大语言模型的工业部署
- [0 前言](#0 前言)
- [1 ollama部署大模型](#1 ollama部署大模型)
-
- [1.1 ollama简介](#1.1 ollama简介)
- [1.2 ollama的安装](#1.2 ollama的安装)
- [1.3 启动ollama服务](#1.3 启动ollama服务)
- [1.4 下载模型](#1.4 下载模型)
- [1.5 通过API调用模型](#1.5 通过API调用模型)
- [2 vllm部署大模型](#2 vllm部署大模型)
-
- [2.1 vllm简介](#2.1 vllm简介)
- [2.2 vllm的安装](#2.2 vllm的安装)
- [2.3 启动vllm模型服务](#2.3 启动vllm模型服务)
- [2.4 API调用](#2.4 API调用)
- [3 LMDeploy部署大模型](#3 LMDeploy部署大模型)
-
- [3.1 LMDeploy简介](#3.1 LMDeploy简介)
- [3.2 LMDeploy的安装](#3.2 LMDeploy的安装)
- [3.3 启动 LMDeploy 模型服务](#3.3 启动 LMDeploy 模型服务)
- [3.4 API调用](#3.4 API调用)
- [4 使用streamlit+vllm部署模型](#4 使用streamlit+vllm部署模型)
- [5 总结](#5 总结)
0 前言
上篇文章讲了Llama3模型的简单部署,并且我们介绍了transformers调用大模型的通用格式,并且我们使用 streamlit 做了一个简易交互界面。但真实生产环境中,推理框架很少用transformers,这是因为该库的设计初衷是广泛兼容性和易用性,而不是专门针对特定硬件或大规模模型的性能优化。生产环境中主要用 vllm 和 LMDploy,另外,对于个人用户,ollama的使用也比较多,所以本文主要介绍这三种推理框架的使用。
1 ollama部署大模型
1.1 ollama简介
Ollama 是一个开源工具,旨在简化大型语言模型(LLMs)在本地计算机上的部署和运行。以下是其核心特点及功能的简要介绍:
核心功能
-
本地运行
允许用户在本地设备(如个人电脑)直接运行LLMs(如Meta的LLaMA、LLaMA 2等),无需依赖云服务,保障数据隐私并支持离线使用。
-
模型支持
• 提供预训练模型库,支持多种模型(如LLaMA 2、Mistral、Gemma等)及不同参数量版本(如7B、13B)。
• 通过简单命令(如
ollama run llama2)即可下载和运行模型,类似Docker镜像管理。 -
跨平台兼容性
支持主流操作系统(Windows、macOS、Linux),并利用硬件加速(如CUDA、Metal)优化性能,提升推理速度。
-
用户友好性
主要提供命令行接口(CLI),简化模型交互流程。部分第三方工具(如Open WebUI)可扩展图形界面。
技术特点
• 量化优化:采用4位量化等技术减少模型内存占用,使其能在消费级硬件(如普通GPU/CPU)上流畅运行。
• 灵活扩展:支持导入自定义模型或适配Hugging Face等平台的模型,满足进阶开发需求。
使用场景
• 开发者测试:本地快速部署模型,进行原型开发或调试。
• 隐私敏感场景:处理敏感数据时避免依赖云端服务。
• 教育与研究:无网络环境下进行模型实验或教学演示。
与类似工具对比
相较于llama.cpp(专注于高效推理)或Hugging Face Transformers(需更多配置),Ollama强调开箱即用,降低使用门槛,适合非专业用户。
1.2 ollama的安装
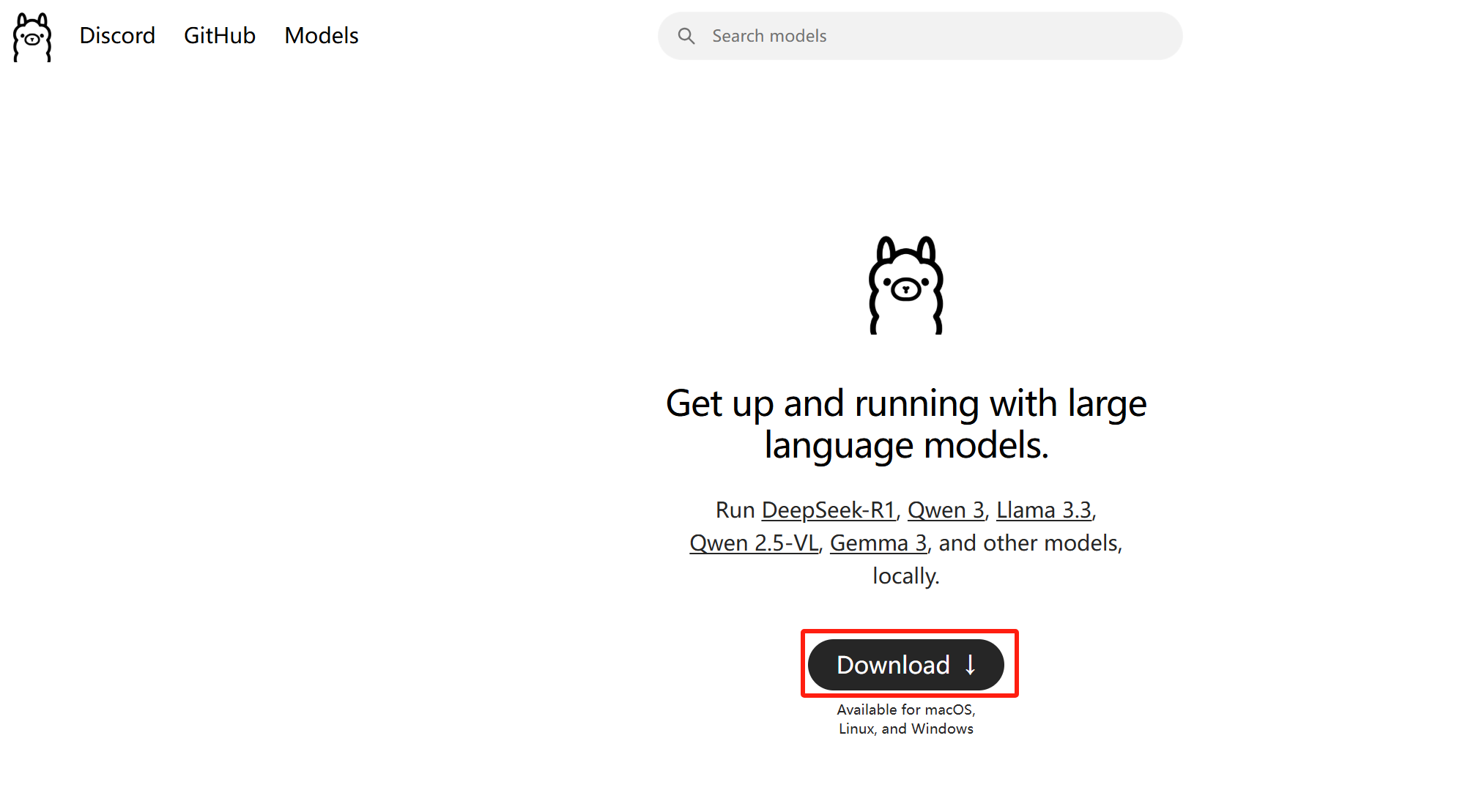
进入ollama官网,点击Download:
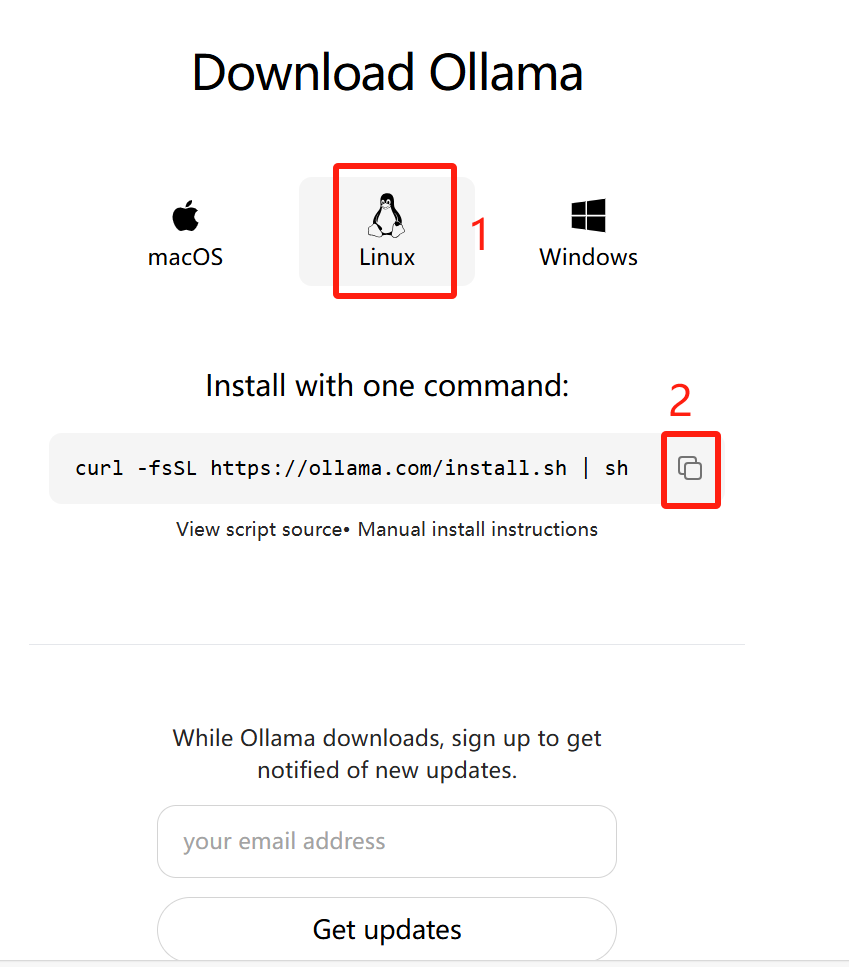
点击Linux,并获取安装命令
在服务器中新建一个conda环境,名字为ollama,此环境专门用于ollama推理:conda create -n ollama python==3.12
环境创建后,激活该环境,输入刚刚复制的安装指令安装,即:
bash
curl -fsSL https://ollama.com/install.sh | sh国内用户这一步经常会因为网络问题而安装失败,这一步在魔搭平台中有解决方案:
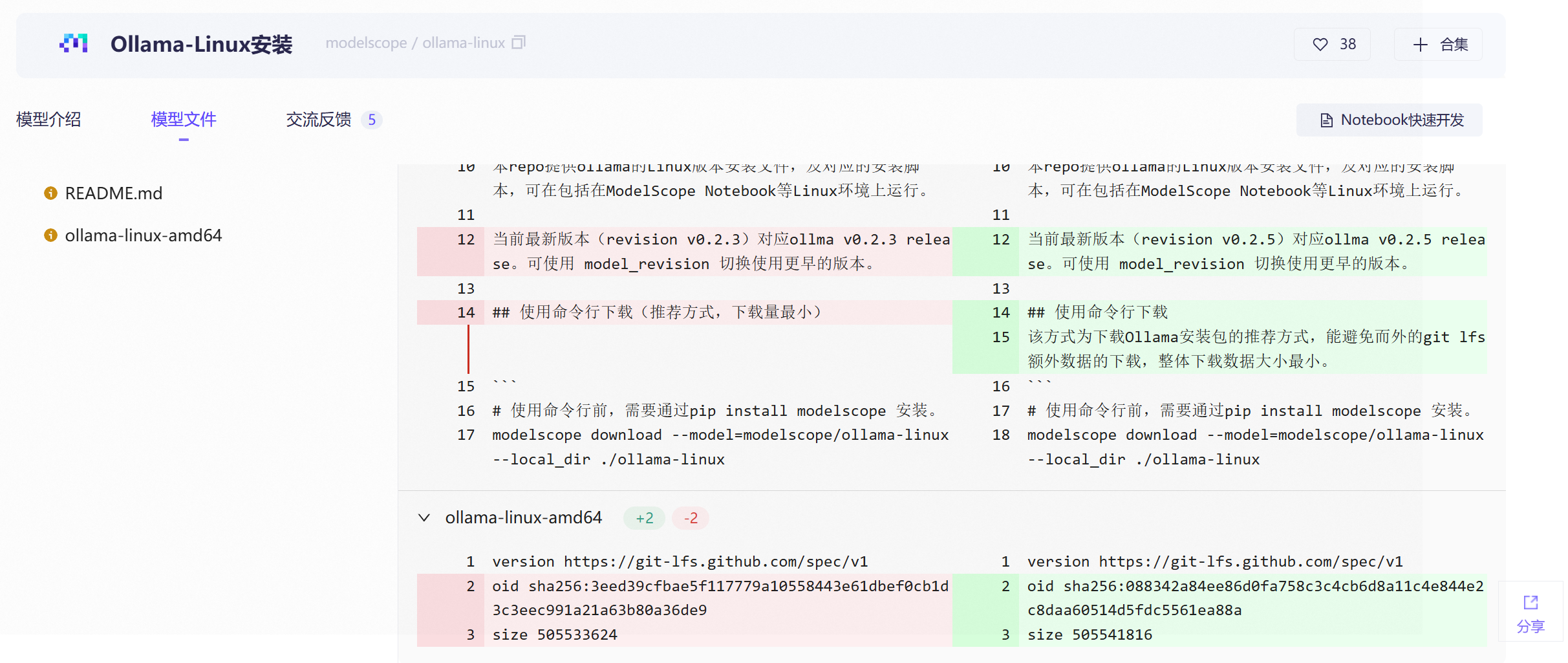
其实就是两条命令:
bash
pip install modelscope
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux以上命令执行后,ollama的安装文件将改从魔搭平台下载。
接下来是安装,执行下面两条命令:
bash
cd ollama-linux/
sh ollama-linux/ollama-modelscope-install.sh若出现以下信息,则说明安装成功:

如果直接使用官网的安装教程安装ollama,那么通过 ollama run 命令从ollama官网中下载的模型会保存在/usr/share/ollama/.ollama/models中。
如果是从魔搭平台下载安装文件进行安装(即替代方案),则通过 ollama run 命令从ollama官网中下载的模型保存在~/.ollama/models中,最好重新设置模型保存路径。依次输入下面两条命令,修改保存路径:
bash
echo 'export OLLAMA_MODELS="/data/coding/model_weights/ollama/models"' >> ~/.bashrc # 修改成你想保存的路径
source ~/.bashrc1.3 启动ollama服务
只有开启服务后,才能下载并部署模型
bash
ollama serve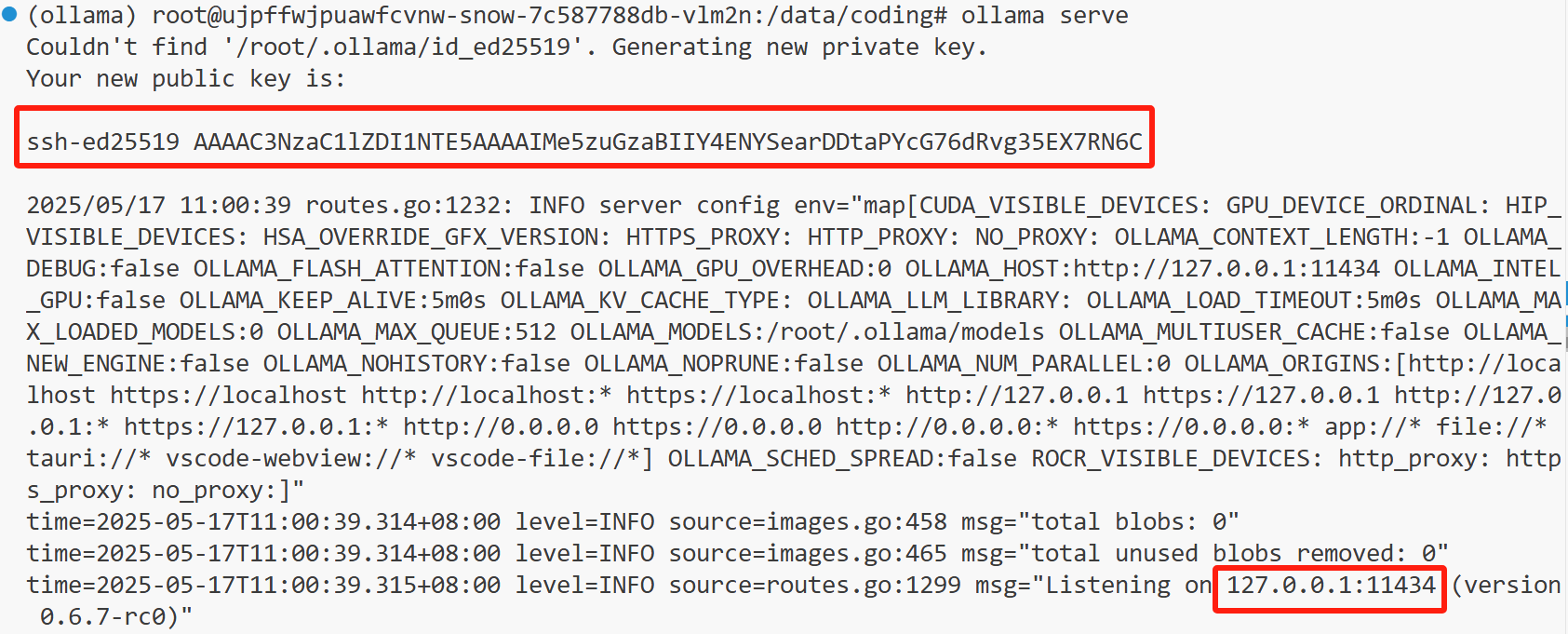
我们可以看到API Key,还有地址与端口号。
1.4 下载模型
ollama只能运行经过GGUF量化后的模型,相对于原模型效果略差。首次运行模型,如果本地没有,那么会从ollama官网拉取模型文件到本地。
在ollama主页中搜索模型名并按回车,我们这里输入qwen3(之所以不用llama3,是因为llama3最小的都是8B,llama3.2最小的是1B,下载起来很慢,而qwen3最小的是0.6B):
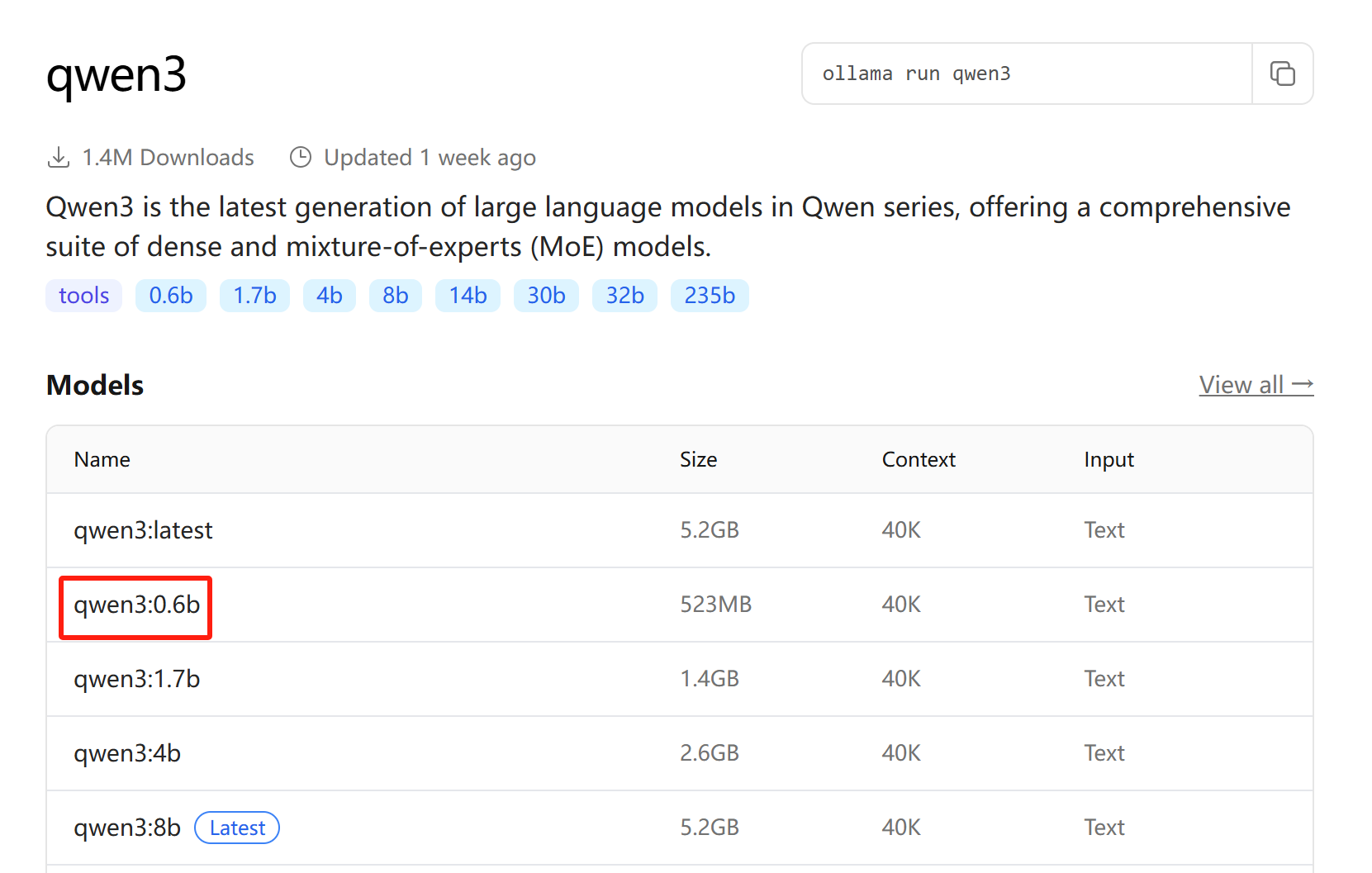
点击 qwen3:0.6b
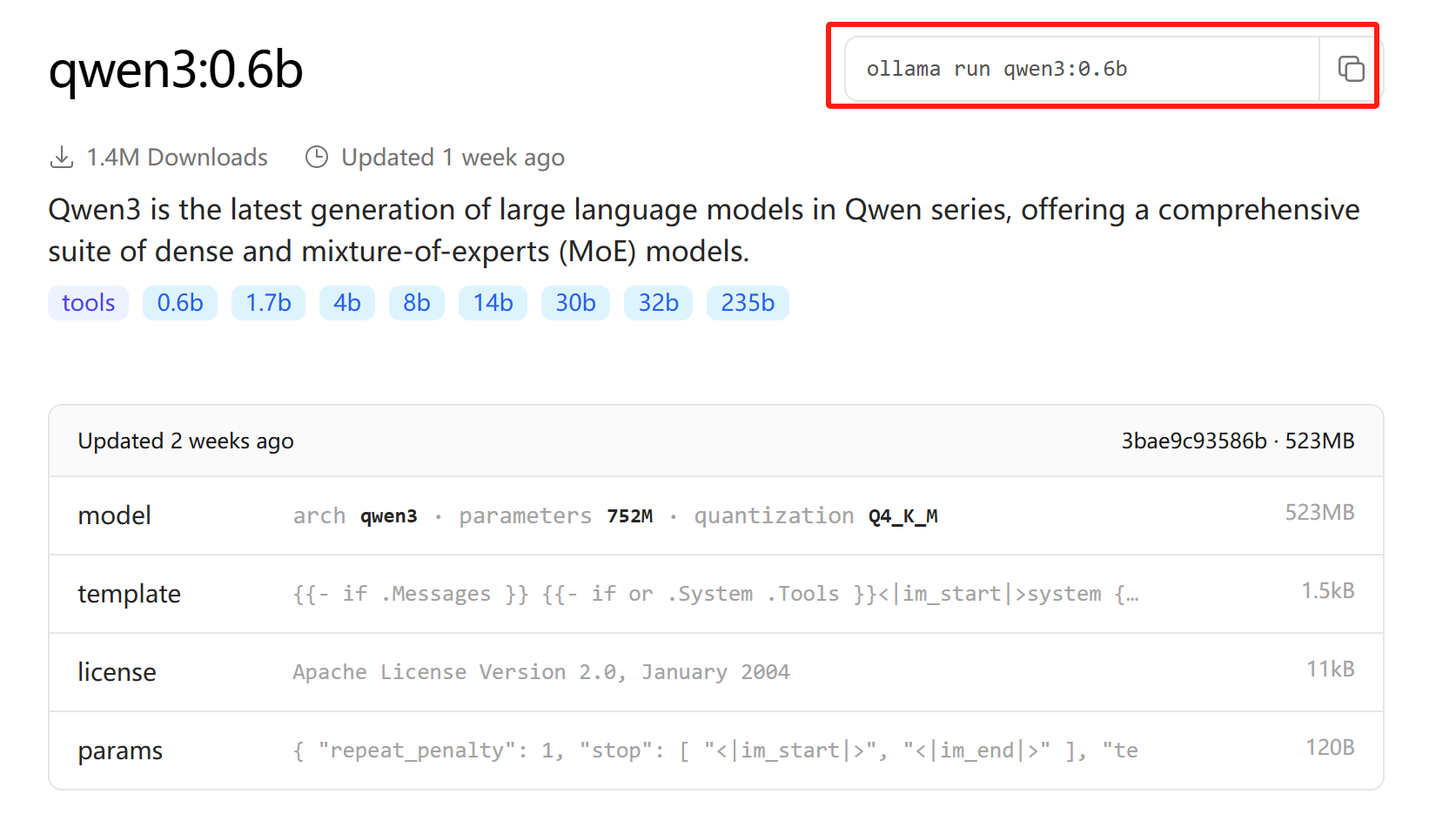
新建一个终端,并激活ollama环境,随后复制右上角的模型运行命令,即:
bash
ollama run qwen3:0.6b拉取完模型后(下载速度不用担心,在国内下载速度是可以的),会出现简单的交互界面:

可以看到,qwen3已经像deepseek一样,具有了深度思考大的功能。输入Ctrl + d 或者 /bye 退出交互界面。
可以在我们设置的路径下找到模型文件:
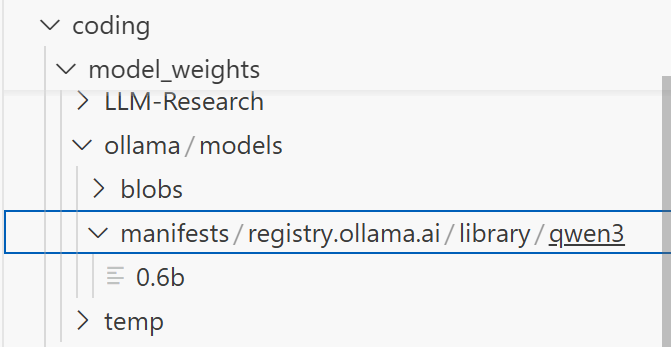
可以在终端输入 ollama list 查看能调用的模型,我这里输入的结果是:
bash
NAME ID SIZE MODIFIED
qwen3:0.6b 3bae9c93586b 522 MB 48 minutes ago 1.5 通过API调用模型
启动服务的那一步,我们可以拿到API Key以及模型地址,接下来我们用OpenAI API 的风格调用模型。在此之前,需要安装OpenAI:
bash
pip install openai新建一个名为 ollama_test.py 的程序文件,内容如下:
python
#多轮对话
from openai import OpenAI
#定义多轮对话方法
def run_chat_session():
#初始化客户端
client = OpenAI(base_url="http://localhost:11434/v1/", # /v1表示调用为OpenAI风格设计的接口
api_key="AAAA" # 调用本机的服务,api_key可以随便写
)
#初始化对话历史
chat_history = []
#启动对话循环
while True:
#获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
#更新对话历史(添加用户输入)
chat_history.append({"role":"user","content":user_input})
#调用模型回答
try:
chat_complition = client.chat.completions.create(messages=chat_history,model="qwen3:0.6b") # model只需要置为模型名就行
#获取最新回答
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
#更新对话历史(添加AI模型的回复)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()Ollama 服务端在启动时,会监听多个路径:/api,原生 Ollama API(如生成、拉取模型);/v1:专为兼容 OpenAI API 设计的接口。
Ollama 的 OpenAI 风格接口仅在 /v1 路径下实现,因此 base_url="http://localhost:11434/v1/" 的 /v1 用于标识 OpenAI API 接口版本,这样可以保持原生 API 和 OpenAI 风格 API 的路径分离,避免冲突。
此外,由于调用本机的服务,无需真实密钥,密钥可以随便写,但不能没有。
在终端输入(以下命令无需在ollama环境中运行):
bash
ollama_test.py终端结果如下:

按Ctrl+C退出交互。
从上面的结果可以看到,qwen3:0.6b 的多轮对话能力不行,记不住前面回答的内容,一方面是模型太小,只有0.6b,另一方面是模型经过量化,效果变差。
2 vllm部署大模型
2.1 vllm简介
vLLM 是一个快速且易于使用的库,用于 LLM 推理和服务。vLLM 最初在加州大学伯克利分校的 Sky Computing Lab 开发,现已发展成为一个社区驱动的项目,汇集了学术界和工业界的贡献。
vLLM 速度快,具有:
- 最先进的服务吞吐量
- 使用 PagedAttention 高效管理注意力键和值内存
- 持续批处理传入请求
- 使用 CUDA/HIP 图快速模型执行
- 量化:GPTQ, AWQ, INT4, INT8 和 FP8
- 优化的 CUDA 内核,包括与 FlashAttention 和 FlashInfer 的集成。
- 推测解码
- 分块预填充
vLLM 灵活且易于使用,具有:
- 与流行的 HuggingFace 模型无缝集成(ollama只能调用GUFF模型)
- 使用各种解码算法(包括并行采样、束搜索等)实现高吞吐量服务
- 张量并行和流水线并行支持分布式推理
- 流式输出
- OpenAI 兼容的 API 服务器
- 支持 NVIDIA GPU、AMD CPU 和 GPU、Intel CPU、Gaudi® 加速器和 GPU、IBM Power CPU、TPU 以及 AWS Trainium 和 Inferentia 加速器。
- 前缀缓存支持
- Multi-LoRA 支持
vllm有专门的中文文档。
2.2 vllm的安装
vllm目前只能在Linux系统安装,安装vllm的硬件环境,必须是算力不低于7.0的GPU,像P40、P100显卡就没法用(其实也可以,但比较麻烦,需要自己编译),CPU虽然也能装,但vllm一般是用于企业级用户,CPU无法满足算力要求。
不要在base环境中安装vllm,因为安装的时候,会安装与vllm配套的CUDA,如果原有的CUDA与vllm不匹配,则会卸载原有的CUDA,从而重新安装PyTorch,这样影响很大。
我们这里和ollama类似,新建一个环境,专门使用vllm部署:
bash
conda create -n vllm1 python=3.12 # 我在新建环境时,环境名后面多敲了个1然后安装vllm:
bash
pip install vllm安装的时候,会把相关的依赖也安装好,包括最新版本的 PyTorch。因为安装的依赖比较多,为了加速,最好把pip的镜像切换回国内的镜像源,例如可以用清华源:
bash
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple2.3 启动vllm模型服务
终端输入:
bash
vllm serve model_weights/LLM-Research/Meta-Llama-3-8B-Instruct其实就是 vllm serve 加 模型路径。
出现以下信息,说明服务启动成功:
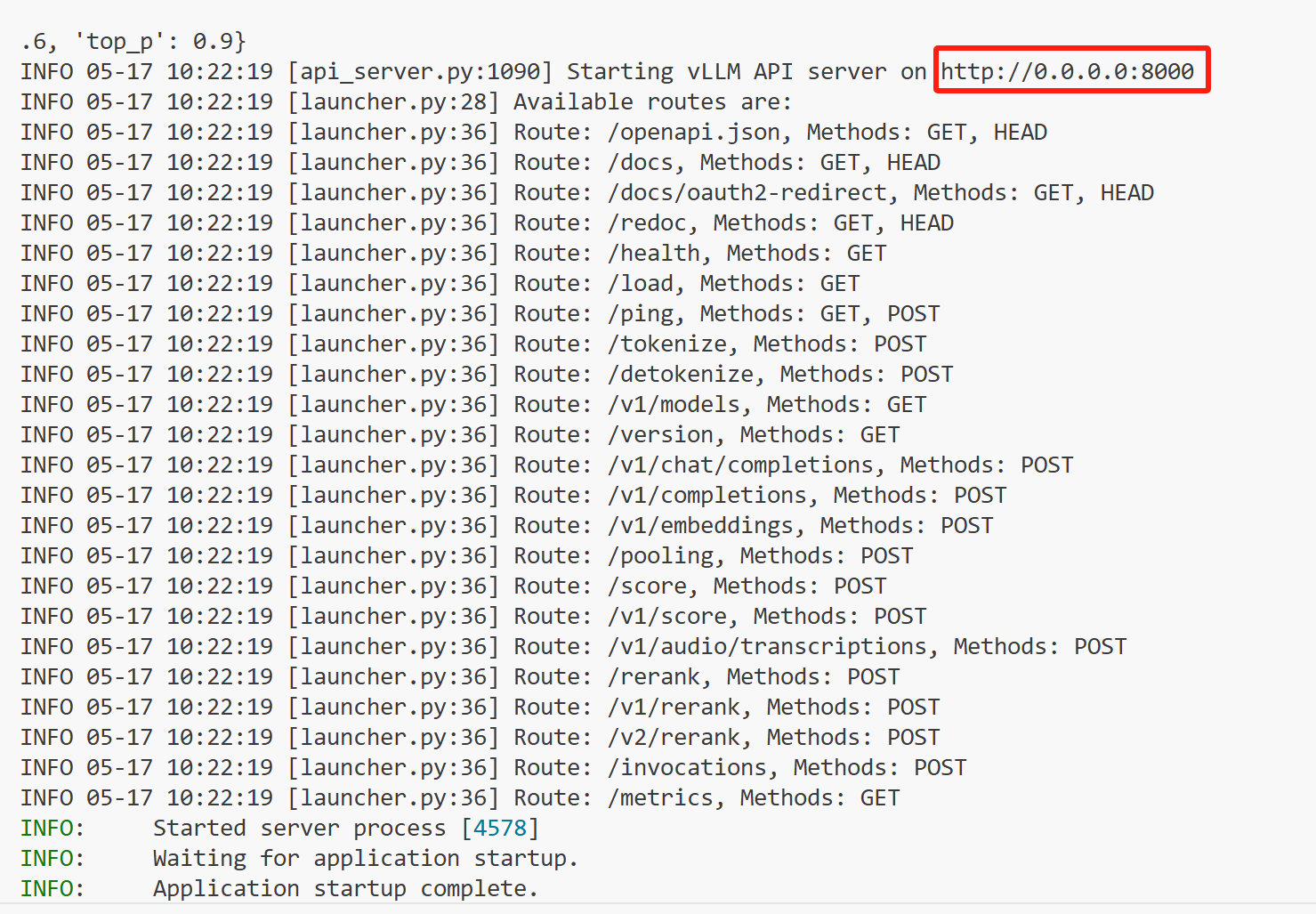
从上面的信息可以看到服务的路径和端口号。
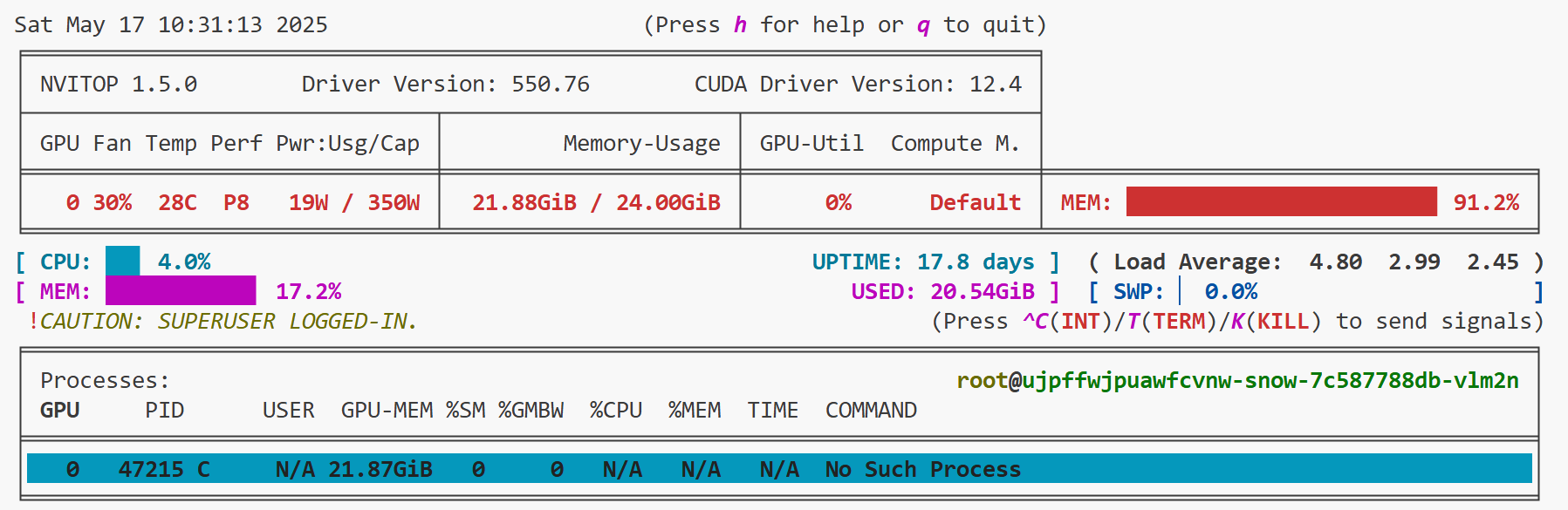
此时我们可以新建一个端口,输入nvitop查看显存使用情况:
2.4 API调用
新建一个名为 test03.py 的代码文件,内容如下:
python
#多轮对话
from openai import OpenAI
#定义多轮对话方法
def run_chat_session():
#初始化客户端
client = OpenAI(base_url="http://localhost:8000/v1/",api_key="suibianxie") # 在本地调用,api_key可以任意,但不能没有
#初始化对话历史
chat_history = []
#启动对话循环
while True:
#获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
#更新对话历史(添加用户输入)
chat_history.append({"role":"user","content":user_input})
#调用模型回答
try:
chat_complition = client.chat.completions.create(messages=chat_history,model="model_weights/LLM-Research/Meta-Llama-3-8B-Instruct")
#获取最新回答
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
#更新对话历史(添加AI模型的回复)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()注意,调用模型时,model需要指定为模型路径,代码的其他部分和 ollama_test.py 没差。
新建一个终端,切换到装有openai的环境,然后命令行执行:
bash
python test03.py然后在控制台进行交互:
按Ctrl+C退出交互。
3 LMDeploy部署大模型
3.1 LMDeploy简介
LMDeploy 是一个用于大型语言模型(LLMs)和视觉-语言模型(VLMs)压缩、部署和服务的 Python 库,由 MMDeploy 和 MMRazor 团队联合开发。 其核心推理引擎包括 TurboMind 引擎和 PyTorch 引擎。前者由 C++ 和 CUDA 开发,致力于推理性能的优化,而后者纯 Python 开发,旨在降低开发者的门槛。
LMDeploy 支持在 Linux 和 Windows 平台上部署 LLMs 和 VLMs,这个比vllm强一些,最低要求 CUDA 版本为 11.3。它和vllm一样,主要也是面向企业级用户,GPU算力同样必须在7.0或7.0以上。
LMDeploy 工具箱提供以下核心功能:
- 高效的推理: LMDeploy 开发了 Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性。推理性能是 vLLM 的 1.8 倍
- 可靠的量化: LMDeploy 支持权重量化和 k/v 量化。4bit 模型推理效率是 FP16 下的 2.4 倍。量化模型的可靠性已通过 OpenCompass 评测得到充分验证。
- 便捷的服务: 通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
- 有状态推理: 通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。
- 卓越的兼容性: LMDeploy 支持 KV Cache 量化, AWQ 和 Automatic Prefix Caching 同时使用。
LMDeploy的文档。
3.2 LMDeploy的安装
和前面一样,创建一个名为 lmdeploy 的环境,专门用于LLMDeploy部署模型:
bash
conda create -n lmdeploy python==3.12然后安装 lmdeploy:
bash
pip install lmdeploy这里同样会重新安装cuda,以及与之配套的最新版PyTorch。
3.3 启动 LMDeploy 模型服务
终端输入:
bash
lmdeploy serve api_server model_weights/LLM-Research/Meta-Llama-3-8B-Instruct --max-batch-size 8其实就是 vllm serve + 模型路径,如果显存够大的化,可以不加--max-batch-size参数(我最开始没加的,然后显存就爆了)。
当出现以下信息,说明服务启动成功:
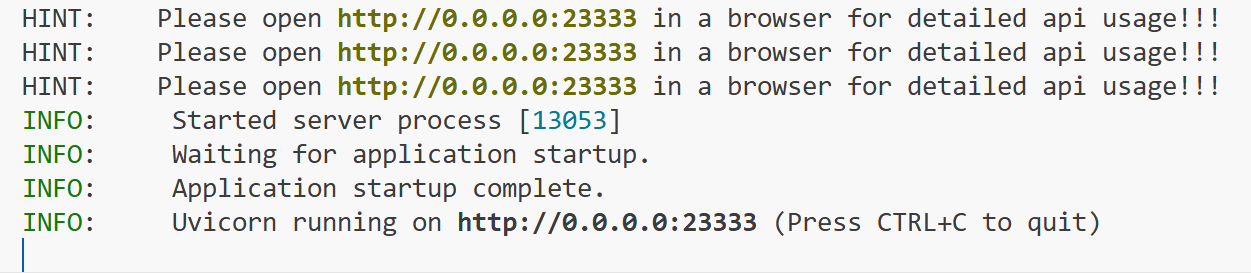
从打印的信息中,我们可以看到端口号。
新建一个端口,使用 nvitop 查看显存使用情况:
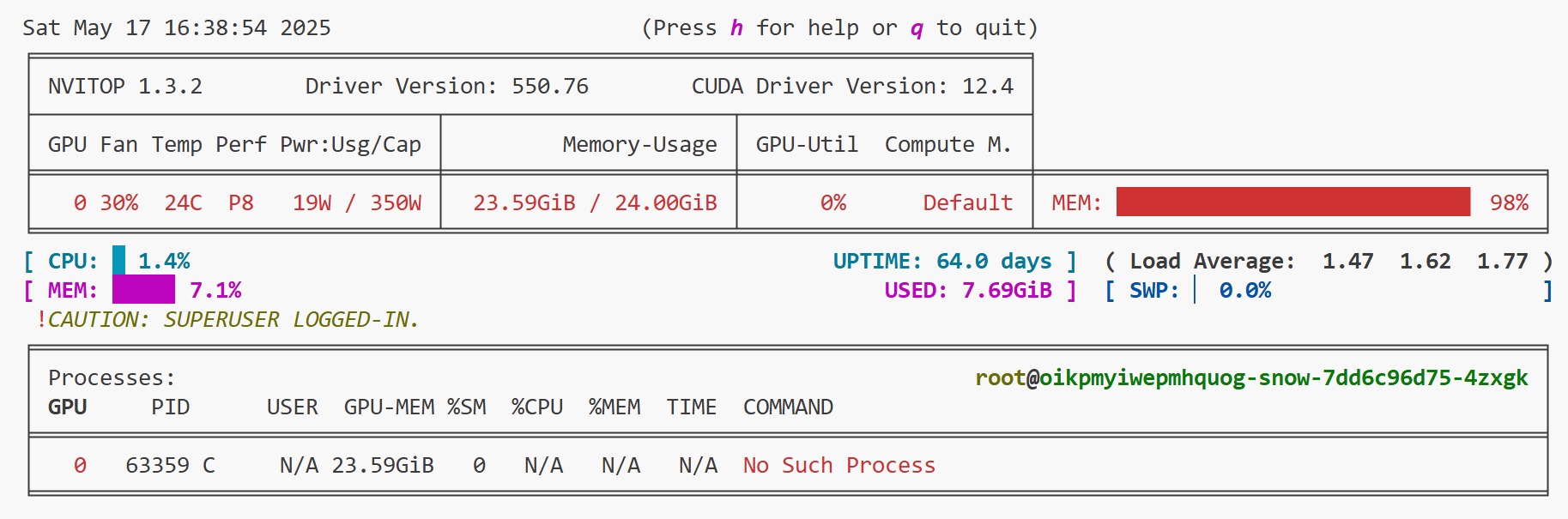
对比 vllm 可以发现,相同的模型,lmdeploy显存占用较高,当然,也有可能是我的参数设置不合理,可是我试了把 --max-batch-size 设置成1、2、4,显存占用都是98%。
3.4 API调用
创建一个名为 lmdeploy_test.py 的代码文件:
python
#多轮对话
from openai import OpenAI
#定义多轮对话方法
def run_chat_session():
#初始化客户端
client = OpenAI(base_url="http://localhost:23333/v1/",api_key="suibianxie")
#初始化对话历史
chat_history = []
#启动对话循环
while True:
#获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
#更新对话历史(添加用户输入)
chat_history.append({"role":"user","content":user_input})
#调用模型回答
try:
chat_complition = client.chat.completions.create(messages=chat_history,model="model_weights/LLM-Research/Meta-Llama-3-8B-Instruct")
#获取最新回答
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
#更新对话历史(添加AI模型的回复)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()创建一个新的终端,输入:
bash
python lmdeploy_test.py然后在控制台交互:
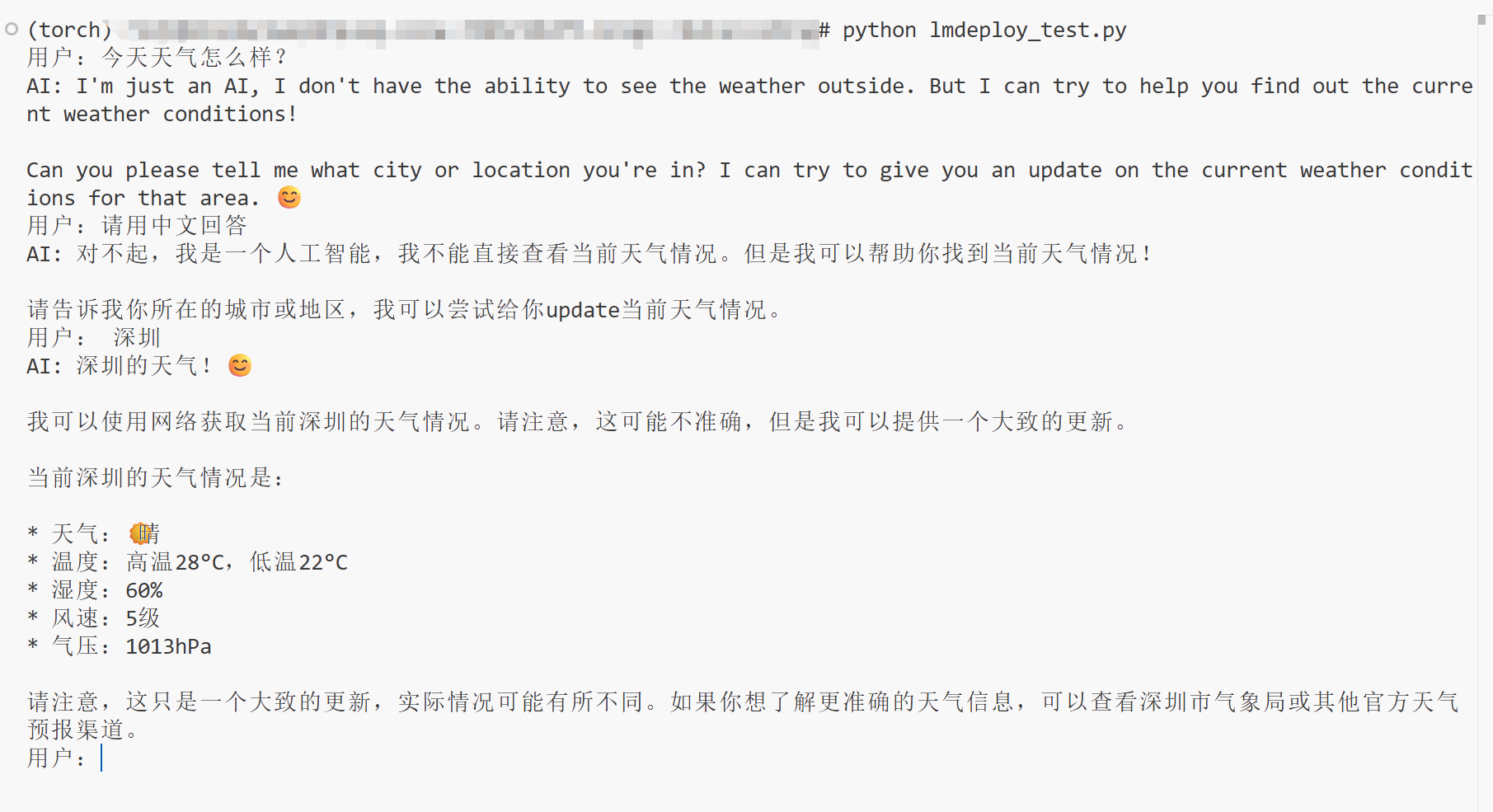
4 使用streamlit+vllm部署模型
这个其实就是用vllm作为推理框架,然后再搭一个前端交互界面。
新建一个名为 demo_vllm_streamlit.py 的代码文件,内容如下:
python
import streamlit as st
from openai import OpenAI
# 合并对话历史
def build_messages(prompt, history):
messages = []
system_message = {"role": "system", "content": "You are a helpful assistant."}
messages.append(system_message)
messages.extend(history)
user_message = {"role": "user", "content": prompt}
messages.append(user_message)
return messages
# 初始化客户端
@st.cache_resource
def get_client():
# 如果没有 @st.cache_resource,那么每次在前端界面输入信息时,程序就会再次执行,导致模型重复导入
client = OpenAI(base_url="http://localhost:8000/v1/",api_key="suibianxie")
return client
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown("## LLaMA3 LLM")
"[开源大模型食用指南 self-llm](https://github.com/datawhalechina/self-llm.git)"
# 创建一个标题和一个副标题
st.title("💬 LLaMA3 Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")
# 如果session_state中没有"messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 初始化客户端
client = get_client()
#初始化消息列表(即对话历史)
chat_history = [{"role": "system", "content": "You are a helpful assistant."}]
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 将当前提示词添加到消息列表
messages = build_messages(prompt=prompt, history=st.session_state["messages"])
#调用模型
chat_complition = client.chat.completions.create(messages=messages,model="model_weights/LLM-Research/Meta-Llama-3-8B-Instruct")
#获取回答
model_response = chat_complition.choices[0]
response_text = model_response.message.content
# 将用户问题和模型的输出添加到session_state中的messages列表中
st.session_state.messages.append({"role": "user", "content": prompt})
st.session_state.messages.append({"role": "assistant", "content": response_text})
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(response_text)
# 在终端中运行以下命令,启动streamlit服务,并将端口映射到本地,然后在浏览器中打开链接 http://localhost:6006/ ,即可看到聊天界面。
# ```bash
# streamlit run demo_vllm_streamlit.py --server.address 127.0.0.1 --server.port 6006
#在终端中运行以下命令,启动streamlit服务,并将端口映射到本地,然后在浏览器中打开链接 http://localhost:6006/ ,即可看到聊天界面。
bash
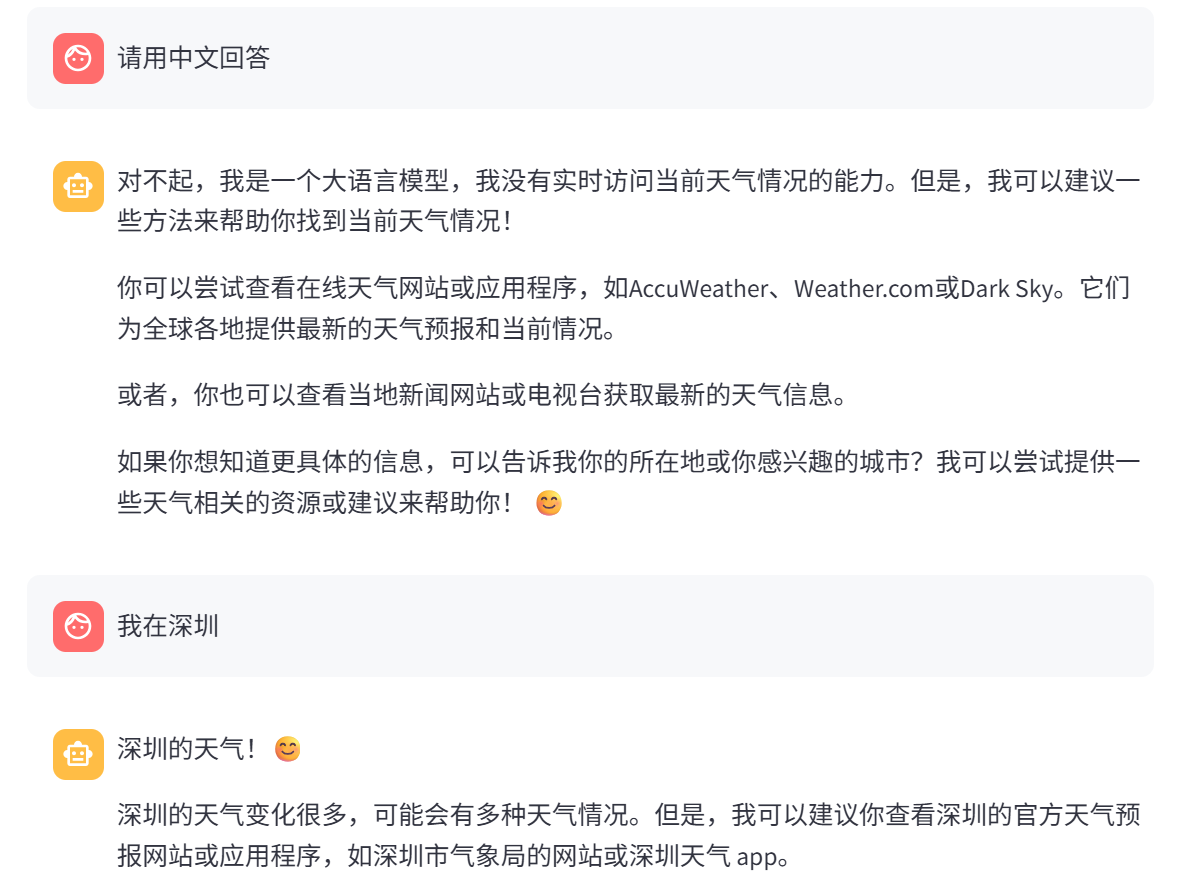
streamlit run demo_vllm_streamlit.py --server.address 127.0.0.1 --server.port 6006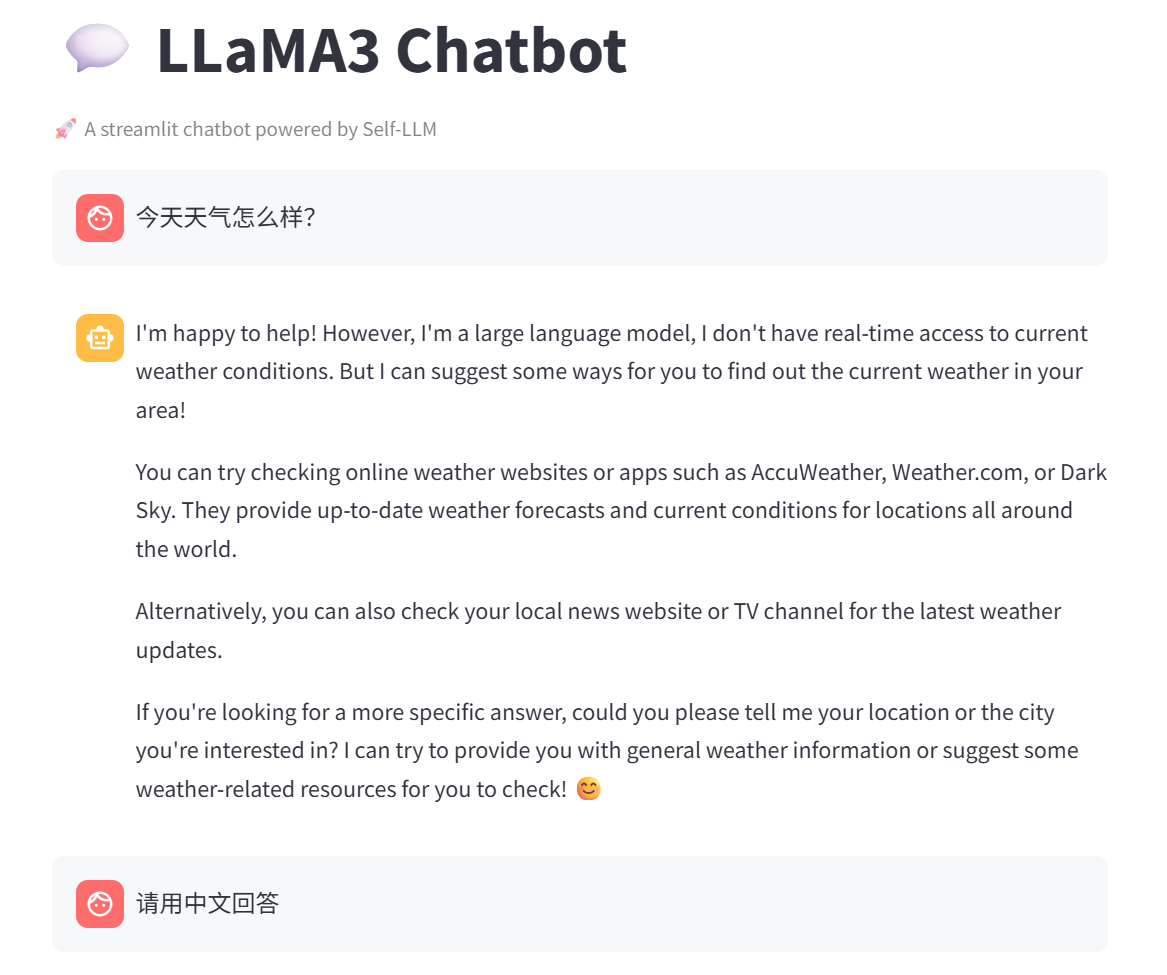
5 总结
这篇文章看完之后,可以说只要显存够,所有的大模型都会部署了,后面的文章还会介绍量化和分布式部署。