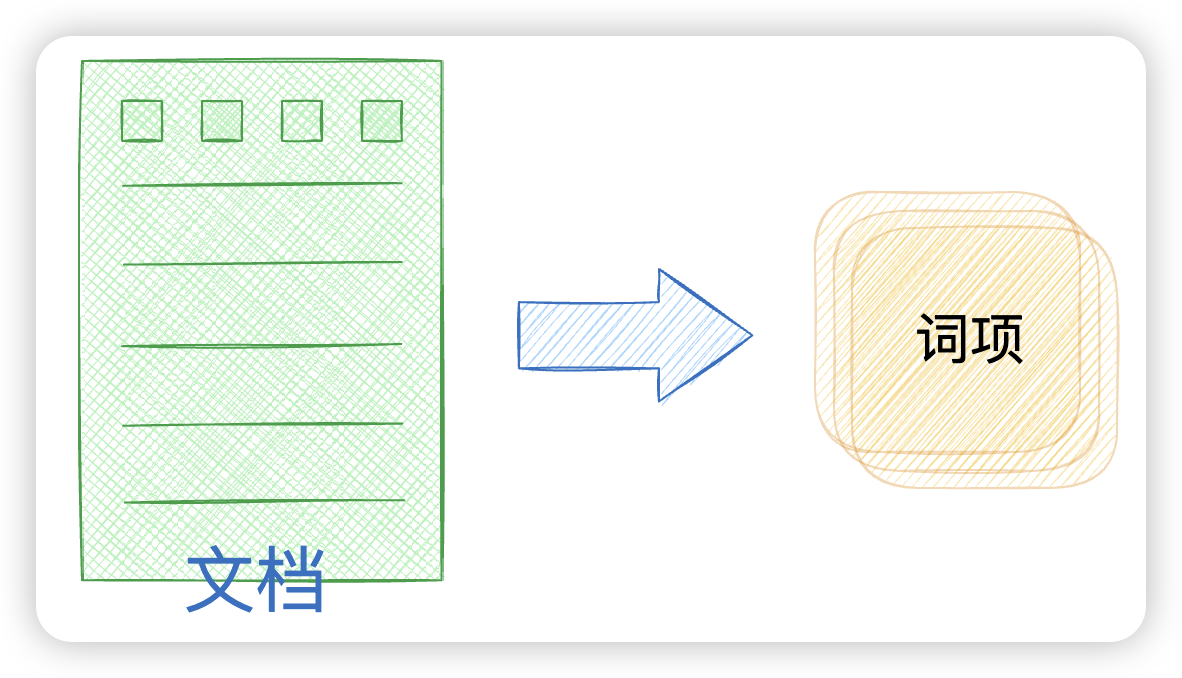
比如有一组网页
- 网页A:山西苹果是一种水果
- 网页B:橘子是一种水果
- 网页C:广西苹果是一种苹果
这样当你看到网页A,就知道山西苹果是一种水果的这个词项。
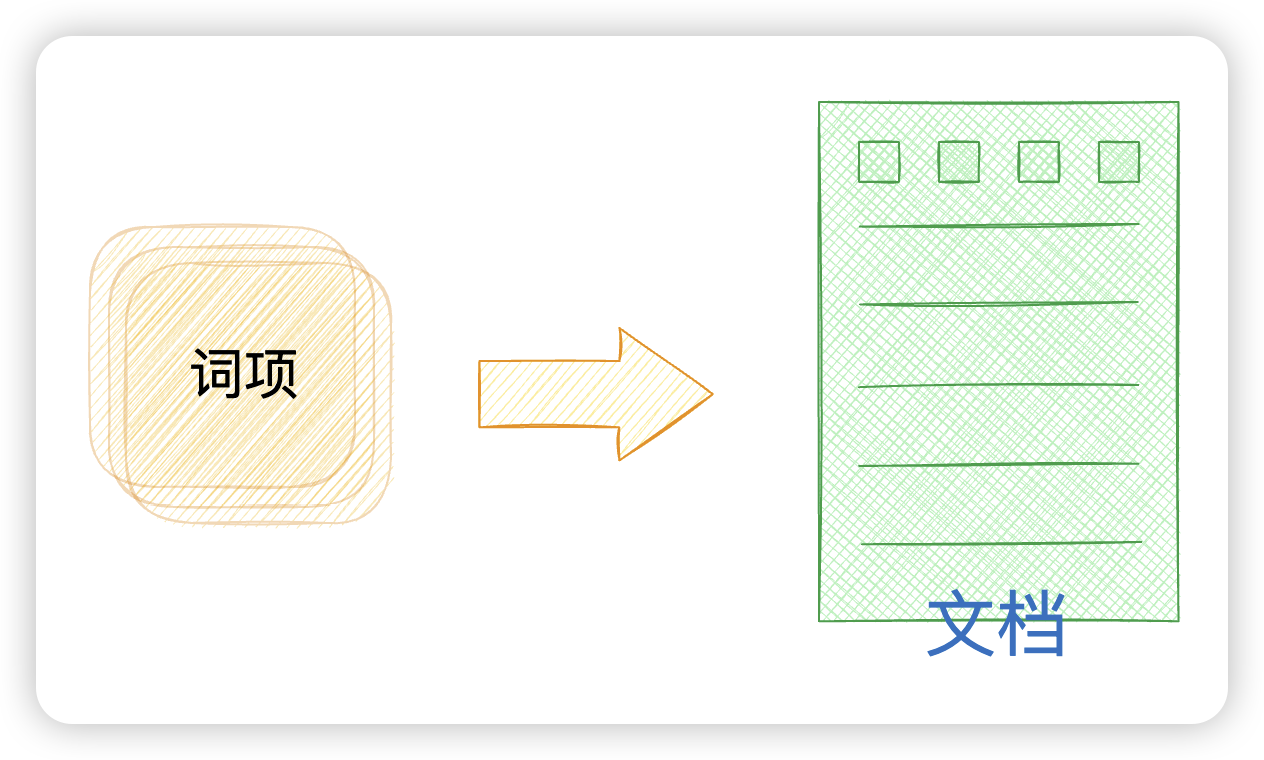
而搜索引擎一般是建立倒排索引,一种"词项→文档"的索引结构,记录每个词项出现在哪些文档中。
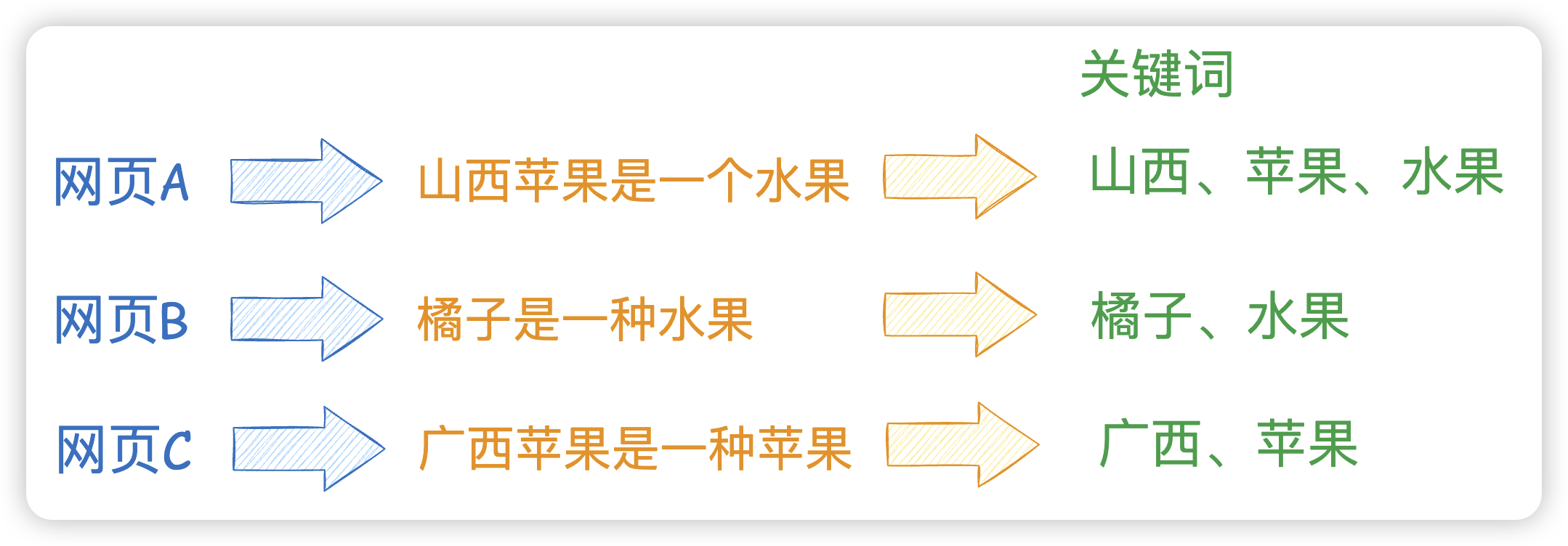
按照上面的例子建立倒排索引,那么就需要先提取关键词,还是上面的例子:
- 网页A:山西苹果是一种水果 -> 提取关键字
山西、苹果、水果 - 网页B:橘子是一种水果 -> 提取关键字
橘子、水果 - 网页C:广西苹果是一种苹果 -> 提取关键字
广西、苹果
倒排索引表如下:
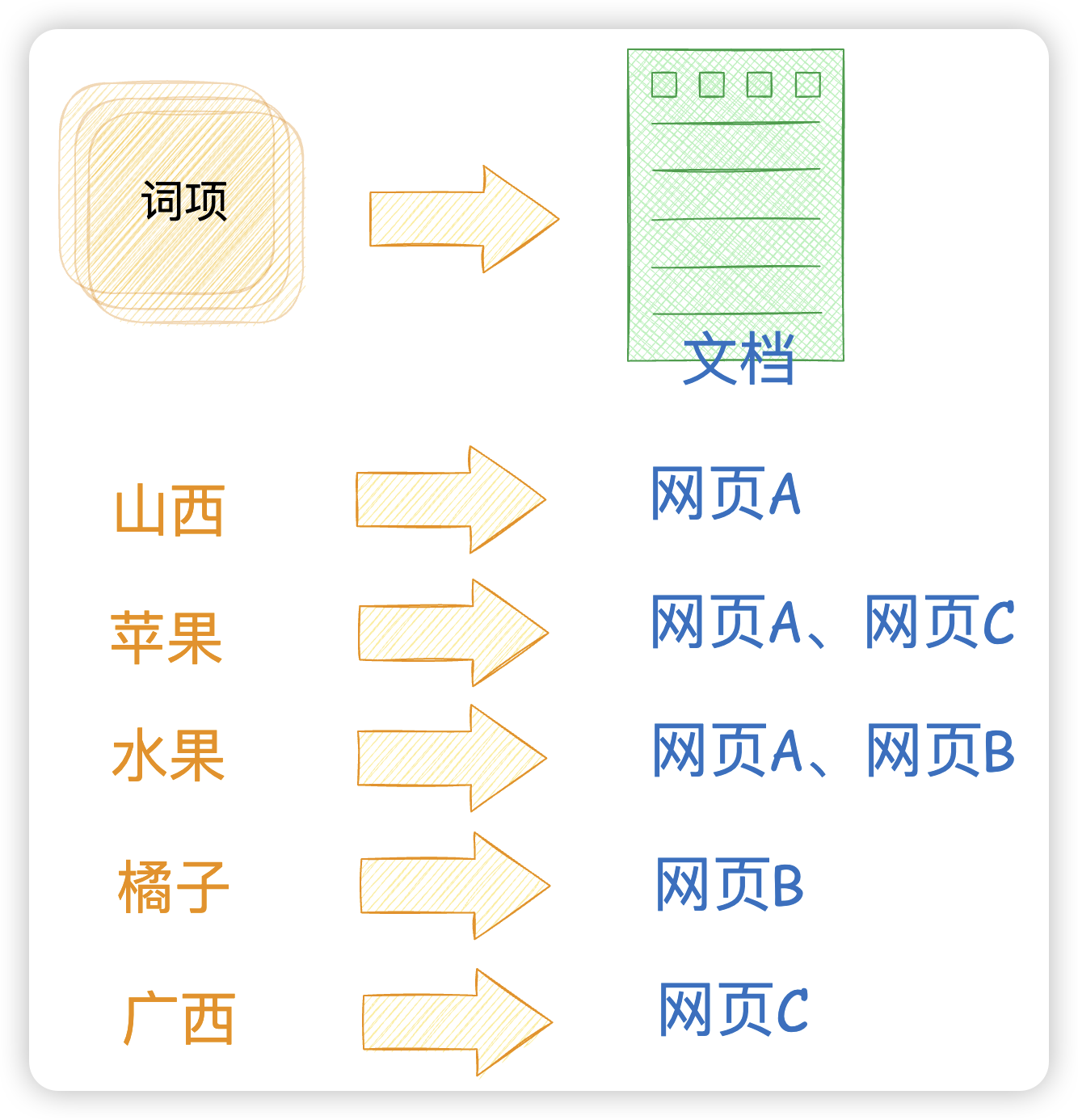
当我们搜索苹果的时候就会出现网页A和网页C,搜索水果的时候,就会出现网页A和网页B。
当然不仅只有倒排索引,还会有其他的索引结构,比如向量索引。当用户搜索的时候,会根据不同的索引数据源、不同的策略做召回,尽可能的召回多点数据,文本召回,向量召回,离线召回,这种叫多路召回。
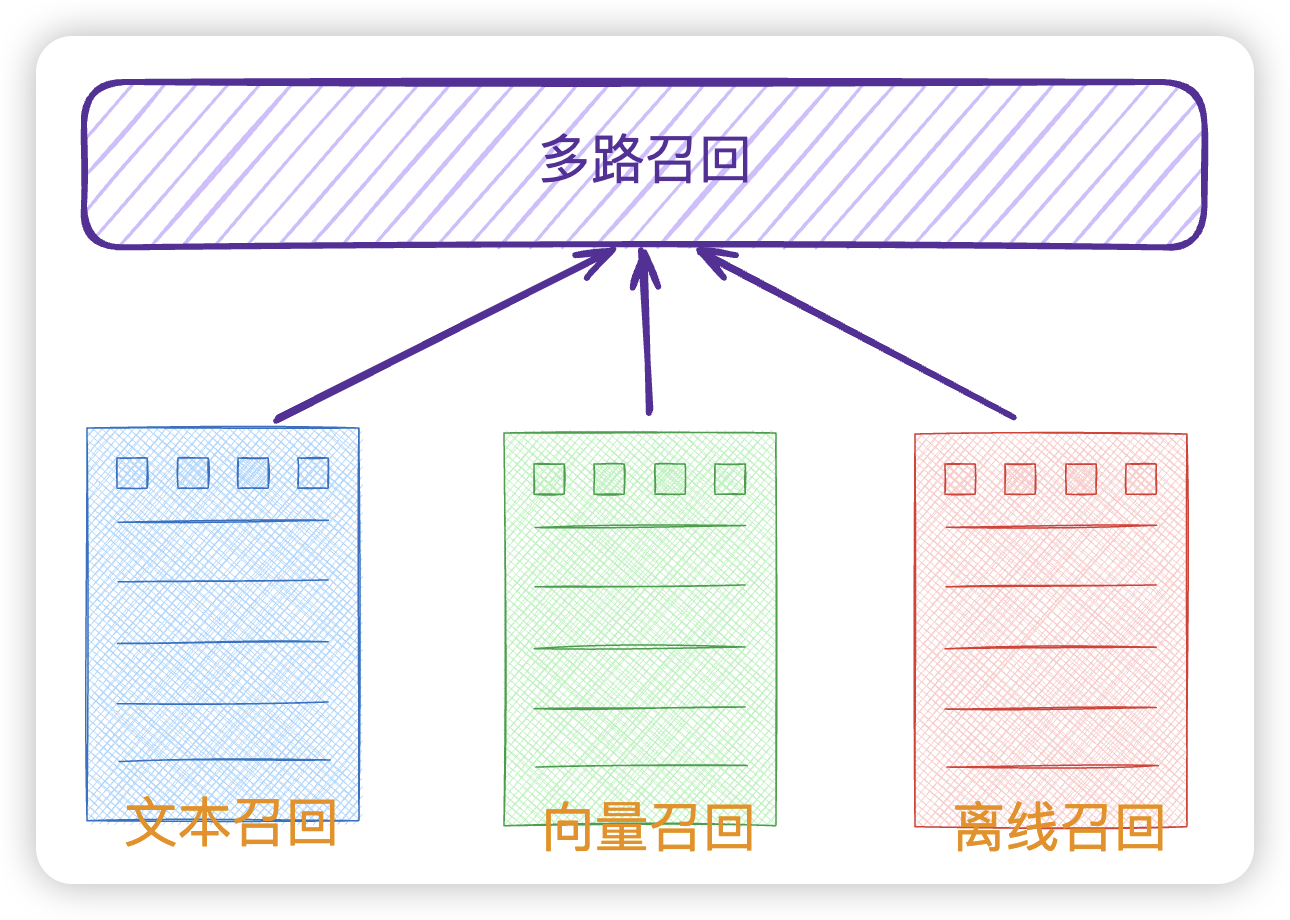
最近这两年,随着大模型的兴起,也开始有了生成式召回。
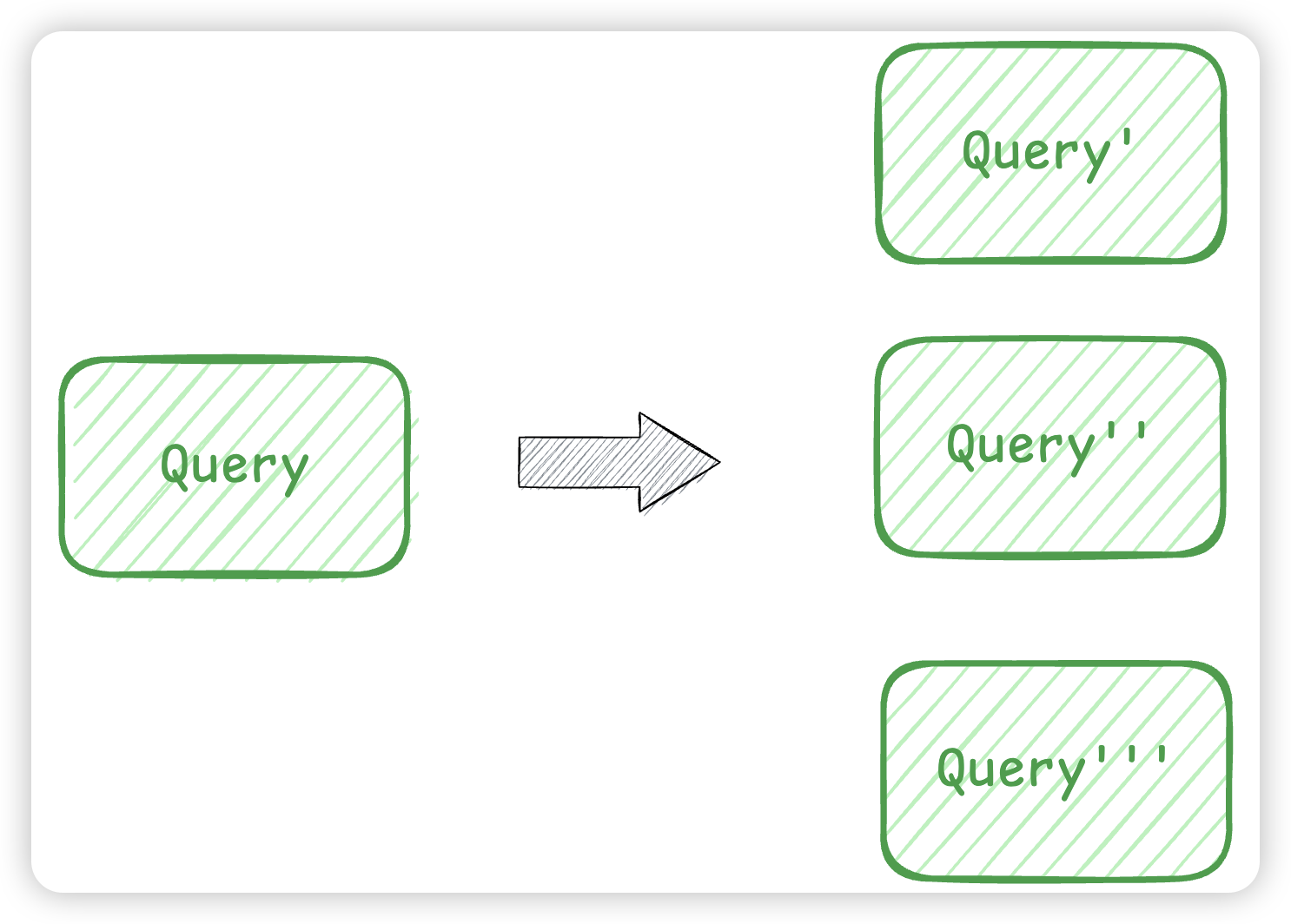
此外搜索引擎还会进行query搜索词改写,虽然向量召回能召回语义类似的词,但是文本召回不行。而query改写能提高我们的召回准确率:
- 扩展相关词,确保不遗漏重要结果,提高召回率,比如搜索"苹果CEO",改写成苹果公司CEO,TimCook
- 纠正错误查询,更精准匹配用户意图,提升准确率,比如苹里公司改写成苹果公司
- 即使查询不完美,也能得到理想结果,改善用户体验,搜索"附近火锅",会附带上了地点信息改写成xxx地点附近的火锅
接着问题出现了,我们召回成千上万个可能相关的网页,究竟是哪些网页出现在前面呢?这就涉及到了搜索引擎最后一个步骤,结果的计算排名。
排名
经过这么多年的发展,谷歌的页面排名规则已经非常复杂,但是没有人知道具体规则是什么。在召回尽可能多的数据之后,会进行召回截断、粗排、精排,这三种情况会呈现漏洞式削峰,从数万到数千、再到数百条数据,最后再次进行打分排序。
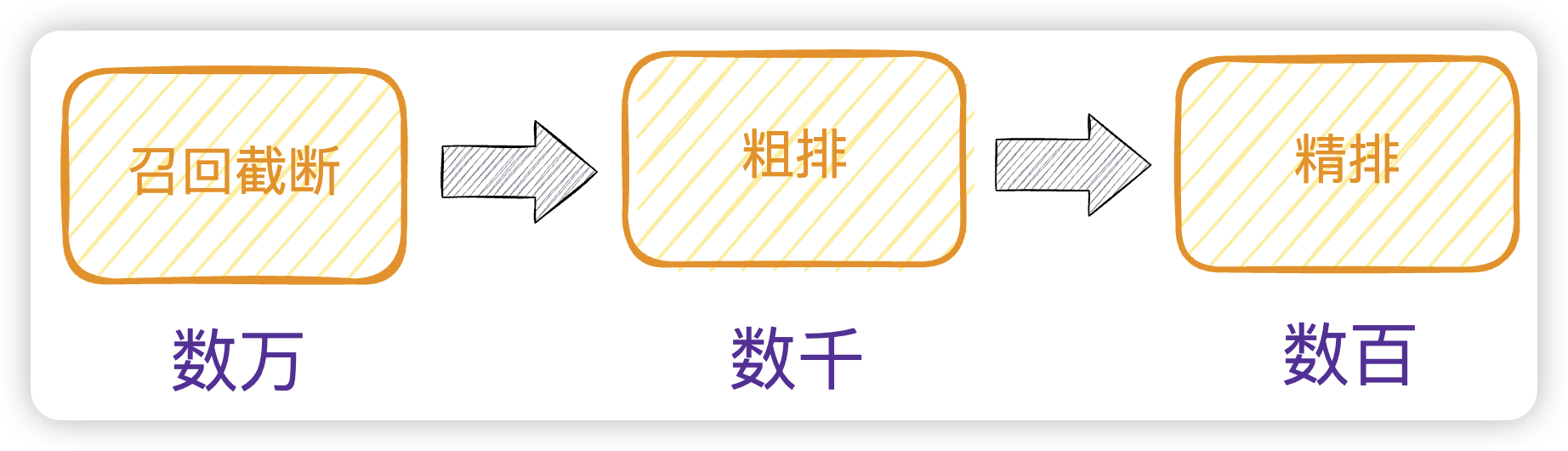
而点击率预估模型就是来做筛选的事情,这个模型顾名思义,预算估计每个召回网页的点击率会是多少,从而将点击率高的网页排在前面。
那么影响点击率的因素有哪些呢?
- 内容相关性: 页面标题与用户查询关键词的相关性,相关性越高的页面,排名就越靠前,也越能满足用户需求。
- 内容质量:
现在越来越提倡高质量内容输出了,也就是说哪怕你的内容相关性很高,但是其质量低下,也很难获得很好的排名。比如页面充斥了关键词堆砌、来源模糊的信息,重复度很高等。 - 链接权重: 链接主要有站内链接和站外链接两种,某种角度上来说,某个页面得到的链接越多,在一定程度上反映了该页面内容丰富,相对应的链接权重也就越高,比如
维基百科。 - 页面加载速度: 现在这年代,网页的加载速度越来越重要了,
每个人愿意在我们网页上停留的时间可能1秒都不到,这时候如果我们页面要过好几秒才能加载成功,用户可能早就不耐烦的关闭网页走人了。那我们前面做了那么多高质量的内容也就失去了意义。 - 竞价排名: 通过竞标方式与特定的关键词挂钩。广告金主针对某一关键词给出的竞标金额越高,当访问者以该关键词搜索时,该广告金主的网站排名越靠前。
当然排序规则远远不止上面说的这些,还有很多可能的规则,这里就不再一一列举。
参考文献
https://dmthought.com/search-engine-working-principle/