1、概述
一款 app 除了要有令人惊叹的功能和令人发指交互之外,在性能上也应该追求丝滑的要求,这样才能更好地提高用户体验:
| 优化目的 | 性能指标 | 优化的方向 |
|---|---|---|
| 更快 | 流畅性 | 启动速度 页面显示速度(显示和切换) 响应速度 |
| 更稳定 | 稳定性 | 避免出现 应用崩溃(Crash) 避免出现 应用无响应(ANR) |
| 更省 | 资源节省性 | 内存大小 安装包大小 耗电量 网络流量 |
响应速度一项就主要取决于数据结构和算法。
2、ArrayList 与 LinkedList
ArrayList 里面是数组,get/set 速度快,但 add/remove 速度慢,因为数组是连续内存,访问某个元素可以根据首地址与偏移量计算出该元素的地址,从而快速访问到元素,但是添加/移除一个元素需要移动其它元素,故而速度慢。
研究下 add() 的源码,视频里的源码版本 add() 时,如果目标位置上已经存有元素,就会调用 System.arrayCopy() 把所有元素向后移一位,但是我看现在的版本底层实现又改了,不用 System.arrayCopy() 了。但不论怎样实现,你都要清除,添加、删除元素都会有性能损耗。
与 ArrayList 相对的是基于双向链表的 LinkedList,插入删除快,访问慢。
3、HashMap 存元素过程
HashMap 在 Android 源码中的实现以 api 26,即 Android 8.0 为界,分为两个版本:
- Android 8.0(api 26)之前,HashMap 通过 ArrayList + LinkedList 实现
- Android 8.0 开始,HashMap 通过数组 + 链表 + 红黑树实现
以下是 HashMap 的结构示意图:
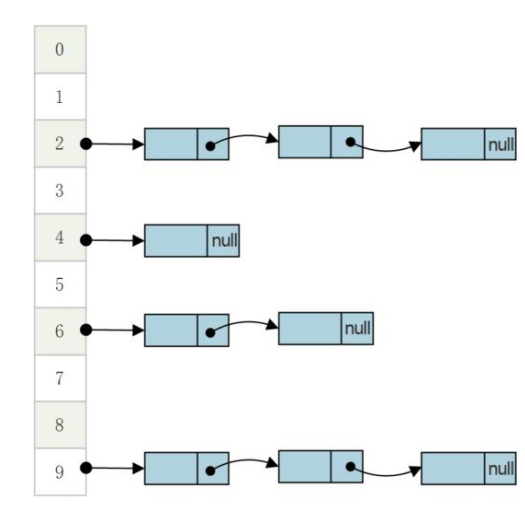
竖向排列的 0 ~ 9 是存放 key 的数组,数组存放一个链表,链表的每个节点都是 value。
首先来考虑一个问题,HashMap 中 key 与 value 的关系,是一对多、一对一还是多对一?结论是多对一,即一个 key 只能保存一个 value,如果对同一个 key put 不同的 value,那么原来的 value 会被覆盖;反之,多个 key 可以有同一个 value。
具体内容要看 put 的源码(使用 7.0 源码):
java
// 默认初始容量,必须是 2 的幂
static final int DEFAULT_INITIAL_CAPACITY = 4;
// 当表格未被填充时,可以共享的空表格实例
static final HashMapEntry<?,?>[] EMPTY_TABLE = {};
// HashMap 实体,可以根据需要调整大小。长度必须始终是 2 的幂
transient HashMapEntry<K,V>[] table = (HashMapEntry<K,V>[]) EMPTY_TABLE;
public V put(K key, V value) {
// table 为空时创建一个 HashMapEntry 数组给它,这是延迟初始化
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 如果 key 为空,则将其加入 table[0] 这个链表中
if (key == null)
return putForNullKey(value);
// 通过 key 计算出哈希值
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
// 哈希值与 HashMap 长度进行位运算(等价于取模运算)计算索引
int i = indexFor(hash, table.length);
// table[i] 是 i 位置的链表头,for 循环就是从头遍历这个链表
for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 寻找哈希值相同并且 key 也相同的节点,把新的 value 存进该节点
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// key 尚未存入 HashMap,通过 addEntry() 将新的 key-value 加入
modCount++;
addEntry(hash, key, value, i);
return null;
}从 put() 中能看出最明显的一点是:哈希表不是在 HashMap 的构造方法中初始化的,而是在 put() 时才初始化,这是一种通过延迟加载节约内存的方式,因为 HashMap 很大。
下面按照 put() 的代码顺序说明其中的部分细节。
3.1 table 初始化
当 table 是空表 EMPTY_TABLE 时,通过 inflateTable() 为 table 初始化:
java
// threshold = capacity * loadFactor,当 HashMap 中
// 存储的元素个数大于 threshold 时就要对 HashMap 扩容。
int threshold;
// 默认为 0.75
final float loadFactor = DEFAULT_LOAD_FACTOR;
// 初始化 table 并计算出扩容阈值 threshold
private void inflateTable(int toSize) {
// capacity 是比 toSize 大的最小的 2 的幂
int capacity = roundUpToPowerOf2(toSize);
// Android-changed: 替换此处对 Math.min() 的使用,因为该方法在运行时的
// <clinit> 中调用,此时 Float.* 所需的本地库可能尚未加载
float thresholdFloat = capacity * loadFactor;
if (thresholdFloat > MAXIMUM_CAPACITY + 1) {
thresholdFloat = MAXIMUM_CAPACITY + 1;
}
threshold = (int) thresholdFloat;
table = new HashMapEntry[capacity];
}roundUpToPowerOf2()
roundUpToPowerOf2() 在不超过最大容量 MAXIMUM_CAPACITY = 1 << 30 的情况下,返回大于参数 number 的最小 2 的幂:
java
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
int rounded = number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (rounded = Integer.highestOneBit(number)) != 0
? (Integer.bitCount(number) > 1) ? rounded << 1 : rounded
: 1;
return rounded;
}Integer.highestOneBit()
Integer.highestOneBit() 是一个简单的位操作算法,它通过执行一系列的位移和按位或操作,将指定的值的所有位都设置为最高位之后的所有位都为 1。然后,通过将该值减去右移一位后的值(无符号右移)来保留最高位的 1,其他位都为 0:
java
/**
* 返回一个 long 类型的值,其最多只有一个位为 1,该位位于指定
* 的 i 值最高位(最左边)的一位。
* 如果指定的值在其二进制的补码表示中没有一位为 1,即等于零,则返回零
*/
public static long highestOneBit(long i) {
// long 是 64 为,而 i 右移了 63 位
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
i |= (i >> 32);
return i - (i >>> 1);
}例如 i = 10011010,最高位的 1 位于第 5 位(从右向左数)。经过方法的处理后,返回的值为 10000000。这个方法的用途包括找到一个数中的最高位,计算一个数的对数(以 2 为底),或者确定一个数是否是 2 的幂等等。
Integer.bitCount()
java
/**
* 返回给定值二进制补码表示中的位数,有时这个函数被称为种群计数
*/
public static int bitCount(long i) {
i = i - ((i >>> 1) & 0x5555555555555555L);
i = (i & 0x3333333333333333L) + ((i >>> 2) & 0x3333333333333333L);
i = (i + (i >>> 4)) & 0x0f0f0f0f0f0f0f0fL;
i = i + (i >>> 8);
i = i + (i >>> 16);
i = i + (i >>> 32);
return (int)i & 0x7f;
}3.2 存放 key 为 null 的元素
key 为 null 时通过 putForNullKey() 存入元素:
java
private V putForNullKey(V value) {
// 遍历 table[0] 这个链表,如果有 key 为 null 的节点,则用新的 value 替换 oldValue
for (HashMapEntry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// table[0] 目前没有 key = null 的节点,则创建并存入这个节点
modCount++;
addEntry(0, null, value, 0);
return null;
}addEntry() :
java
// 添加 key = null 的元素时,hash 传 0、key 传 null、bucketIndex 传 0
void addEntry(int hash, K key, V value, int bucketIndex) {
// 超过扩容的阈值并且 table[bucketIndex] 链表不为空
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容
resize(2 * table.length);
hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0;
// 通过哈希值和扩容后的长度,计算应该放在哪个链表中
bucketIndex = indexFor(hash, table.length);
}
// 创建新的 HashMapEntry
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
// 让 e 指向 table[bucketIndex] 这个链表头
HashMapEntry<K,V> e = table[bucketIndex];
// 新创建的 HashMapEntry 的 next 指向 e,再赋值给 table[bucketIndex],
// 相当于在链表头插入了这个新的 HashMapEntry
table[bucketIndex] = new HashMapEntry<>(hash, key, value, e);
size++;
}HashMapEntry 的构造方法:
java
static class HashMapEntry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
// 链表
HashMapEntry<K,V> next;
int hash;
// n 是原来的链表,让 next指向 n,就是在原链表的头插入了 this
HashMapEntry(int h, K k, V v, HashMapEntry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}3.3 计算 key 的哈希值
HashMap 使用 key 的 hashCode 值来确定 key 在内部数据结构中的存储位置。计算 key 的哈希值时可能会有装箱操作:
java
public static int singleWordWangJenkinsHash(Object k) {
// k 是 Object 类型,那么可能是基本类型,也可能是引用类型
int h = k.hashCode();
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}如果 k 是基本数据类型,不会发生装箱操作,但如果是引用数据类型,通常会将对象转换为 Integer、Long 或其他装箱类型,然后再调用其 hashCode() 来计算哈希值。这个装箱操作可能会对性能产生一定的影响,因此在需要高性能的场景下,可以考虑使用基本数据类型作为 key,以避免装箱操作带来的开销。
3.4 indexFor() 计算索引
计算索引的目的是为了找出新加入元素应该保存在哪个位置:
java
// h 是 key 的哈希值,length 是 HashMap 当前容量
static int indexFor(int h, int length) {
return h & (length-1);
}h & (length-1) 这个与运算,相当于 h % length 即对 length 求模。直接使用位运算的原因是其效率更高(所有的加减乘除的计算,最终都会转换成位的与或非运算,在将运算指令转换为字节码的过程中,位运算可能只有一条字节码,而数学计算因为存在转换,可能有多条字节码,显然使用一条字节码的位运算效率更高)。
3.5 保存新的值
通过 indexFor() 求出新值在 table 数组的下标后,就应该将其保存到数组中。数组的结构如下图:
table 数组的每一个元素都是一个链表,链表元素类型是 HashMapEntry,其内部有 next 指针指向链表中的下一个 HashMapEntry。
从图中能看出,存放新值涉及两种情况:
- 目标位置的链表不为空,且遍历时发现要操作的 key 所在的 HashMapEntry 已经在这个链表中,那么直接用新值覆盖老值
- 目标位置的链表为空,或者链表不为空但在遍历时并没有找到包含目标 key 的 HashMapEntry,那就只能新建一个 HashMapEntry 存入目标位置
这两种情况分别对应 put() 中的 for 循环和最后的 addEntry(),for 循环会在 key 匹配的 HashMapEntry 直接用新值替换老值,而 addEntry() 前面已经介绍过,它会使用"头插法",在链表头插入新的 HashMapEntry。
为什么用链表保存 HashMapEntry 呢?一个 tablek 中的链表有多个元素,是因为这些元素的 hashCode 计算出的 index 相同,也称哈希碰撞(冲突)。而这种"链表法"也正是解决哈希碰撞的一种方法,将相同 index 的元素存在链表中,那么在 get 某一个元素时,先计算出这个元素的 index,然后再去这个 index 的链表中遍历元素,找是否有 key 相同的元素。
3.6 扩容问题
最后我们来说说扩容问题。其实前面贴源码的时候出现过与扩容有关的常量和变量:
- HashMap 容量:在 8.0 之前的 HashMap 中,DEFAULT_INITIAL_CAPACITY = 4,而从 8.0 开始,DEFAULT_INITIAL_CAPACITY = 1 << 4,即 16 个。并且这个容量值必须是 2 的幂,如 16、32、64...
- 加载因子:默认值 DEFAULT_LOAD_FACTOR = 0.75f,这个 0.75 是谷歌测试结果,实际上论文中表述的是数学家认为 0.6 ~0.75 是最佳范围。
- 扩容的阈值:当 HashMap 中元素个数超过 threshold = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR 时,对于默认值来说就是 4 * 0.75 = 3 个时,就要进行扩容
以下我们通过几个问题来了解扩容。
为什么要扩容?
HashMap 扩容的意义在于提升效率,那么 HashMap 何时效率最低呢?不是满载的时候,而是全部冲突时(所有元素全在 tablek 的链表中,退化成单链表了)。
扩容会降低元素的冲突情况。因为扩容只是将 HashMap 的 length 翻倍,而通过 key 计算的 hashCode 没有变,由于索引等价于 hashCode % length,这样 HashMapEntry 的索引就会随之改变,很容易出现原本在同一个链表中的 HashMapEntry 在扩容后会分到不同链表的情况。
比如两个 key 的 hashCode 分别为 1 和 17,那么对于容量为 16 的 HashMap 而言,这两个 key 都会存在 table1 中。而假如将 HashMap 扩容到 32,那么这两个 key 就不会存在同一个 table 链表中了。这样就降低了哈希冲突的概率,从而提升了 HashMap 的效率。
为什么要尽量避免扩容
扩容后需要把已经在 HashMap 中的元素重新计算它在扩容后的新位置并将其移动到这个新位置上,所以扩容是 HashMap 中耗费性能的一个动作,应该尽量避免扩容。因此在 new HashMap() 时应该先评估哈希表中可能要存放的元素数量 count,在 new 时传 new HashMap(count/0.75+1)。传进来的这个数,会在内部被取成大于它的最小的 2 的整数幂,比如传进来 25 会转变成 32。
为什么要求 HashMap 的容量必须是 2 的幂?
也是为了减少哈希碰撞从而提升效率的一种方法,这需要从二进制的角度来看 hashCode & (length - 1) 这个求模公式。
假如我们的长度违背了必须是 2 的幂的法则,比如说是 10,那么 length - 1 就为 9,转换成二进制就是 1001。那么在与 hashCode 做与运算时,就只有最高位和最低位是有效的,中间两位由于是 0,无论 hashCode 这两位是什么运算完都是 0,这就增加了 hashCode 碰撞的几率。比如说 hashCode 为 001,101,111 运算完都是 0001,那么他们就都会去 table1 这个链表中。而 2 的整数次幂 -1 后的二进制全部都是1,在与 hashCode 做与运算时对应位置的结果要看 hashCode 那一位是什么(即 hashCode 的所有位置都是有效的运算位置),减少了 hashCode 冲突的情况,从而提高了效率。
HashMap 有什么缺点吗?
因为 HashMap 存储的元素数量到最大容量的 75% 时就会开始扩容,这是用空间换时间的做法;而这造成了空间的浪费,尤其是仅仅超出阈值 1 个时也要扩容 2 倍,这大大的浪费了空间。所以在 Android 中有一个解决方法就是使用 SparseArray。
4、SparseArray
使用 SparseArray 主要是为了节省空间,其内部将 key 和 value 分别保存在两个数组中:
java
private int[] mKeys;
private Object[] mValues;在 put() 时通过二分查找找到 key 在 mKeys\[\] 中的位置并存入(key 按照从小到大的顺序排列),如果需要移动元素就 arrayCopy() 移动。比如说找到 key 存入 mKeysk,那么 value 就要存到 mValuesk 这个位置。大致结构如图:
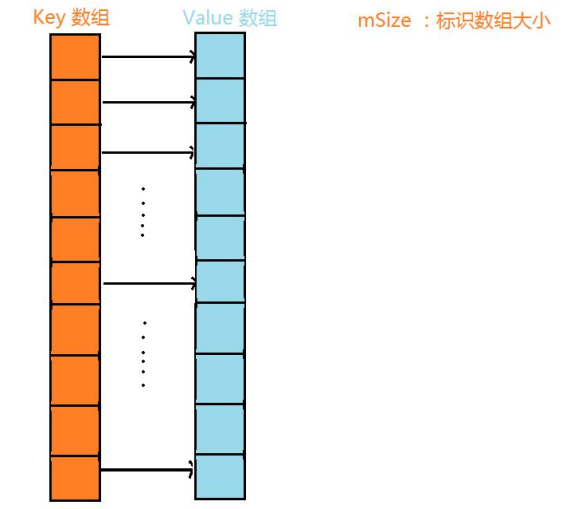
这样做的优点:
- 节约内存,不会有冲突了
- 速度上采用二分查找,也很快,删除时是给这个位置赋值为 DELETED,不发生位移,不会把后面的元素向前移,等到后面再插入元素时如果这个位置是 DELETED 就可以直接存放,不用把该位置后面的元素都向后移一位。
测试同样是长度为 10000 的 HashMap 和 SparseArray:
- put 10000 个元素,HashMap 用时 239ms,SparseArray 用时 44ms
- get 10000 个元素,HashMap 用时 43ms,SparseArray 用时 17ms
空间上 SparseArray 一定是比 HashMap 要节约空间的。
缺点是 key 只能是 int 类型的,解决方式是使用 ArrayMap(SimpleArrayMap),它是 HashMap 与 SparseArray 的结合体。
SimpleArrayMap 的 key 取的是 Object 的 hashCode,由于 hashCode 也是可能会发生冲突的,所以 SimpleArrayMap 也是需要解决哈希碰撞的,它的解决方式就是采用追加。意思是,比如通过 hashCode 算出某个 Object 应该存放的位置是 k,但是 keysk 已经有了元素,那么就逐一再检查 keysk+1,keysk+2...直到有一个位置空闲,就把 Object 放在那个位置上。当元素满了之后也需要扩容(+1),发生 arraycopy 操作。
总结:实际上源码中使用的数据结构不断演进的过程,就是不断提升性能的过程。而性能提升,又分为空间和时间的优化。